Seongkyun Han's blog
Seongkyun Han's blog
Pytorch에서 tensorboard로 loss plot하기
11 May 2019 | Pytorch tensorboard tensorflowPytorch에서 tensorboard로 loss plot하기
- 참고 글: https://pythonkim.tistory.com/39
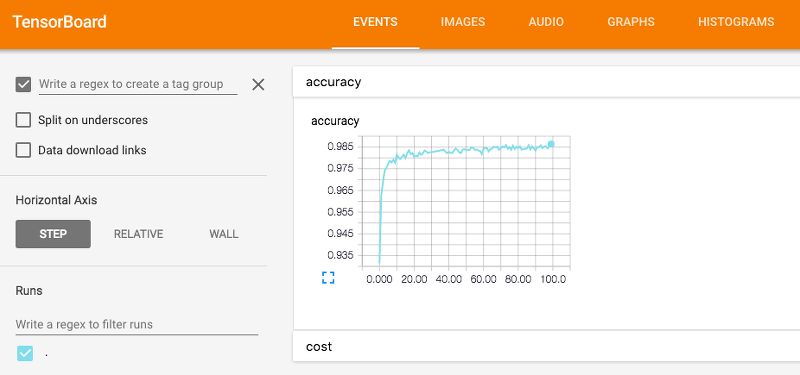
- Tensorboard는 tensorflow에서 제공하는 툴로, log를 그래프로 시각화하여 보여주는 도구다.
설치
- Pytorch에서 tensorboard로 loss plot을 하기 위해서는
tensorboardX가 필수로 설치되어 있어야 한다.- 설치:
pip install tensorboardX - tensorboardX를 사용하기 위해선 tensorboard가 필요하며, tensorboard는 tensorflow가 필요하다.
- tensorflow를 설치하면 알맞는 버전의 tensorboard가 자동으로 설치된다.
- 설치:
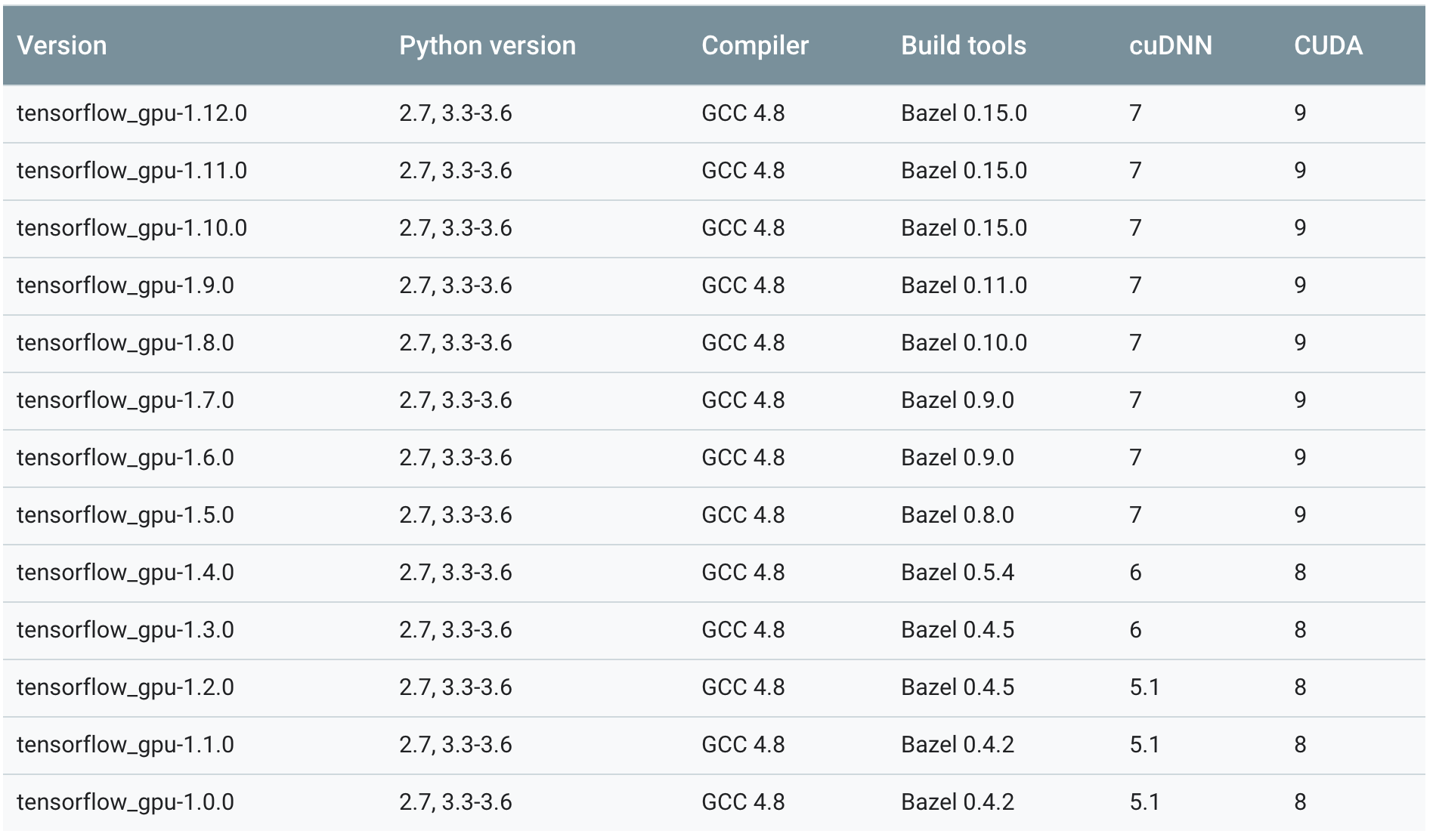
pip install tensorflow-gpu==version - version에는 자신의 CUDA와 cuDNN 버전에 알맞는 버전의 tensorflow version을 넣으면 됨(본인은
tensorflow-gpu==1.12.0)
- 설치:
- 설치:
코드 작업
- Pytorch 코드 내에서 별도의 작업이 필요하다.
- 학습 코드 상단부에 summaryWriter를 정의해준다.
from tensorboardX import SummaryWriter
summary = SummaryWriter()
...
- 모델 학습과정에서 tensorboard에 plot 할 값들에 대한 x축으로 사용할 값(변수)이 필요하다.
- 전체에 대한 iteration이 담기면 되므로, 본인은 total iteration이 담기는
iteration변수를 설정하였음 - 전체 학습 loop에 대해 tensorboard에서 x축으로 사용할 변수(
iteration)는 epoch이 변해도 초기화되지않고 이어서 커져야 함
- 전체에 대한 iteration이 담기면 되므로, 본인은 total iteration이 담기는
- 변수 설정 후, 학습 loop에서 매 iteration마다 값을 update하면 실효성도 떨어지고 너무 데이터가 많아진다.
- 따라서 적절하게 (10이나 20iteration마다) 값을 update한다.
- 또한, pytorch tensor에 담긴 loss값은 값의 형태로 전달되도록
tensor_name.item()멤버를 이용하여 리턴받는다.
from tensorboardX import SummaryWriter
summary = SummaryWriter()
...
for iteration in range(start_iter, max_iter):
...
out = net(input)
loss_a, loss_b = criterion(out)
loss = loss_a, loss_b
loss.backward()
optimizer.step()
if iteration % 10 == 0: # 매 10 iteration마다
summary.add_scalar('loss/loss_a', loss_a.item(), iteration)
summary.add_scalar('loss/loss_b', loss_b.item(), iteration)
summary.add_scalar('learning_rate', lr, iteration)
summary.add_scalar('loss/loss', {"loss_a": loss_a.item(),
"loss_b": loss_b.item(),
"loss": loss.item()}, iteration)
...
Tensorboard 실행
- 새로운 터미널을 켠 후,
tensorboard --logdir=directory_to_log_file로 tensorboard를 실행한다.- 보통 log 파일은 별도의 설정이 없다면 해당 코드를 실행시킨 폴더에
runs폴더가 생성된 후 그 안에 해당 시점 이름의 폴더에 저장된다. - 만약 특정 위치로 log가 저장되게 하고 싶다면, 위 코드에서
summary = SummaryWriter(dir_to_log_file)의 dir_to_log_file에 저장되게 할 수 있다.
- 보통 log 파일은 별도의 설정이 없다면 해당 코드를 실행시킨 폴더에
- 한 번에 두 개의 학습이 돌아가고 있는 경우, 별도 port를 설정해야 한다.
tensorboard --logdir=directory_to_log_file --port=8008또는--port=6006- tensorboard의 기본 port 번호는 6006이다.
- 실행 후 생성되는 인터넷 주소를 복사하여 웹 브라우저에 넣으면 그래프를 확인 할 수 있다.
- 형식은
username:port으로 주소가 생성된다.
- 형식은
- 종료의 경우 tensorboard를 실행시킨 터미널에서
Ctrl + C로 종료한다.
학습을 끊었다가 이어서 하게되는 경우
- 메인 코드에서
summary = SummaryWriter(dir_to_log_file)에서 dir_to_log_file의 주소를 이전 log가 존재하던위치로 설정해주면 알아서 이어서 그래프를 plot해준다. - 하지만 x축으로 이용되는 변수(
iteration)가 다시 1부터 시작하게 될 경우 그래프가 덧씌어져 의미 없게 되므로 이에대한 대처코드가 training code에 존재해야 한다.