Authors: Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, Tom Goldstein
Abstract
Neural network의 학습은 좋은 minimizer나 highly non-convex loss function을 찾는 능력에 의해 성능이 결정된다. 각 Skip connection을 포함하는 ResNet과 같은 네트워크 구조가 쉽게 학습되고, 학습 파라미터(batch size, learning rate, optimizer)를 잘 설정하며 일반화(generalization)를 잘 시키는 minimizer를 잘 만드는것으로 알려져 있다.
하지만, 이러한 차이의 이유와 근본적인 loss landscape에 대한 영향은 잘 알려져 있지 않다.
이 논문에선 neural loss function의 구조, 다양한 시각화(visualization)방법을 이용하여 generalization 측면에서의 loss landscape의 효과에 대해서 탐구한다.
우선, loss function curvature(곡률)의 시각화를 돕는 filter normalization이라는 방법을 제안하고, 각 loss function간 비교를 한다.
다음으로, 다양한 시각화 방법을 이용하여 어떻게 network의 구조가 loss landscape에 영향을 주는지, training 파라미터가 minimizer의 shape에 어떻게 영향을 주는지 탐구한다.
1. Introduction
Neural network의 학습은 high-dimensional non-convex loss function을 최소화시키는것이 필요하다. 일반적인 neural loss function의 학습의 난해함(NP-hard)에도 불구하고[2], data와 label들이 학습 전에 randomized 되어있다 하더라도 간단한 gradient 계산 방법들을 이용해 global minimizer들(zero or near-zero training loss에서 parameter configurations)을 찾을 수 있다[42]. 하지만 이런 경우는 일반적인 경우가 아니며 neural net의 trainability(학습가능성)은 network의 구조, optimizer의 종류, 초기화(initialization) 방법 등등 다양한 고려사항에 의해 결정된다. 이러한 다양한 옵션들의 선택지에도 불구하고 근본적인 loss surface는 명확하지 않다. Loss function의 평가는 학습 데이터셋에서 모든 data point들에 대하여 looping이 필요하므로 비용이 많이들어 불가능하기 때문에 loss function의 평가는 이론적으로만 존재했다.
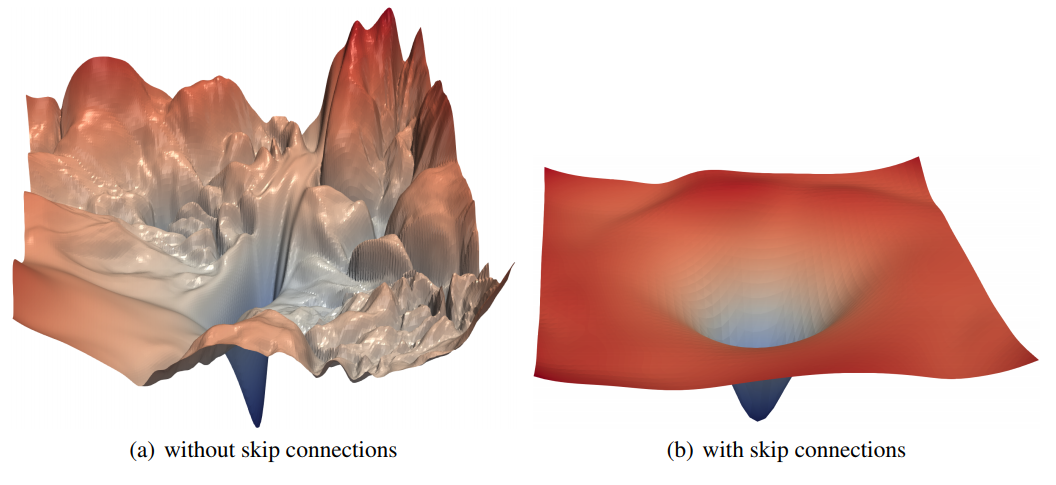
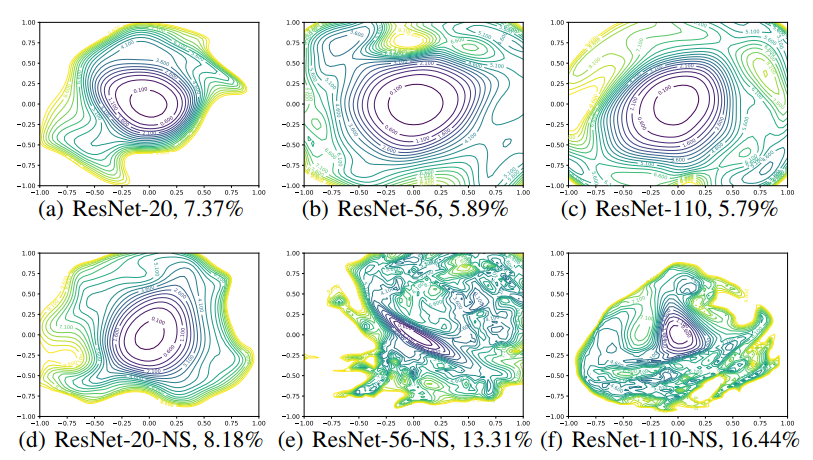
Figure 1. ResNet-56에 대해 skip connection의 유무에 따른 loss surface plot. 논문에서 제안하는 filter normalization scheme에 의해 shrpness, flatness의 비교가 가능하다.
시각화는 neural network이 왜 동작하는지에 대한 답변에 도움이 된다. 특히, 왜 highly non-convex neural loss function을 최소화 시킬 수 있는가(에 대한 답변에 대한 도움이 된다). 논문에서는 neural loss function의 실증적 묘사를 위해 논문에서는 고 해상도 시각화 방법을 사용한다. 다음으로 어떻게 서로 다른 네트워크 구조가 loss landscape에 영향을 끼치는지를 탐구한다. 거기에 더해서, neural loss function의 non-convex 구조가 그 네트워크의 학습가능성과 연결되어있는지 탐구하고, 어떻게 neural minimizer의 지형(sharpness.flatness, surrounding landscape)이 일반화(generalization) 특성에 형향을 끼치는지에 대해 탐구한다.
논문에선 이러한 연구를 위해 training 과정 중 찾아지는 서로 다른 minima간의 비교를 위해 simple한 “filter normalization” scheme을 제안한다. 다음으로 서로 다른 방법에 의해 찾아지는 minimizer들의 sharpness/flatness를 탐구하기 위해 시각화를 사용하고, 네트워크 구조의 차이(skip connection이 있는지, filter의 개수, 네트워크 깊이 등)가 loss landscape에 영향을 끼치는가에 대한 연구를 수행한다. 본 논문의 목표는 어떻게 loss function의 지형이 neural net의 일반화(generalization)에 영향을 끼치는가에 대한 이해다.
1.1. Contributions
논문에선 의미있는 loss function의 시각화에 대한 방법을 연구한다. 그 다음, 이러한 다양한 시각화 방법을 이용하여 loss landscape의 지형이 어떻게 학습가능성과 generalization error에 영향을 주는지에 대해 탐구한다. 아래에서 본 논문에서 다루는 더 자세한 issue에 대해 설명한다.
논문에서는 다양한 loss function의 시각화 방법들의 단점을 드러내고, 간단한 시각화 방법들의 loss function minimizer의 local geometry(sharpness or flatness)를 정확하게 capture하는것에 대한 실패를 보여준다.
논문에서는 “filter normalization”에 기반하는 간단한 시각화 방법을 제안한다. 논문에서 제안하는 normalization이 사용될 때 Minimizer들의 sharpness가 얼마나 generalization error와 유사한지를 보이고, 서로 다른 네트워크 구조와 학습 방법에 대한 비교를 수행한다.
논문에서는 네트워크가 충분히 깊을 때 neural loss landscape가 거의 convex 상태에서 매우 복잡한(chaotic)상태로 빠르게 전환되는지에 대해 관찰한다. Convex에서 chaotic으로 가는 변환은 generalization error의 급격한 하락과 함게 발생하며, 학습가능성을 매우 낮추게 된다.
논문에서는 skip connection이 어떻게 minimizer를 flat하게 만들고, chaotic하게 되는것을 방지하는지에 대해 관찰한다. 그래고 매우 깊은 네트워크의 학습에는 skip connection이 필수로 필요하게 되는지에 대한 설명을 한다.
논문에서는 local minima 주변의 Hessian의 smallest(most negative) eigen-values를 계산하여 non-convexity를 양적으로 측정한다.
논문에서는 SGD optimization의 궤적(trajectory)들의 시각화에 대한 연구를 한다. 논문에서는 이러한 궤적의 시각화에서 발생하는 어려움을 설명하고, extremely low dimensional space에 있는 optimization trajectory들을 보여준다. 이러한 low dimensionality는 논문의 2-dimensional visualization에서 관찰된 것 같이 loss landscape에 크게 볼록한 영역(large, nearly convex region)이 존재함으로 설명 가능하다.
3. The Basics of Loss Function Visualization
Neural network은 학습에 영상 ${x_{i}}$ 과 label ${y_{i}}$ 같은 feature vector 뭉치(corpus)가 필요하며, $ L(\theta)=\frac{1}{m} \sum_{i=1}^{m}l(x_{i}, y_{i}\; ;\theta) $ 와 같은 loss function을 최소화시는 과정이 포함되고, 그 과정에서 $ \theta $ 로 정의되는 weight parameter를 $ m $ 개의 샘플을 이용하여 잘 얻어지는지 계산한다.
Neural net은 많은 파라미터를 포함하며, 따라서 loss function은 very high-dimensional space에 존재하게 된다. 하지만 시각화는 1D(line)나 2D(surface) plot등 low-dimension에서만 가능하며, dimensionality gap을 줄위기 위한 몇 가지 방법들이 존재한다.
1-Dimensional Linear Interpolation
Loss function을 plot하기 위한 간단하고 가벼운 방법이다. 두 개의 파라미터 세트인 $\theta$ 와 $\theta’$ 를 설정하고, loss function의 값들을 이러한 두 점을 이어 plot한다.
이 방법은 다른 minima에서의 sharpness와 flatness에 대한 연구에 폭넓게 사용되었으며, batch size에 의한 sharpness의 dependence의 연구에도 사용되었다.
1D linear interpolation 방법은 몇가지 약점이 있다. 우선 1D plot으로는 non-convexities의 시각화가 매우 어렵다. 다음으로, 이 방법은 네트워크의 batch normalization이나 invariance symmetries를 고려하지 않는다. 이러한 이유로 인해 1D interpolation plot으로 생성된 visual sharpness로는 적절한 비교가 불가능하다.
Contour Plots & Random Directions
이 방법을 이용하기 위해서는, 하나의 center point $\theta^{\ast}$ 를 그래프에서 정의하고, 두개의 direction vector $\delta$ 와 $\eta$ 를 정한다.
다음으로 function을 $ f(\alpha)=L(\theta^{\ast}+\alpha \delta) $ 의 1D line이나
$f(\alpha , \beta)=L(\theta^{\ast}+\alpha \delta +\beta \eta)$ (식 1)의 2D surface로 plot한다. 하지만 2D plotting은 연산량이 매우 많고 이러한 방법들은 보통 loss surface의 complex non-convexity를 capture하지 못하는 small region을 저 해상도(low-resolution)로 plot 한다. 이러한 이유로 본 논문에서는 weight space의 large slice에 대해 고 해상도 시각화를 사용하여 네트워크 디자인(설계)가 non-convex structure에 미치는 영향을 시각화 한다.
논문의 연구는 밑에서 서술되는 적절한 scaling이 적용된 random Gaussian distribution에서 sampled된 random direction vector $\delta$, $\eta$를 사용하는 (식 1)의 plot 방식이 적용된다. Random directions가 plotting을 간단하게 만들어도 loss surface의 고유한 지형(geometry)을 capture하는것을 실패하기때문에 서로 다른 두 minimizer나 네트워크의 geometryt의 비교에 사용 할 수 없게 된다. 이는 네트워크 weight 파라미터들의 scale invariance 라는 특성 때문이다. 예를들어 네트워크에 ReLU non-linearities가 사용될 경우, 네트워크의 어떤 레이어에서 얻어지는 weight값들에 10을 곱한 후 다음 레이어에서 10으로 나누더라도 ReLU에 의해 그 차이는 존재하지 않게 된다.(자세한것은 ReLU참조!) 이러한 불변성(invariance)은 batch normalization이 사용될 경우 더 중요하게 작용한다. 이런 경우 각 레이어의 출력이 batch normalization에 의해 re-scaled 되므로 필터의 사이즈(norm)가 무관하다. 따라서 네트워크의 동작은 결국 weight를 re-scale 하더라도 바뀌지 않게 된다.(단, scale invariance는 rectified network에서만 작용)
Scale invariance는 이를 방지하는 특별한 방법을 적용함에도 불구하고 plot들에 대한 비교에서 의미있는 결과를 만드는것들 방해한다. Large weights를 갖는 neural network은 smooth하고 slowly하게 변하는 loss function을 갖는것 처럼 보일 수 있다. 하나의 단위로 weight를 교란(perturbing)시키는 것은 만약 weight가 1보다 훨씬 큰 scale의 weight가 남아있다 하더라도 네트워크의 성능에 매우 적은 영향을 미칠 것이다.
하지만, 만약 weight가 1보다 매우 작다면 같은 unit perturbation이 catastrophic effect을 만들어 낼 것이며, loss function을 weight perturbation에 대해 매우 민감하게 만들 것이다. Neural nets들은 scale invariant하다는 점을 상기시켜보면, 만약 small-parameter와 large-parameter 네트워크가 존재한다 할 때 두 모델은 동일한 모델이 되며, 그렇다면 loss function에 대한 어떠한 분명한 차이도 단지 인공적인 scale invariance에 의한 것들일 것이다.
이러한 scaling effect를 제거하기 위해 논문에서는 loss function을 filter-wise normalized directions를 이용하여 plot 하였다. 파라미터들 $\theta$를 포함하는 네트워크의 direction을 얻기 위해 random Gaussian driection vector $d$와 dimension compatible $\theta$를 만들어냈다. 그 다음에 $\theta$와 상응하는 같은 norm을 얻기위해 각각의 $d$에 존재하는 filter를 normalize했다. 즉, $d_{i,j}\leftarrow \frac{\parallel d_{i,j} \parallel}{d_{i,j}}\parallel \theta_{i,j}\parallel$로의 변화를 만들어냈다.
(참고: FC layer는 $1\times 1$의 출력 feature map을 만들어내는 Conv layer와 같다.)
5. The Sharp vs Flat Dilemma
이번 섹션에선 flat minimizer보다 sharp minimizer가 더 잘 일반화(generalize)를 시키는지 아닌지에 대한 것을 다룬다. 이를 이용해 filter normalization이 사용될 때 minimizer의 sharpness가 일반화 오차(generalization error)와의 연관성이 크다는 것을 알 수 있다. 이로인해 plot간의 side-by-side(나란한) 비교할 수 있다. 반면에 non-normailzed plot들의 sharpness는 왜곡되거나(distorted) 예측 불가능한(unpredictable)한 것처럼 보일 수 있다.
Large-batch는 일반화(generalize)를 잘 시키지 못하는 sharp minima를 만들어내는 반면, Small-batch SGD는 일반화를 잘 시키는 flat한 minimizer를 만들어낸다고 알려져 있다[3, 24, 18]. 하지만 이에대한것은 아직 논의중으로, 일반화가 직접적으로 loss surface의 curvature에 연관되어있지 않으며, large batch size로도 좋은 성능을 내는 모델들이 존재한다[7, 23, 19, 14, 6]. 이 섹션에선 sharp minimizer와 flat minimizer의 차이에 대해 탐구한다. 우선 이러한 시각화(visualization)를 수행함에 있어 생기는 문제점들에 대해 논하고, 어떻게 적절한 normalization이 왜곡된 결과(distorted result)를 만들어내는것을 방지하는지에 대해 논한다.
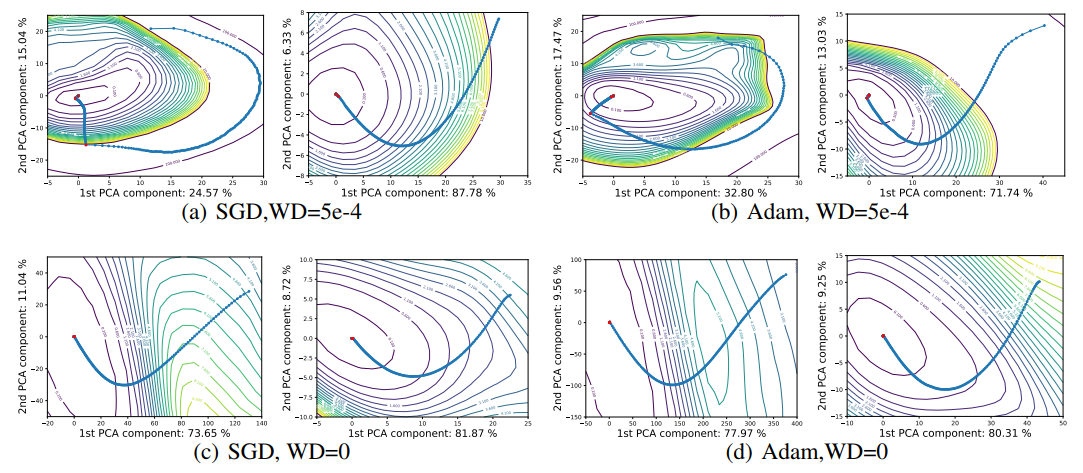
논문에서는 CIFAR-10 데이터셋을 VGG-9 네트워크[33]를 이용하여 학습시키며 batch normalization를 일정한 epoch마다 규칙적으로 수행한다. 또한 2개의 batch size를 사용하며, large batch size로 8192(16.4% of training data of CIFAR-10)를, small batch size로 128을 사용한다. $\theta^{s}$와 $\theta^{l}$은 각각 small batch size와 large batch size를 사용하여 SGD를 동작시켰을 때 얻어지는 결과를 나타낸다. [13]의 linear interpolation approach를 이용하여, 논문에서는 $f(\alpha)=L(\theta^{s}+\alpha (\theta^{l}-\theta^{s}))$로 정의되는 두 solution direction이 표함되어 CIFAR-10의 학습/테스트 데이터셋에 대한 loss 값들을 plot한다.
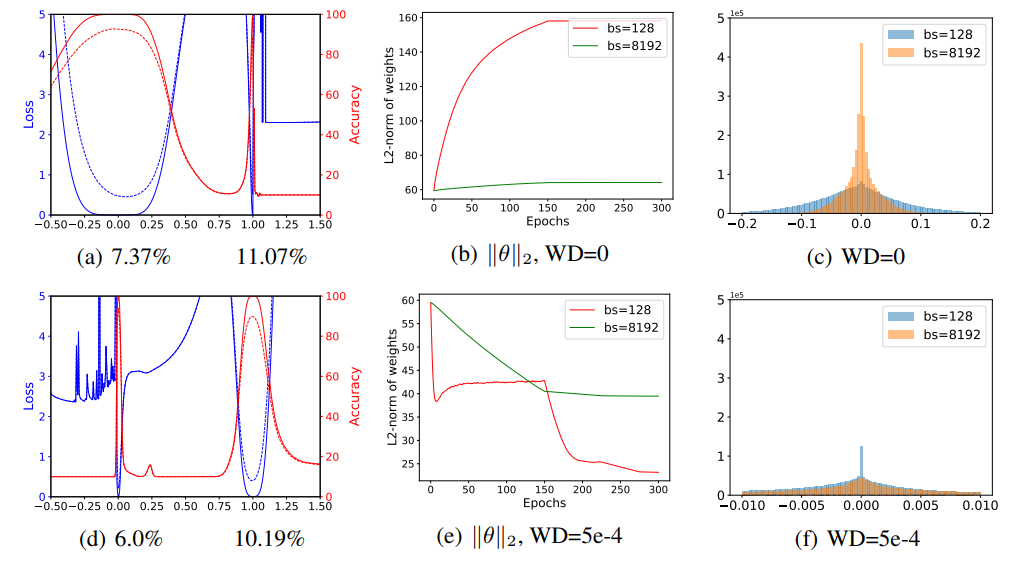
Figure 2. (a)와 (b)는 VGG-9에 대한 small/large batch 학습 결과의 1D linear interpolation이다. 파란 선은 loss value, 빨간 선은 accuracy이며 실선은 training curve, 점선은 testing curve다. Small batch 실험결과는 (a)에서 가로축 0 근처, large batch는 가로축 1 근처이다. 각 실험에 대한 우측에 보여진다. (b)와 (e)는 training에서의 weight norm $\parallel \theta \parallel_{2}$의 변화를 나타낸다. Weight decay(WD)가 없는 경우(WE=0) weight norm이 training동안 서서히 계속 증가한다. (c)와 (f)는 weight decay의 차이에 의한 weight histogram을 보이며, weight decay가 적용 되었을 경우 더 0에 가까운 weight 값들을 출력하게 되는것을 알 수 있다.
Figure 2(a)는 linear interpolation polt으로, x축 0 근처는 $\theta^{s}$를 나타내는 small batch size일 때의 경우, x축 1 근처는 $\theta^{l}$을 나타내는 large batch size일때를 의미한다. [24]에서 논의된 바 처럼, small batch solution이 더 넓고, large batch solution은 좁고 sharp한 solution을 보이는것을 확인 할 수 있다. 하지만, 이러한 sharpness balance는 weight decay[25]를 적용함으로써 확 바뀔 수 있다. Figure 2(d)는 같은 실험에 대해 non-zero weight decay parameter가 적용되어 실험동안 weight decay가 적용된 것에 대한 solution을 확인 할 수 있다. (a)와 비교했을 때 small batch minimizer가 sharp해지고 large batch minimizer의 그래프 모양이 flatten 된 것을 확인 할 수 있다. 하지만 이번 실험에선 small batch가 모든 실험에대해 실험적으로 generalize를 잘 시키는 것을 확인했기 때문에 이 실험에선 sharpness가 generalization과 명확한 연관이 있는 것을 확인하지 못했다. 뒤쪽에서 이러한 sharpness 비교가 왜 엄청난 오해의 소지가 있고, minima의 내면의 특성을 다 잡아내지(capture) 못하는지에 대한 것을 다룬다.
Sharpness의 분명한 차이들은 각 minimizer들의 weight들에 대한 검토를 통해 설명이 가능하다. Network weight histogram들은 Figure 2(c)와 (f)에서 보여진다. Large batch와 zero weight decay가 사용되었을 때 small batch를 사용한 경우보다 더 작은 weight값들을 갖는 경향을 보인다. 즉, weight 값의 분포가 0에 더 치우쳐져 있다. 이러한 scale의 차이는 간단한 이유로 인해 발생한다. 더 작은 batch size가 더 큰 batch size보다 더 많은 한 epoch당 더 많은 weight update를 하기 때문에 weight decay의 효과(norm of the weights에 대한 penalty를 줌) 감소가 더 두드러지게 되는것이다. 학습 중 weight normalization(norm)에 의한 변화는 Figure 2(b)와 (e)에서 볼 수 있다. Figure 2는 minimizer들의 내부의 sharpness를 시각화하지 않고 (무관한) 그냥 weight scaling에 대한 것만을 시각화한다. Batch normalization는 unit variance(단위 분산, 즉 분산값이 1)를 갖기 위해 출력물을 다시 scaling하기 때문에 batch normalization을 사용하는 네트워크의 weight scaling은 의미가 없다. 하지만 작은 weight들은 더 변화에 민감하며, 더 sharp하게 보이는 minimizer들을 만들어낸다.
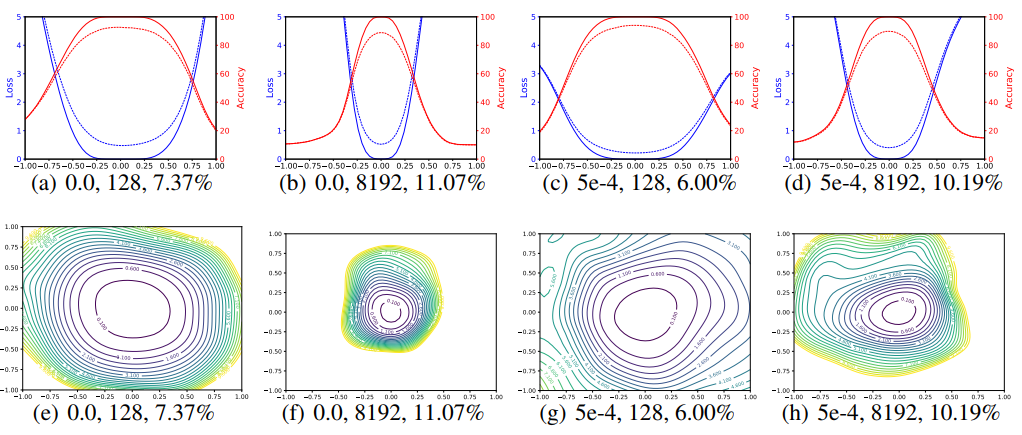
Figure 3. 서로 다른 weight decay와 batch size에 대한 SGD를 이용하여 얻어진 1D와 2D 시각화 solution. 각 subfigure은 weight decay, batch size, test error를 나타낸다.
Filter Normalizaed Plots
이곳에선 Figure 2의 실험을 다시 반복했다. 하지만 이번엔 random filter-normalized directions를 사용하여 각 minimizer 근처에서의 loss function을 개별적으로 plot하였다. 이로 인해 Figure 2(c)와 (f)에서 보여지는 scaling에 의해 발생되는 지형(geometry)의 차이가 사라진다. Figure 3의 실험 결과는 small batch와 large batch minima 사이의 sharpness 차이를 여전히 보이지만, 이러한 차이는 un-normalized plot에서 보이는 것보다 훨씬 작은 것을 알 수 있다. 비교를 위해 samole un-normalized plot과 layer-nodrmalized plot을 Appendix Section A.2에 실어놓았으니 참고할것… 또한 논문에서는 두 개의 random directions과 contour plot들을 이용한 실험 결과를 시각화했다. 실험 결과 sharper large batch minimzer보다 small batch size와 non-zero weight decay 모델이 더 넓은 contour를 갖는 결과를 얻었다. ResNet-56의 실험결과는 Appendix의 Figure 15에 나와있다. Figure 3에서 filter-normalizeed plot을 이용할 때, 이로인해 minimizer간의 side-by-side(나란한) 비교가 가능했으며 이로부터 sharpness가 generalization error와 밀접한 연관이 있음을 볼 수 있었다. Large batch는 시각적으로 더 sharp한 minima(비록 엄청나게 명확하진 않지만)를 만들어내고 더 높은 test error를 보였다.
6. What Makes Neural Networks Trainable? Insights on the (Non)Convexity Structure of Loss Surfaces
Neural loss function의 global minimizer를 찾는 능력은 일반적이지 않다(쉬운일이 아니다). 즉 global minimizer를 찾는 일은 어떠한 neural architecture들이 다른것들보다 minimize하기 쉬운 case에 대해서는 찾기 쉽다는 의미다. 예를 들어, skip connection을 쓰는 경우, [17]의 저자들은 매우 깊은 구조(architecture)의 모델들을 학습시켰으며, 그와비슷한 깊은 구조의 네트워크들은 학습이 불가능했다. 더해서 이러한 네트워크를 학습시키는 능력은 학습을 시작 할 대 초기 파라미터와 큰 관련이 있다. 시각화 방법을 이용하여 논문에선 neural architecture에 대한 실증적인 연구를 수행하여 왜 loss function의 non-convexity가 어떤 상황에서는 문제가 되고, 어떨땐 아닌지에 대한 조사를 했다.
논문에선 다음 질문들에 대한 통찰력(insight)을 제공하고자 했다.
Loss function은 중요한 non-convexity를 모두 가지고 있는가?
만약 눈에 띄는 non-convexity가 있는 경우 왜 그러한 non-convexity들이 항상 문제가 되지 않는가?
왜 일부 archecture들은 쉽게 훈련 할 수 있고, 결과가 initialization에 매우 민감한 이유는 무엇인가?
논문에선 이러한 질문에 답하는 non-convexity 구조에서의 극단적인(extreme) 차이를 갖는 아키텍쳐에 대해 살펴보고, 이러한 차이점들이 generalization error와 연관이 있음을 살펴본다.
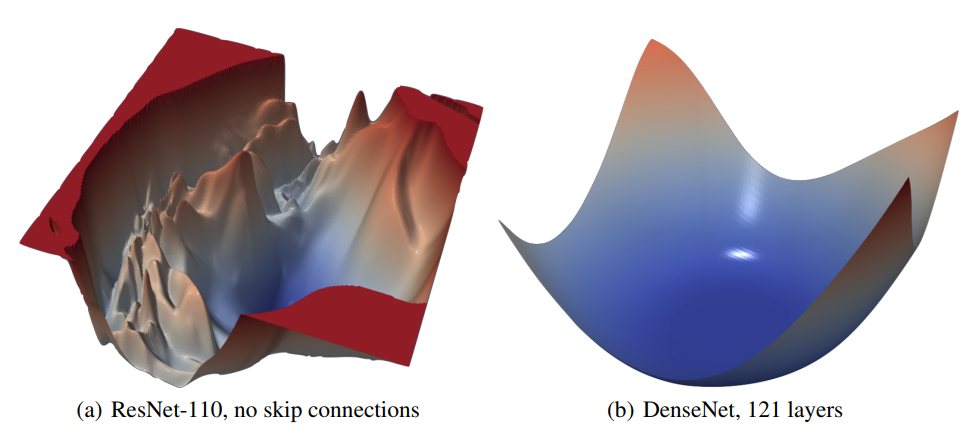
Figure 4. ResNet-110-noshort과 DenseNet의 CIFAR-10에 대한 loss surface
Figure 5. 서로 다른 depth에서의 ResNet과 ResNet-noshort의 2D loss surface visuzlization
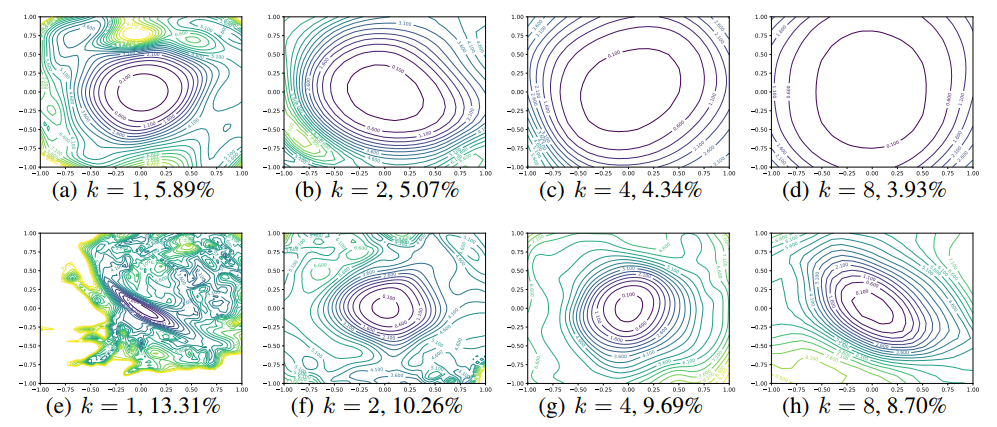
Figure 6. CIFAR-10에 대한 Wide-ResNet-56 실험 결과이며, 상단은 W/ shortcut connection, 하단은 W/O shortcut connection. 레이블 k=2는 레이어당 1배의 많은 filter들이 존재하는것을 뜻한다. 테스트 에러는 각 figure 밑에 표기되어있다.
Experimental Setup
Non-convexity의 network architecture에 대한 효과를 이해하기 위해 논문에서는 다양한 네트워크에 대한 학습을 진행하였고, 섹션 4에서 설명하는 filter-normalized random direction method를 사용하여 얻어진 minimizer들 주변의 landscape를 plot하였다. 실험에서는 neural network들에 대한 세 가지 class들을 고려하였다.
1) CIFAR-10에서의 성능에 대해 optimize된 ResNets[17] 사용. 실험에선 ResNet-20/56/110을 사용하였고, 각 숫자는 layer의 숫자를 의미한다.
2) Shortcut이나 skip connection을 포함하지 않는 ‘VGG-like’ 네트워크들을 사용. 실험에선 ResNet들의 shortcut connection을 제거하여 적용했다.
3) CIFAR-10 optimized network보다 더 많은 레이어당 필터 갯수를 갖는 ‘Wide’ ResNets 사용.
모든 모델들은 CIFAR-10 데이터셋에 대해 Nesterov momentum을 이용한 SGD를 이용하였으며, batch-size 128, 0.0005 weight decay/300 epochs가 적용되었다. Learning rate는 0.1로 초기화되었으며 150, 225, 275 epoch마다 10배씩만큼 감소한다. 더 깊은 네트워크에 대한 VGG-like 실험은(밑에서 기술되는 ResNet-56-noshort같은) 0.01의 더 작은 learning rate를 적용하였다. 각각 다른 neural network의 minimizer에 대한 3개의 고 해상도 2D plot은 Figure 5와 Figure 6에서 확인 가능하다. 결과는 surface plot이 아닌 convour plot으로 표시되며, 이는 non-convex structures에 대한 sharpness를 쉽게 평가하도록 해준다. ResNet-56에 대한 surface plot은 Figure 1에서 참고 가능하다. 참고로 각 plot의 중심은 minimizer이며(minima), 두 축은 (1)과 같이 filter-wise normalization를 통해 두 개의 random direction을 매개변수화(parameterize)한 결과다. 논문에선 어떻게 architecture가 loss landscape에 영향을 미치는지에 대한 몇 가지 관점을 아래에 제시한다.
The Effect of Network Depth
Figure 5에서, 네트워크의 깊이가 skip connection들의 유무에 따라 어떻게 neural network의 loss surface에 영향을 미치는가에 대한 것을 볼 수 있다. ResNet-20-noshort 네트워크에 대한 실험 결과를 볼 때, 중앙에 상당히 부드러운(benign) 지역에 의해 좋은 landscape를 갖고 있으며, 극단적인 non-convex(비 볼록성)는 없다.(네트워크가 얕기때문에 shortcut에 의한 영향력이 적다는 의미) 그다지 놀랍지 않은게 원래 ImageNet에 대한 original VGG네트워크를 보면 19개의 레이어를 갖고 효율적으로 학습이 가능했다[33]. 하지만 네트워크의 깊이가 깊어질수록 VGG-like 네트워크의 loss surface가 자발적으로(spontaneously) nealy convex에서 chaotic으로 변하게 된다.(네트워크가 깊어질수록 loss landscape가 복잡해진다는 의미) ResNet-50-noshort은 극단적인 non-convexity를 가지며 넓은 지역에서 gradient direction이 중앙의 minimizer를 가리키지 않게 되는 것을 확인 할 수 있다.(surface가 복잡하므로 확률적으로 당연히 중양의 minima로 optimization 되기 힘듦) 또한 loss function이 어떤 방향으로 움직일때 때때로 극단적으로 커지게 된다. ResNet-110-noshort은 더 dramatic한 non-comvexity를 보인다. 그리고 plot에서 모든 방향으로 움직일 때 extremely하게 가파른 양상을 보인다. 거기에 더해서, 참고로 VGG-like 네트워크들의 중양의 minimizer들은 상당히(fairly) sharp한 모습을 보인다. ResNet-56-noshort의 경우 minimizer가 꽤 ill-conditioned(불량 조건) 상태이며 minimizer 주변의 contour들을 볼 때 상당히 기이한(eccentricity) 꼴을 보인다.
Shortcut Connections to the Rescue
Shortcut connection들은 loss function의 지형(geometry)에 대해 dramatic한 효과를 가져온다. Figure 5에서, 저자들은 residual connection이 네트워크의 깊이가 깊어짐에 따른 loss surface의 chaotic한 변화를 방지하는것을 확인했다. 사실 0.1-level contour의 width와 shape가 20-layer와 110-layer가 거의 동일한 것을 알 수 있다. 흥미롭게 skip connection의 효과는 deep network에 가장 중요한것 같다. ResNet-20이나 ResNet-20-noshort같은 shallow network에 대해서는 skip connection의 효과가 별로 없다(unnoticeable). 하지만 네트워크가 깊어질수록(networks get deep) non-convexity의 폭발적 증가(explosion)를 residual connection이 막아준다. 이 효과는 다른 종류의 skip connection에서도 존재한다. 이러한 residual connection의 효과는 다른 종류의 skip connection에도 적용되는 것을 보여주며, Figure 4에서는 DenseNet[20]의 loss landscape를 통해 다른 종류의 skip connection을 포함하므로 깊은 구조임에도 non-convexity를 보이지 않는 것을 확인 할 수 있다.
Wide Models vs Thin Models
레이어당 convolutional filter의 갯수의 효과에 대해 보기 위해서 논문에서는 narrow CIFAR-optimized ResNets(ResNet-56)을 이용한 Wide-ResNets[41]을 사용하였으며, 이는 필터의 갯수를 레이어당 k=2, 4, 8로 k 배수만큼 많게 한 모델이다. Figure 6에서는 모델이(k가 큰 모델) wider할수록 눈에띌만한 chaotic한 변화를 갖는 loss landscape가 없는것을 확인 할 수 있다.(wider 할수록 모델 모양이 더 안정적이게 된다는 의미) 네트워크의 넓이(width)를 넓게할수록 minima는 flat한 minima와 넓은 convexity(볼록) 영역이 나타난다. 마지막으로, 참고하자면 sharpness는 test error와 극단적으로 연관이 있다.
Implications for Network Initialization
Figure 5에서 보여지는 하나의 재미있는 특성은 모든 네트워크에 대해 loss landscape들이 high loss value의 well-defined region과 non-convex contour들로 둘러쌓인 low loss value의 well-defined region과 convex contour로 나뉘어진다고 판단된다. 이러한 chaotic과 convex 지역(region)의 분리성은(partitioning) 좋은 initialization strategies와 좋은 네트워크 구조가 학습이 쉽게 되는 특징의 중요성으로 설명가능하다. [11]에서 제안하는 normalized random initialization strategy같은 방법을 쓸 때, 전형적인 neural network들은 initial loss value를 2.5보다 적게 얻게된다. Figure 5의 ResNets나 얕은 VGG-like 네트워커와 같이 잘 동작되는(behaved)네트워크의 loss landscape는 loss value를 4 이상으로 커지는 large, flat, nearly convex한 attractor(끌어당기는것, 장점들)에 의해 주도된다. 이러한 landscape들에 대해, random initialization은 well-behaved loss region에 놓이게 될 것이며(landscape가 좋으면 random하게 weight를 초기화 하더라도 좋은 지역에 놓이게 될 것이라는 의미), optimizer 알고리즘들은 절대로 high-loss를 발생시키는 chaotic한 고원(plateau)이 발생시키는 non-convexity들을 볼 수 없을 것이다.(즉, 쉽게 optimization이 될 것이다.) ResNet-56/110-noshort의 chaotic한 loss landscape들은 loss값이 낮아지는 convexity가 더 좁은 지역에서 관찰된다.(즉, loss값이 낮아지는 방향으로 흘러갈 수 있는 확률이 낮아질 수 밖에 없음) Shallow enough attractor를 가진 충분히 깊은 네트워크의 경우 초기 반복은 gradient 정보가 없는 쓸모없는(uniformative) chaotic region에 놓이게 된다. 이러한 경우 gradient들은 흩어지게 되며(statter)[1] 학습이 불가능하게 된다. SGD는 skip connection이 없는 156 레이어 네트워크의 학습이 불가능해서 이러한 가설에 힘을 실어주었다(심지어 매우 작은 learning rate로도).
Landscape Geometry Affects Generalization
Figure 5와 6에서는 landscape의 지형이 일반화(generalization)에 미치는 dramatic한 효과에 대해 보여준다. 우선, 시각적으로 편평한 minimizer들은 계속 낮은 test error를 가지며, 논문에서 제안하는 filter normalization이 loss function의 geometry를 시각화하는 자연스러운 방법임에 더 큰 힘을 실어준다. 다음으로, skip connection이 없는 deep network의 chaotic landscape 결과들은 더 어려운 학습과 높은 test error를 보이며, 더 convex한 landscape일수록 낮은 error를 보인다. 사실 Figure 6의 윗줄에서 볼 수 있는 Wide-ResNets과 같은 가장 convex한 landscape들은 가장 일반화(generalize)를 잘 시키며 chaotic한 landscape 모습을 거의 찾아볼 수 없다.
A note of caution: Are we really seeing convexity?
논문에서는 dramatic한 dimensionality 감소를 통해 loss surface를 보고 있으므로 이러한 plot을 어떻게 하냐 설명함에 있어서 주의를 기울여야 한다. Loss function의 level을 측정하기 위한 하나의 방법으로는 principle curvatures() 를 계산하는 방법이 있는데, 이것은 간단하게 Hessian의 eigenvalue들을 뜻한다. Convex function은 non-negative curvature들을 갖으며(positive semi-definite Hessian), 동시에 non-convex function은 negative curvature들을 갖는다. 이는 dimensionality reduced plot(with random Gaussian directions)의 curvature 이론이 full-dimensional surface(where the weights are Chi-square random variables)의 curvaturee들의 weighted된 평균임을 이론적으로 의미한다.
이것은 몇가지 결과를 갖는다. 우선, 만약 non-convexity가 dimensionality reduced plot에 존재한다면, non-convexity는 full-dimensional surface에도 또한 무조건 존재하게 된다. 하지만 분명한 convexity가 low-dimensional surface에 존재하더라도 high-dimensional function이 truly convex하다는것을 의미하지는 않는다. 오히려 positive curvature들이 dominant(지배적)함을 의미한다(더 공식적으로 mean curvature 또는 average eigenvalue가 양수임).
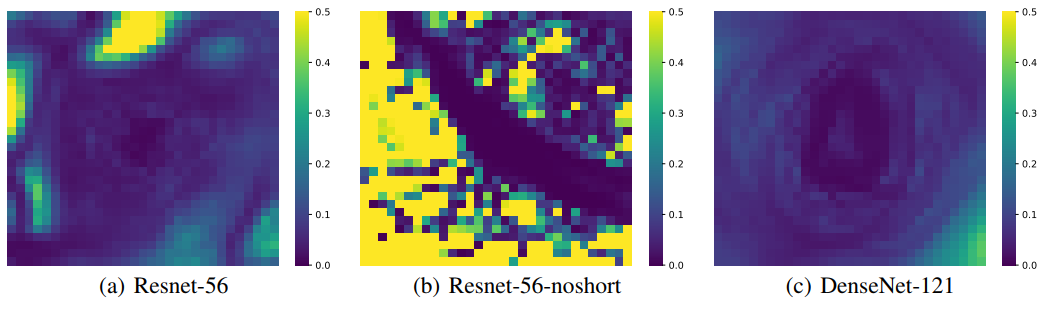
Figure 7. 각각의 filter-normalized surface plot에 대해 Hessian의 maximum과 minimum eigenvalue를 계산하고, 이 두 eigenvalue에 대한 비율을 map으로 나타냈다.
이러한 analysis가 충분히 가정에 대해 안심시키지만(reassuring), 만약 이러한 시각화(visualization)가 포착(capture)하지 못하는 중요한 숨겨진 non-convexity가 존재할 수 있는지 궁금할 수 있다. 이것에 대한 대답으로, 우리는 Hessian의 minimum eigenvalue $\lambda_{min}$ 과 maximum eigenvalue $\lambda_{max}$ 를 계산했다. Figure 7의 map들은 위에서 연구된 loss surface들(같은 minimizer와 같은 random direction들을 사용했을 때)에 대한 $\begin{vmatrix}\lambda_{min}/\lambda_{max}\end{vmatrix}$ 비율이다. 파란색은 더 convex한 지역을 의미하며(양의 eigenvalue에 비해 0에 가까운 음의 eigenvalue), 노란색은 눈에띄는 negative curvature를 의미한다. 논문의 surface plot에서의 convex-looking region들은 실제로 무의미한 negative eigenvalue들을 가진 지역에 해당하며(즉, plot에 포함되지 않는 중요한 non-convex feature는 없다는 의미), 동시에 chaotic region은 large negative curvature들을 포함한다. DenseNet과 같은 convex-looking surface의 경우에는 plot의 넓은 지역에서 negative eigenvalue들이 매우 작게 남아있는것을 확인 할 수 있다(less than 1% the size of the positive curbatures).
즉, Figure 7에서 파란 부분은 아래로 볼록한 부분이며, 노란 부분은 위로 볼록한 것을 의미한다. 따라서 파란색이 넓게 분포할수록 더 loss surface에 chaotic한 부분이 덜 존재하는것을 의미하며, 이는 해당 모델이 Generalization이 더 잘 되어 있음을 의미한다. (negative curvature가 더 좁게 존재)
또한 고 차원의 loss surface를 저 차원으로 plot하면 고 차원에 숨겨진 non-convexity가 저 차원으로 plot 되지 못한다고 생각 할 수 있다. 이는 고 차원의 데이터에 대한 hessian matrix를 구한 후 계산되는 hessian eigenvector의 최솟값과 최댓값의 비율 plotting을 볼 때(Figure 7의 그림), chaotic한 부분은 large negative curvature(노란부분)로 eigenvalue plotting에서 나타나게 되므로 고 차원의 정보까지 plotting이 가능한것을 알 수 있다.
N 차원의 loss surface 정보들을 taylor expansion으로 근사화 한 후 해당 eigenvalue들에 대한 최솟값/최댓값의 절댓값을 plotting 한 결과가 Figure 7이다. 따라서 전체 차원에 대한 곡률정보를 담고 있으므로 고 차원에 숨겨진 non-convexity또한 저 차원인 2D 사진에 표현이 될 것이다.
참고로 Hessian matrix 계산 시 필요한 Taylor expansion의 eigenvalue의 모든 값이 양수면 함수는 극소, 모든 값이 음수면 함수는 극대, 음과 양의 고유값을 모두 가지면 saddle point로 판단한다.
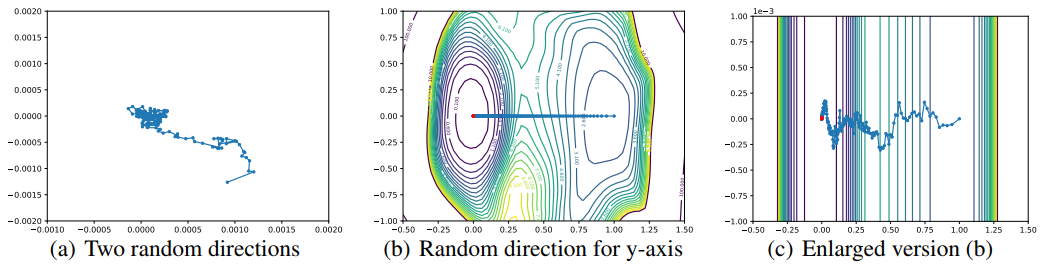
Figure 8. Optimizer 궤적의 효과적이지 못한 시각화 예시. 이러한 시각화 방법들은 고차원에서의 random dirction의 직교성으로 인해 제대로 동작하기 힘들다.
7. Visualizing Optimization Paths
마지막으로, 서로 다른 optimizer의 궤적(trajectory)들을 시각화 하는 방법에 대해 탐구한다. 이 application의 경우, random direction은 효과적이지 못하다. 논문에서는 왜 random direction이 효과적이지 못한지에 대한 이론적인 설명과 함께 효과적으로 loss function contour의 위에 궤적(trajectory)을 효과적으로 plotting하는 방법에 대해 연구한다.
몇몇의 저자들이 왜 random direction이 optimization 궤적의 변화를 capture하는것이 실패하는지에 대한 연구했다[10, 29, 28, 27]. Figure 8에선 실패한 시각화에 대한 예시를 보인다. Figure 8(a)에서는 SGD가 두 random direction으로 정의되는 평면에 반복적으로 영사한(나타낸) 궤적을 보인다. 실제로 움직임(motion)이 거의 capture 되지 않았다(참고로 축방향으로 엄청나게 확대 되어있으며 random하게 움직이는듯 함). 이러한 문제는 [13]에서 발견되었으며, 이를 위한 solution으로 one random direction을 이용하여 궤적을 초기화하였다. 이 방접근법은 Figure 8(b)에 나와있다. Figure 8(c)는 random axis가 거의 변화가 없으므로 직선 경로로 잘못된 optimization path를 보인다.
7.1. Why Random Directions Fail: Low-Dimensional Optimization Trajectories
고 차원의 공간에 존재하는 두 random vector들은 높은 확률로 직교한다는것은 잘 알려져있다. 사실 예상되는 $n$ 차원의 Gaussian random vector들간의 cosine similarity는 대략적으로 $\sqrt{2/(\pi n)}$이다([12], Lemma 5). 하지만 이러한것들은 저 차원 공간에 optimization 궤적이 존재할 때 문제가 된다. 이런 경우 random하게 선택된 vector가 optimization path를 포함하는 low-rank 공간에 orthogonal하게 존재하게 되며, random direction의 projection의 변화가 거의 없게 된다. Figure 8(b)는 optimization 궤적이 저 차원이라는 것을 제안하는데, random direction이 random direction이 optimization path를 따라 가리키는(points) 벡터보다 적은 크기의 변화를 포착(capture)하기 때문이다. 아래에서는 PCA directions를 이용하여 직접적으로 이러한 low dimensionality를 증명하엿으며, 효과적인 시각화 자료를 만들어냈다.
7.2. Effective Trajectory Plotting using PCA Directions
궤적의 변화를 포착(capture)하기 위해서, 논문에서는 non-random(and carefully chosen) direction이 필요하였다. 여기서 논문은 얼마나 변화가 포작되었는가를 감지할 수 있는 PCA를 기반으로 한 접근 방식을 제안하고 이를 이용해 loss surface의 contour를 따라 이러한 궤적(trajectory)들을 plot하였다.
$\theta_{i}$를 $i$번째 epoch의 model parameter라 하고, 학습과정에서 $n$ epoch 뒤의 마지막 parameter들을 $\theta_{n}$이라 하자. 주어진 n번의 epoch동안의 학습에서, matrix $M=\begin{bmatrix}\theta_{0}-\theta_{n} ; \cdots ; \theta_{n-1}-\theta_{n}\end{bmatrix}$에 PCA를 적용하고, 다음으로 두개의 explanatory(설명하기 위한) direction을 선택한다. Figure 9에선 PCA direction을 따라 optimizer의 궤적(파란 점)과 loss surface를 확인 할 수 있다. Learning rate가 감소되는 epoch에 대한 결과는 빨간 점으로 나타나있다. 각각의 축에 대해 PCA direction에 의해 포착된 하강(descent) path의 변화가 측정되어 있다.
Figure 9. VGG-9의 nurmalized PCA direction을 이용하여 영사된 learning trajectories. 각 subfigure의 왼쪽이 batch size 128일 때, 우측이 batch size 8192일 때이다.
학습 초반의 stage에서는 loss surface의 contour로 수직하게(perpendicular) path가 움직이는 경향이 있었으며, 즉 비 확률적(non-stochastic) gradient descent로부터 기대할 수 있는 것처럼 gradient 방향을 따르게 된다.(gradient가 큰 방향으로 loss가 감소하게 된다는 것을 의미) 확률성(stochasticity)은 점점 training의 뒤 stage로 갈수록(학습의 후반부에 갈수록) 여러 plot들에 대해 뚜렷해진다. 이러한 현상은 weight decay와 small batch를 사용하는 경우 더 도드라진다(batch가 작을수록 gradient noise가 많아지고, 결정론적(deterministic) gradient direction으로부터 더 급진적(radical)으로 출발(departure)하게 됨). (즉, batch가 작아질수록 noise성분이 많아져 더 빠르게 minima에 도달 할 수 있게 된다는 의미) Weight decay와 small batch가 사용된 경우, contour와 거의 평행한 방향으로 path가 변하는 것을 볼 수 있으며 stepsize가 클수록(radical departure) solution을 orbit(궤도에 진입)시킬 수 있게 된다. Stepsize가 빨간 점처럼 떨어지게 될 경우, system의 효과적인 noise는 감소하게 되며, path가 가장 가까운 local minimizer에 빠지면 구부러지기(kink) 시작하는것을 확인 할 수 있다.
마지막으로, descent path를 매우 낮은 차원에서 관찰하였는데, 오직 2차원의 공간에 descent path의 변화(variation)의 40~90%가 존재한다는 것을 알 수 있다. Figure 9의 optimization trajectories는 가까운 attractor direction으로의 움직임(movement)에 의해 지배적인것(dominated by)으로 보인다. 이러한 low dimensionality는 non-chaotic landscape들이 wide, nearly convex minimizer들에 의해 지배적이게 되는 것데 대해 관찰한 Section 6의 관찰과 호환 될 수 있다.
8. Conclusion
논문에서는 network 구조, optimizer 선택, batch size를 포함하는 neural network practitioner의 다양한 선택의 결과에 대한 통찰력을 제공하는 시각화(visualization) technique을 제안했다. Neural network들은 복잡한 가정(assumption)을 가진 입증되지 않은(anecdotal) 지식(knowledge)과 이론적인 결과를 바탕으로 최근 극적으로(dramatically) 발전하였다. (연구의) 진척(progress)이 계속되기 위해서는 neural network의 구조에 대한 일반적인 이해가 더 필요하다. 효과적인 시각화(visualization)가 이론의 지속적인 발전과 결합되면 보다 빠른 training, 단순한 모델구조, 그리고 더 나은 일반화(generalization)가 가능해 질 것으로 기대된다.
스택 (stack)은 기본적인 자료구조 중 하나로, 컴퓨터 프로그램을 작성할 때 자주 이용되는 개념이다. 스택은 자료를 넣는 (push) 입구와 자료를 뽑는 (pop) 입구가 같아 제일 나중에 들어간 자료가 제일 먼저 나오는 (LIFO, Last in First out) 특성을 가지고 있다.
1부터 n까지의 수를 스택에 넣었다가 뽑아 늘어놓음으로써, 하나의 수열을 만들 수 있다. 이때, 스택에 push하는 순서는 반드시 오름차순을 지키도록 한다고 하자. 임의의 수열이 주어졌을 때 스택을 이용해 그 수열을 만들 수 있는지 없는지, 있다면 어떤 순서로 push와 pop 연산을 수행해야 하는지를 알아낼 수 있다. 이를 계산하는 프로그램을 작성하라.
첫 줄에 n (1 ≤ n ≤ 100,000)이 주어진다. 둘째 줄부터 n개의 줄에는 수열을 이루는 1이상 n이하의 정수가 하나씩 순서대로 주어진다. 물론 같은 정수가 두 번 나오는 일은 없다.
문제 자체를 이해하는데 있어서 상당한 시간이 걸렸다.
이 문제가 어떻게 돌아가는지 예시를 들어서 이해해봤다.
입력
8 4 3 6 8 7 5 2 1 인 경우(길이 8)
Input
Stack
출력
수열
4
4
+
3
+
2
+
1
+
Input
Stack
출력
수열
-
4
~~4~~
+
3
+
2
+
1
+
Input
Stack
출력
수열
3
-
4
~~4~~
+
3
+
2
+
1
+
Input
Stack
출력
수열
-
3
-
4
~~4~~
+
~~3~~
+
2
+
1
+
Input
Stack
출력
수열
6
6
+
5
+
-
3
-
4
~~4~~
+
~~3~~
+
2
+
1
+
Input
Stack
출력
수열
-
6
~~6~~
+
5
+
-
3
-
4
~~4~~
+
~~3~~
+
2
+
1
+
Input
Stack
출력
수열
8
8
+
7
+
-
6
~~6~~
+
5
+
-
3
-
4
~~4~~
+
~~3~~
+
2
+
1
+
… (Stack 내부의 숫자가 위에서 아래 순서대로 지워진다.)
Input
Stack
출력
수열
7
-
7
8
-
8
~~8~~
+
~~7~~
+
-
6
~~6~~
+
5
+
-
3
-
4
~~4~~
+
~~3~~
+
2
+
1
+
…
Input
Stack
출력
수열
1
-
1
2
-
2
5
-
5
-
7
-
8
~~8~~
+
~~7~~
+
-
6
~~6~~
+
~~5~~
+
-
3
-
4
~~4~~
+
~~3~~
+
~~2~~
+
~~1~~
+
뽑아내야 할 값이 현재 스택에 없어서 저장 후 뽑아내야 하는 값이라면 push를 통해 해당 수를 만들고 바로 pop을 1번 수행해 그 수를 뽑아낸다.
즉, 만일 뽑아내야 할 값이 스택에 현재 있는 값이라면 pop을 수행해야 하므로 stack에 해당 값의 유무에 상관없이 무조건 1회의 pop이 수행되어야 한다.
위의 예시에서, 8 4 3 6 8 7 ~~5~~ 2 1 로 5를 제외하고 뽑아내야 하는 경우는 출력 불가능하다(Stack은 LIFO)
즉, pop 연산을 통해 최상위 값만 뽑아낼 수 있는 경우를 제외하곤 모두 “NO”를 출력해야 한다.
정답
classStack:def__init__(self):self.len=0self.list=[]defpush(self,num):self.list.append(num)self.len+=1defpop(self):ifself.size()==0:return-1pop_result=self.list[self.len-1]delself.list[self.len-1]self.len-=1returnpop_resultdefsize(self):returnself.lendefempty(self):return1ifself.len==0else0deftop(self):returnself.list[-1]ifself.size()!=0else-1num=int(input())# 몇 개의 숫자를 입력 받을지
stack=Stack()# 문제풀이를 위한 Stack 객체 선언
inputs=[]# 입력 저장용 list
outputs=[]# 출력 저장용 list
index=0# 입력을 받아 inputs 리스트 저장
forjinrange(num):inputs.append(int(input()))# 각 loop의 시작점마다 push
forjinrange(1,num+1):stack.push(j)outputs.append('+')# index가 전체 숫자 개수보다 크고 스택의 맨 위 숫자가 현재번째 숫자와
# 같지 않다면 수열을 만들 수 없는 상태가 됨
# 그러한 경우 while문 안에서 pop을 수행하지 못해 스택에 숫자가 남아있게 됨
whileindex<numandstack.top()==inputs[index]:stack.pop()outputs.append('-')index+=1# 위의 while문에 따라 스택에 숫자가 남아있게 되면 수열을 만들지 못한것이므로 NO를 출력
ifnotstack.empty():print('NO')else:forjinoutputs:print(j)

 Seongkyun Han's blog
Seongkyun Han's blog