Seongkyun Han's blog
Seongkyun Han's blog
Distilling the knowledge in a Neural Network
02 Apr 2019 | Deep learningDistilling the knowledge in a Neural Network
Original paper: https://arxiv.org/pdf/1503.02531.pdf
Authors: Geoffrey Hinton, Oriol Vinyals, Jeff Dean (Google Inc)
- 참고글: https://www.youtube.com/watch?v=tOItokBZSfU
-
참고글: https://jamiekang.github.io/2017/05/21/distilling-the-knowledge-in-a-neural-network/
- 논문의 내용 들어가기에 앞서, 아래와 같이 간단한 개념을 이해하고 시작하는게 도움 됨.
- Google과 같이 큰 회사에서 ML로 어떤 서비스를 개발 할 때, 개발 단계에 따라 training에 사용되는 모델과 실제 서비스로 deploy 되는 모델에는 차이 존재
- 즉, training에 사용되는 모델은 대규모 데이터를 갖고 batch 처리를 하며 리소스를 비교적 자유롭게 사용하고, 최적화를 위한 비슷한 여러 변종이 존재 할 것임
- 반면에 실제 deployment 단계의 모델은 데이터의 실시간 처리가 필요하며 리소스의 제약을 받는 상태에서의 빠른 처리가 중요함
- 이 두가지 단계의 모델을 구분하는 것이 이 논문에서 중요한데, 그때 그때 다른 이름으로 부르므로
- 1번 모델을 “cumbersome model”로 하며 training stage 에서 large ensemble 구조를 갖고 동작하며, 느리고 복잡하나 정확히 동작함.(teacher)
- 2번 모델을 “small model”로 하며, deployment stage에서 single small 구조를 갖고 동작하며, 빠르고 간편하나 비교적 정확도가 떨어짐.(student)
- 머신 러닝 알고리즘의 성능을 올리는 아주 쉬운 방법은 많은 모델을 만들어 같은 데이터셋으로 training 한 다음, 그 prediction 결과 값을 average 하는 것임.
- 이러한 다중 네트워크를 포함하는 모델의 집합을 ensemble(앙상블) 모델이라 하며, 위에서 1번의 “cumbersome model”에 해당함
- 하지만 실제 서비스에서 사용할 모델은 2번 모델인 “small model”이므로, 어떻게 1번의 training 결과를 2번에게 잘 가르치느냐 하는 문제가 발생함
-
이 논문의 내용을 한 문장으로 말하면, 1번 모델(cumbersome model)이 축적한 지식(dark knowledge)을 2번 모델에 효율적으로 전달하는(기존 연구보다 더 general 한) 방법에 대한 설명임.
- 이 논문은 아래와 같이 크게 두 부분으로 나누어짐
- Model compression: 1번 ensemble 모델의 지식을 2번 모델로 전달하는 방법
- Specialist networks: 작은 문제에 특화된 모델들을 training 시켜 ensemble training 시간을 단축하는 방법
- 본 글에서는 distillation을 이용한 model compression에 대해 설명
Model compression
- Distilling ensemble model to single model을 이용
- 계산시간이 오래걸리는 앙상블 모델의 정보를 single model로 이전
- 앙상블 모델의 정보를 single model로 이전하는 방법을 distilling이라고 함
- 일반적인 인공신경망의 경우 파라미터 수가 많아 training data에 대해 overfitting이 쉬움.
- 이를 해결하기 위해 앙상블 모델을 사용하게 됨
Expensive ensemble
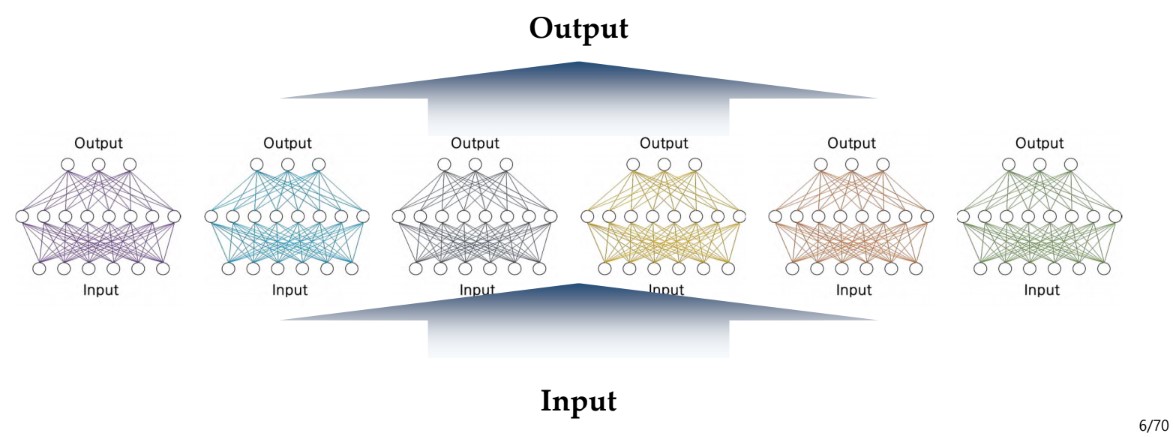
- 앙상블 모델이란, 위 사진처럼 Input에 대해 여러 모델들이 각각 계산을 한 후, 그 계산을 합쳐서 결과물을 내놓는 방법
- 쉽게 말해서 데이터셋을 여러개의 training set으로 나누어서 동시에 학습을 진행한 후, 모든 training set에 대한 학습이 끝난 후 그 결과를 통합하는 방식
- Hinton(저자)은 인공신경망 앙상블 모델의 학습과정에서 다른 앙상블처럼 hidden layer의 갯수를 각 구조가 서로 다르게 하기 보다는 단순이 initial parameter를 다르게 설정하는게 효과가 더 좋다고 설명함
- 이러한 앙상블 모델을 이용 할 경우 실험 결과는 최소 2에서 4~5%까지의 정확도 향상을 기대 할 수 있지만, weight parameter의 개수가 매우 많아져 저장공간이 매우 많이 필요하고 계산시간이 매우 오래걸린다는 단점이 존재함.
- GoogleNet의 경우 test set의 inference time조차도 크며, 결국 GPU를 이용한 병렬처리를 한다 해도 앙상블 안의 모델 개수가 core의 개수보다 많은 경우 한 모델에 대한 계산보다 시간이 훨씬 오래 걸리므로 연산에 부담이 됨
- Mobile device 등에서도 저장공간등의 이유로 mobile device에 앙상블 모델을 적용하는것은 불가능함
- 일반적인 딥러닝 모델도 저장공간이 많이 차지해서 mobile device에 적합하지 않음
- MobileNet 과 같은 특화된 구조 말고, VGG와 같은 모델은 모델의 크기가 500MB가 넘어가게 됨
Distilling ensemble: Single model
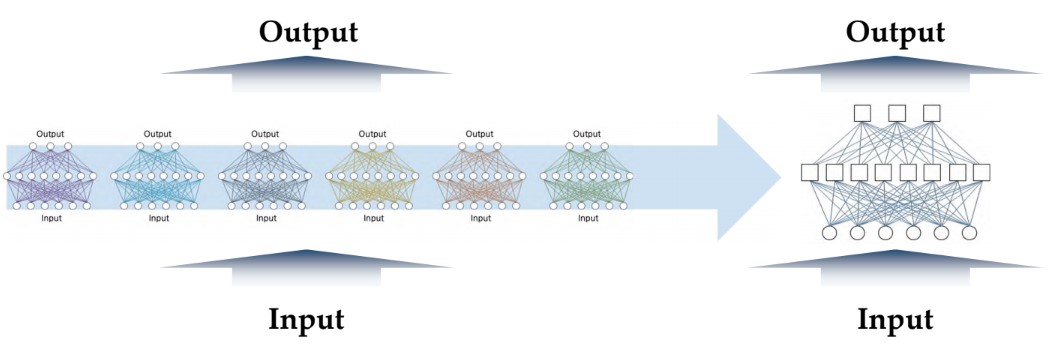
- 위에서 발생하는 문제들을 해결하기 위해 여러 앙상블 모델들의 정보를 전달받은 single model을 만들어야 함
- 이 모델은
- 앙상블 만큼의 좋은 성능을 보여야 하며
- 계산시간 및 저장공간을 조금 차지해 computation cost가 적은
- 위의 두 가지 조건을 만족시켜야 하며, 이러한 single shallow model을 얻는 것이 최종 목표임
- 이러한 여러 모델을 포함하는 앙상블 모델을 하나의 single model로 정보들을 이전하는 방식을 “distillation” 이라고 지칭
Distillation method 1
- Method from: Buciluǎ, C., Caruana, R., & Niculescu-Mizil, A. (2006, August). Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 535-541). ACM.
- 관측치가 많다면, 구지 앙상블 모델을 쓰지 않아도 일반화 성능이 좋아진다는 점에서 착안
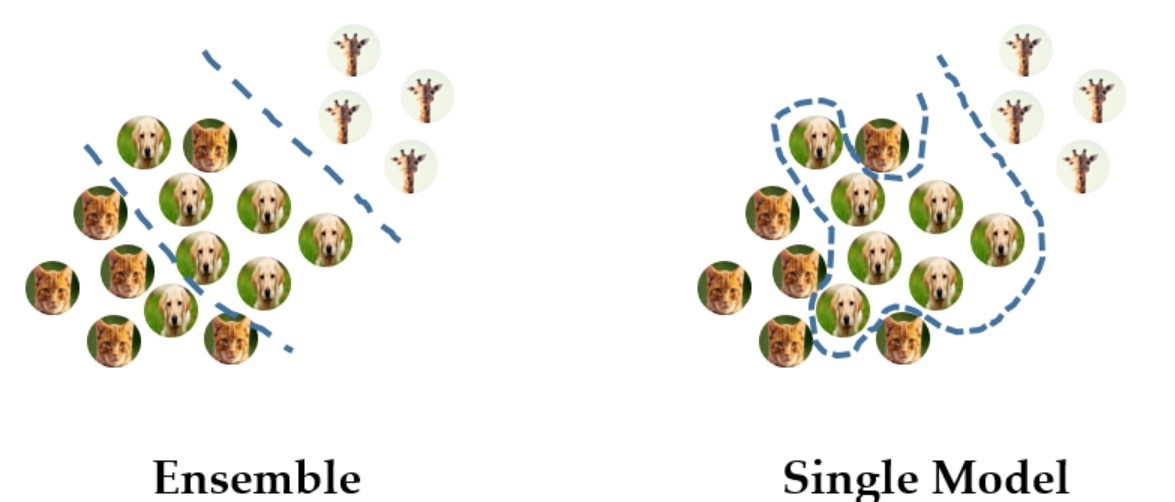
- 앙상블 모델의 경우 학습 데이터셋이 많지 않더라도 일반화 성능이 좋아 실제 test단에서 성능이 좋음
- Generalization이 잘 된 모델
- 일반적인 single model의 경우, training set에만 적합하도록 overfitting되는 경향이 있음
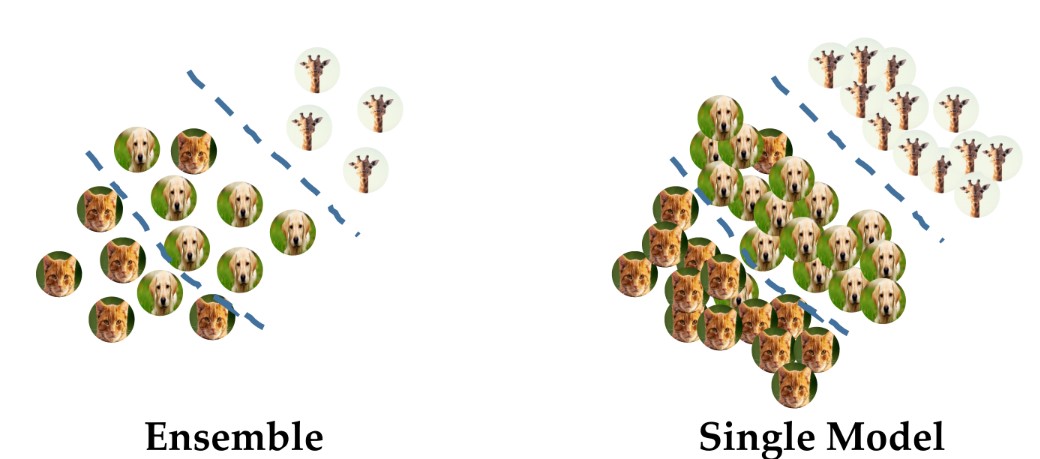
- 하지만 training data가 많아진다면 overfitting이 일부 발생하더라도 전반적으로 모델의 generalization 성능이 좋아지게 됨.
- 이러한 원리로 접근한 것이 첫 번째 방법.
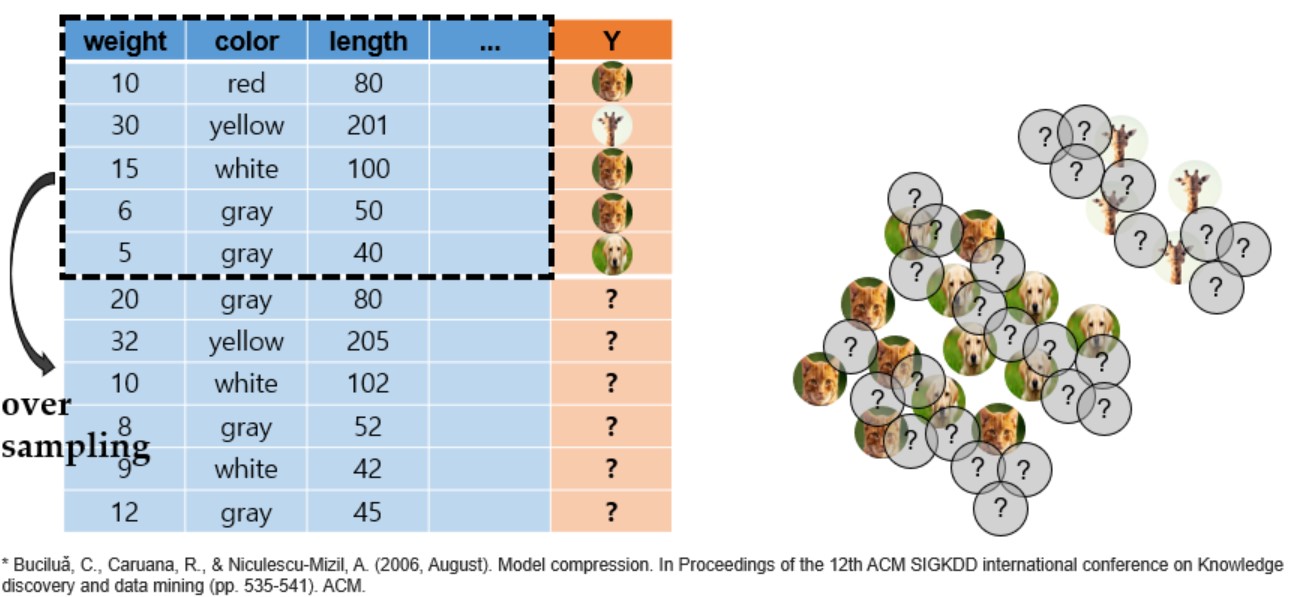
- 적은 량의 training dataset에 대해 oversampling을 통해 새로운 데이터셋을 생성(사진상의 물음표 처진 training data가 oversampling된 데이터)
- 이렇게 oversampling 된 데이터는 현재 label이 정의되어있지 않은 상태임
- 또한 기존의 data에 약간의 noise를 추가해 기존 data와 유사하지만 완전히 같지 않지만 유사한 새로운 unlabeled data를 생성
- 생성된 oversampling data는 label 정보가 없으므로, 이 생성된 data들에 대해 label을 붙이는 과정이 필요함
- 이 과정에서 기존의 training data로 학습된 앙상블 모델을 사용하여 label 정보를 생성시킴
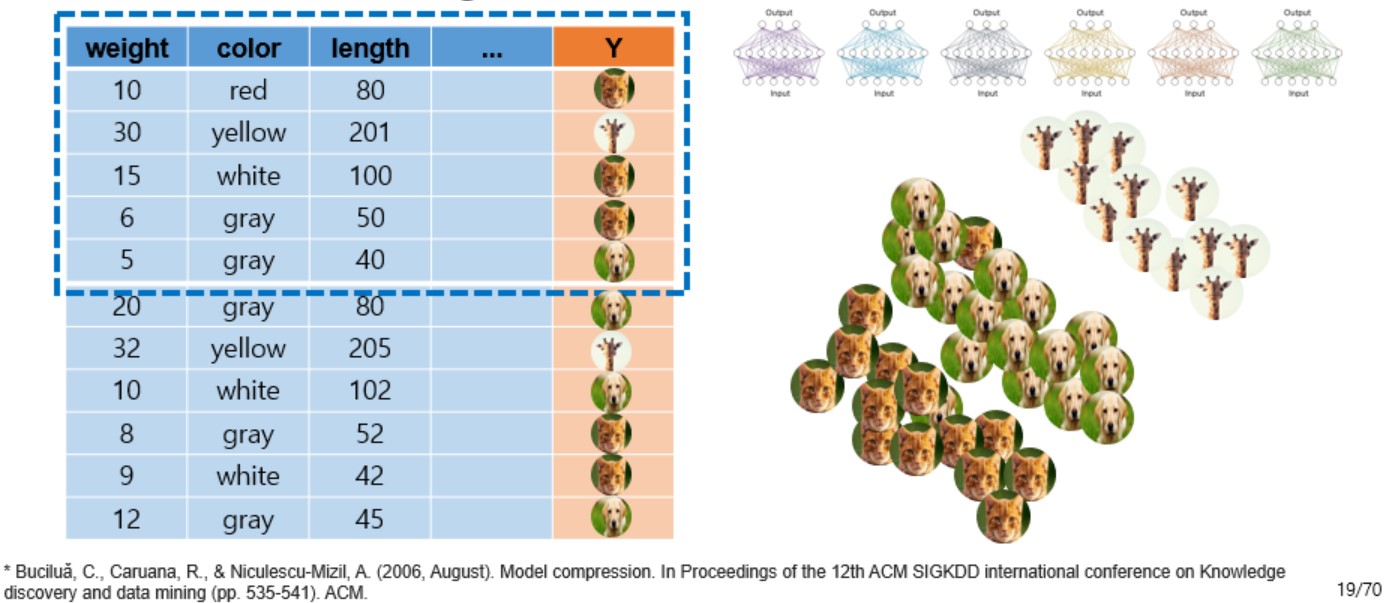
- 앙상블 모델을 이용하여 새로 생성된 oversampling data에 레이블 정보를 모두 생성함
- 위 과정을 통해 label정보를 모두 갖고있는 많은 data가 포함된 새로운 training dataset이 정의됨
- 이렇게 생성된 training dataset에는 앙상블 모델의 정보가 담겨있음.
- 새로운 training dataset을 이용하여 다시 single shallow model을 학습시킴
- 이로 인해 앙상블 모델의 정보가 전해진 single shallow network가 만들어짐
- 좀 더 generalization이 잘 되고, 좀 더 overfitting에 강인한 single shallow model이 학습됨
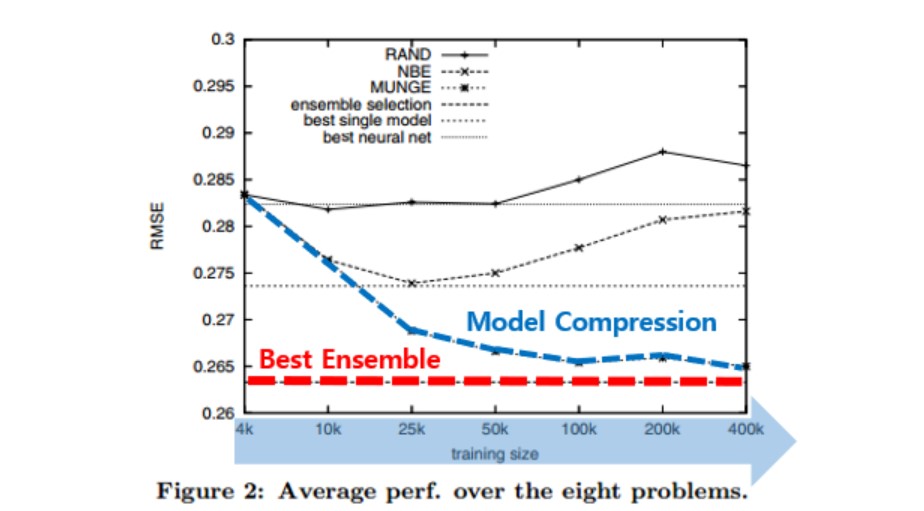
- 평가지표로 RMSE를 사용
- Training dataset size가 커질수록(x축에서 우측으로 갈수록) single shallow model의 성능이 best ensemble 모델과 비슷해지는것을 확인 가능
- 빨간 선이 best ensemble model, 파란 선이 single shallow model
Distillation method 2
- Method from: Ba, J., & Caruana, R. (2014). Do deep nets really need to be deep?. In Advances in neural information processing systems (pp. 2654-2662).
- 두 번째 방법으로, 단순히 네트워크의 출력으로 class 정보를 주었던 앙상블의 출력에 대한 logit값을 이용하여 앙상블 모델의 data 분포를 알아보자는 접근방식
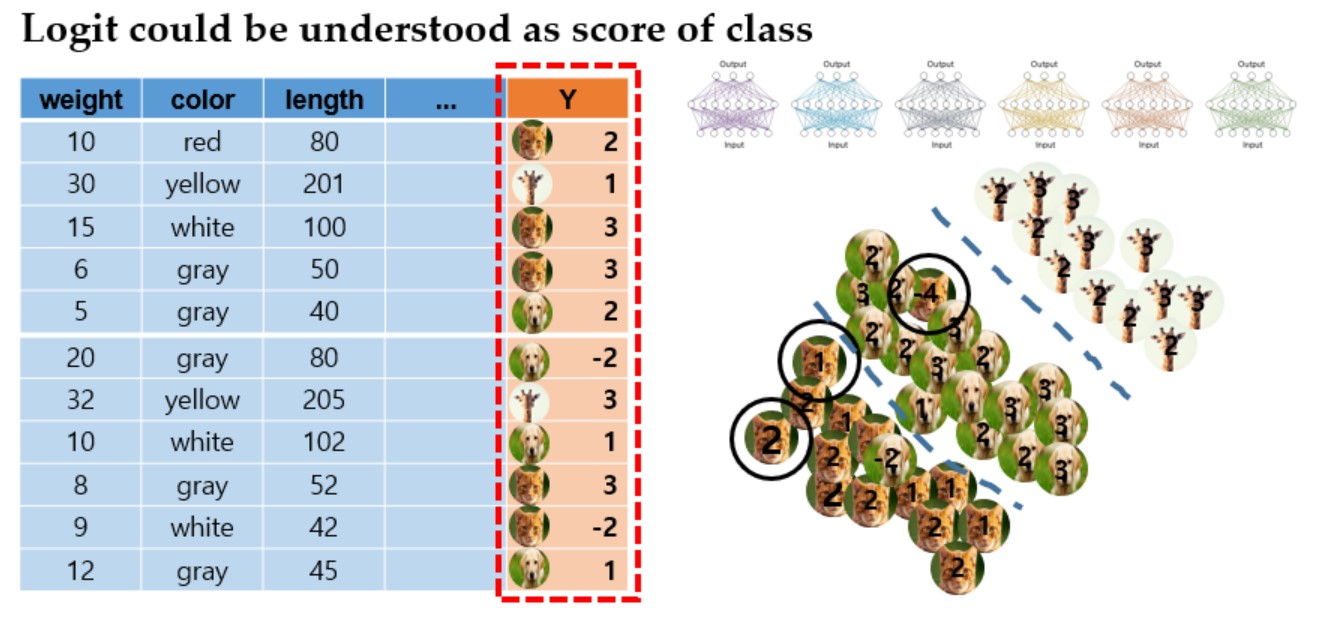
- Logit은 클래스의 점수로, 이 점수를 학습 시에 같이 고려하여 class의 확률분포를 보게 됨
여기서 logit 이란?
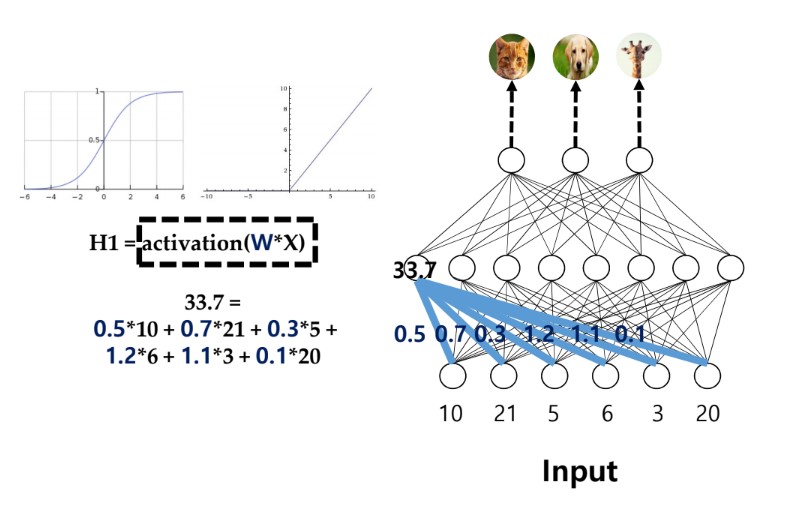
- Neural net에서 input이 입력되었을 때, 이들에 대한 weighted sum을 해서 hidden layer의 점수를 계산
- 이 weighted sum이 sigmoid나 ReLU와 같은 activation function을 지나 hidden layer 각각의 node의 점수가 계산됨
- Sigmoid 는 0에서 1 사이의 값을, ReLU는 음수인경우 0을, 나머지는 해당 값 그대로 출력
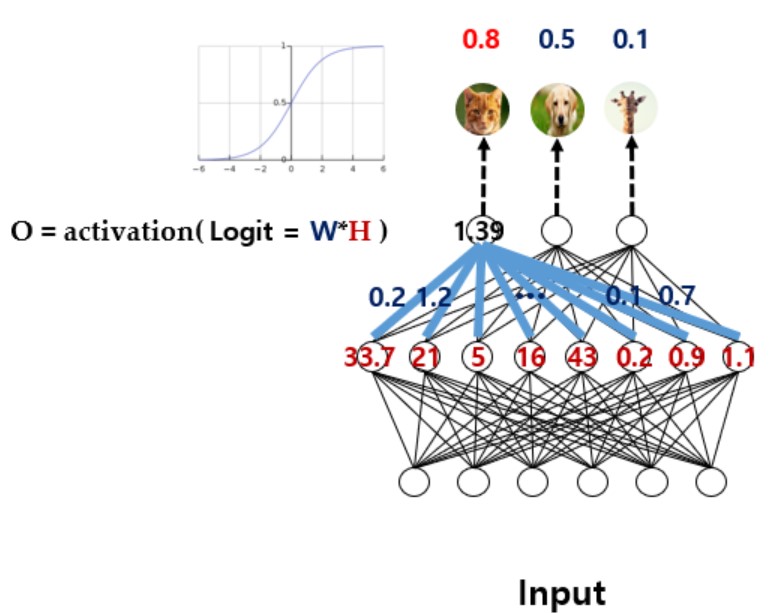
- 이렇게 계산된 점수를 이용해 다시 weighted sum을 하여 logit을 구하게 되고(1.39 위치의 값들)
- 거기에 Sigmoid와 같은 activation function을 거쳐서 나온 결과로 최종 class를 추론하게 됨
- 위의 사진에선 고양이의 확률이 0.8로 가장 높기때문에 고양이로 추론된다.
- 위 사진에서 최종 추론 결과 이전에 1.39의 위치에 있는 값들을 logit이라고 한다.
- 이 logit은 해당 클래스의 분포를 잘 따르면 큰 수가, 잘 따르지 못하면 작은 수(음수까지)가 나온다.
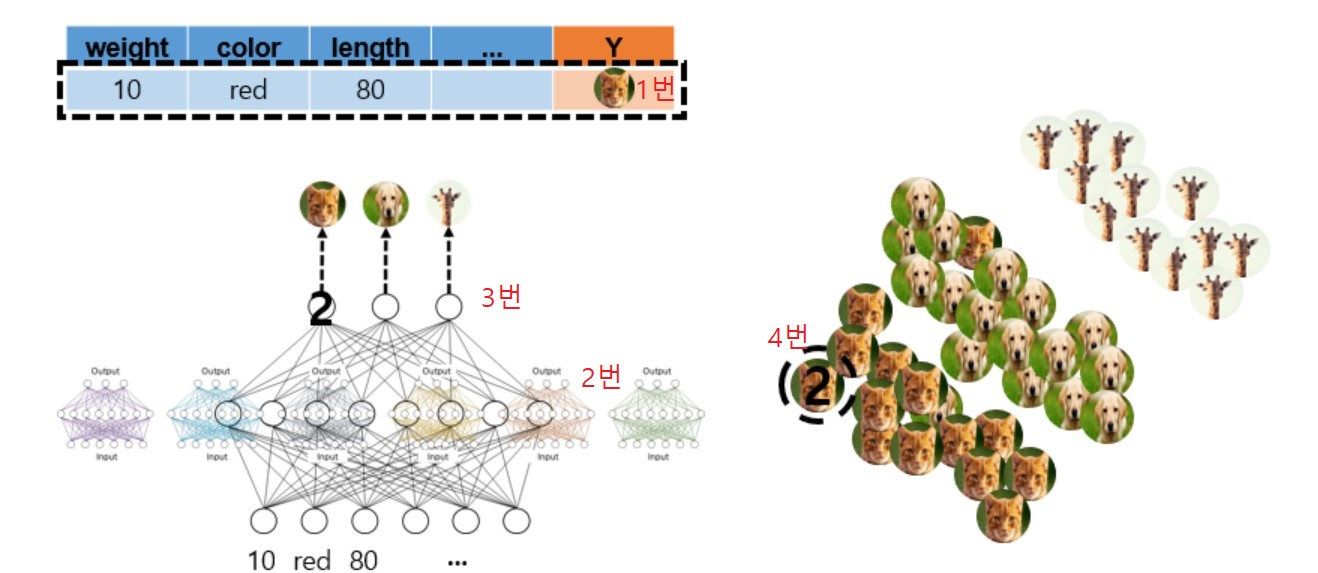
- 위 그림에서
- 1번: 우선 네트워크에 input 값이 들어갔을 때
- 2번: 앙상블 네트워크에서 계산을 하여
- 3번: 앙상블 네트워크에서 logit 값을 구해서
- 4번: 이 logit 값을 Y로 대신 사용하게 된다
- 즉, 동일한 input이 미리 학습 된 앙상블 모델과 학습되지 않은 single shallow model에 들어갔을 때, 앙상블 모델에서 생성해내는 logit 값들대로 single shallow model이 만들어내도록 single shallow model이 학습되는 것이다.
- 이렇게 될 경우 그냥 class 정보를 single shallow model이 training dataset만을 이용하여 단독 학습하는 경우보다 각 class의 점수를 알기 때문에(즉, 앙상블 모델이 출력하는 출력의 분포를 single shallow model이 따르게 된다) 더 많은 정보가 들어가 있게 되며, 이는 곧 class의 확률 분포를 의미하게 된다.
Distillation method 3
- Method from: Sau, B. B., & Balasubramanian, V. N. (2016). Deep Model Compression: Distilling Knowledge from Noisy Teachers. arXiv preprint arXiv:1610.09650.
- 세 번째 방법으로, 위의 distillation method 2의 과정과 동일하지만 앙상블 모델의 logit 값에 약간의 noise 성분 $\epsilon$ 을 추가하여 single shallow model을 학습시키게 되면 더 성능이 좋아지게 된다.
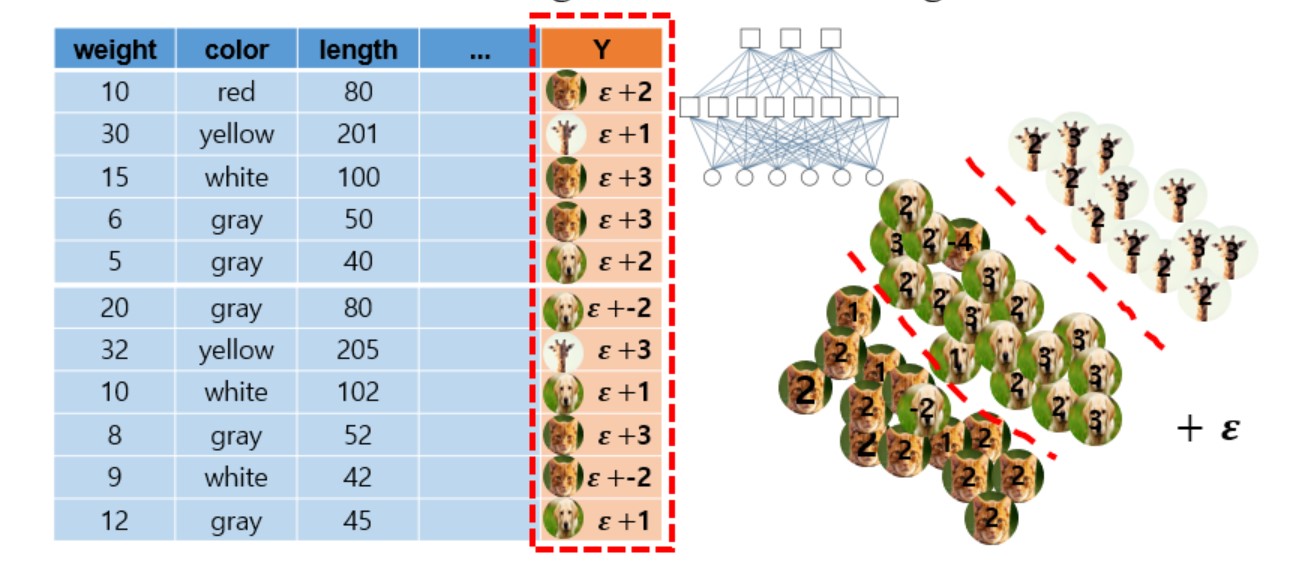
- Logit에 첨가되는 noise 성분 $\epsilon$ 이 regularizer의 역할을 해서 single shallow model의 학습 결과가 더 개선된다(정확도 향상)
- 앙상블 모델에 logit값과 noise값을 준 다음, 그것을 다시 single shallow model이 학습하게 된다.
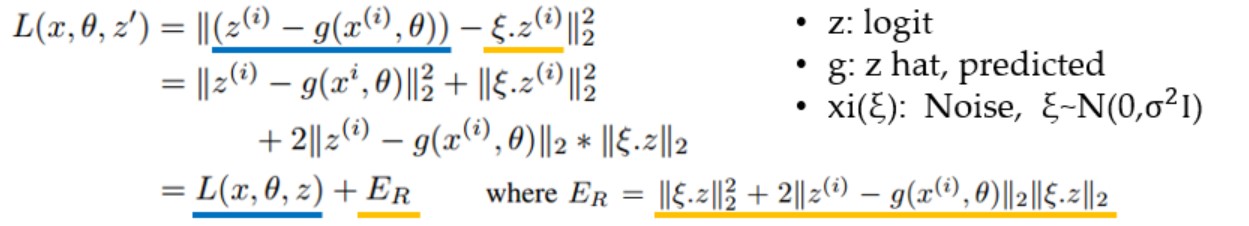
- 위 수식에서
- 좌측 상단의 파란 밑줄은 Error의 square값, 노란 밑줄은 logit값에 noise성분 $\epsilon$이 붙은 것을 의미
- 좌측 하단의 파란 밑줄은 Error의 제곱값, $E_{R}$은 나머지값이며 그 우측에 설명되는 $E_{R}$, 즉 나머지값이 결국 regularizer의 역할을 하게 된다.
Distillation method 4
- Method from: Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Hinton이 제안한 방법으로 본 논문에서 다루는 방법이다. 이 방법은 위의 방법들(method 2, 3)과 다르게 softmax를 사용한다.
- 핵심 아이디어
- 일반 training dataset으로 앙상블 모델을 학습시킨 후, 해당 dataset에 대한 결과 prediction에 대한 분포값을 얻는다.
- 이 과정에서 일반적인 neural network가 사용하는 softmax와는 다르게 temperature parameter(customized)를 적용하여 일반적인 softmax가 가장 높은 확률을 1, 나머지는 0으로 one-hot encoding 형식(hard target)으로 만들어내는것과는 다르게 0과 1 사이의 실수값(soft target)을 생성하도록 한다.
- 학습된 앙상블 모델이 출력한 soft target의 분포를 single shallow model이 갖는 것을 목표로 학습 시킨다면, 앙상블 모델이 학습한 지식을 충분히 generalize해서 전달 할 수 있게 된다.
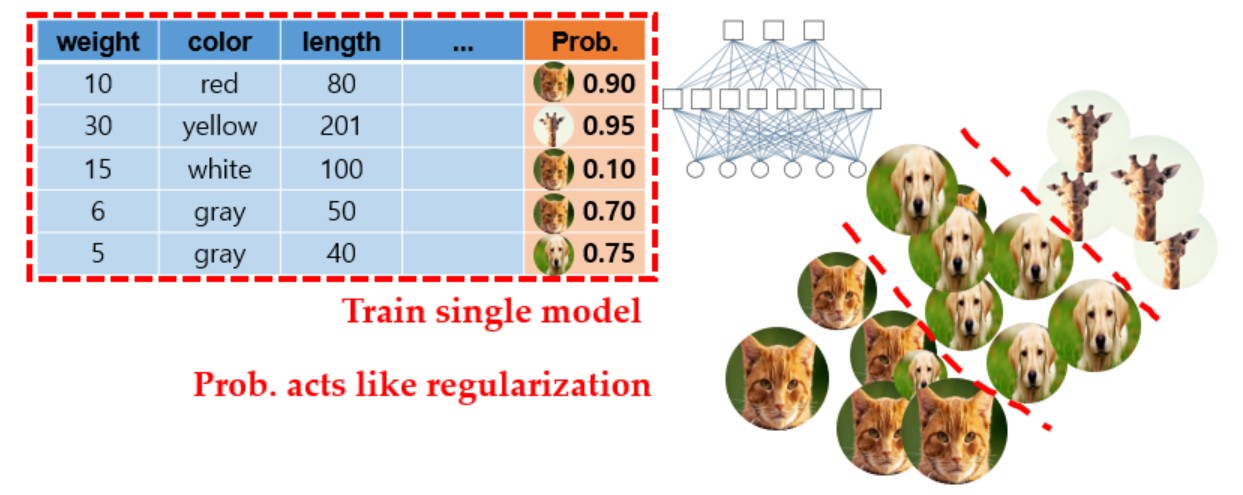
- 우선 갖고있는 training dataset으로 앙상블 모델을 학습시킨 후, softmax를 이용해서 class가 해당할 확률을 구한다.
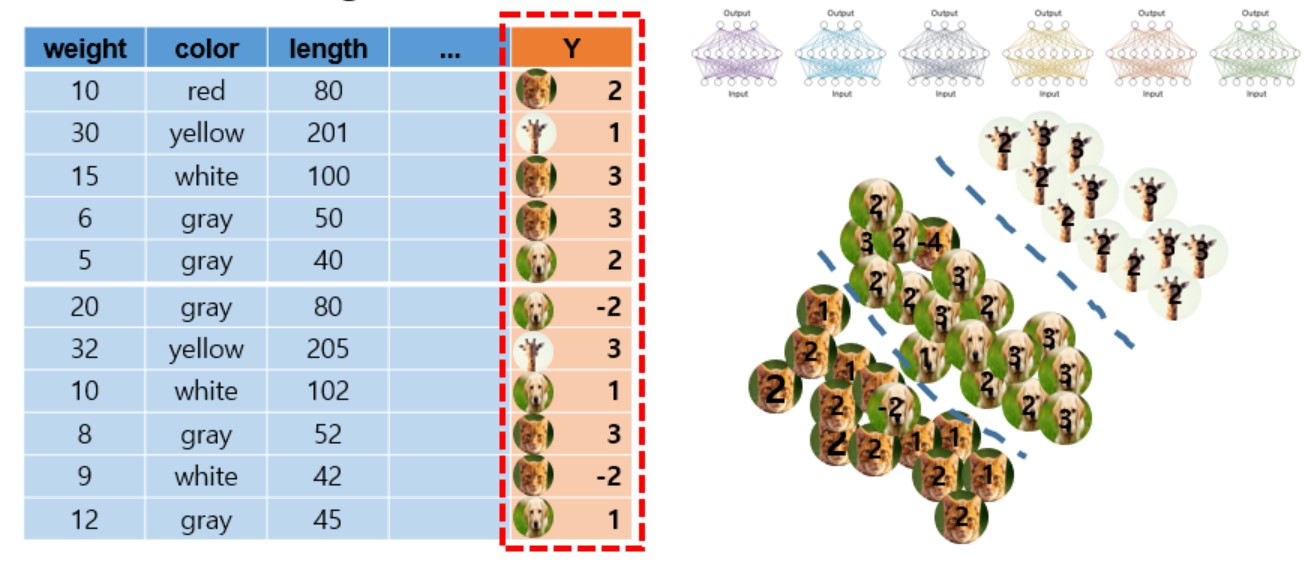
- 즉, 어떠한 관측치(새로운 데이터)가 들어갔을 때 앙상블을 통해서 softmax를 통한 확률값을 출력하게 된다.
- 위 그림에서 각 고양이, 개, 기린 사진의 크기가 각 관측치에 대한 확률을 의미한다.(크면 1에 가깝고 작으면 0에 가까움)
- 각 class별로 맨 아래 고양이가 많은 부분에선 고양이가 나올 확률이, 중간에선 개가 나올 확률이, 맨 위에선 기린이 나올 확률이 커지도록 single shallow model이 학습된다.
- 하지만 일반적인 학습과 다르게, class의 정보만을 맞추는게 아니라 앙상블 모델이 출력하는 각 data의 class 정확도 만큼 single shallow model이 학습하게 된다.
- 즉, 최종 정답인 label 정보 외에도 앙상블 모델이 만들어내는 예측결과의 확률 분포를 따르도록 single shallow model이 학습된다.
- 이 과정에서 각 확률을 구할땐 temperature 파라미터가 추가된 softmax activation function을 사용한다.
- 이렇게 앙상블 모델이 만들어내는 확률분포를 따르도록 single shallow model이 학습하게 되면 앙상블 모델의 정보가 single shallow model로 전달되게 된다.
- 앙상블 모델이 계산하는 확률값을 이용하여 single shallow model이 학습되는 것이 regularization의 역할을 하게 됨
- 즉, 어떠한 관측치(새로운 데이터)가 들어갔을 때 앙상블을 통해서 softmax를 통한 확률값을 출력하게 된다.
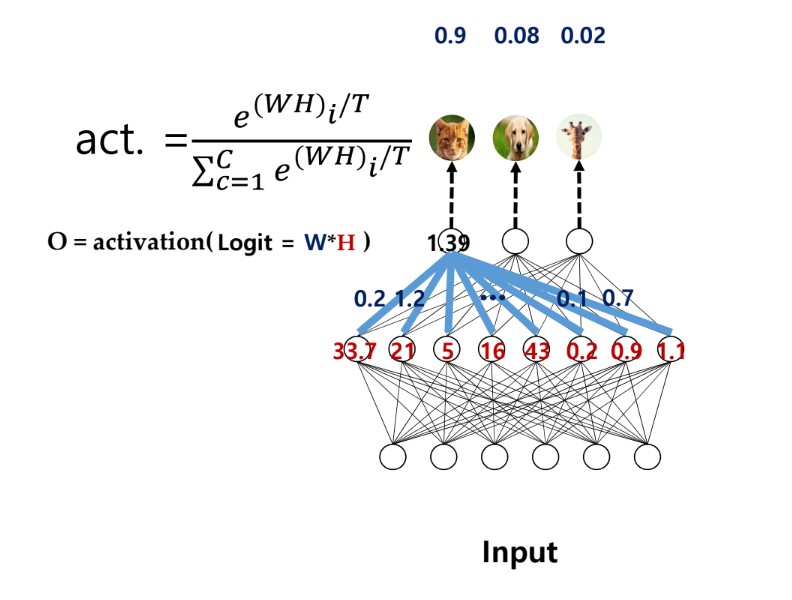
- 일반적으로, Softmax는 네트워크의 최종 output 계산시 logit 값에 적용되는 activation function으로 적용되며, 그 결과 가장 큰 logit을 갖는 node의 출력을 1과 매우 가까운 값으로, 나머지를 0에 매우 가까운 값으로 매핑하여 출력하게 된다.
- 또한, softmax의 특징으로 모든 추론 결과(softmax로 매핑된 각 node의 출력 값들)의 확률변수를 더하면 1이 된다. (위의 사진에서, 0.9 + 0.08 + 0.02 = 1)
- Sigmoid 또한 logit의 값을 확률변수로 만들어주지만 sigmoid로 매핑된 각 node의 출력 값들의 합은 1이 아니기때문에 class의 확률분포로 보기 어렵다.
- 따라서 확률분포를 이용하기 위해 모든 activation function으로 매핑된 각 node의 결과값들의 합이 1이 되는 softmax를 이용해야 하지만, 매핑된 값들의 분포가 하나만 1에 너무 가깝고 나머진 0에 너무 가까우므로 크게 의미가 있지 않다.
- 이를 해결하기 위해 일반적인 softmax가 아닌, Temperature parameter T 가 추가된 변형된 softmax를 activation function으로 사용한다.
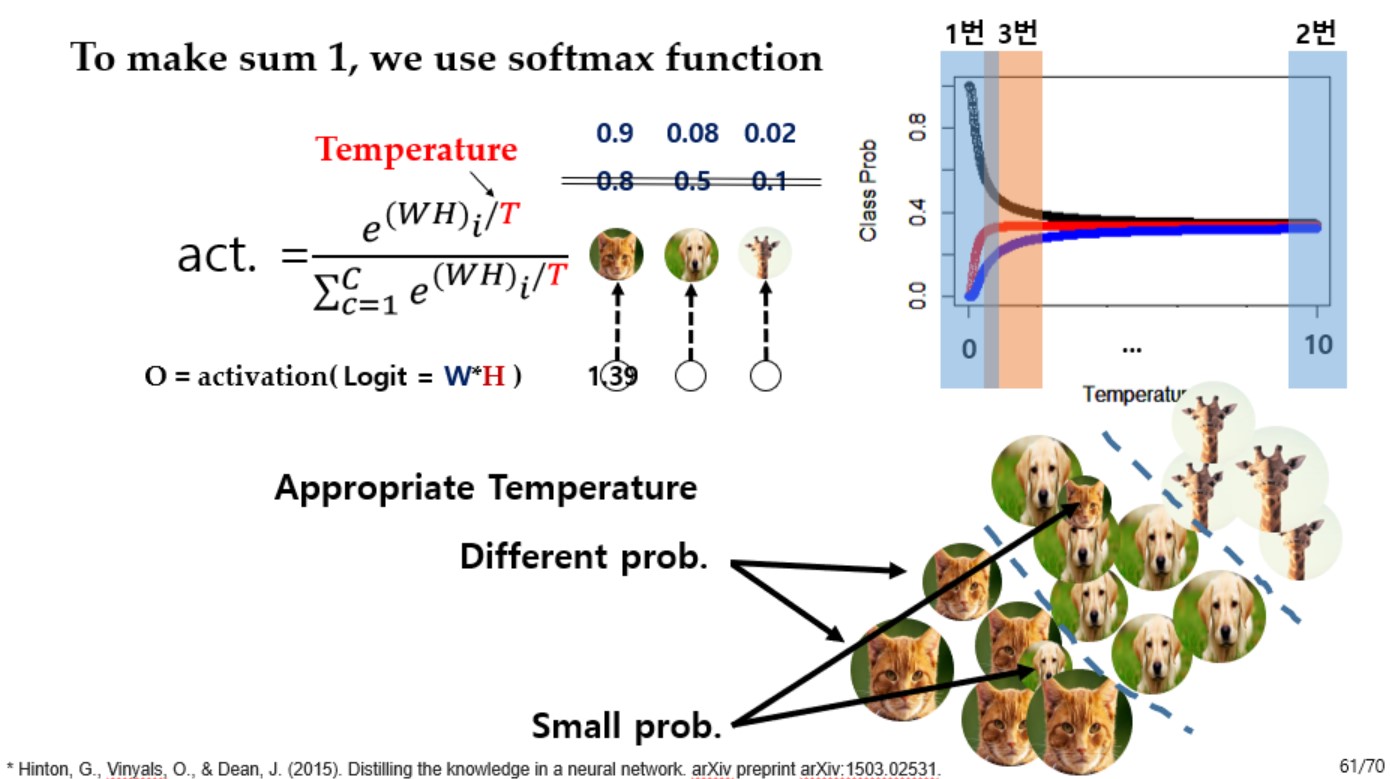
- 일반적인 softmax와 다르게 temperature parameter T가 들어있으며, T값에 따라 출력의 분포가 달라지게 된다.
- 1번: T가 작은 경우 logit 값이 큰 값에 대해 확률값이 아주 크게(1에 매우 가깝게), 작은 값에 대해 확률값이 아주 작게(0에 매우 가깝게) 출력된다. (T가 0인경우는 일반적인 Softmax와 동일하다)
- T가 1번 위치에 있는 경우(T가 1일때는 일반적인 softmax임) 확률값이 큰 class가 1의 확률이 들어가 앙상블 모델이 출력하는 구체적인 확률분포를 알 수 없게된다.
- 이로인해 T=1인 기존의 softmax를 사용하면 앙상블 모델의 출력의 확률 분포를 구체적으로 알 수 없으며, Hinton의 논문에선 T로 2~5 사이의 값을 사용하게 된다.
- 적절한 T의 값은 실험적으로 알아봐야 한다.(구체적인 이유가 없음)
- 2번: T가 매우 큰 경우 모든 관측치들이 같은 확률값을 갖게 된다.
- 즉, 3개의 class가 있을 때 모든 추론 결과가 0.33의 확률을 갖게 되므로 올바른 추론을 할 수 없게된다.
- 3번: 따라서 3번과 같이 적절한 T의 값을 선택해서 사용하여야 하며 이를 이용하여 class간의 분포를 알아낼 수 있게 된다.
- 적절한 T를 구하는것은 모든 case에 대해 T=0부터 10까지 실험을 해 봐야 한다.
- T가 적당하다면 오탐되는 경우에 대해(위 사진에서 우측 하단의 Small prob) 각각 확률이 작다는 추가 정보를 얻을 수 있게 된다.
- 1번: T가 작은 경우 logit 값이 큰 값에 대해 확률값이 아주 크게(1에 매우 가깝게), 작은 값에 대해 확률값이 아주 작게(0에 매우 가깝게) 출력된다. (T가 0인경우는 일반적인 Softmax와 동일하다)
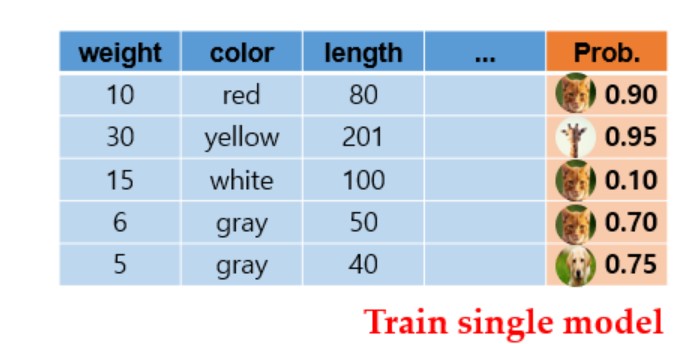
- 이렇게 앙상블 모델에서 얻은 각 출력에 대한 확률분포 정보를 추가하여 single shallow model을 학습시키게 된다.
Loss function의 생성 과정
- 위 방법을 적용시킨 classification 모델의 학습에 대해 다음의 Cross Entropy loss function을 사용한다.
- Cross Entropy loss: $Loss\; function=-\sum_{k=1}^{|V|}q(y=k|x;\theta_{T})\times log P(y=k|x;\theta)$
- $q$: Probability of softmax with Ensemble model
- $P(y=k|x;\theta)$: Probability of single model
- $k$: Class index
- $|V|$: Total number of class
- 논문에서는 아래의 Objective function을 maximize되도록 네트워크를 학습시킨다.
- $Obj.(\theta)=+\prod_{k=1}^{|V|}1{y=k}\times p(y=k|k;\theta)$
- $1{y=k}$: Indicator of true class, 추론 결과가 맞으면 1, 아니면 0을 반환한다.
- $p(y=k|k;\theta)$: Predicted probability of true class(our model), true class가 주어졌을 때 추론 결과가 최대한 높은 확률로 추론하게 하는 모양
- 이 $Obj.(\theta)$ 함수를 음수로 만들어 loss function(cost function)을 만든다.
- $Cost(\theta)=-\prod_{k=1}^{|V|}1{y=k}\times p(y=k|k;\theta)$
- 하지만 이 형태는 확률이 계속 곱해지는 형태로 결국 1보다 작은 값들이 계속 곱해질 수 밖에 없는 구조로 무조건 0에 수렴하게 된다.
- 이를 해결하기 위해 곱해지는 부분에 log transform을 적용하여 곱하기 연산을 덧셈 연산으로 변형한다.
- $Cost(\theta)=-\sum_{k=1}^{|V|}1{y=k}\times log p(y=k|k;\theta)$
- 여기서 $1{y=k}$ 부분이 temperature가 적용된 softmax로 구한 확률값으로 대채하여 loss function을 완성한다.
- Loss function: $Cost(\theta)=-\sum_{k=1}^{|V|}q(y=k|x;\theta_{T})\times log p(y=k|k;\theta)$ (위와 동일)
- $q$: Probability of softmax with Ensemble model
- $P(y=k|x;\theta)$: Probability of single model
- $k$: Class index
- $|V|$: Total number of class
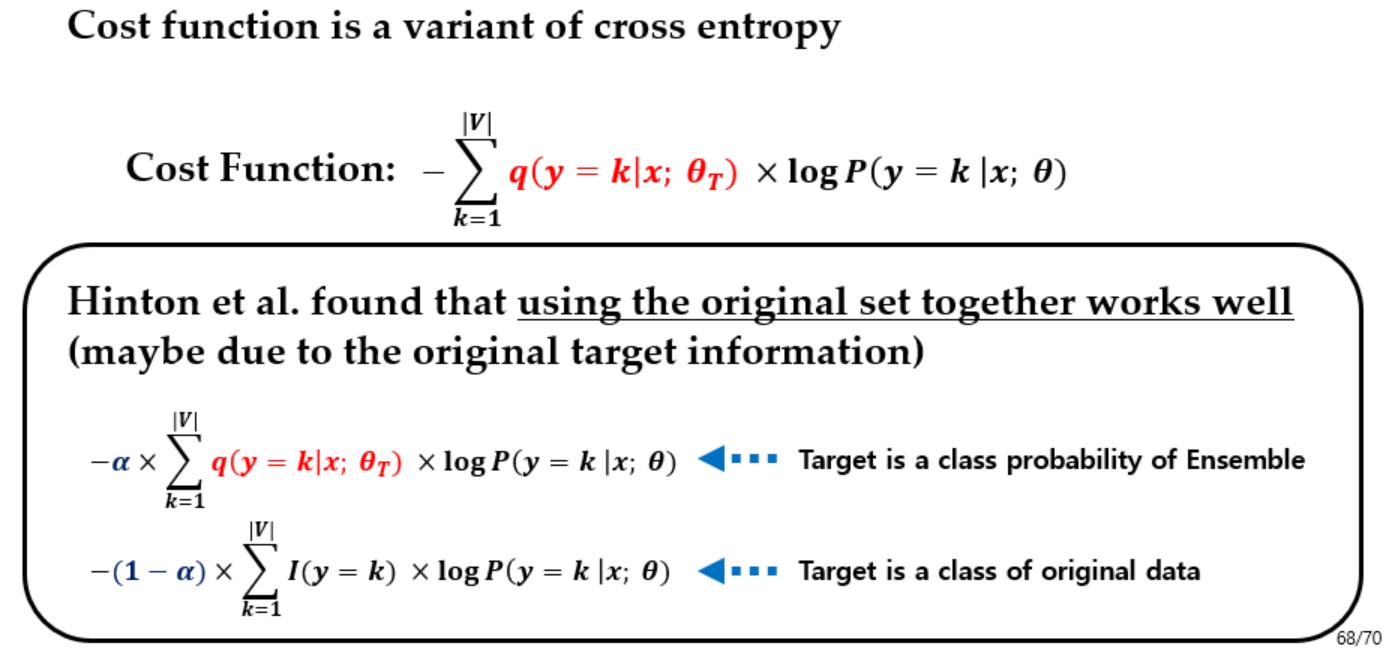
- 또한 성능을 높히기 위해 위에서 생성한 loss function과 일반적인 cross entropy loss function을 섞어 위의 사진처럼 사용한다.
- 해당 비율을 정하는 parameter는 $\alpha$ 이며, 실험적으로 논문에서는 0.5를 사용하였을 때 결과가 가장 좋았다고 한다.

- 1번 실험 결과, 앙상블 및 DropOut이 적용된 모델에 비해 위의 distillation method 4가 적용된 모델이 비슷한 test error를 갖는 것을 알 수 있다.
- 1번 실험 결과에서 일반적인 학습의 경우 146개의 test error를 보이는데 반해 distillation method 4가 적용된 경우 앙상블모델의 67 test error와 비슷한 74 test error를 보이며 성능이 상당히 개선 된 것을 확인 가능하다.
- 2번 실험 결과, 일반적인 Baseline case에 비해 distillation method 4가 적용된 모델이 앙상블모델과 거의 비슷한 정확도로 speech recognition을 수행한 것을 확인 할 수 있다.
Conclusion
- 결국 앙상블 모델의 정보 또한 shingle shallow network로 이전이 가능하다
-
이는 인공 data에 앙상블 모델을 이용하여 labeling을 하거나 soft target을 이용하여 가능해지며, 그 결과 성능 개선과 더불어 single shallow model을 사용하므로 연산량이 줄어들게 된다.
- 논외로, 최근 논문에선 softmax로 확률분포를 구하는 distillation method 4보단 logit값으로 앙상블 모델이 추론하는 확률분포를 single shallow model로 전달하는 distillation method 2, 3의 방법을 적용한것이 결과가 더 좋았다는 논문도 존재한다.
- 실험적으로 distillation method 4의 T나 $\alpha$를 노가다로 계산하는것보단 method 2, 3을 사용하는것이 효율적일것으로 사료된다.