Seongkyun Han's blog
Seongkyun Han's blog
CH8. 트리(Tree) 1-1 (트리의 개요)
05 Jun 2019 | data structure 자료구조CH8. 트리(Tree) 1-1 (트리의 개요)
- 비선형 자료구조를 다루는 첫 번째 자료구조
- 선형/비선형 자료구조는 자료구조에 대해 접근하는 방식이 다름!
- 선형: Data를 저장하는 개념으로 접근!
- 비선형: Data를 표현하는 개념으로 접근!
- Data의 표현에 저장이라는 개념이 포함됨
- 즉, 비선형 자료구조는 data를 표현하는 방식을 제시함
8-1 트리의 개요
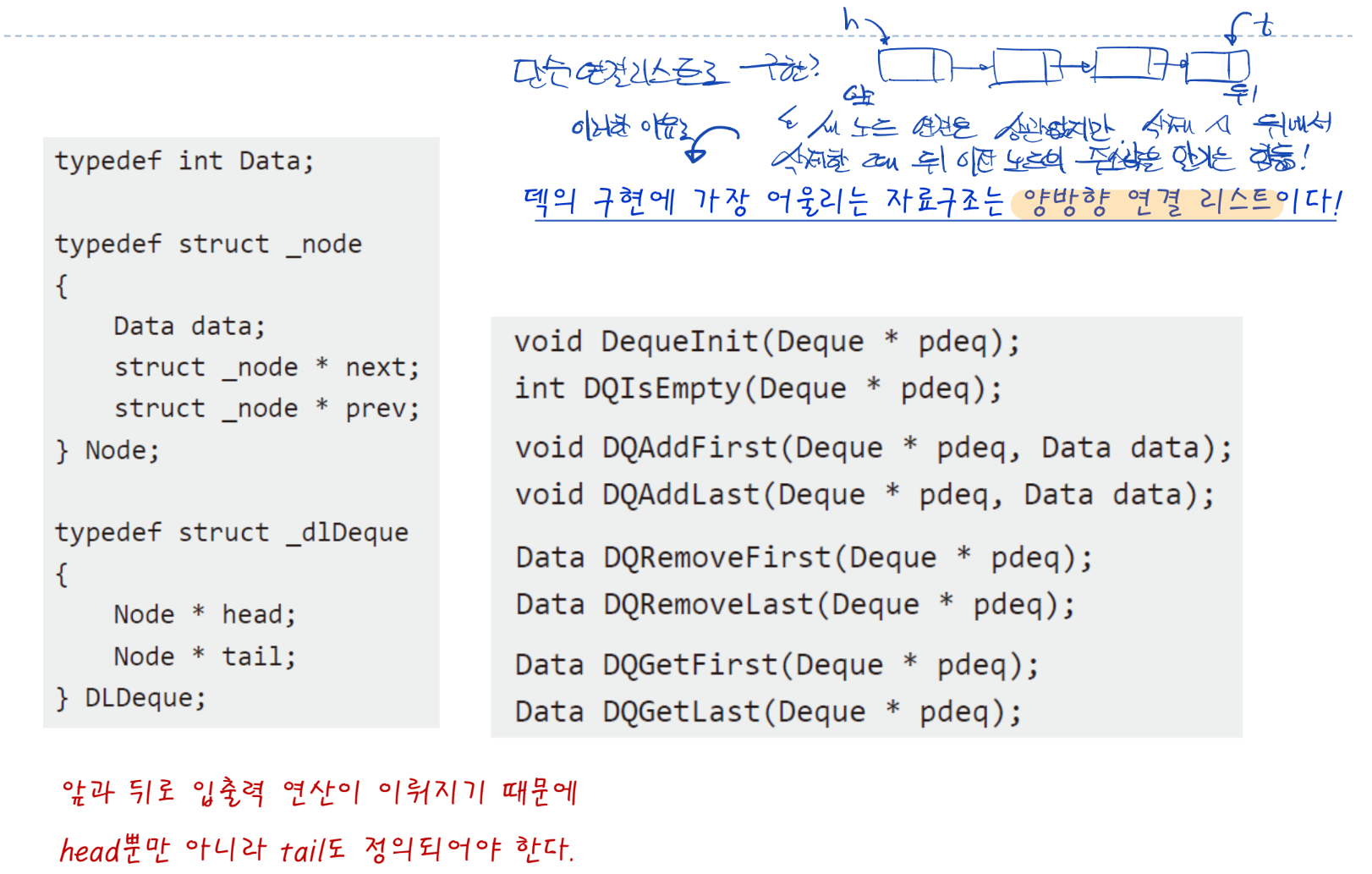
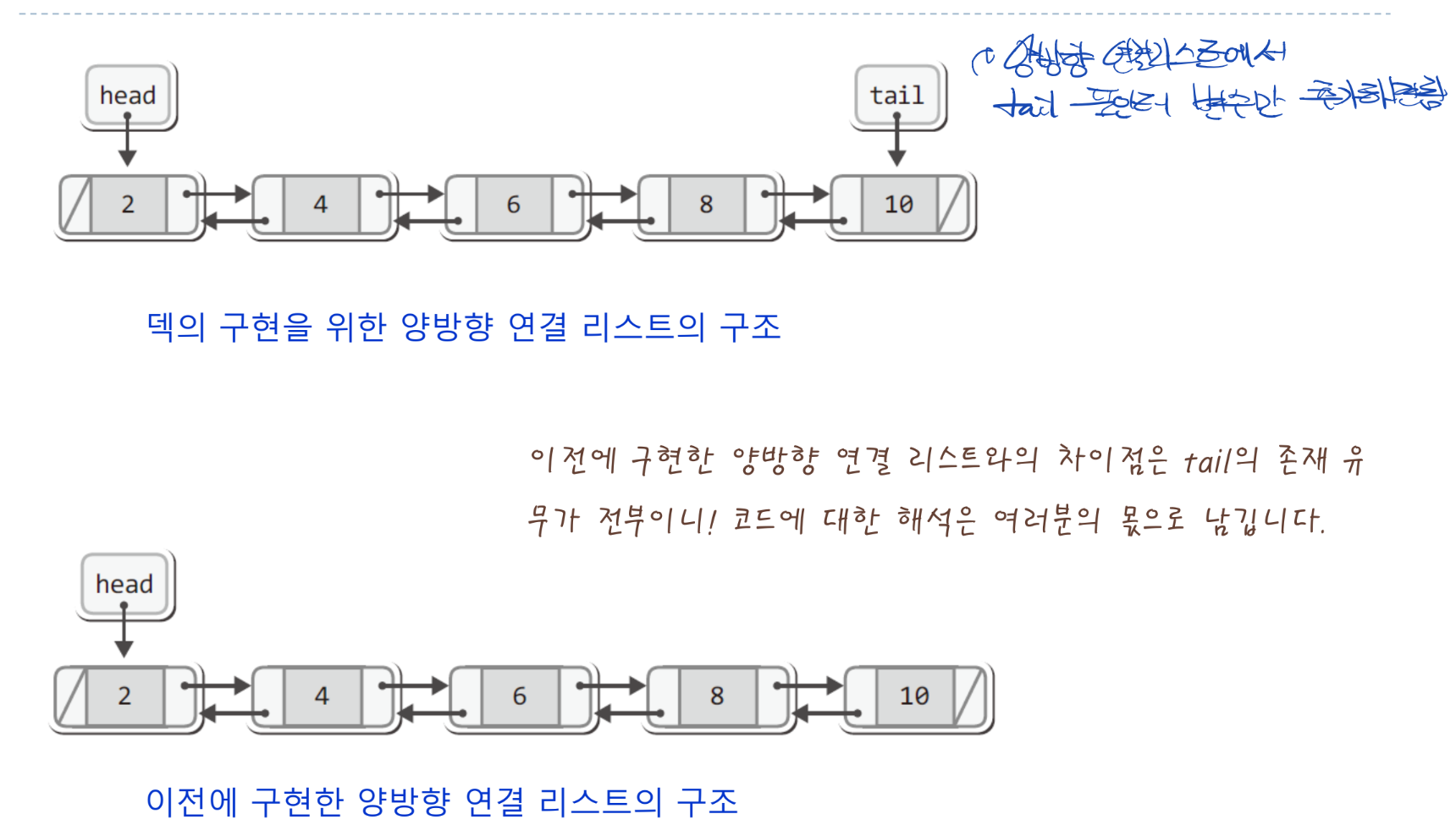
- 연결리스트와 트리의 비교
- 연결리스트를 정의하는 구조체?
- 노드의 추가, 삭제, 탐색을 위한 변수 만 정의되어있음
- 연결리스트면 포인터 변수, 배열기반이면 배열의 index
- 주로 data의 삽입, 삭제, 탐색 을위한 함수만 정의됨
- 그 과정에서 자동으로 노드의 추가, 삭제가 부수적으로, 자동으로 이루어짐
- 노드 자체의 삽입/삭제에 대한 함수는 정의되지 않음
- 노드를 직접적으로 control 하는 함수는 없는 꼴
- 즉, 연결리스트에서는 자료구조를 data의 저장이라는 개념 중심으로 접근
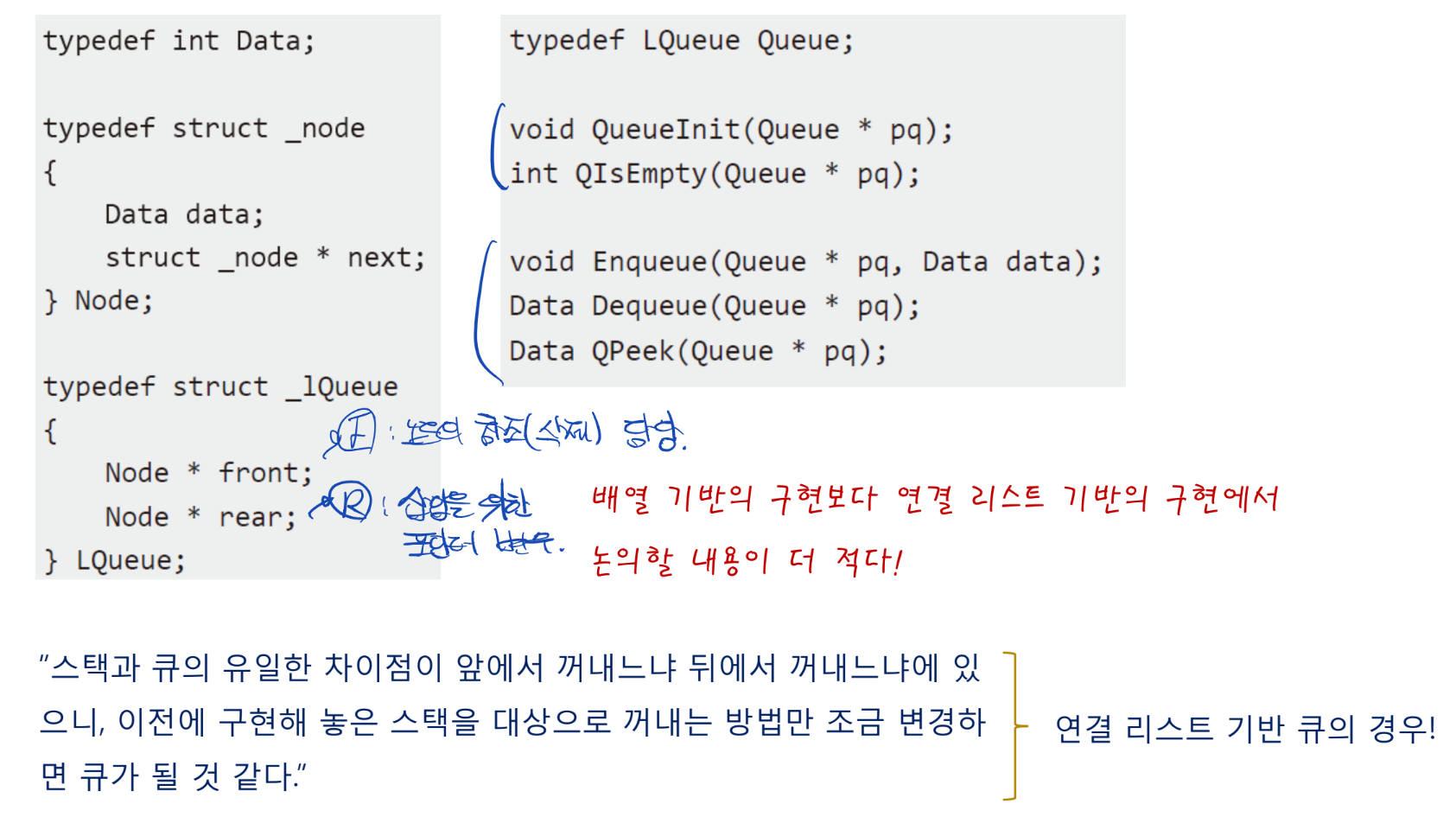
- 트리를 정의하는 구조체?
- 구조체 정의 자체가 연결리스트와 동일하지 않음!
- 직접적으로 노드를 control 하는 함수를 정의
- 즉, 트리 자체를 갖다 만드는, 노드 자체를 추가, 조합, 컨트롤하는 함수를 만듦
- Tree 자체를 만드는 도구를 정의하게 됨
- Data의 저장은 부수적인것일 뿐 중요하지 않음!
- 트리 자체를 만드는 도구를 기반으로 다양한 data를 표현하기 위해 도구 자체를 만듦
- 우선 트리를 구성하는 도구를 만들고
- 그 도구를 이용해 무엇인가를 표현 함.
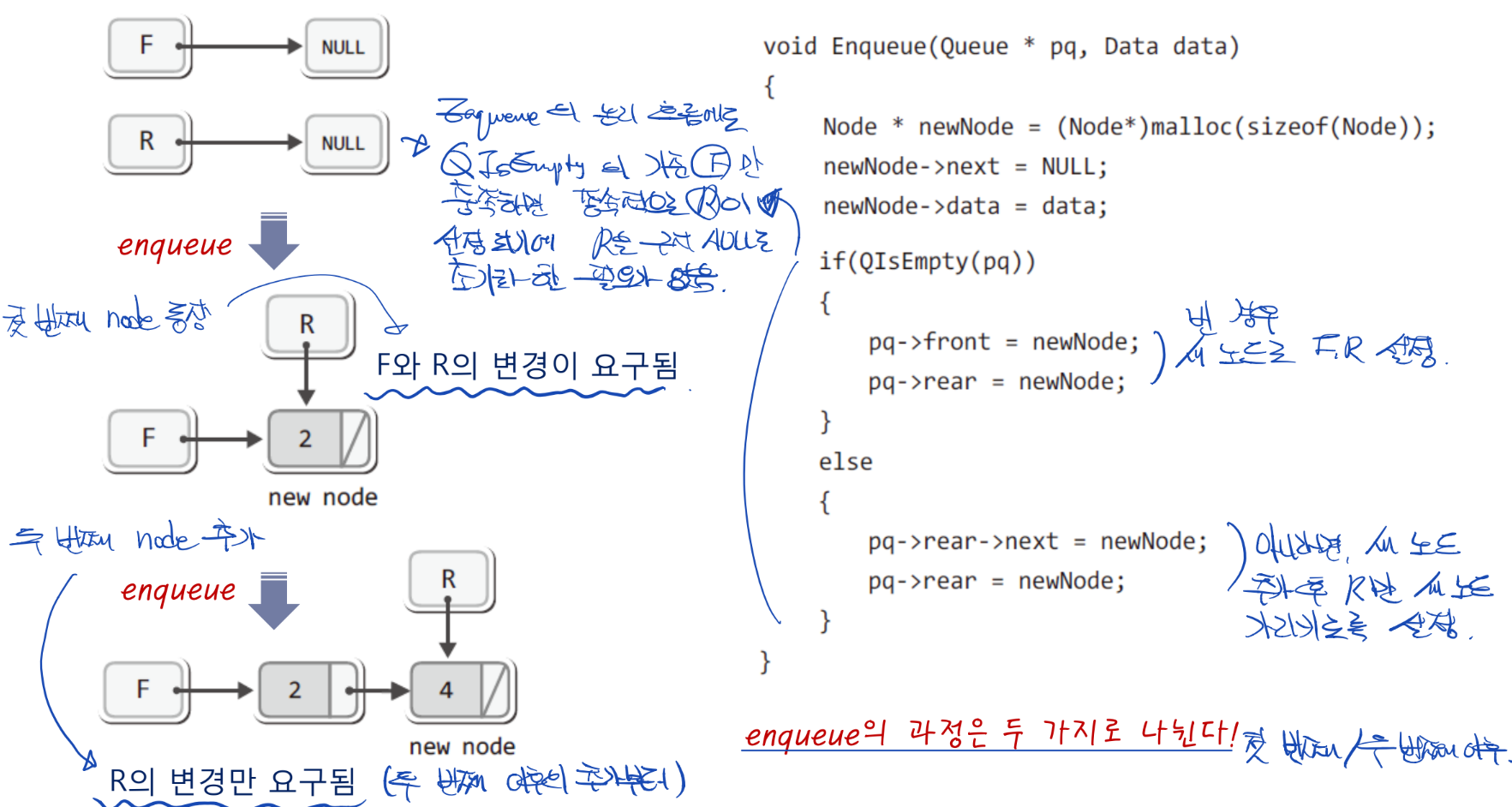
- 연결리스트의 함수는 data의 저장, 삭제, 탐색을 위한 함수로 자동으로 노드가 삽입, 삭제 됨
- 트리는 data의 저장이 아닌 직접 노드 자체를 연결/끊는 여러 도구들을 만듦
- 트리는 두 단이면 펼쳤을 때 연결리스트와 동일한 모양이지만, 형태 자체는 중요하지 않음
- 또한 트리의 구현에 사용되는 노드는 배열 기반이건 연결리스트 기반이건 노드라는 자체가 중요하지 안에 형식은 중요하지 않음!
- 앞에서 배웠던 노드를 기반으로 구현
트리의 접근과 이해
- 트리는 계층적 관계를 표현하는 자료구조임
- 트리: 하나의 중심점을 기점으러 뻗어나가는 구조라는 의미
- 트리를 만드는 도구를 먼저 정의하는 이유?
- 트리로 표현 가능한 많은 형태의 data들을 모두 표현하도록 기반작업을 하는 것!
- 도구를 이용하여 모든 형태의 트리들을 다 표현 가능하도록!
- 트리로 표현 가능한 많은 형태의 data들을 모두 표현하도록 기반작업을 하는 것!
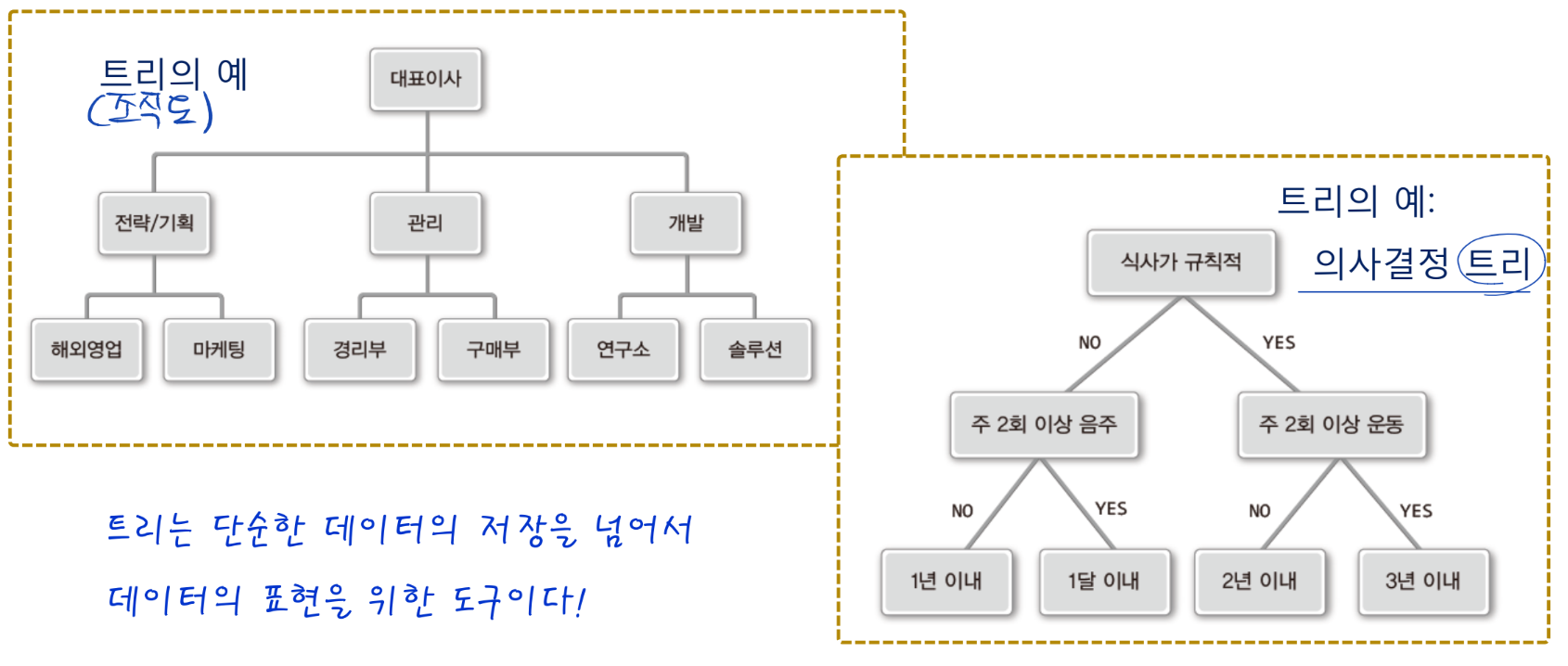
트리 관련 용어의 소개
- 트리 공부할때 자만하지 말라고 강사님이..
- 용어는 아래와 같이 사용하되, 노드 자체는 연결리스트의 노드와 기본적으로 동일하지만 완전히 같다고 생각하면 안됨!
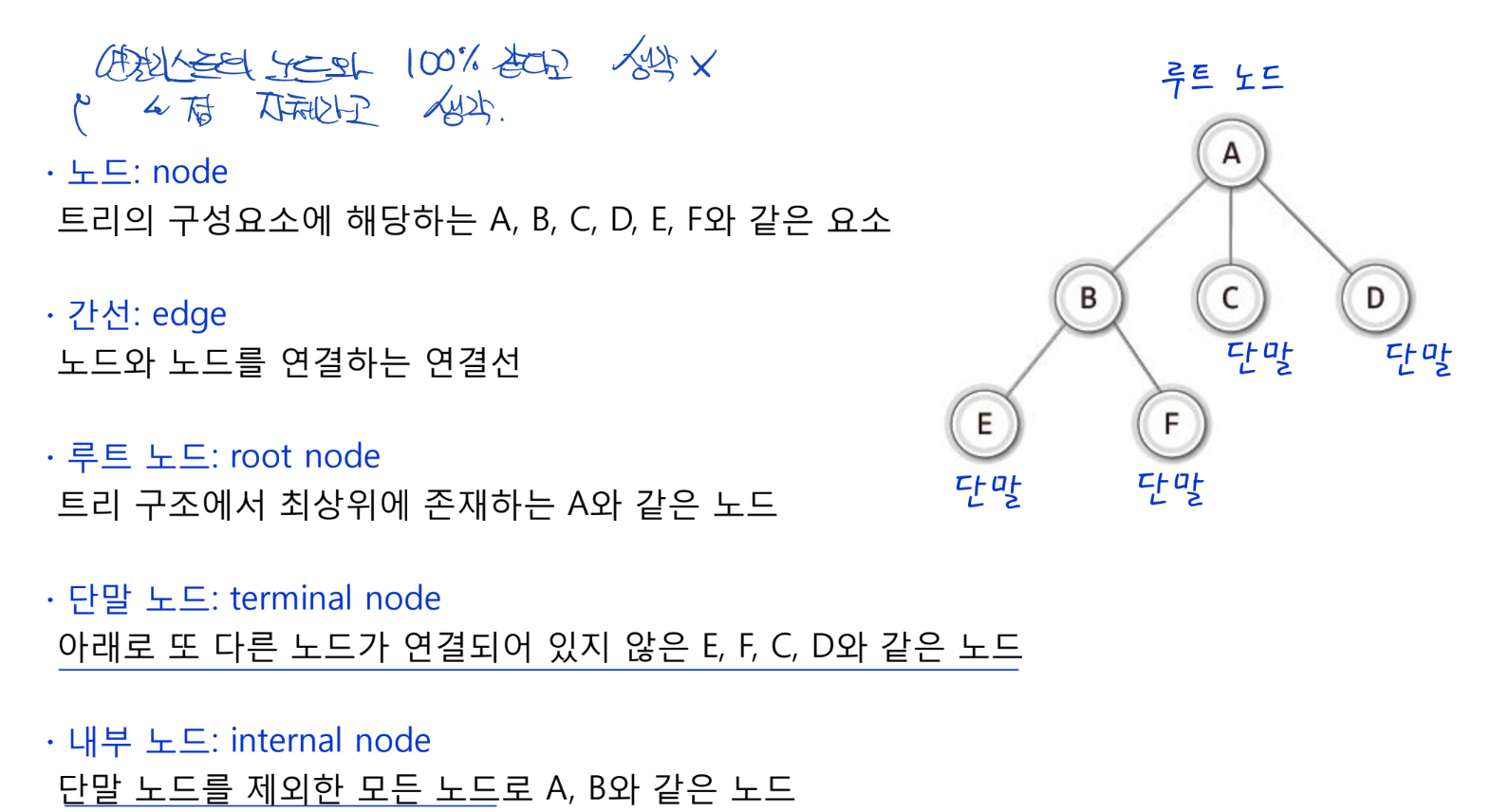
트리의 노드간 관계
- 트리는 계층적으로 해석
- 트리 노드간의 관계는 상대적인 관계
- 항상 부모노드일수도, 항상 자식노드일수 없음.
- 상대적 관계에 의해 정의되므로 비교대상에 따라 달라짐
- 항상 부모노드일수도, 항상 자식노드일수 없음.
- 동일 부모를 둔 노드라면 형제 노드로 정의!
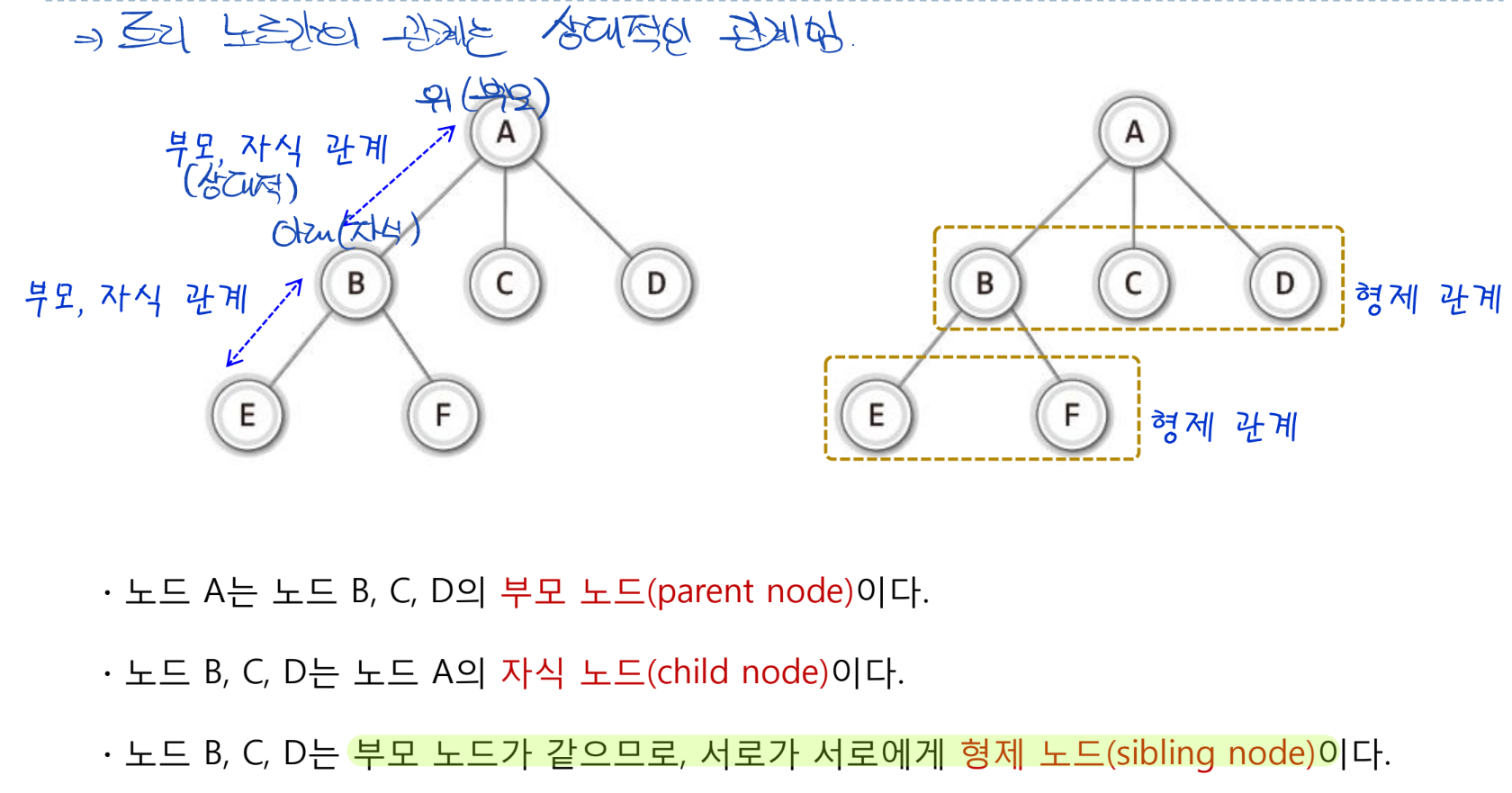
- 트리는 다양한 서브트리를 갖고 잇으며, 서브트리 또한 다른 서브트리로 이루어져 있음
- 따라서 구조 자체가 재귀적이므로 ‘재귀’에 대한 제대로된 이해가 필요!