1단계: head가 가리키는 dummy node의 next가 [4, new]를 가리키도록 함
2단계: [4, new]의 prev가 head가 가리키는 dummy node를 가리키도록 함
3단계: [2, old] 노드를 삭제하고 삭제된 값을 반환
위의 조건을 바탕으로 ADT의 동작코드인 DBLinkedList.c를 작성하면 아래와 같다
#include <stdio.h>
#include <stdlib.h>
#include "DBLinkedList.h"
// 초기화 함수 정의voidListInit(List*plist){plist->head=(Node*)malloc(sizeof(Node));// head 포인터에 더미노드 연결plist->tail=(Node*)malloc(sizeof(Node));// tail 포인터에 더미노드 연결plist->head->prev=NULL;// head가 가리키는 dummy node의 prev는 NULL로 초기화(맨 앞이므로 prev는 없음)plist->head->next=plist->tail;// head가 가리키는 dummy node의 next는 tail이 가리키는 dummy node를 가리키도록 초기화plist->tail->prev=plist->head;// tail이 가리키는 dummy node의 prev는 head가 가리키는 dummy node를 가리키도록 초기화plist->tail->next=NULL;// tail이 가리키는 dummy node의 next는 NULL로 초기화(맨 마지막이므로 next는 없음)plist->numOfData=0;// 주어진 리스트의 유효 데이터의 갯수를 0으로 초기화(더미노드는 유효 데이터가 아님)}// 새 노드를 연결하는 함수(값의 추가)voidLInsert(List*plist,Datadata){Node*newNode=(Node*)malloc(sizeof(Node));// 새 노드를 정의(동적할당)newNode->data=data;// 새 노드에 값을 넣음// 새 노드는 맨 마지막에 추가되도록 해야 함(tail이 가리키는 dummy node의 바로 앞)newNode->prev=plist->tail->prev;// 새 노드의 prev가 기존에 tail이 가리키던 dummy node의 prev가 가리키던 노드가 되도록 초기화([2, old])plist->tail->prev->next=newNode;// tail이 가리키는 dummy node의 prev가 가리키던 node([2, old])의 next가 새 노드를 가리키도록 초기화newNode->next=plist->tail;// 새 노드의 next는 tail이 가리키는 dummy node를 가리키도록 초기화plist->tail->prev=newNode;// tail이 가리키던 dummy node의 prev는 새 노드를 가리키도록 초기화(plist->numOfData)++;// 유효 데이터의 갯수 1개 증가}// 데이터의 첫 번째 참조intLFirst(List*plist,Data*pdata){if(plist->head->next==plist->tail)// 유효 데이터가 하나도 저장되어있지 않은 초기상태일 경우returnFALSE;plist->cur=plist->head->next;// cur 포인터가 head가 가리키는 dummy node의 next를 가리키는 노드가 되도록 초기화 ([2, old])*pdata=plist->cur->data;// 해당 포인터가 가리키는 노드의 data의 주소로 초기화returnTRUE;}// LFirst와 동일하나 cur 포인터변수를 이용하여 동작.intLNext(List*plist,Data*pdata){if(plist->cur->next==plist->tail)returnFALSE;plist->cur=plist->cur->next;*pdata=plist->cur->data;returnTRUE;}// LNext와 동일하지만 이전 값을 참조하게끔 설정된다intLPrevious(List*plist,Data*pdata){if(plist->cur->prev==plist->head)returnFALSE;plist->cur=plist->cur->prev;*pdata=plist->cur->data;returnTRUE;}intLCount(List*plist){returnplist->numOfData;}// 데이터의 삭제과정DataLRemove(List*plist){Node*rpos=plist->cur;// 삭제 할 노드의 주소를 rpos로 초기화 (주어진 리스트의 cur 포인터가 가리키는 노드가 삭제됨)Datarm=rpos->data;// 삭제 할 노드의 data를 rm에 초기화plist->cur->prev->next=rpos->next;// cur포인터가 가리키는 노드의 prev가 가리키는 노드의 next(head가 가리키는 dummy node의 next) 를 지울 노드(cur)의 next와 연결plist->cur->next->prev=rpos->prev;// cur표인터가 가리키는 노드의 next가 가리키는 노드의 prev([4, new])를 지울 노드의 이전 노드와 연결(head가 가리키는 dummy node)plist->cur=plist->cur->prev;// cur의 위치를 한칸 앞으로 당겨줌(cur가 가리키는 노드는 head가 가리키는 노드와 동일하게 됨)free(rpos);// 메모리 해제(plist->numOfData)--;// 데이터 수 감소returnrm;// 삭제된 데이터 반환}
전체적으로 보면 복잡해보이지만, 문제를 쪼개고 하나의 일반적인 예시를 들어 관계를 풀어나가면 쉽게 이해되고 풀기 용이해진다!
S$^{3}$FD: Single Shot Scale-invariant Face Detector (간단히)
Original paper: https://arxiv.org/pdf/1708.05237.pdf
Authors: Shifeng Zhang Xiangyu Zhu Zhen Lei* Hailin Shi Xiaobo Wang Stan Z. Li
Codes: Google에 s3fd github 치면 많이 나옴
Abstract
본 논문에서는 Single Shot Scale-invariant Face Detector (S3FD)라 불리는 real-time face detector를 제안한다. S3FD는 다양한 face scale에 대하여 단일 deep neural network를 사용하여 face detection을 수행하며, 특히 작은 얼굴을 잘 찾는다. 특히, 본 논문에서는 anchor based detector들이 object가 작은 경우 성능이 급격히 나빠지는 일반적인 문제를 해결하려고 시도하였다. 본 논문에서는 다음의 3 가지 측면에 대한 기여를 하였다.
1) 다양한 scale을 갖는 얼굴에 대한 처리(detection)를 잘 하기 위해 scale-equitable(공정한) face detection framework를 제안한다. 논문에선 모든 scale의 face들에 대해 detection이 충분히 가능하도록 layer의 넓은 범위에 anchor를 바둑판 식으로 배열한다. 게다가 논문에선 효과적인 receptive field와 논문에서 제안하는 equal proportion interval principle(동등 비례 간격 원칙)에 따라 anchor scale을 재 디자인했다.
2) 작은 얼굴들에 대한 recall rate를 높히기 위해 scale compensation(보상) anchor matching strategy를 적용했다.
3) Max-out background label을 통하여 작은 얼굴들에 대한 false positive rate를 줄였다.
위의 결과로써, 논문에서 제안하는 모델은 AFW, PASCAL face, FDDB, WIDER FACE dataset의 common face detection benchmark에 대해 SOTA detection 성능을 얻었으며 VGA-resulution image에 대해 Nvidia Titan X(Pascal)에서 36FPS로 작동 가능하다.
4. Experiments
본 섹션에선 scale-equitable framework, scale compensation anchor matching strategy, max-out background label에 대한 효과를 확인하며, 최종 모델의 common face detection benchmark를 수행한 후 inference time에 대해 다룬다.
4.1. Model analysis
논문에선 WIDER FACE validation set을 이용한 다양한 실험을 통해 제안하는 모델을 분석했다. WIDER FACE validation set은 easy, medium, hard subset을 갖고 있으며, 대략적으로 각각 크고, 중간, 작은 크기의 얼굴들을 갖고 있다. 이 benchmark는 논문에서 제안하는 모델을 평가하기 적절하다.
Baseline. 논문에서 제안하는 방법들의 contribution들의 평가를 위해 몇 가지 baseline에 따른 비교실험을 수행했다. 제안하는 S3FD는 RPN[38]과 SSD[26]에서 영감받아졌으며 두 face detector들을 그대로 baseline으로 학습시키기 위해 사용했으며 이름을 각각 RPN-face와 SSD-face로 marking했다. [38]과는 다르게 RPN-face는 VGG16의 conv5_3 layer에 정사각형모양의 (16, 32, 64, 128, 256, 512) 6개 scale을 갖는 anchor를 붙여 비교를 보다 견고하게 만들었다. SSD-face는 기본 SSD의 구조와 anchor 세팅을 따랏다. 나머지 것들은 논문에서 제안하는 S3FD와 동일하다.
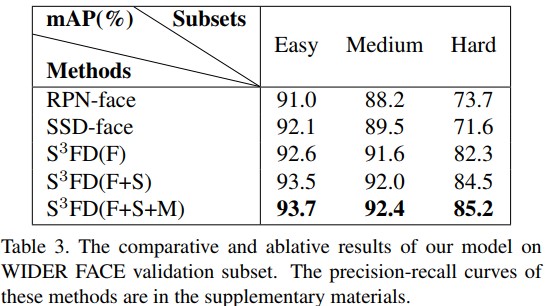
Ablative Setting. S3FD를 더 잘 이해하기 위해 각각의 제안하는 component가 최종 성능에 영향을 끼치는지 평가하기 위해 ablation experiment를 수행했다. 실험에선 세 가지 다른 세팅에 대한 실험을 수행했다. 1) S3FD(F): 이 모델은 scale-equitable framework만을 사용한다(constructed architecture and designed anchors). 그리고 다른 두 조건을 제거한다. 2) S3FD(F+S): 이 모델은 scale-equitable framework와 scale compensation anchor matching strategy를 적용한다. 3) S3FD(F+S+M): 이 모델은 모든 제안하는 방법에 다 적용된 모델로, scale-equitable framework와 scale compensation anchor matching strategy, 그리고 max-out background label이 적용된 모델이다. 각 실험 결과는 Table 3에 나와있다.
Table 3. 비교 조건에 대한 WIDER FACE validation subset의 실험 결과. 각 방법에 대한 precision-recall curve는 supplementary materials 섹션에 있다.
4.2. Evaluation on benchmark
제안하는 S3FD 모델에 대한 AFW[63], PASCAL Face[52], FDDB[13], WIDER FACE[56]을 이용한 평가를 진행한다. 몇 실험 결과는 supplementary materials에 실려있다.
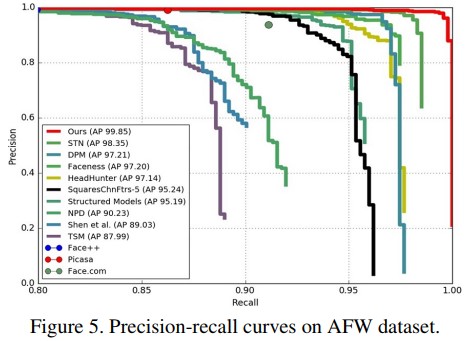
AFW dataset. 이 데이터셋은 205장의 이미지와 473개의 레이블된 얼굴이 존재한다. 논문에선 잘 알려진 몇 방법과 논문에서 제안하는 방법의 실험 결과를 비교한다. 여기엔 몇몇의 commercial face detector들이 포함되어있다. 실험 결과는 Figure 5에 실려있으며, S3FD의 성능이 크게 좋다.
Figure 5. AFW 데이터셋에 대한 Precision-recall curve
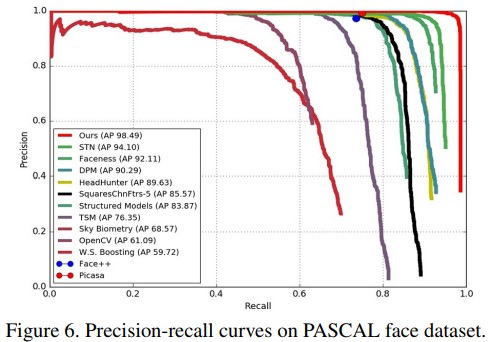
PASCAL face dataset. 이 데이터셋은 1,335 개의 레이블링된 얼굴들이 851개의 이미지에 저장되어 있으며, 다양한 face appearance와 pose variation이 존재한다. 이 데이터셋은 PASCAL test 데이터셋의 person label에서 얻어졌다. Figure 6에서 실험 결과가 나오며, 다른 방법들에 비해 제안하는 모델이 더 좋은 성능을 보인다.
Figure 6. PASCAL face 데이터셋에 대한 Precision-recall curve
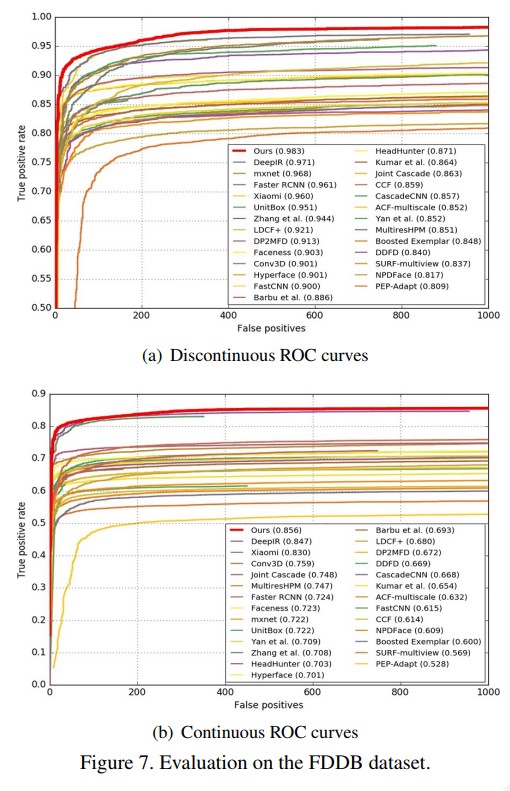
FDDB dataset. 이 데이터셋은 5,171개의 얼굴이 2,845개의 영상에 저장되어 있다. 여기엔 두 개의 evaluation 문제가 존재한다. 1) FDDB는 F3SD가 사각형의 bounding box를 출력하는것과 달리 타원형의 ground truth를 갖는다. 이러한 불일치로 인해 continuous score에 지대한 영향을 미치며, 따라서 논문의 모델이 bounding box가 아닌 타원형 bounding을 치도록 regressor를 학습시켰다. 2) FDDB는 많은 unlabelled face를 가지므로, 그 결과 많은 false positive face가 있더라도 높은 점수가 나오게 된다. 따라서 논문에선 수동적으로 실험 결과를 review하고, 238개의 unlabeled face를 추가했다. 마지막으로 제안하는 모델을 다양한 SOTA 모델들에 대해 실험을 진행했다. 그 결과는 Figure 7(a)와 (b)에서 보여진다. 제안하는 S3FD는 SOTA 성능을 달성했으며 모든 다른 모델에 비해 큰 차이로 좋은 성능을 보이고 ROC curve를 나타낸다. 이것은 제안하는 S3FD가 얼굴의 제한 없이 robust함을 의미한다.
Figure 7. FDDB dataset에 대한 평가 결과
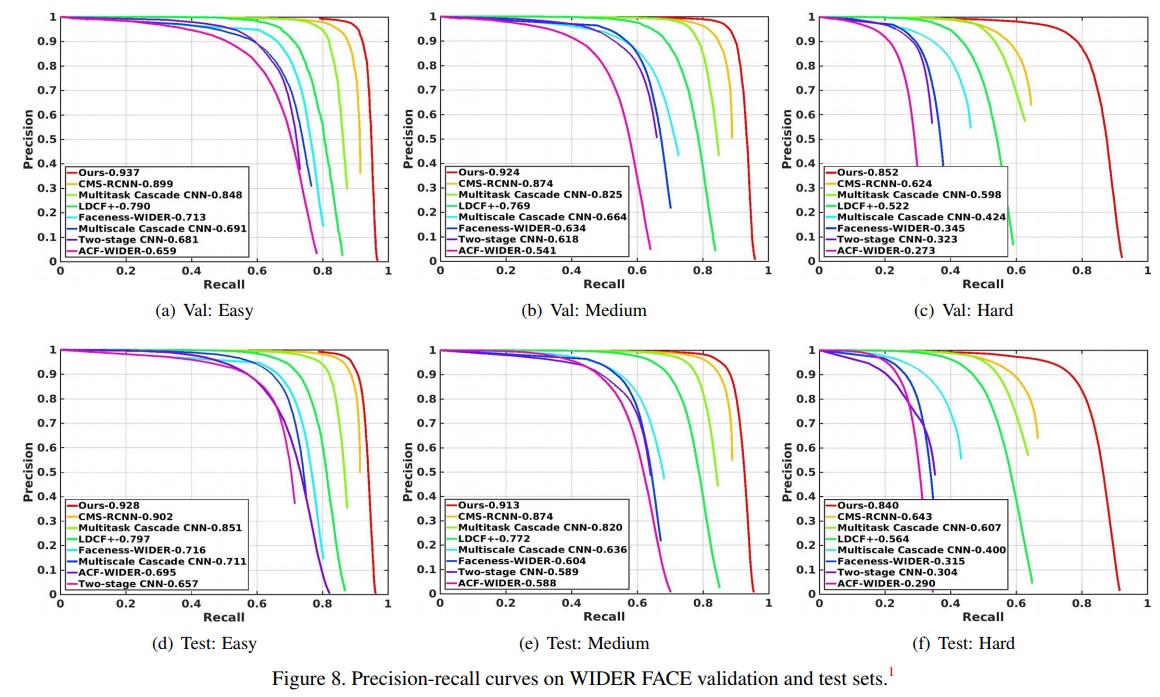
WIDER FACE datset. 이 데이터셋은 32,203개의 이미지에 393,703개의 레이블링된 얼굴이 존재하며 높은 회전각이나 다양한 scale, pose, occlusion을 포함한다. 데이터셋은 40%의 training, 10%의 validation, 50%의 testing 데이터셋으로 이루어져있다. 게다가 이미지들은 3 개의 level로 나뉘어있다. (Easy, medium, hard). 이는 detection의 어려움에 따른 분류다. 학습과 validation 셋은 온라인에서 접근 가능하나 test셋은 결과가 서버로 보내져 채점되어 돌아온 precision-recall curve를 분석하여 이용 가능하다. S3FD는 training 셋에서만 학습되었고 validation 셋과 test셋 모두에서 평가되었으며, 다양한 face detection 방법들과 함께 평가되었다. Precision-recall curve와 mAP는 Figure 8에서 보여진다.
Figure 8. WIDER FACE validation and test set에 대한 precision-recall curve
제안하는 모델이 큰 차이로 다른 모델들을 제쳤으며, 특히 small face에 대한 실험 결과가 좋다. 각각 0.937 (Easy), 0.924 (Medium) and 0.852 (Hard) for validation set, and 0.928 (Easy), 0.913 (Medium) and 0.840 (Hard) for testing set의 실험 결과를 보인다. 이는 제안하는 방법의 유효성 뿐만 아니라 제안하는 방법이 작고 찾기 어려운 얼굴을 잘 찾는다는 것을 증명한다.
4.3. Inference time
Inference 동안 제안하는 모델은 많은 box들을 출력한다.(VGA 해상도 이미지에서 25,600개의 박스). Inference time을 가속화하기 위해 대부분의 박스들을 0.05의 confidence threshold로 필터링 하고, NMS를 적용하기까지 400개의 box를 남긴다. 다음으로 NMS를 jaccard overlap이 0.3일 때로 수행하며 200개의 박스를 남긴다. 실험은 Titan X(Pascal), cuDNNv5.1, Intel Xeon E5-2683v3@2.00GHz에 대한 시간을 측정하였다. VGA 해상도 영상에 대해 batch size가 1이고 단일GPU를 사용할 때, 제안하는 모델은 36FPS로 동작하였으며 실시간 동작이 가능하다. 게다가 80%가량의 forward time이 VGG16 네트워크에서 소모되므로, 더 빠른 네트워크를 사용 할 경우 속도를 더 향상 시킬 수 있을 것이다.
5. Conclusion
본 논문에서는 새로은 face detector를 소개하고, 일반적인 anchor based detection method의 문제인 작은 객체를 잘 찾지 못하는 것을 해결하였다. 논문에선 문제의 이유를 측정하고 wide range of anchor-associated layer를 갖고 다양한 크기의 얼굴을 잘 다룰 수 있는 합리적인 scale의 anchor들을 포함하는 scale-equitable framework를 제안하였다. 게다가 논문에선 작은 얼굴들의 recall rate를 높이기 위해 scale compensation anchor mathing strategy를 제안하였으며, 작은 얼굴들에서 false positive rate를 줄이기 위한 max-out background label을 제안하였다. 실험은 위의 세 방법을 포함하는 S3FD의 효과를 증명했으며 그 결과 여러 SOTA의 성능을 다양한 common face detection benchmark에 대해 크게 성능을 앞질렀다. 향후 연구에서, 저자들은 background patch들의 classification strategy를 향상시킬 예정이다. 이러한 background class를 어떠한 sub-category로 나누는 것은 향후 연구에 적용할 가치가 있다.
A Fast and Accurate System for Face Detection,Identification, and Verification (Face detection에 대해서만)
Original paper: https://arxiv.org/pdf/1809.07586.pdf
Authors: Rajeev Ranjan, Ankan Bansal, Jingxiao Zheng, Hongyu Xu, Joshua Gleason, Boyu Lu, Anirudh Nanduri, Jun-Cheng Chen, Carlos D. Castillo, Rama Chellappa
Abstract
많은 데이터셋과 컴퓨터의 연산능력 증가로 인해 CNN을 이용한 object detection, recognition benchmark의 성능이 향상됨. 이로 인해 딥러닝을 이용한 face detection의 성능이 많이 향상 됨. CNN을 이용해 얼굴을 찾을 수 있으며 landmark의 위치를 정의하고 pose나 얼굴 인식을 할 수 있다.
본 논문에서는 몇몇의 benchmark 데이터셋을 이용하여 SOTA face detection의 성능을 검증하고 몇몇 face identification에 대한 detail에 대해 다룸.
또한 새로운 face detector인 Deep Pyramid Single Shot Face Detector(DPSSD)를 제안한다. 이는 빠르고 face detection시 다양한 scale 변환에 유용하다. 논문에서 automatic face recognition에 관련된 다양한 모듈의 design detail을 설명하며, 이는 face detection, landmark localization and alignment, 그리고 face identification/verification을 포함한다.
논문에서는 제안하는 face detector를 이용하여 각종 데이터셋들에 대한 evaluation 결과를 제공하며, IARPA Janus Benchmarks A, B, C(IJB-A, B, C)와 Janus Challenge Set 5(CS5)에 대한 실험 결과를 제공한다.
1. Introduction
Facial analytics에 대한 많은 연구가 진행되어 있으며 이러한 연구는 law enforcement, active authentication on device, face biometrics for payment, 자율 주행차 등에 응용되어지고 있다. 또한 각종 dataset들의 등장으로 DCNN의 활용 가능성과 성능이 높아졌다.
본 논문에선 새로은 face detector를 제안하고, 이는 훨씬 빠르고 다양한 scale의 얼굴에 대해 탐지 결과가 좋다. 또한 현존하는 DCNN 기반 자동 face detection pipeline을 적용하여 SOTA 기술에 대해 좋은 결과를 보인다.
2. A brief survey of existing literature
본 챕터에서는 간단하게 현존하는 다른 방법을 사용하는 face identification/verification pipeline 모듈들에 대한 overview를 제시한다. 우선 최근의 face detection method에 대한 것을 다룬다. 다음으로 두 번째 모듈인 facial keypoint detection에 대해 고려한다. 마지막으로 feature learning에 관한 최근의 여러 연구에 대해 논하고 face verification과 identification에 대한 SOTA 연구들을 요약한다.
2.1 Face Detection
Face detection은 face recognition/verfication pipeline의 첫 번째 step이다. Face detection 알고리즘은 주어진 입력 영상에 대해 모든 얼굴들의 위치를 출력하며, 보통 bouning box 형태로 출력한다. Face detector는 pose, illumination, view-point, expression, scale, skin-color, some occlusions, diguises, make-up 등에 대한 변화요인으로부터 강건해야한다. 대부분의 최근 DCNN-based face detector들은 일반적인 object detection의 접근 방법으로부터 영감 받아졌다(inspired by). CNN detector 들은 두 개의 sub-category로 나뉘어지는데, 하나는 Region-base와 다른 하나는 Sliding window-based 방식이다.
Region-based 접근방식은 우선 object-proposal들을 생성하며 CNN classifier를 이용해 각각의 proposal을 분류하여 그것이 얼굴인지 아닌지를 판별한다. 첫 번째 step은 보통 off-the-shelf(기성품인) proposal generator인 Selective search[26] 을 사용한다. 최근의 다른 HyperFace[10] detector나 All-in-One Face[18]같은 경우 이러한 방법을 사용한다. Generic method를 이용하여 object proposal을 생성하는 방법 말고, Faster R-CNN[5]는 Region Proposal Network(RPN)을 사용한다. Jiang and Learned-Miller는 Faster-RCNN 네트워크를 face detect에 사용하였다[27]. 유사하게 [28]에서는 Faster-RCNN framework를 사용하여 mulit-task face detector를 제안하였다. Chen et al.[29]에서는 multi-task RPN을 face detection과 facial keypoint localization을 위해 학습 시켰다. 이로인해 낭비되어지는(너무 많이 제안되는) face proposal을 줄일 수 있었으며 그 결과 face proposal의 quality가 좋아졌다. Single Stage Headless face detector[7] 또한 RPN 기반이다.
Sliding window-based 접근방식은 주어진 scale에서의 feature map에서의 모든 location에서 얼굴을 탐지하여 출력한다. 이러한 detection 방식은 face detection score와 bounding box의 형태로 구성되어 있다. 이러한 접근방식은 proposal generation step으로 분리되어 있지 않으므로(한번에 detection) region-based 방식(2-step)에 비해 더 빠르게 동작한다(one-step). [9]나 [30]같은 경우 multiple scale에서 image pytamid를 생성하여 multi-scale detection을 수행한다. 유사하게 [31]에선 multiple resolution을 위한 cascade architecture을 사용한다. Single Shot Detector(SSD)[6] 또한 multi-scale sliding-window 기반의 object detector다. 하지만 multi-scale procession을 위한 object pyramid를 사용하는 대신에, SSD는 deep CNN들의 계층적 특성을 이용한다(utilizes the hierarchal nature of deep CNNs). ScaleFace[32]나 S3FD[33]과 같은 방법 또한 face detection을 위한 유사한 방법을 사용한다.
더해서 detection 알고리즘을 개선하기 위해, large annotated datset을 사용 가능하게 됨으로써 face detection의 성능이 급진적으로 좋아지고 있다. FDDB[34]는 2,845개의 이미지를 갖고 있으며 전체 5,171개의 얼굴들을 포함한다. 유사한 scale인 MALF[35] 데이터셋은 5,250개의 이미지로 구성되었으며 11,931개의 얼굴을 갖고 있다. 더 큰 데이터셋은 WIDER Face[22]다. WIDER Face는 32,000개가 넘는 이미지를 갖고 있으며 expression, scale, pose, illuminsation 등에 대한 다양한 변화를 갖는 이미지를 갖고있다. 대부분의 SOTA face detector들은 WIDER Face 데이터셋을 이용하여 학습되어졌다. 이 데이터셋은 작은(tiny) 크기의 얼굴들을 많이 갖고있다. 위에서 논해진 몇몇의 face detector들은 아직도 이미지에서 작은 얼굴들을 잘 찾기 위해 노력하고 있다.(작은 얼굴들에 대한 탐지 결과가 좋지 못함). [36]은 이러한 작은 얼굴들의 탐지가 왜 중요한지에 대하여 보여준다.
[37]에서는 2014년 이전에 개발된 수많은 face detection 방법들에 대한 survey의 연장선을 보여준다(extensive survey). [12]에서는 video에서 face recognition을 위한 face associtaion의 중요성을 논한다. Association은 다른 비디오 프레임에서의 다른 얼굴들에대한 관련성을 찾는 과정이다.
2.2 Facial Keypoints Detection and Head Orientation
Facial keypoints는 corners of eyes나 nose tip, ear lobes, mouth corner 등을 포함한다. 이러한 것들은 face identification/verification에서 중요한 face alignment를 위해 필요하다[15]. Head pose는 또다른 관심있는 중요한 정보 중 하나다. Keypoint localization 방법들에 대한 포괄적인 조사는 [38]과 [39]에서 찾을 수 있다.
2.3 Face Identification and verification
2.4 Multi-task Learning for Facial Analysis
3. A state-of-the-art face verification and recognition pipeline
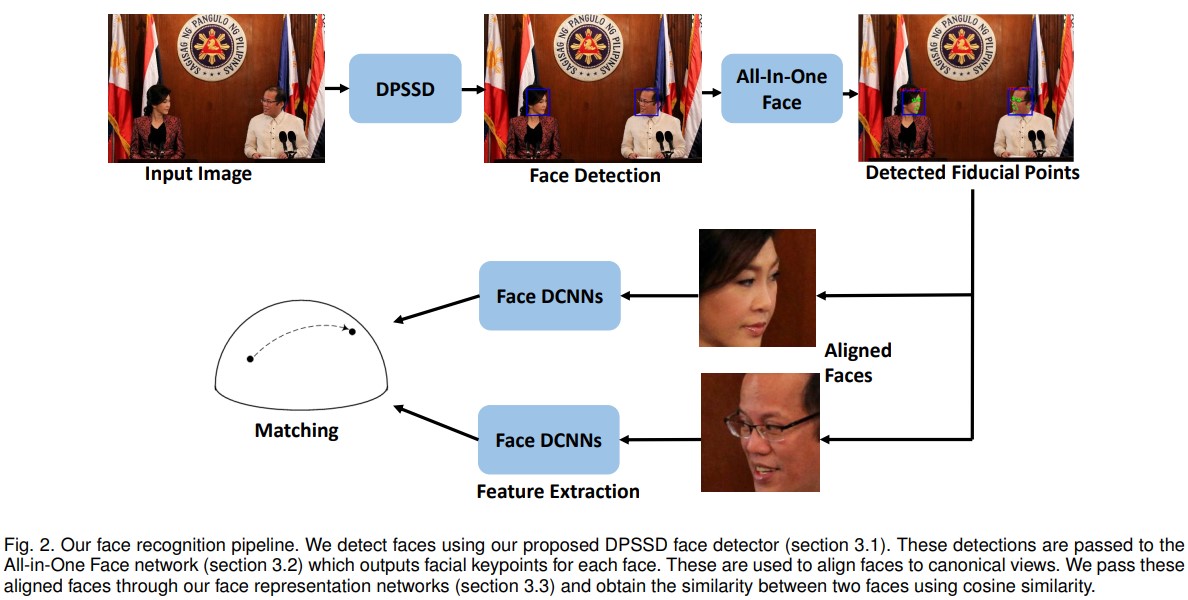
Figure 2. 논문에서 제안하는 face recognition pipeline. 논문에서 제안하는 DPSSD face detector(section 3.1)를 이용하여 얼굴을 탐지한다. 이러한 detection들은 All-in-One Face network(section 3.2)를 통과하며 각각 얼굴에 대한 facial keypoint들을 만들어낸다. 이러한 정보들은 canonical view를 만들기 위해 얼굴 정렬(face align)에서 사용되어진다. 이러한 aligned face들은 논문에서 제안하는 face representation network(section 3.3)을 통과하고 cosine similarity를 이용하여 두 얼굴의 유사성을 얻는다.
이번 섹션에선, 18개월 이내에 저자들에 의해 만들어진 face identifiaction과 verification을 위한 SOTA pipeline에 대해 논한다. Pipeline에 대한 overview는 figure 2에서 보여진다. 우선 논문에서 제안하는 DPSSD face detection을 subsection 3.1에서 설명한다. 다음으로 간단하게 MTL 접근방법을 사용하는 논문의 face alignment 방법을 요약한다. 마지막으로 identity feature의 extracting을 위한 논문의 접근 방법을 설명하고, 그것을 이용하여 face identification과 verification을 진행한다.
3.1 Deep Pytamid Single Shot Face Detector
논문에선 DCNN-based face detector를 제안하며 이를 Deep Pyramid Single Shot Face detector(DPSSD)라고 하며, 다양한 scale에 대해서 빠르게 face detection이 가능하다. 특히 작은 얼굴을 잘 찾는다. Face detection이 일반적인 object detection의 한 분야이므로, 다양한 연구자들이 이미 나와있는 object detector들을 fine-tunning하여 face detection을 위해 사용한다[27]. 하지만 효율적인 face detector를 디자인 하기 위해 face detection과 object detection의 방식에 차이를 두는것은 중요하다. 우선, 얼굴은 일반적인 객체에 비해 영상에서 더 작은 scale/size를 갖고 있다. 전형적으로 object detector들은 이러한 face detection에서 필요되어지는 low resolution을 탐지하도록 설계되어있지 않다. 다음으로, 전형적인 객체에 비해 얼굴은 다양한 aspect ratio가 필요하지 않다. 얼굴은 비율이 보통 정해져있으므로 일반적인 object detector들이 다양한 aspect ration를 다루는 작업이 필요하지 않다. 따라서 이러한 점을 토대로 face detector를 설계하였다.
4. Experimental results
이번 섹션에서는 4개의 데이터셋에 대한 논문에서 제안하는 face detection 결과를 보여준다. 또한 face identification과 verification에 대한 4 개의 challenging evaluation dataset인 IJB-A, B, C,와 CS5에 대한 실험 결과를 보여준다. 논문에선 논문에서 제안하는 system이 SOTA의 결과나 혹은 그와 근접한 결과를 대부분의 protocol에 대해 보여준다. 아래의 섹션에서는 평가 데이터셋과 protocol에 대해 설명하며, 논문에서 제안하는 시스템과의 실험결과의 차이를 보여준다.
4.1 Face detection
논문에선 WIDER Face, UFDD, FDDB, Pascal Face라는 4개의 face detection dataset에 대해 제안하는 DPSSD face detector의 성능을 평가했다. 논문에서 제안하는 방식은 Pascal Faces dataset에 대해 SOTA의 결과를 보였으며, WIDER Faces, UFDD, FDDB에 대해 경쟁력 있는 결과를 달성했다.
4.1.1 WIDER Face Dataset Results
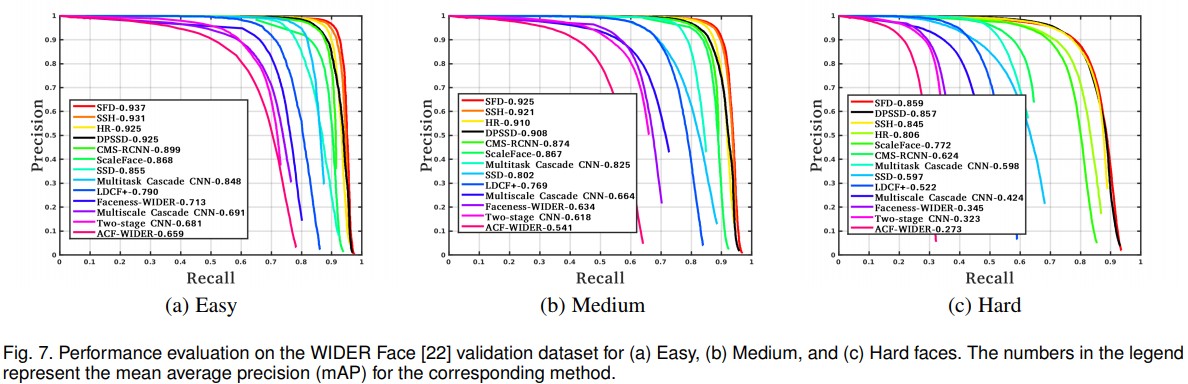
데이터셋은 393,703개의 face annotation을 가진 32,203개의 이미지를 포함하고 있으며, 이중 40%는 학습에 사용되고 10%는 validation에, 나머지 50%는 test에 사용된다. 데이터셋에는 occlusions, poses, event categories 및 face bounding box를 포함하는 많은 annotation들이 들어있다. 각 face들은 scale, pose, occlusion에 대한 다양한 변화를 갖고있다. 또한 얼굴의 크기가 4픽셀까지 작은 경우도 있기 때문에 이 데이터셋을 이용한 face detection은 매우 어려운 일이다. 논문에선 Face detection 학습을 위해 traning set을 사용하고, validation set을 이용하여 성능을 평가한다. Figure 7에서는 제안하는 DPSSD와 SOTA Face detector들의 성능을 비교한다.
Figure 7. WIDER Face validation dataset에 대한 성능 평가로, 각각 Easy, Medium, Hard faces로 나뉜다. 모델명 우측의 숫자는 mean average precision(mAP)이다.
논문에서는 DPSSD와 S3FD[33], SSH[7], HR[36], CMS-RCNN[96], ScaleFace[32], Multitask Cascade[82], LDCF+[97], Faceness[98], Multiscale Cascade[22], Two-stage CNN[22], ACF[99],에 대한 성능을 비교한다. 논문에선 S3FD, SSH, HR과 같은 SOTA 방식과 비교해 DPSSD가 경쟁적인 성능을 달성한 것을 볼 수 있다. DPSSD는 easy, medium 셋에서 각각 0.925, 0.908의 mAP를 달성했다. Hard셋에서의 경우, mAP는 0.857로 가장 좋은 성능을 나타내는 S3FD(0.859) 방식과 아주 근접한 성능을 보였다.
또한 SSD[100]를 fine tunning하여 학습한 baseline face detector와 논문에서 제시하는 방법을 비교했다. 이는 Hard set에서 DPSSD가 SSD보다 44%가량 향상된 mAP를 보였다. 이 결과는 고정된 aspect ration를 가진 anchor pyramid를 재 설계하고, upsampling layer를 추가하여 얼굴 감지 성능을 향상시키는데 많은 도움이 되게 하였다.
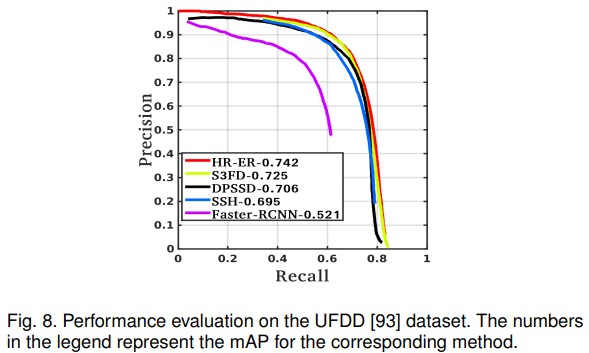
4.1.2 UFDD Dataset Results
Figure 8. UFDD 데이터셋에 대한 performane evaluation 결과. 각 방법 우측의 숫자는 mAP를 의미한다.
UFDD는 기존 데이터 셋에 존재하지 않는 몇 가지 현실적인 문제를 포함하는 최근의 face detection dataset이다. UFDD는 날씨에 의한 흐려짐(비, 눈, 안개), 움직임에 의한 번짐, 초점 흐려짐과 같은 요소들이 포함된 이미지 셋이다. 추가적으로 UFDD는 동물 얼굴이나 사람 얼굴이 아닌것들과같이 이 데이터셋을 매우 까다롭게 만드는 distractor들을 포함하고 있다. 데이터셋은 10,897개의 face annotation을 가진 총 6,425개의 이미지를 포함하고 있다. 논문에서 제안한 방식과 S3FD[33], SSH[7], HR[36], Faster-RCNN[27]을 비교했다. WIDER Face 데이터셋과 유사하게 0.706의 mAP로 경쟁력 있는 겨로가를 달성했다. UFDD 데이터셋에 대해서 논문에서 제안하는 알고리즘이 fine-tunning 되지 않았단 것을 고려해야 한다.
4.1.3 FDDB Dataset Results
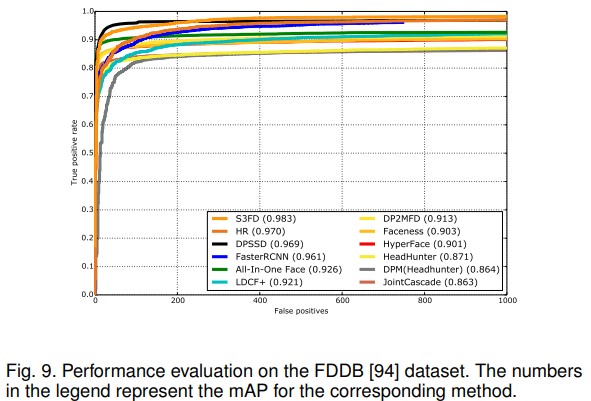
Figure 9. FDDB 데이터셋에 대한 performance evalutation 결과. 각 방법 우측의 숫자는 mAP를 의미한다.
FDDB datset은 제한되지 않은(unconstrained) face detection을 위한 데이터셋이다. FDDB는 야후 웹사이트 뉴스기사에서 가져온 2,845개의 이미지를 포함한 총 5,171개의 얼굴로 구성되어 있다. 영상들은 manually하게 ground truth를 생성하기 위해 localized 되어있다. 데이터 셋에는 2 개의 evalutation protocol이 있으며, 이는 discrete와 continuous로 나뉜다. 이는 각각 근본적으로 detecion과 ground truth 사이에 coarse match와 precise match에 대응된다. 논문에서 제안하는 모델의 성능을 평가하기위해 논문에서 제안하는 방법을 Figure 9에서 보여지는 Receiver Opoerating Characteristic(ROC) curves를 사용하는 discrete protocol에 근거하여 평가했다.
논문에서는 S3FD[33], HR[36], Faster-RCNN[27], All-In-One Face[8], LDCF+[97], DP2MFD[9], Faceness[98], HyperFace[10], Head-hunter[101], DPM[101], Joint Cascade[79]와 같은 다른 얼굴 검출 방법과의 성능을 비교했다. 그림에서 볼 수 있듯, 논문의 방법은 최신 방식은 S3FD나 HR과 비교해서 경쟁력 있는 성능을 보였고, 0.969의 mAP를 달성했다. FDDB 데이터셋을 위한 특별한 fine-tunning이나 bounding box regressiond을 사용하지 않았다는 점을 고려해야 한다.
4.1.4 Pascal Faces Dataset Results
Figure 9. FDDB 데이터셋에 대한 performance evalutation 결과. 각 방법 우측의 숫자는 mAP를 의미한다.
PASCAL faces dataset은 PASCAL VOC 데이터셋의 subset인 person layout dataset에서 수집되었다. 데이터셋에는 851개의 이미지에서 1,335개의 얼굴을 포함하고 있으며, 각각 모양(appearance)과 pose가 크게 다르다. Fig.10에서 이 데이터 셋에 대한 서로 다른 face detection 방식과의 성능 비교를 확인 할 수 있다. Figure 10에서, 논문에서 제안하는 DPSSD 방식이 96.11%의 mAP로 가장 좋은 결과를 보이는 것을 알 수 있다. Table 5에서는 다양한 데이터셋과 verification과 identification의 evaluation task에 대한 결과를 볼 수 있다.
4.2 ~ 4.5 생략(Face identification/verification에 대한 )
5. Conclusion
논문에서는 현재의 CNN을 이용하는 face recognition system을 이용한 모델들의 overview를 제공했다. 논문에서는 face recognition pipeline에 대해 논했으며 SOTA 기술들이었다. 또한 논문에서는 feature representation을 위한 두 네트워크의 앙상블(ensemble)을 사용하는 face recognition system을 제안하고 이에 대한 detail들에 대해 설명했다. 논문에서 제안하는 모델에서 pipeline에서의 Face detection과 keypoint localization은 모두 CNN을 이용하여 한번에 이루어졌다. 논문에서는 시스템을 위한 training과 dataset에 대한 detail에 대해 논했으며 이게 어떻게 face recognition과 연관되어 잇는지 논했다. 논문에서 IJB-A, B, C와 CS5의 4개 challenging dataset에 대한 제안하는 시스템의 실험결과를 제시했다. 그리고 앙상블 based 시스템이 SOTA 결과에 근접하게 나왔다.
하지만 풀어야 할 몇몇 issue들이 존재한다. DCNN 기반의 face recognition system에 대한 이론적인 이해를 위한 연구가 필요하다. 주어지는 다양한 loss function들은 이러한 network의 학습을 위해 사용되어지며, 모든 loss function을 같은 맥락으로 통합하는 framework를 개발해야 한다. Domain adaptation과 dataset bias또한 현재의 face recognition system의 issue다. 이러한 시스템은 보통 dataset을 이용하여 학습되어지며 유사한 test set에 대해 잘 동작한다. 하지만 하나의 도메인에 대해서 학습 되어진 네트워크는 다른 도메인에서 잘 동작하지 않는다. 논문에서는 다른 서로 다른 dataset들을 조합하여 학습시켰다. 이로인해 학습되어진 모델이 더 강건(robust)해 졌다. CNN의 학습에는 현재 몇시간에서 몇일이 걸린다. 따라서 더 빠른 학습을 위한 효율적인 구조(architecture)나 CNN의 implementation이 필요하다.

 Seongkyun Han's blog
Seongkyun Han's blog