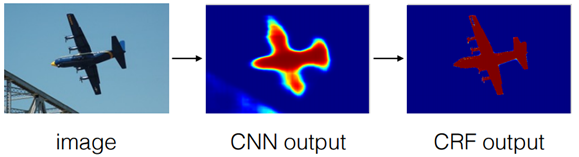
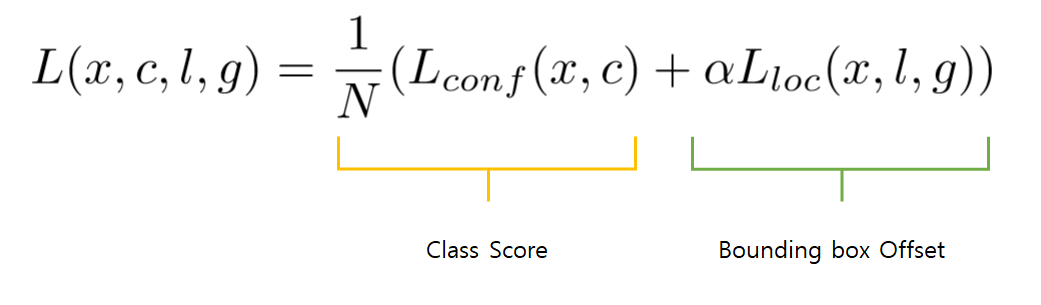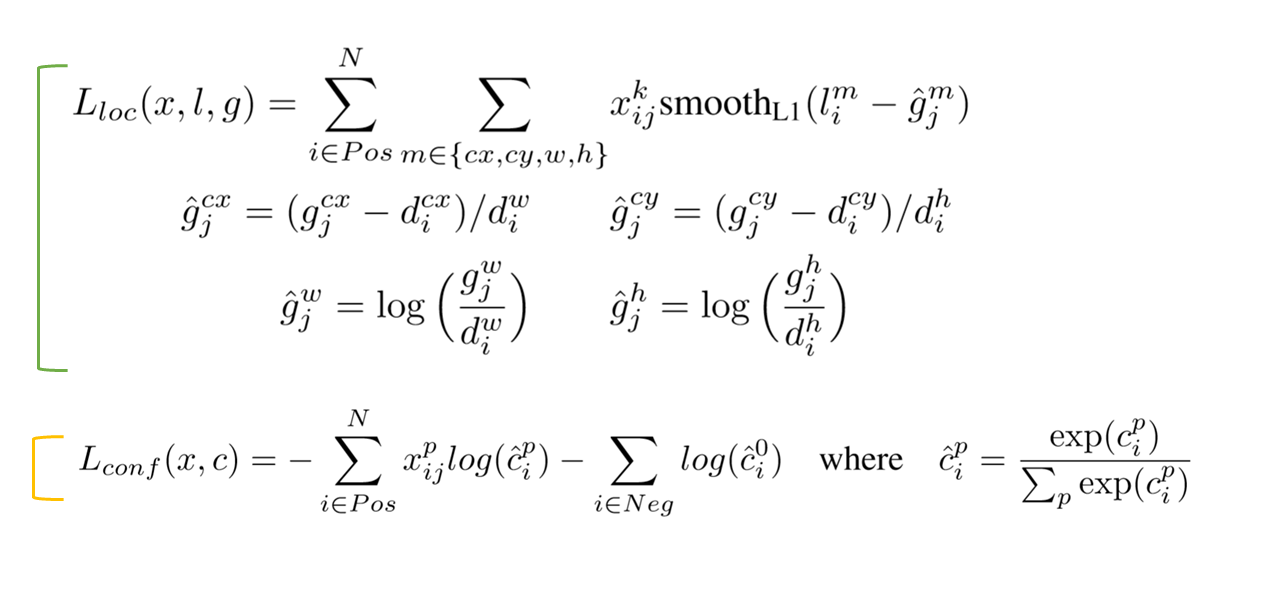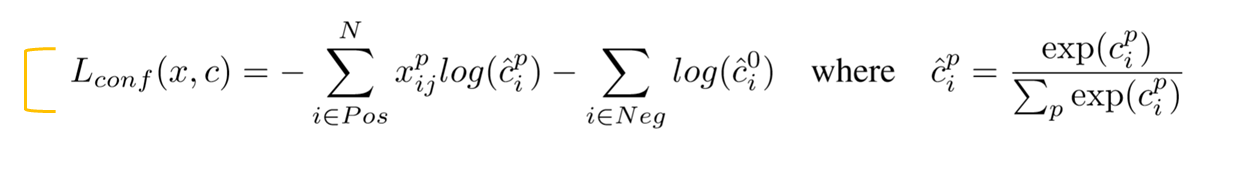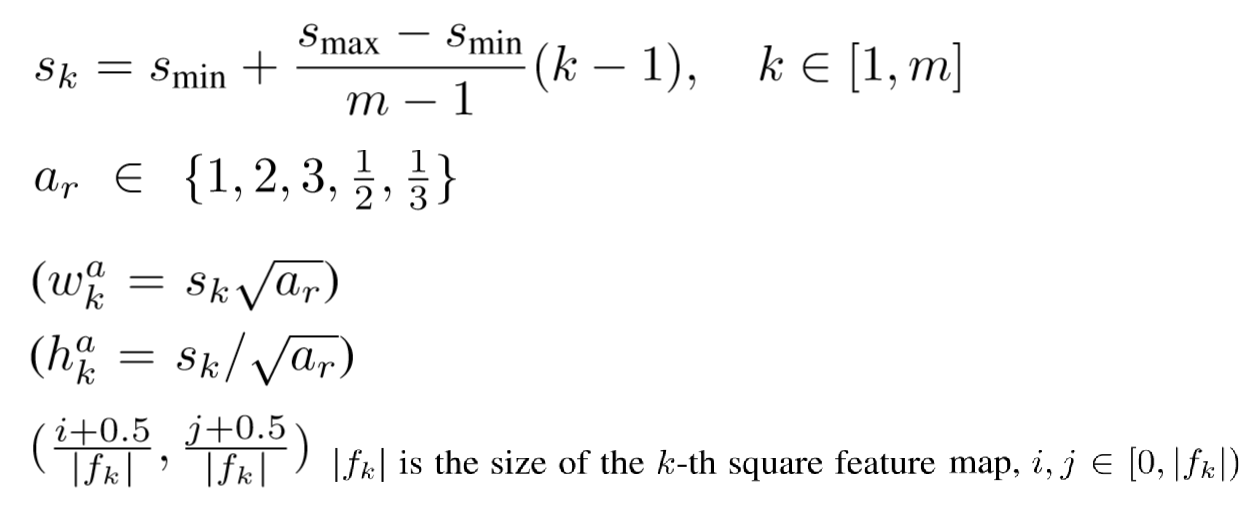DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Original paper: https://arxiv.org/pdf/1606.00915.pdf
Authors: Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille
참고 글
https://laonple.blog.me/221000648527
DeepLab에는 v1과 v2가 있지만, 본 글은 v2에 대해 다루며 앞으로 나오는 DeepLab은 모두 v2이다.
논문 제목에 다 나열되어있듯이 Deep convolutional neural networks(DCNN)와 astrous convolution 및 fully connected CRF 개념을 잘 활용해 semantic segmantation을 더 잘하게 되었다. 재미있는건 DeepLab v1에서는 hole algorithm이라는 용어를 사용했으나, v2부턴 atrous convolution으로 바꿔 부른다
Classification 기반 망을 semantic segmentation에 적용할 때의 문제점
Classification이나 detection은 기본적으로 대상의 존재 여부에 집중하기에 object-centric하며, 강력한 성능을 발휘하기 위해선 여러 단계의 conv+pooling을 거쳐 말 그대로 영상 속에 존재하며 변화에 영향을 받지 않는(robust하게 영향을 덜 받는) 강인한 feature만을 끄집어내야 함
따라서 details보다는 global 한 것에 집중을해야 함
반면 semantic segmentation은 픽셀 단위의 조밀한 예측이 필요한데, classification 망을 기반으로 segmantation망을 구성하게 되면 계속 feature map의 크기가 줄어들기에 detail한 정보를 얻는데 어려움이 있음
그래서 FCN 개발자는 skip layer를 사용하여 1/8, 1/16, 1/32 결과를 결합(concat)하여 detail이 줄어드는 문제를 보강하였으며, DeepLab과 앞서 본 dilated convolution 팀(Fisher Yu)은 망의 뒷 단에 있는 2개의 pooling layer를 없애고 dilated conv(atrous conv)를 사용하여 receptive field를 확장시키는 효과를 얻었으며, 1/8 크기까지만 feature map을 줄이도록 하여 detail한 정보들을 보존함
하지만 1/8까지만 사용하더라도 다음과 같은 문제가 발생
Receptive field가 충분히 크지 않아 다양한 scale에 대응이 어렵다
1/8크기의 정보를 bilinear interpolation을 통해 원 영상 크기로 키우면 1/32 크기를 확장한것보다는 details가 살아있지만 여전히 정교함이 떨어진다
이러한 문제를 DeepLab 팀과 dilated convolution 에서는 다른 방식으로 해결하였으며, dilated convolution 팀은 DeepLab 팀의 atrous conv에서 많은 힌트를 얻은 것으로 보여짐
Atrous convolution
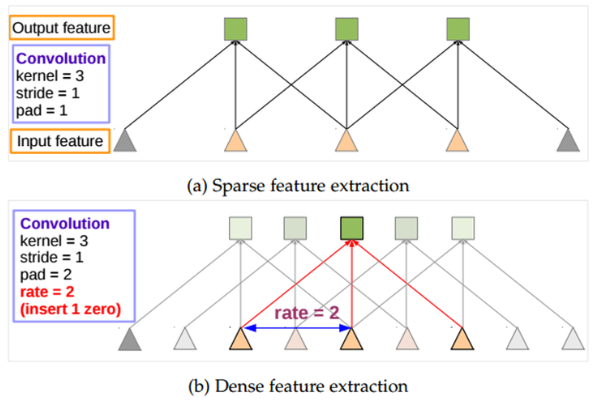
Atrous conv란 wavelet을 이용한 신호 분석에 사용되던 방식이며, 보다 넓은 scale을 보기 위해 중간에 hole(0)을 채워 넣고 convolution을 수행하는 것을 말함
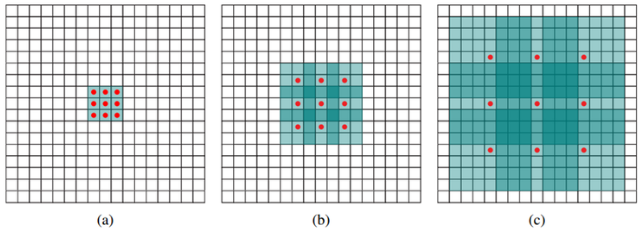
직관적인 이해를 위해 논문의 1차원 conv 그림을 살펴보면
위 그림 (a)는 기본적인 conv이며, 인접 데이터를 이용해 kernel size 3인 conv를 보여줌
(b)는 확장 계수 k가 2인 경우로 인접한 데이터가 아닌 중간에 hole이 1개씩 들어오는 점이 (a)와 차이가 나며, 똑같은 kernel size 3이더라도 대응하는 영역의 크기가 커졌음을 확인 할 수 있음
이처럼 atrous conv(dilated conv)를 사용하면 kernel 크기는 동일히 유지하기에 연산량은 동일하지만 receptive field의 크기가 커지는 효과를 얻을 수 있음
영상 데이터와같은 2차원에 대해서도 아래와같이 좋은 효과가 있는것을 확인 할 수 있음
자세한 설명은 dilated convolution 참고
Atrous convolution 및 bilnear interpolation
DeepLab v2에선 VGG16뿐만 아니라 ResNet101도 DCNN망으로 사용했으며, ResNet 구조를 변형시킨 모델을 이용해 VGG16모델보다 성능이 더 좋아짐
DCNN에서 max-pooling layer 2개를 제거함으로 1/8 크기의 feature map을 얻고, atrous conv를 통해 넓은 RF를 갖도록 함
Pooling 후 동일 크기의 conv를 수행하면 자연스럽게 RF가 넓어짐
논문에선 details때문에 pooling layer를 제거하였기에 이 부분을 atrous conv를 사용해 더 넓은 RF를 가질 수 있도록 하였으며, 이를 통해 pooling layer가 사라졌을때의 문제점들을 해소시킴
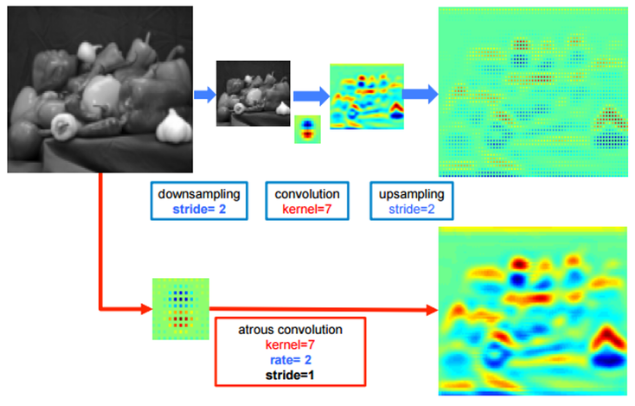
이후FCN이나 dilated conv와 마찬가지로 bilear interpolation을 이용해 원 영상 크기로 복원해냄(아래 그림 참고)
Atrous conv는 RF 확대를 통해 입력에서 feature를 찾는 범위를 넓게 해주기 때문에 전체 영상으로 찾는 범위를 확대하면 좋겠지만, 이렇게 하려면 단계적으로 수행을 해야하기에 연산량 증가가 불가피함
그래서 이 팀은 적정한 선에서 deal을 했으며, 나머지는 모두 bilinear interpolation을 선택함
하지만 bilinear interpolation만으론 정확하게 객체의 픽셀 단위까지 위치를 정교히 segmentation하는게 불가능하므로 뒷부분은 CRF(Conditional Random Field)를 이용하여 post-processing을 수행하도록 함
결과적으로 전체적인 구조는 DCNN+CRF의 형태이며, DCNN의 앞부분은 일반적인 conv를, 뒷부분은 atrous conv를 이용했고 전체 구조는 아래와 같음
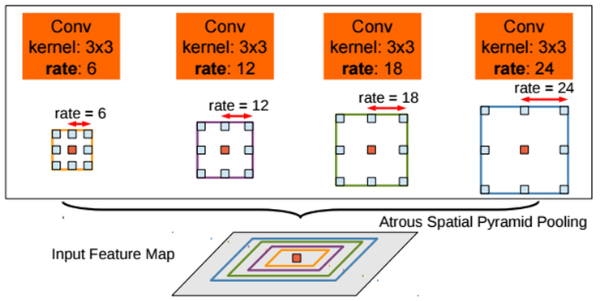
ASPP(Atrous Spatial Pyramid Pooling)
DeepLab v1과 달리 v2에선 multi-scale에 더 강인하도록 fc6 layer에서의 atrous conv를 위한 확장 계수를 아래와같이 6, 12, 18, 24로 적용하고 그 결과를 취합(concat)하여 사용함
ResNet 설계자인 Kaiming He의 SPPNet 논문에 나오는 Spatial Pyramid Pooling 기법에 영감을 받아 ASPP로 이름을 지었으며, 확장 계수를 6부터 24까지 다양하게 변화시켜 다양한 RF가 고려된 feature map을 생성할 수 있도록 함
SPPNet에서의 방식처럼 이전 단계까지의 결과는 동일하게 사용을 하고, fc6 layer에서 atrous conv를 위한 확장계수 r 값만 다르게 적용시킨 후 그 결과를 합치게(concat) 되면 연산의 효율성 관점에서 큰 이득을 얻을 수 있음
참고로 구글의 inception 구조도 여러 RF의 결과를 같이 볼 수 있게 되어있음
논문 저자들의 실험에 따르면 단순히 확장계수 r을 12로 고정하는것보다 ASPP를 지원하여(다양하게 r을 변화시킨 후 그 feature map들을 합침) 1.7%가량의 성능 향상이 있었다고 함
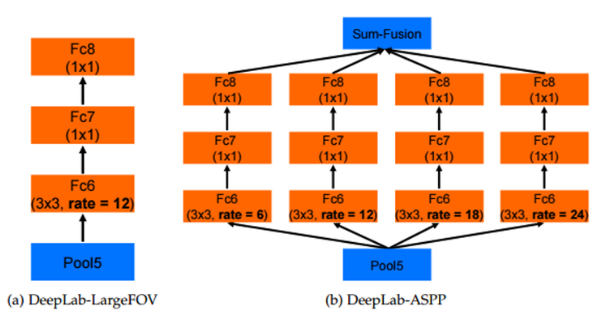
위 그림에서 (a)는 DeepLab v1의 구조이며 ASPP를 치원하지 않는 경우 fc6의 확장 계수를 12로 고정한 경우임
(b)는 v2에서 fc6의 계수를 6, 12, 18, 24로 하여 ASPP를 수행하는 구조를 나타냄
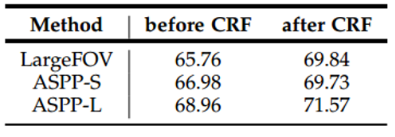
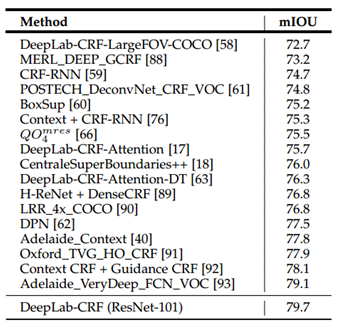
성능은 아래 표와 같음
표에서 LargeFOV는 기존처럼 r=12로 고정한 경우이며, ASPP-S가 r이 2, 4, 8, 12로 좁은 RF만 커버하는 branch들을 사용한 경우, ASPP-L은 r이 6, 12, 18, 24로 넓은 RF를 커버하는 branch를 갖도록 ASPP를 수행한 경우임
실험에 사용한 네트워크는 VGG16이며 결과는 scale을 고정시키는것보다는 multi-scale을 사용했을때의 성능이 좋았고, 좁은 RF보단 넓은 RF를 갖는 branch들을 사용하는게 성능이 더 좋은것을 알 수 있음
Fully Connected CRF
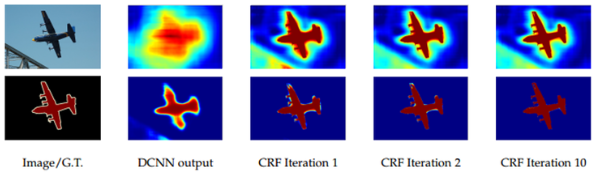
앞의 것들만 사용하더라도 FCN보다는 결과가 좋지만, 아래 그림처럼 CRF(Conditional Random Field)를 사용하는 후보정 작업을 해주면 결과가 더 좋아지는것을 확인 할 수 있음
일반적으로 1/8크기 해상도를 갖는 DCNN 결과를 bilinear interpolation을 통해 원영상 크기로 확대하면 아래처럼 해상도가 떨어지는 문제가 있음
DeepLab 구조에서는 이 문제 해결을 위해 CRF(Conditional Random Field)를 사용하는 후처리를 이용해 성능을 향상시킴
왜 CRF(Conditional Random Field)가 필요한가?
Classification과 같이 object-centric한 경우 가능한 높은 수준의 공간적인 불변성(spatial invariance)를 얻기 위해 여러 단계의 conv+pooling을 통해 영상 속에 존재하며 변화에 영향을 크게 받지 않은 강인한 특징을 추출해야하며, 이로인해 detail한 정보보단 global한 정보에 집중하게 됨
반면 semantic segmenation은 픽셀 단위의 조밀한 예측이 필요해 classification 네트워크 기반으로 segmentation 망을 구상하게 된다면 계속 feature map의 크기가 줄어들게되는 특성상 detail한 정보들을 잃게 됨
이 문제에 대한 해결책으로 FCN에선 skip connection을 사용하였고, dilated conv나 DeepLab에서는 마지막에 오는 pooling layer 2개를 없애고 dilated/atrous conv를 사용함
하지만 이러한 방법을 사용하더라도 분명히 한계는 존재하기에 DeepLab에서는 atrous conv에 그치지 않고 CRF를 후처리 과정으로 사용하여 픽셀 단위 예측의 정확도를 더 높일 수 있게 됨
Fully Connected CRF
일반적으로 좁은 범위(short-range)의 CRF는 segmentation을 수행한 뒤 생기는 segmentation noise를 없애는 용도로 많이 사용됨
하지만 앞서 살펴본 것처럼 DCNN에서는 여러 단계 conv+pooling을 거치며 feature map의 크기가 작아지게 되고 이를 upsampling을 통해 원 영상 크기로 확대하기에 이미 충분히 smoothen되어있는 상태이며, 여기에 기존처럼 short-range CRF를 적용하면 결과가 더 나빠지게 됨
Noise 성분도 같이 upsampling 되므로
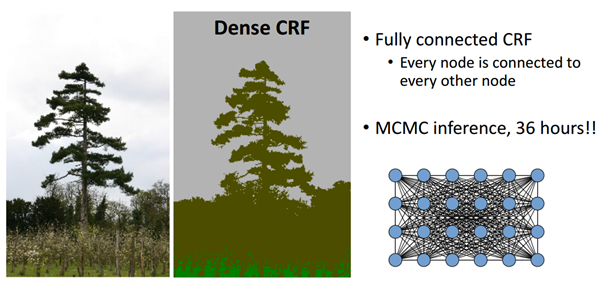
이에 대한 해결책으로 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials (Philipp Karahenbuhl)라는 논문이 발표되었으며, 해당 논문에선 기존에 사용되던 short-range CRF대신 전체 픽셀을 모두 연결한 (fully connected) CRF 방법을 개발해 놀라운 성능향상을 얻어내었고 이 후 많은 사람들이 fully connected CRF를 후처리에서 사용하게 됨
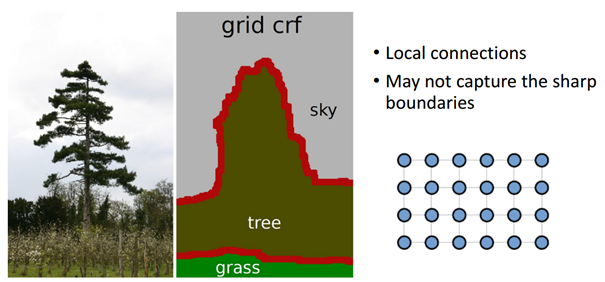
기존에 사용되던 short-range CRF는 아래 그림처럼 local connection 정보만을 사용함
이렇게되면 details 정보가 누락되게 됨
반면 fully connected CRF를 사용하면 아래처럼 detail 정보들이 살아있는 결과를 얻을 수 있음
위처럼 MCMC(Markov Chain Monte Carlo) 방식을 사용할 경우 좋은 결과가 나오지만 연산량이 많다는 단점이 있어 적용이 불가했으나, Philipp Karahenbuhl의 논문에선 이를 0.2초만에 효과적으로 연산가능하게 함
Philipp Karahenbuhl는 일명 mean field approximation 방법을 적용해 message passing을 사용한 iteration 방법을 적용하여 효과적으로 빠른 fully connected CRF를 수행 가능하도록 함
여기서 mean field approximation이란 물리학이나 확률이론에서 많이 사용되는 방법으로, 복잡한 모델을 설명하기 위해 더 간단한 모델을 선택하는 방식을 의미함. 수많은 변수들로 이루어진 복잡한 관계를 갖는 상황에서 특정 변수와 다른 변수들의 관계의 평균을 취하게 되면, 평균으로부터 변화(fluctuation)를 해석하는데도 용이하고, 평균으로 단순화/근사화된 모델을 사용하면 전체를 조망하기에 좋아짐
CRF의 수식을 보면 unary term과 pairwise term으로 구성됨. 아래의 식에서 x는 각 픽셀의 위치에 해당하는 픽셀의 label이며, i와 j는 픽셀의 위치좌표를 나타냄. Unary term은 CNN 연산을통해 얻어질 수 있으며, 픽셀간의 detail한 예측에서 pairwise term이 중요한 역할을 함. Pairwise term에서는 마치 bi-lateral filter에서 그러듯이 픽셀값의 유사도와 위치적인 유사도를 함께 고려함
위 CRF 식을 보면, 2개의 가우시안 커널로 구성된 것을 볼 수 있으며 표준편차 $\rho_{\alpha}, \rho_{\beta}, \rho_{\gamma}$를 통해 scale을 조절 할 수 있음. 첫 번째 가우시안 커널은 비슷한 컬러를 갖는 픽셀들에 대해 비슷한 label이 붙을 수 있도록 하며, 두 번째 가우시안 커널은 원래 픽셀의 근접도에 따라 smooth 수준을 결정함. 위 식에서 $p_{i}, p_{j}$는 픽셀의 위치(position)를 나타내며 $I_{i}, I_{j}$는 픽셀의 컬러값(intensity)임
이것을 고속처리하기 위해 Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현 할 수 있게되어 고속 연산이 가능해짐
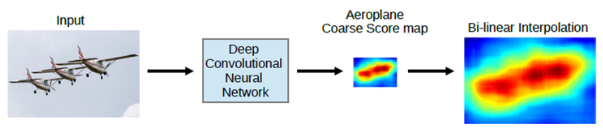
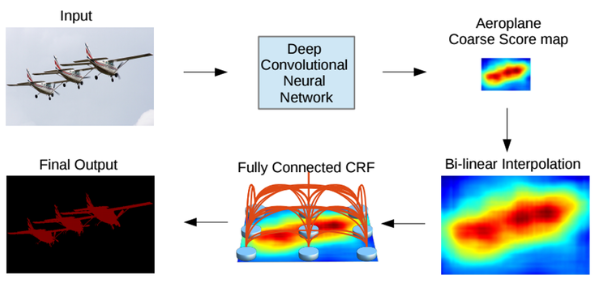
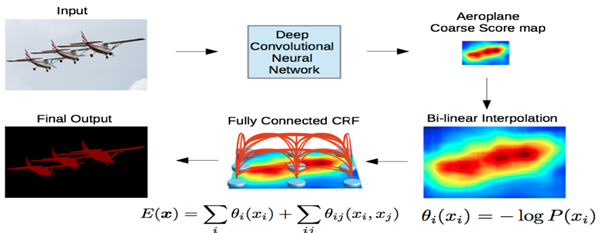
DeepLab의 동작 방식
CRF까지 적용된 DeepLab의 최종 동작방식은 아래와 같음
DCNN을 통해 1/8 크기의 coarse score-map을 구하고, 이것을 bilinear interpolation을 통해 원영상 크기로 확대시킴. Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은 CRF의 unary term에 해당함. 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있음
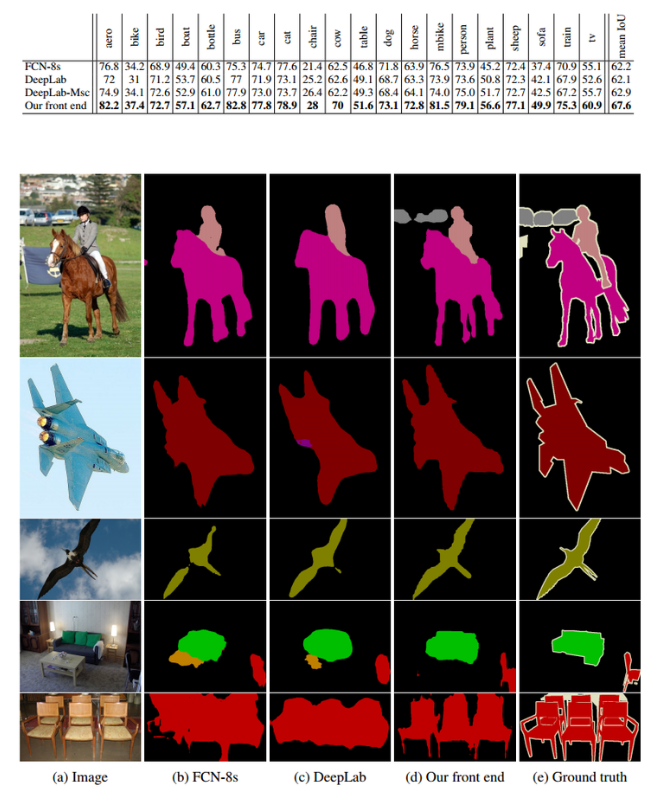
DeepLab 최종 결과
DeepLab v1은 VGG16 기반이며 ASPP가 적용되지 않음
DeepLab v2의 경우 ResNet-101 기반이기에 아래 그림처럼 실험결과가 좋아진것을 볼 수 있음.
CRF 적용 전 후 결과를 보면 CRF가 적용되었을 때 detail 정보가 상당히 개선된것을 알 수 있음.
아래 표는 PASCAL VOC2012 데이터셋에 대한 실험결과인데, ResNet-101에 CRF를 적용하면 평균 IoU가 79.7%수준으로 매우 높다는것을 확인 할 수 있음
그 외에도 다양한 데이터를 바탕으로 실험한 결과 역시 매우 좋지만 자세한 결과는 논문 참조
FCN(Fully Convolutional Network)에 대한 분석과 약간의 구조 변경을 통해 FCN의 성능을 좀 더 끌어올리게 할 수 있는 방법을 제시
Dilated convolution
본 논문에서는 dilated convolution이라는 단어를 Fisher Yu의 segmentation 방법을 지칭하는것과 실제 dilation 개념이 적용된 convolution을 섞어서 표현함
Dilated convolution이란?
Dilated convolution 자체는 Fisher Yu가 처음 언급한것이 아니라, FCN을 발표한 Jonathan Long의 논문에서 잠깐 언급이 있었고, FCN 개발자들은 dilated convolution 대신 skip layer와 upsampling 개념을 사용함
그 후 DeepLab의 논문 “Semantic image segmentation with deep convolutioonal nets and fully connected CRFs”에서 dilated convolution이 나오지만, Fisher Yu의 방법과 조금 다른 방법으로 사용
Dilated convolution의 개념은 wavelet decomposition 알고리즘에서 “Atrous algorithm” 이라는 이름으로 사용되었으며, DeepLab 팀은 구별하여 부르기 위해 atrous convolution이라고 불렀는데, Fisher Yu는 이를 dilated convolution이라고 불렀으며 주로 이렇게 표현됨
참고로 atrous는 프랑스어로 a trous고 trous는 hole(구멍)의 의미를 갖음.
Dilated convolution이란 아래 그림처럼 기본적인 conv와 유사하지만 빨간색 점의 위치에 있는 픽셀들만 이용하여 conv 연산을 수행함
이렇게 하는 이유는 해상도의 손실 없이 receptive field의 크기를 확장할 수 있기 때문임
Atrous convolution이라고 불리는 이유는 전체 receptive field에서 빨간색 점의 위치만 계수가 존재하고, 나머지는 모두 0으로 채워지기 때문임
아래 그림에서 (a)는 1-dilated convolution이며 이는 흔히 알고있는 convolution과 동일함.
(b)는 2-dilated convolution이며, 빨간 점들의 값만 conv 연산에서 참조되어 사용되고 나머지는 0으로 채워짐.
이렇게 되면 receptive field의 크기는 7x7 영역으로 커지게 됨(연산량의 증가 없이 RF가 커짐)
(c)는 4-dilated convolution이며, receptive field의 크기는 15x15로 커지게 됨
Dilated conv를 사용하여 얻을 수 있는 이점이 큰 receptive field(RF)를 취하려면 일반적으로 파라미터의 개수가 많아야 하지만(large kernel size conv를 사용 후 pooling해야함) dilated convolution을 사용하면 receptive field는 커지지만 파라미터의 개수는 늘어나지 않기에 연산량 관점에서 탁월한 효과를 얻을 수 있음
위 그림의 (b)에서 RF는 7x7이기 때문에 normal filter로 구현 시 필터의 파라미터 개수는 49개가 필요하며, conv 연산이 CNN에서 가장 많은 연산량을 차지한다는점을 고려한다면 이는 부담이 상당한 연산이 됨
하지만 dilated conv를 사용하면 49개의 파라미터중 빨간점에 해당하는 9개의 파라미터만 사용하고 나머지 값 40개는 모두 0으로 처리되어 연산량 부담이 3x3 filter 처리량과 같아지게 됨
Dilated convolution을 하면 좋은점
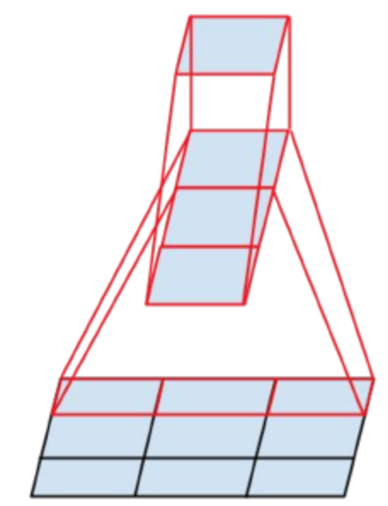
우선 RF의 크기가 커지게 된다는 점이며, dilation 계수 조절 시 다양한 scale에 대한 대응이 가능해짐.
다양한 scale에서의 정보를 끄집어내려면 넓은 receptive field를 볼 수 있어야 하는데, dilated conv를 사용하면 별 어려움이 없이 이것이 가능해짐
기존의 일반적인 CNN에서는 RF의 확장을 위해 pooling layer를 통해 feature map의 크기를 줄인 후 convolution 연산을 수행하는 방식으로 계산
기본적으로 pooling을 통해 크기가 줄었기에 동일한 크기의 filter를 사용하더라도 CNN망의 뒷단으로 갈수록 넓은 RF를 커버할 수 있게 됨
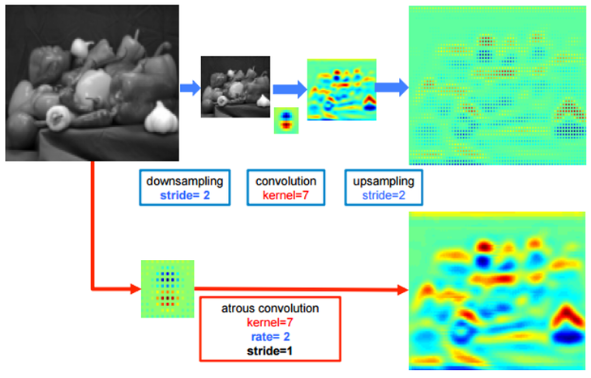
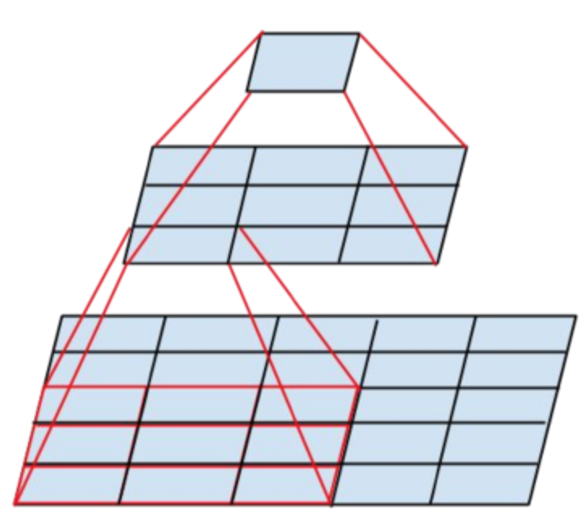
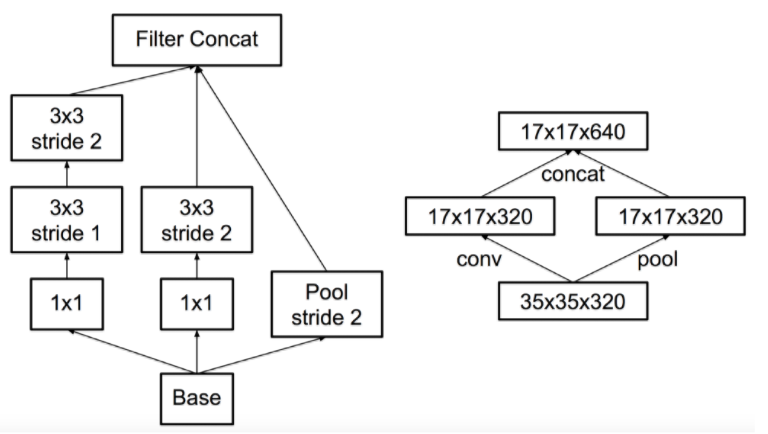
Fisher Yu의 논문에서는 자세하게 설명하지 않았기에 아래의 DeepLab 논문 그림을 참조하여 이해하면 이해가 훨씬 쉬워짐
그림에서 위쪽은 앞서 설명한 것처럼 down-sampling(pooling) 후 conv를 통해 large RF를 갖는 feature map을 얻고, 이를 이용해 픽셀 단위 예측을 하기위해 다시 up-sampling을 통해 영상의 크기를 키운 결과임
아래는 dilated convolution(atrous conv)을 통해 얻은 결과
Fisher Yu는 context module이라는것을 개발하여 segmentation의 성능을 끌어 올렸으며, 여기에 dilated convoluton을 적용함
Front-end 모듈
FCN이 VGG16 classification 모델을 거의 그대로 사용한 반면 논문에서는 성능 분석을 통해 모델을 수정함
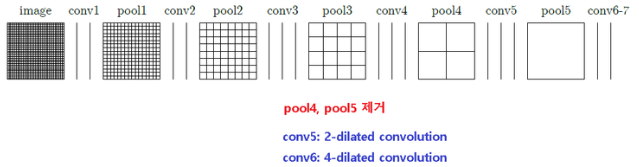
VGG16의 뒷단을 그대로 사용하였지만 오히려 크게 도움이 되지 않아 뒷부분을 아래처럼 수정했다고 함
먼저 pool4, 5는 제거함. FCN은 이를 그대로 두었기에 feature map의 크기가 1/32까지 작아지고 이로 인해 좀 더 해상도가 높은 pool4, 3의 결과를 사용하기 위해 skip layer라는 것을 포함시킴
하지만 Fisher Yu는 pool4와 pool5를 제거함으로써 최종 featue map의 크기는 원영상의 1/8수준으로만 작아지게 하였고 이로인해 up-sample을 통한 원영상 크기로의 복원 과정에서도 상당한 detail 정보들이 살아있게 됨
또한 conv5, 6(fc6)에는 일반적인 conv 사용하는 대신 conv5는 2-dilated conv를, conv6에는 4-dilated conv를 적용함
결과적으로 skip layer도 없고 망도 더 간단해졌기에 연산 측면에서는 훨씬 가벼워졌음
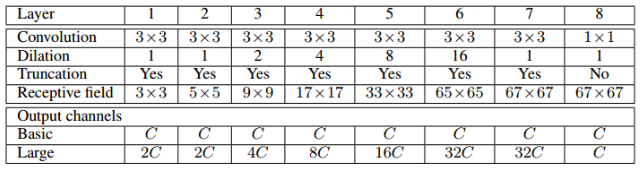
아래 표와 그림을 보면 front-end의 수정만으로도 이전 결과들보다 정밀도가 상당히 향상된 것을 확인 가능
아래 표와 그림에서 DeepLab은 dilated conv를 사용했지만 구조가 약간 다른 모델
Context 모듈
Front-end 모듈뿐만 아니라 다중 scale의 context를 잘 추출해내기 위한 context 모듈도 개발했고, basic과 large 모듈이 있음
Basic type은 feature map의 개수가 동일하지만 large type은 feature map의 개수가 늘었다가 최종단만 feature map의 개수가 원래의 개수와 같아지도록 구성됨
Context 모듈은 기본적으로 어떤 망이든 적용이 가능할 수 있도록 설계되었으며 자신들의 front-end 모듈 뒤에 context 모듈을 배치함
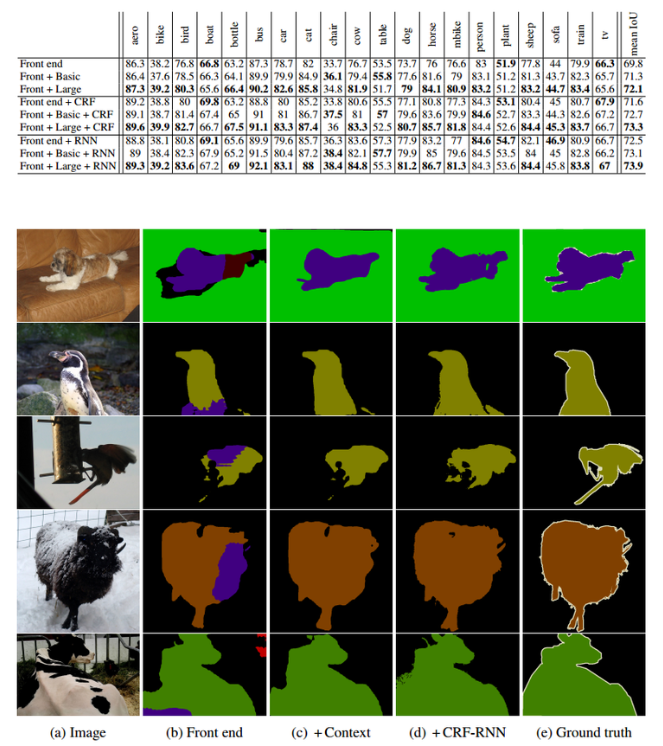
Context 모듈의 구성은 아래 표와 간으며 전부 convolutional layer로만 구성됨
아래 표에서 C는 feature map의 개수를, dialteion은 dilated conv의 확장 계수(rate), convolution만으로 구성이 되었지만 뒷단으로 갈수록 RF의 크기가 커지도록 구성된것을 확인 가능함
표를 이해해보면, layer 1에서 3x3 conv, layer 2에서 3x3 conv가 되면 RF가 5x5가 되는것을 확인 할 수 있음
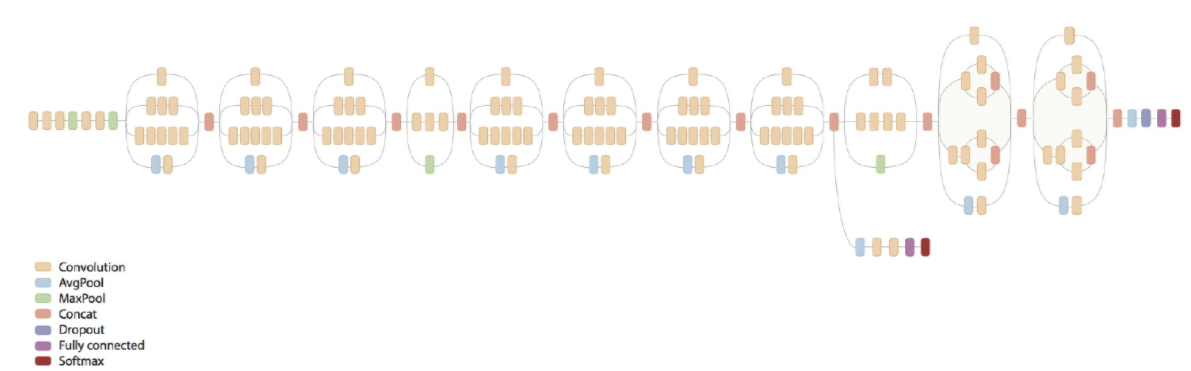
2014년 ILSVRC에서 1등을 한 모델로, Going Deeper with Convolutions 라는 논문에서 Inception이란 이름으로 발표됨
Inception은 이 버전 이후 v4까지 여러 버전이 발표되었으며, 이번 글에선 Inception v1에 대해서만 다룸
ILSVRC 2014에서 팀명이 GoogLeNet이므로 구글넷으로 부른다.
구글의 가설
딥러닝에서 대용량 데이터 학습시 일반적으로 망이 깊고 레이어가 넓은 모델의 성능이 좋다는것이 정설
하지만 현실적으로는 네트워크를 크게 만들면 파라미터가 많이 늘어나고, 망이 늘어날때마다 연산량이 exponential하게 많아지며 overfitting, vanishing gradient등의 문제가 발생해 학습이 어려워짐
이를 해결하기 위한 방안 중 하나가 Sparse connectivity임.
현재까지 사용된 convolution 연산은 densely하게 연결되어있음
이를 높은 correlation을 가진 노드들끼리만 연결하도록, 즉 노드들 간의 연결을 sparse하도록 바꾼다면 연산량과 파라미터수가 줄고, 따라서 overfitting 또한 개선될 것이라 생각함
Fully connected network에서 사용하는 dropout과 비슷한 기능을 할 것이라고 본 것임
하지만 실제로는 dense matrix 연산보다 sparse matrix 연산이 더 큰 computational resource를 사용
LeNet때의 CNN은 sparse한 CNN 연산을 사용함.
이후 연산을 병렬처리하기위해 dense connection을 사용했고, 이에 따라 dense matrix 연산기술이 발전함
반면 sparse matrix 연산은 dense matrix 연산만큼 발전하지 못했고, dense matrix연산보다 비효율적이게 됨
따라서, 위 목적을 달성하기 위해 sparse connectivity를 사용하는것은 해결방안이 될 수 없었음
여기에서, 구글이 고민한것은 어떻게 노드 간의 연결을 줄이면서(sparse connectivity) 행렬 연산은 dense 연산을 하도록 처리하는가였으며, 이 결과가 바로 Inception module임.
Inception module
구글넷이 깊은 망을 만들고도 학습이 가능했던것은 inception module 덕분임
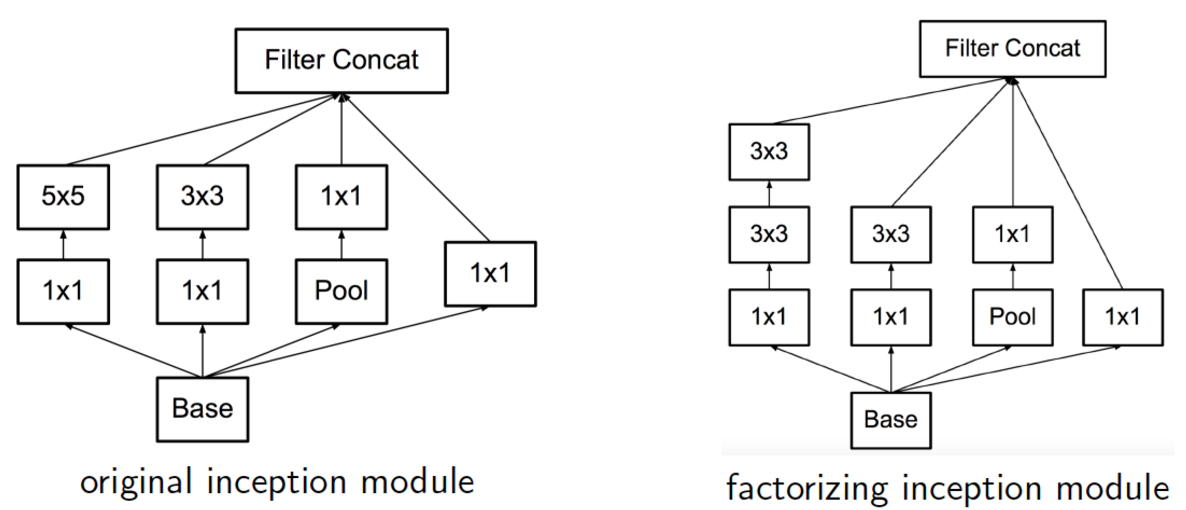
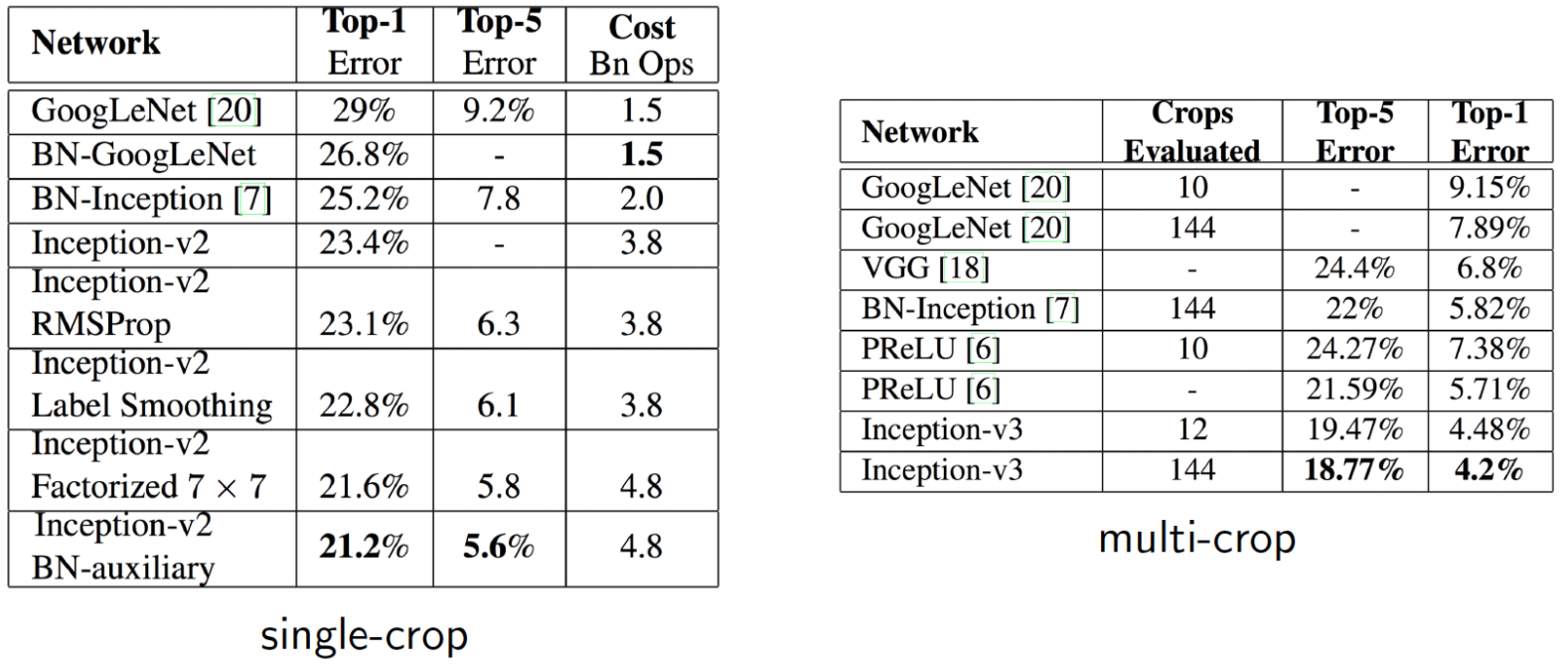
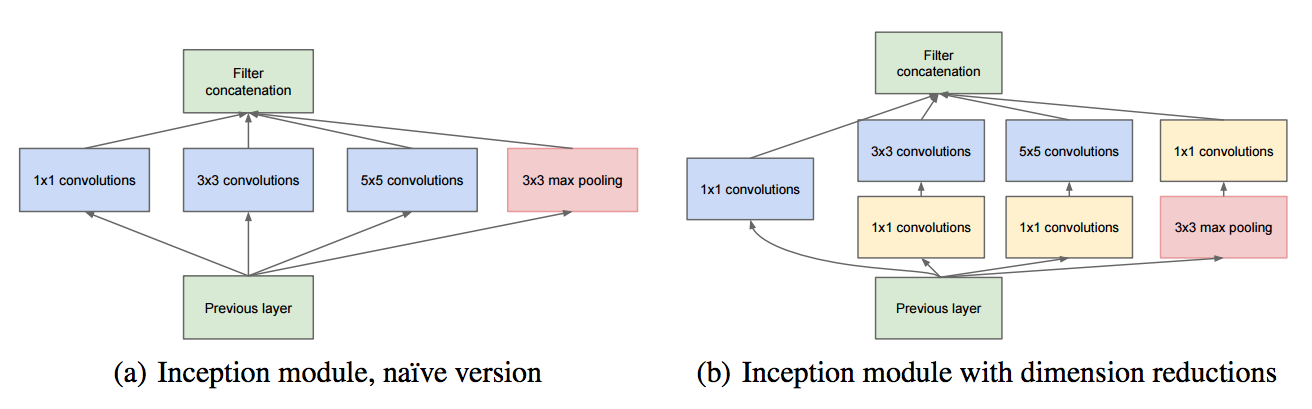
위 그림은 inception module의 구조를 나타낸 것으로, 입력값에 대해 4가지 종류의 연산을 수행하고 4개의 결과를 채널 방향으로 concat함
이러한 inception module이 모델에 총 9개가 있음
Inception module의 4가지 연산은 각각
1x1 convolution
1x1 convolution 후, 3x3 convolution
1x1 convolution 후, 5x5 convolution,
3x3 MaxPooling후 1x1 convolution
이 결과들을 Channel-wise concat(feature map을 쌓기)
이 중, 1x1 conv 연산은 모호하게 여겨질 수 있으나 핵심 역할을 하며 기능은 아래와 같음
채널의 수를 조절하는 역할. 채널의 수를 조절한다는것은 채널간의 correlation을 연산한다는 의미라고 할 수 있음. 기존의 conv 연산은 3x3커널 연산의 경우 3x3 크기의 지역 정보와 함께 채널 간의 정보 또한 같이 고려하여 하나의 값으로 나타냄. 다르게 말하면 하나의 커널이 2가지의 역할 모두 수행해야 하는것을 의미. 대신, 이전에 1x1 conv를 사용하면 채널 방향으로만 conv 연산을 수행하므로 채널간의 특징을 추출하게 되며, 3x3은 공간방향의 지역 정보에만 집중하여 특징을 추출하게 됨. (역할을 세분화 해줌) 채널간의 관계정보는 1x1 conv에서 사용되는 파라미터들끼리, 이미지의 지역 정보는 3x3 conv에 사용되는 파라미터들끼리 연결된다는점에서 노드간의 연결을 줄였다고 볼 수 있음
1x1 conv 연산으로 이미지의 채널을 줄여준다면 3x3과 5x5 conv 레이어에서의 파라미터 개수를 절약 할 수 잇음. 이 덕분에 망을 기존의 cnn 구조들보다 더욱 깊게 만들고도 파라미터가 그렇게 많지 않음
2012년 Alexnet 보다 12x 적은 파라미터 수. (GoogLeNet 은 약 6.8M 의 파라미터 수)
구글의 가설
딥러닝은 망이 deeper, 레이어가 wider 할수록 성능이 좋음
현실적으로는 overfeating, vanishing gradient 등의 문제로 실제 학습이 어려움
구현을 위해 아래와같은 현실적 문제들 발생
신경망은 Sparsity 해야지만 좋은 성능을 냄(Dropout)
논문에서는 데이터의 확률 분포를 아주 큰 신경망으로 표현할 수 있다면(신경망은 사후 분포로 취급 가능하므로) 실제 높은 상관성을 가지는 출력들과 이 때 활성화되는 망내 노드들의 클러스터들의 관계를 분석하여 최적 효율의 토폴로지를 구성할 수 있음
대략적인 SSD의 프로세스를 알지만 구체적으로 정확하고 자세하게 분석되어있지 않아 직관적 이해를 위해 다룸
참고 글: https://taeu.github.io/paper/deeplearning-paper-ssd/
Abstract
SSD discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location(multiple feature map).
즉, 아웃풋을 만드는 multi-feature map을 나눈 다음 각 feature map에서 다른 비율과 스케일로 default box를 생성한 후, 모델을 통해 계산된 좌표와 클래스값에 default box를 활용해 최종 bounding box를 생성한다.
Introduction
섹션 2.1 Model과 2.2 Training에서 box의 class 점수와 위치좌표 크기를 예측하는데 고정된 default box를 예측하도록 하는 내용을 다룸
정확도 향상을 위해 서로 다른 피쳐맵에서 서로 다른 스케일의 예측을 할 수 있게 함.
YOLO v1의 경우 최종 아웃풋으로 나온 하나의 feature map의 각 그리드 셀당 2개의 bounding box를 예측하도록 했음
SSD는 이에 반해 여러가지의 grid cell을 갖고 각 feature map당 여러가지(보통 6개) 바운딩박스를 가짐
2.1과 2.2에서 상세설명
The Single Shot Detector (SSD)
2.1 Model
Image detection의 목적상 들어온 영상에서 객체의 위치와 크기, 레이블을 찾아야 함.
따라서 input으로는 이미지, output으로는 class score, x, y, w, h가 됨.
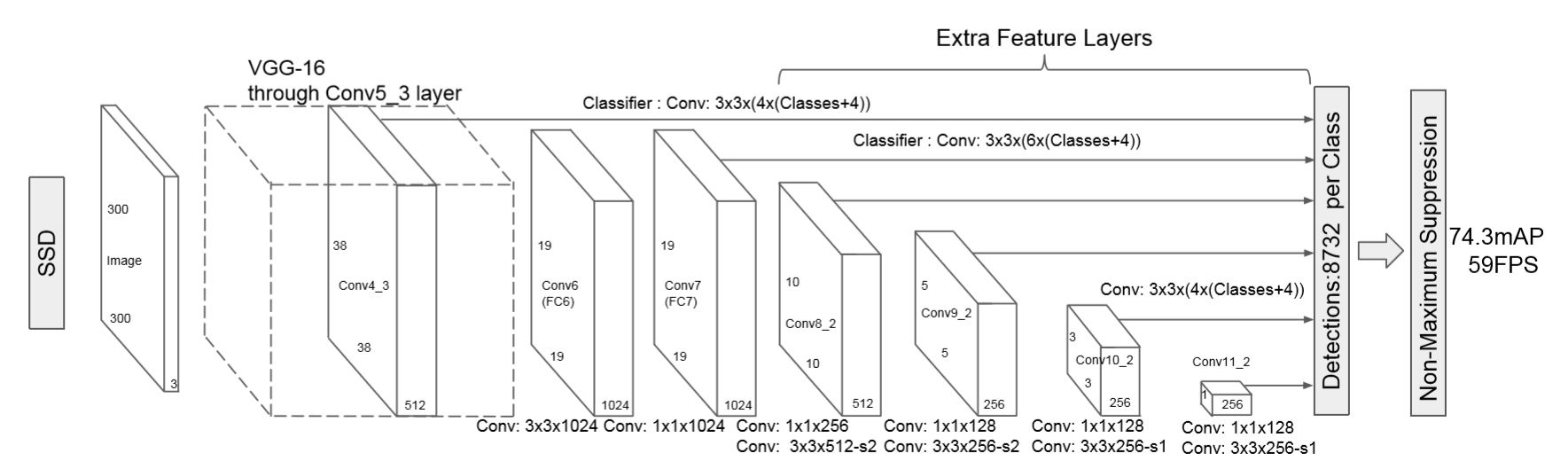
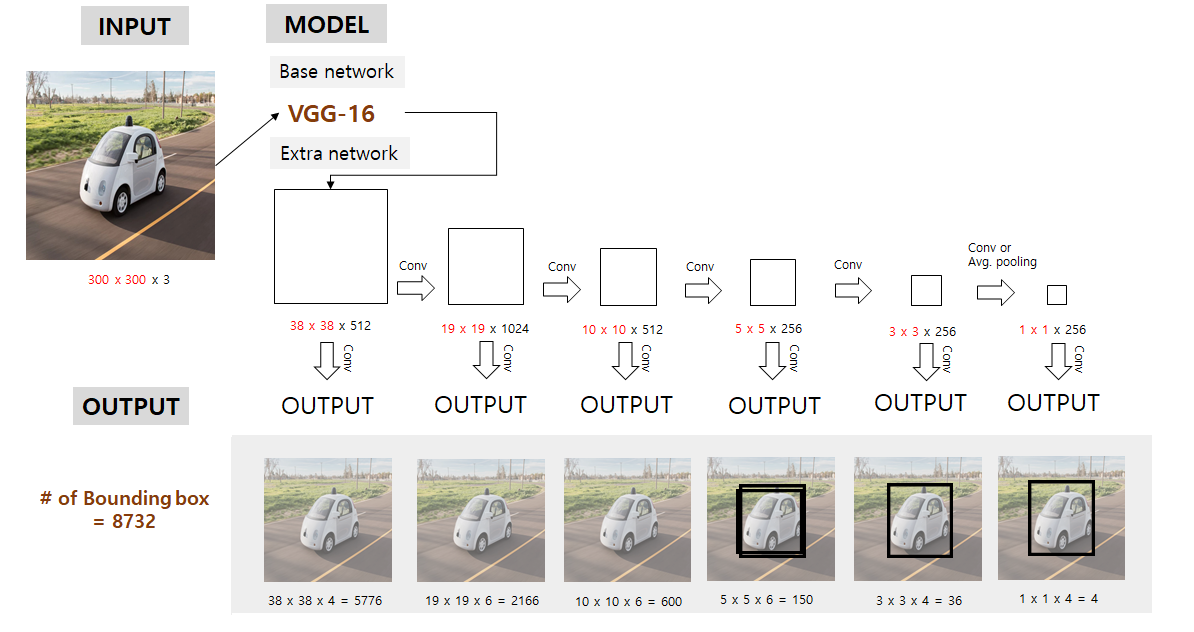
논문의 SSD 구조는 위와 같음(VGG16 backbone)
우선 SSD는 저해상도에서도 작동이 잘 되기에 300x300 pixel image를 기본적으로 입력받도록 함.
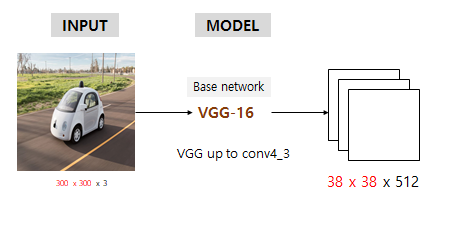
Input image를 기본적으로 처리할땐 backbone인 VGG16을 갖고와 conv4_3까지만 가져다가 씀
300x300x3 input이 backbone 통과 후 38x38x512가 됨
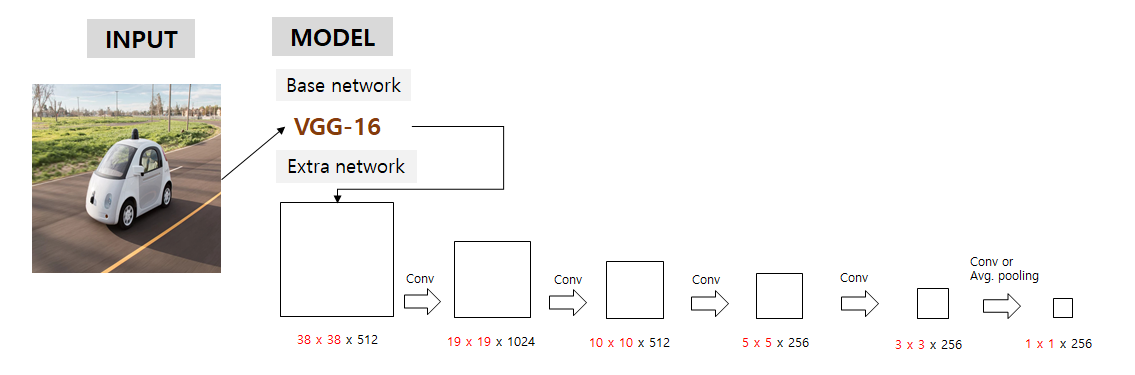
다음으로 논문에서 강조하는 multi feature maps에 해당하는 부분으로, 각각 위의 사진의 크기를 갖는 feature map들을 backbone과 extra network가 포함된 feature extractor에서 가져와서 그 multi-feature map들을 이용하여 detection을 수행하게 됨.
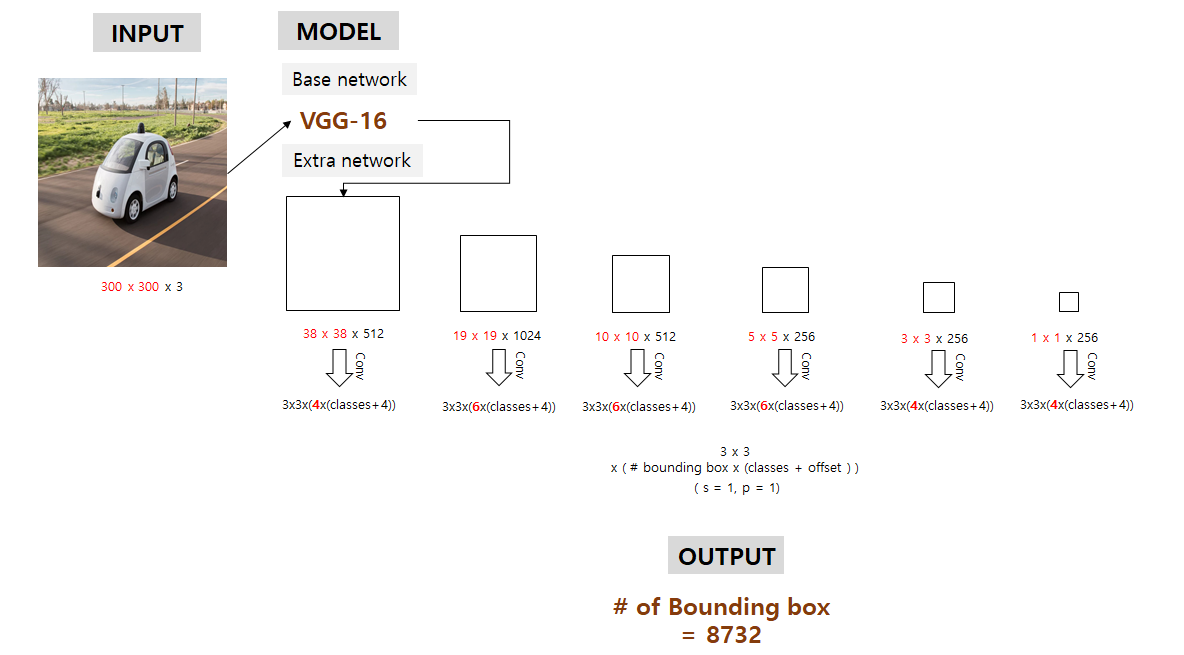
각 feature map에서적절한conv 연산을 이용해 우리가 예측하고자 하는 bounding box의 정보들(x, y, w, h, class scores)을 예측함.
여기서 conv filter size는 3 x 3 x (# of bounding box x (class score + offset)) 이 됨
stride = 1, padding = 1로 추정
이 6개의 서로 다른 크기를 갖는 feature map들 각각에서 예측된 bounding box의 개수 합은 하나의 클래스당 8732개가 됨
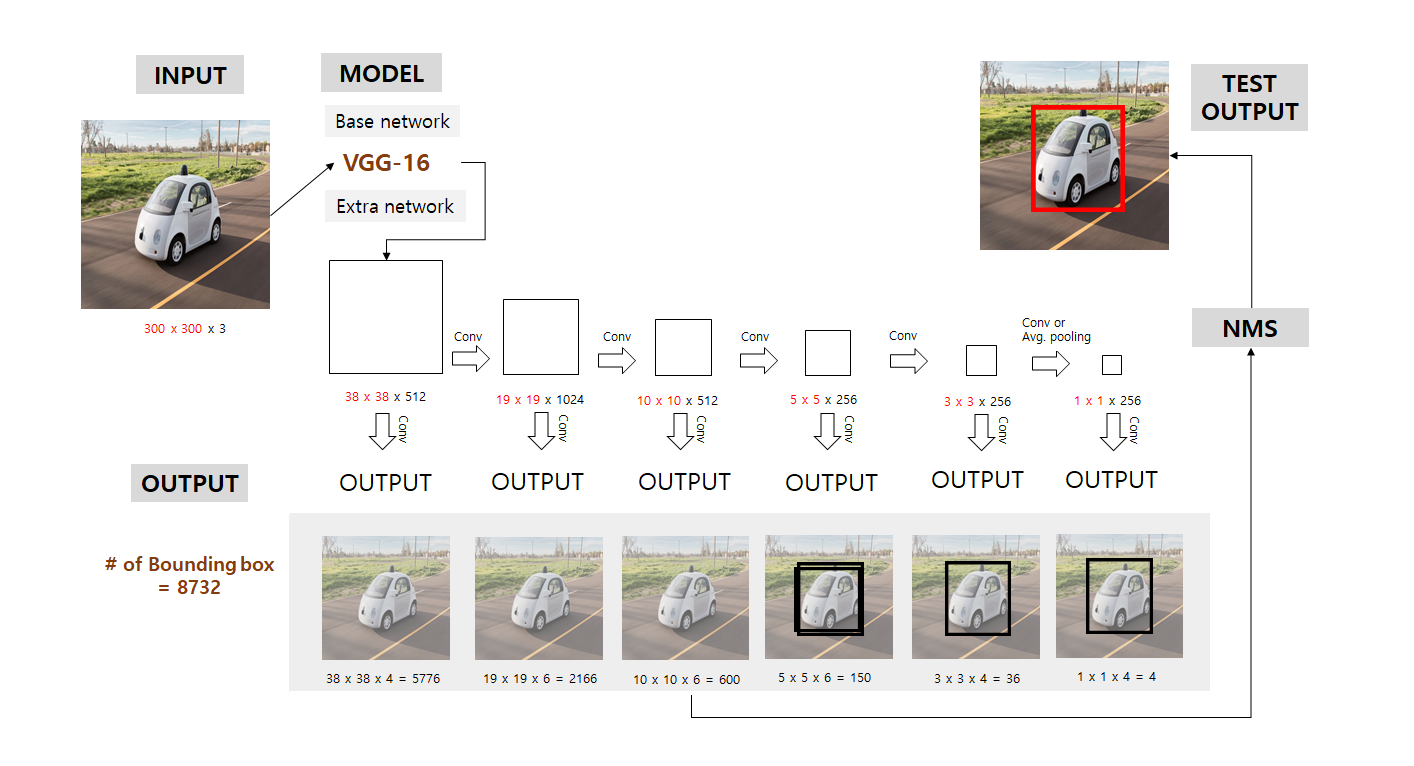
8732개의 bounding box의 output이 나온다고 해서 그것을 다 고려하지 않음
Default box간의 IOU를 계산한 후 0.5가 넘는 box들만 출력결과에 포함시키고 나머지는 0으로 하여 실효성 없는 데이터를 삭제함
이 box들을 NMS를 거쳐서 중복되는 box를 제거
마지막으로 NMS를 통해 최종 detection 결과는 위 그림에서 우측 상단과 같음
Multi-scale feature maps for detection
38x38, 19x19, 10x10, 5x5, 3x3, 1x1 의 다양한 크기를 갖는 피쳐맵들을 의미
Yolo는 7x7 grid 만을 이용했지만, SSD는 전체 이미지를 38x38, 19x19, 10x10, 5x5, 3x3, 1x1의 그리드로 나누고 이를 predictor layer와 연결하여 결과를 추론
큰 피쳐맵에서는 작은 물체 탐지, 작은 피쳐맵에서는 큰 물체 탐지 (뒤의 2.2 training 부분에서 더 자세히 다룸)
Convolutional predictors for detection
위에서 생성된 feature map은 3x3 kernel size stride=2 conv layer와 연결
Feature map은 3x3xp size의 필터로 conv 연산.
Yolo v1은 fc layer를 사용하여 x, y, w, h, score를 추론
예측된 결과는 x, y, w, h, score(offsets)를 의미
Default boxes and aspect ratios
각 feature map에 grid cell을 만들고(5x5와 같이..) default bounding box를 만들어 그 default box와 대응되는 자리에서 예측되는 박스의 offset과 per-class scores(여기서는 박스 안에 객체가 있는지 없는지를 예측)를 예측
이 때 per-class scores를 클래스 확률로 생각하면 안되고, 해당 박스 안에 객체가 있는지 없는지를 나타내는 값이라고 생각해야 하며 자세한것은 뒤쪽의 matching strategy에서 설명
6개의 feature map(마지막 prediction layer와 연결된 feature map)은 각각 연산을 통해 conv(3*3*(#bbx*(c+offset))) 출력을 생성
Output은 각 셀당 #bb 개의 bounding box를 예측
2.2 Training
SSD 모델의 학습에 제대로된 이해를 하기 위해서는 predicted box와 default box가 정확히 구분되어야 하며, Fast R-CNN 논문의 anchor box와 loss function 부분의 이해가 필요함
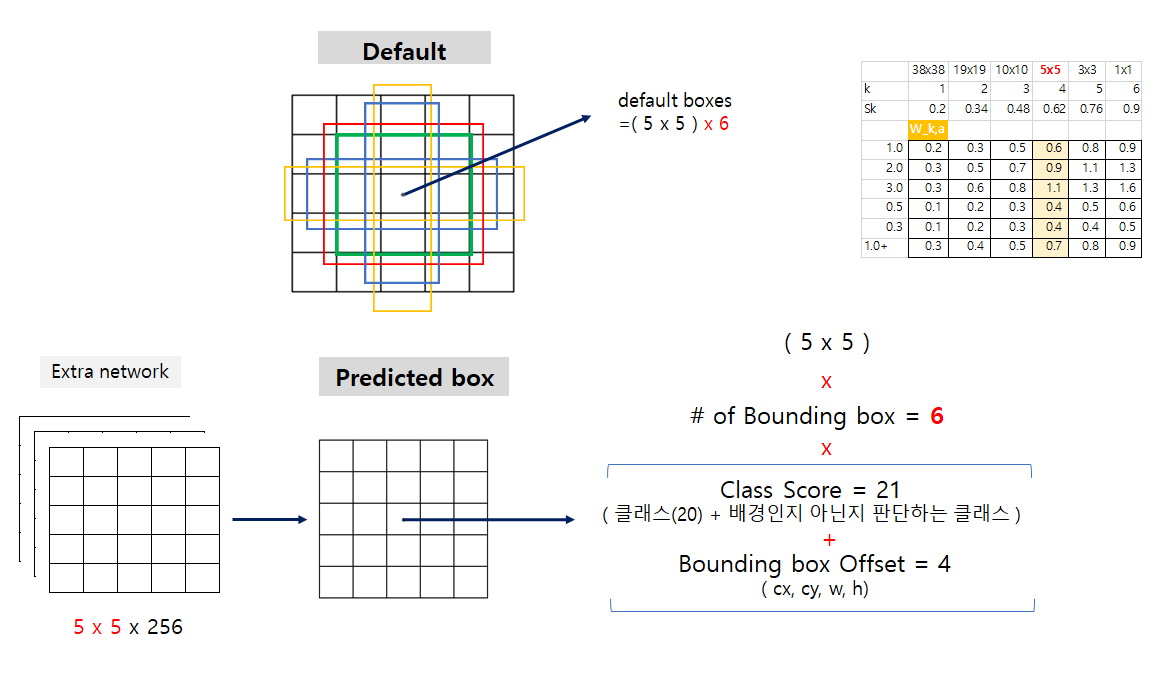
위 모델에서 5x5 크기의 feature map 부분만 따로 떼서 고려해보자.
Ground Truth Box: 우리가 예측해야 하는 정답 박스
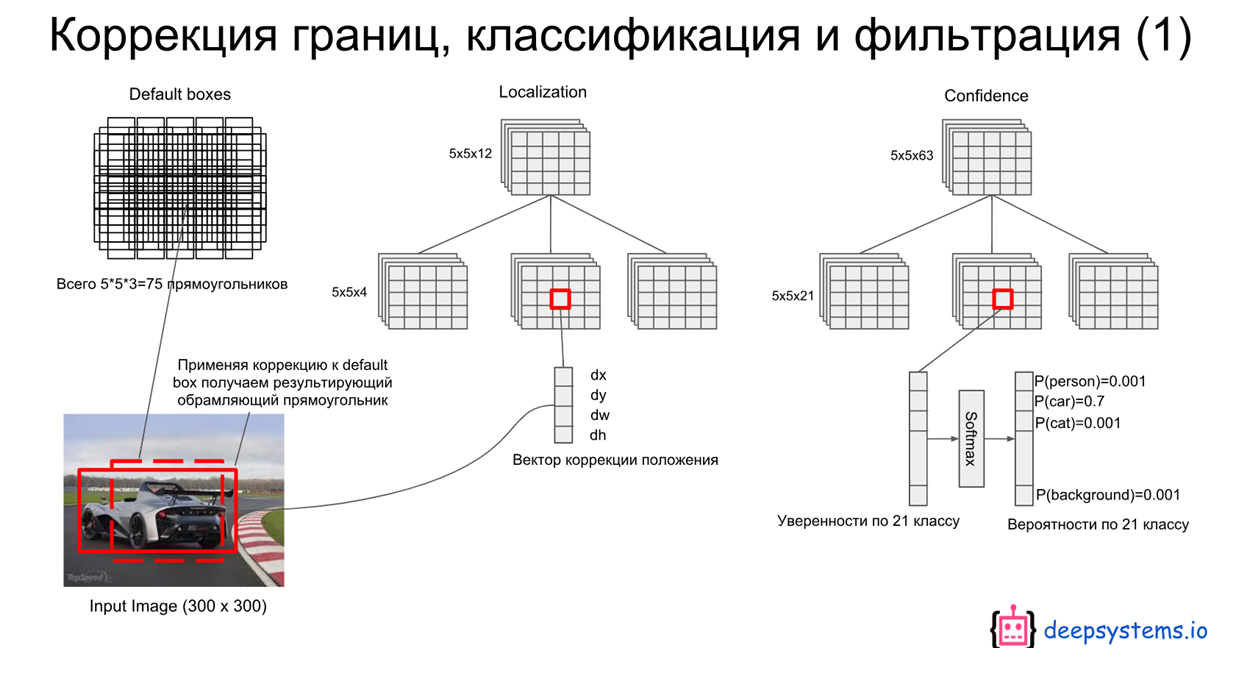
Predicted Box: Extra Network에서 만들어진 5x5 크기의 feature map에서 output(predicted box) 생성을 위해 conv 연산을 하면 총 5x5x(6x(21+4))개의 값이 생성됨. (= Grid cell x Grid cell x (# of bb x (class + offset)))
Default Box: 5x5 feature map은 각 셀당 6개의 default box를 갖고있다. (위 그림 참조)) 여기서 default box의 w, h는 feature map의 scale에 따라 서로 다른 S 값(scale factor)과 서로 다른 aspect ratio인 a 값을 이용해 얻어진다. 또, default box의 cx와 cy는 feature map size와 index에 따라 결정된다.
먼저, default box와 ground truth box간의 IoU를 계산해 0.5 이상인 값들은 1(Positive), 아닌 값들은 0으로 할당한다.
이는 아래서 x에 해당하는 값임
예를 들어, 위 그림과 같이 5x5의 feature map의 13번째 셀(정 중앙)에서 총 6개의 default box와 predicted bounding box가 있는데, 같은 순서로 매칭되어 loss를 계산한다. 이는 아래의 loss function을 보면 더 쉽게 이해가 가능하다.
매칭된 (x=1, positive) default box와 같은 순서의 predicted bounding box에 대해서만 offset에 대한 loss가 update된다.
위 그림에서 빨간색 점선이 matching된 default box라고 한다면, 거기에 해당하는 cell의 같은 순서의 predicted bounding box의 offset만 update되고 최종적으로는 아래와 같이 predicted된다.
Matching strategy
Ground truth와 ‘default box’를 미리 매칭 시킴
두 영역의 IoU가 0.5 이상인 것들을 match
Training objective
용어정리
$x_{ij}^{p}={1,0}$: i 번째 default box와 j 번째 ground truth 박스의 category p에대한 물체 인식 지표. p라는 물체의 j 번째 ground truth와 i번째 default box간의 IoU가 0.5 이상이면 1, 아니면 0으로 정의됨
$N$: Number of matched default boxes
$l$: Predicted box (예측된 상자)
$g$: Ground truth box
$d$: Default box
$cx, cy$: 해당 박스의 x, y좌표
$w, h$: 해당 박스의 width, heigth
$\alpha$: 교차검증으로부터 얻어진 값($\alpha = 1$)
Loss fucntion 은 크게 2부분으로 클래스 점수에 대한 loss와 바운딩 박스의 offset에 대한 loss로 나뉨
우리가 예측해야할 predicted box의 $l_{i}^{m}(cx,cy,w,h)$값들은 특이한 $\hat{g}$ 값들을 예측

 Seongkyun Han's blog
Seongkyun Han's blog