Seongkyun Han's blog
Seongkyun Han's blog
CH4. 연결 리스트 (Linked list) 2-2
12 Mar 2019 | data structure 자료구조CH4. 연결 리스트 (Linked list) 2-2
4-2 단순 연결 리스트의 ADT와 구현
- ADT는 배열기반/연결기반(동적할당)에 상관없이 동이일하게 작동해야 함
- 배열 기반 연결 리스트는 나란히 구성되어 Index 값을 이용해 특정 위치 Data에 쉽게 접근 가능
- 이를 위해 Chapter3의 배열 기반 ADT를 그대로 구현
- 배열/연결 기반 ADT가 원칙적으로 서로 다를 순 없지만, 필요 기능이나 효율 측면에서 유연하게 달라질 수 있음
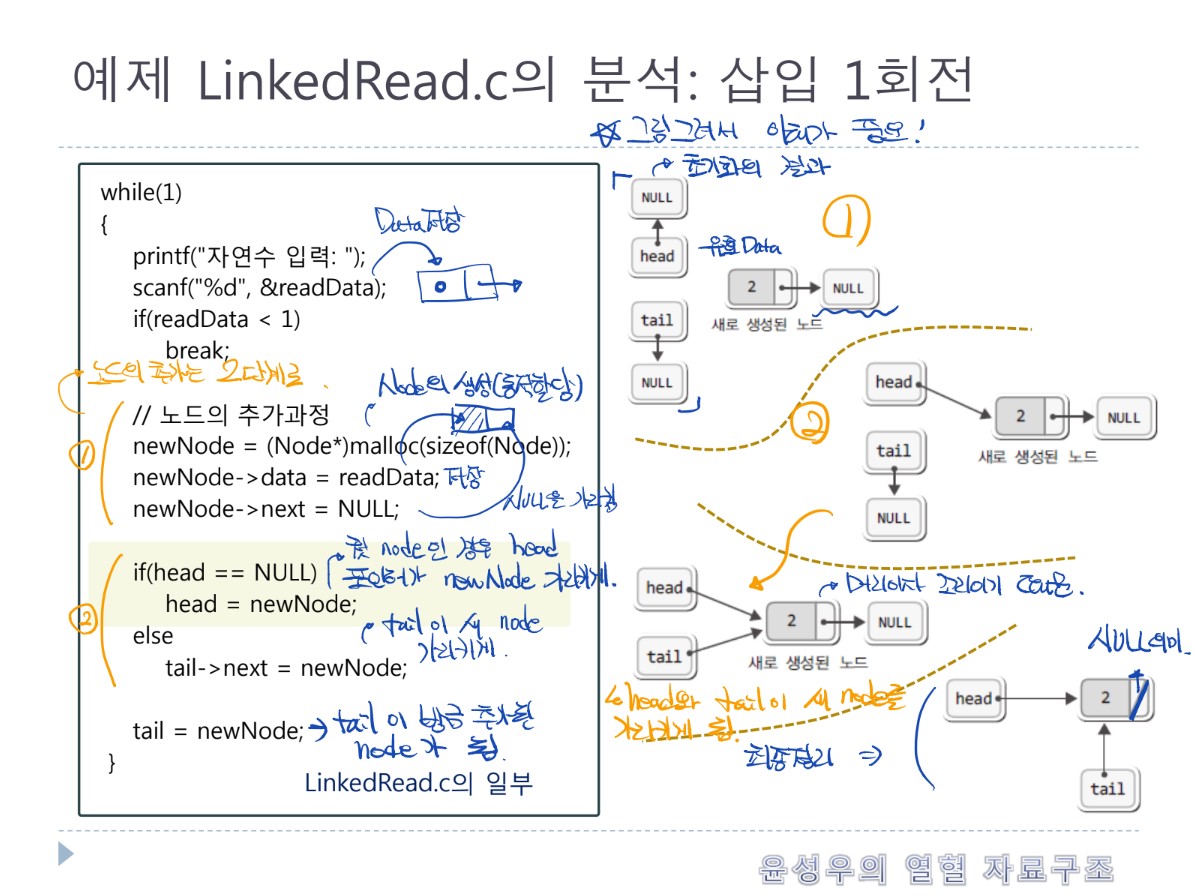
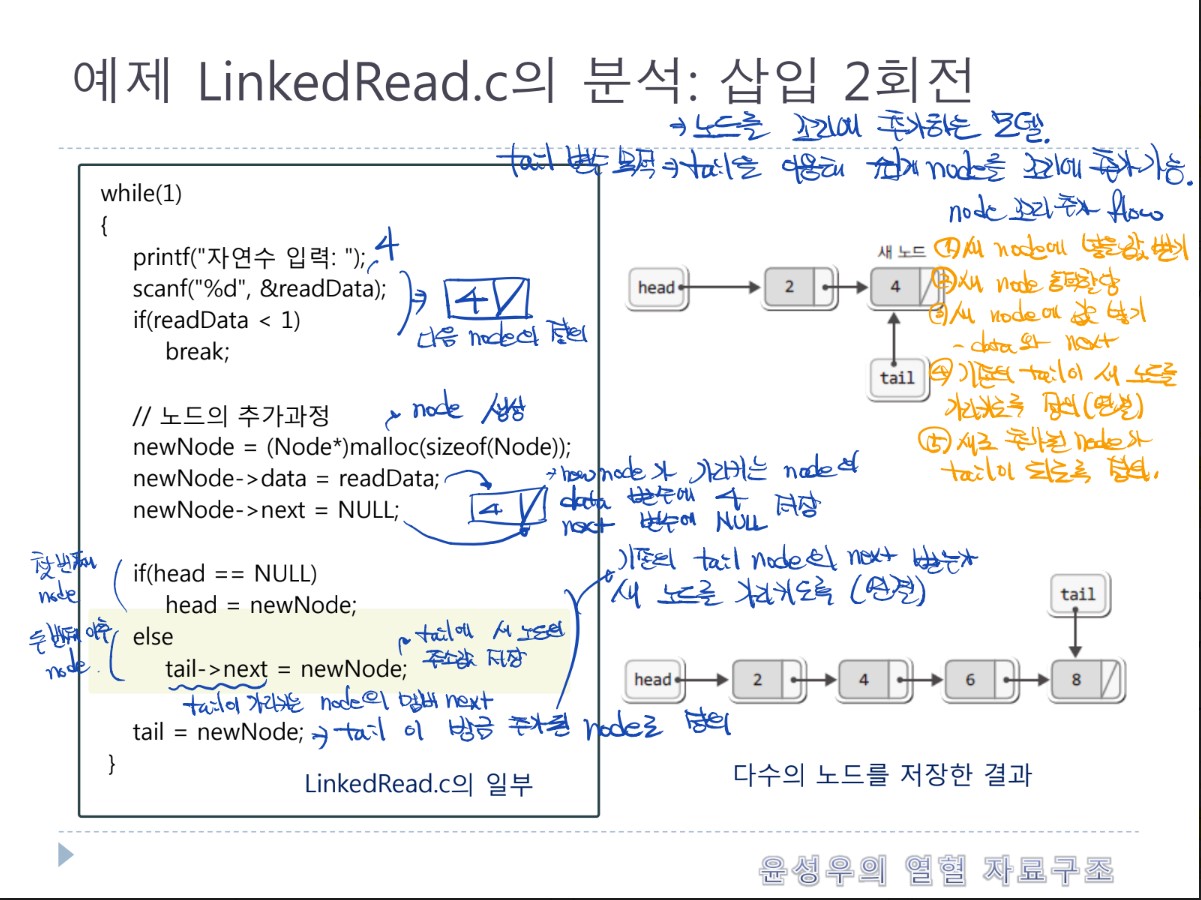
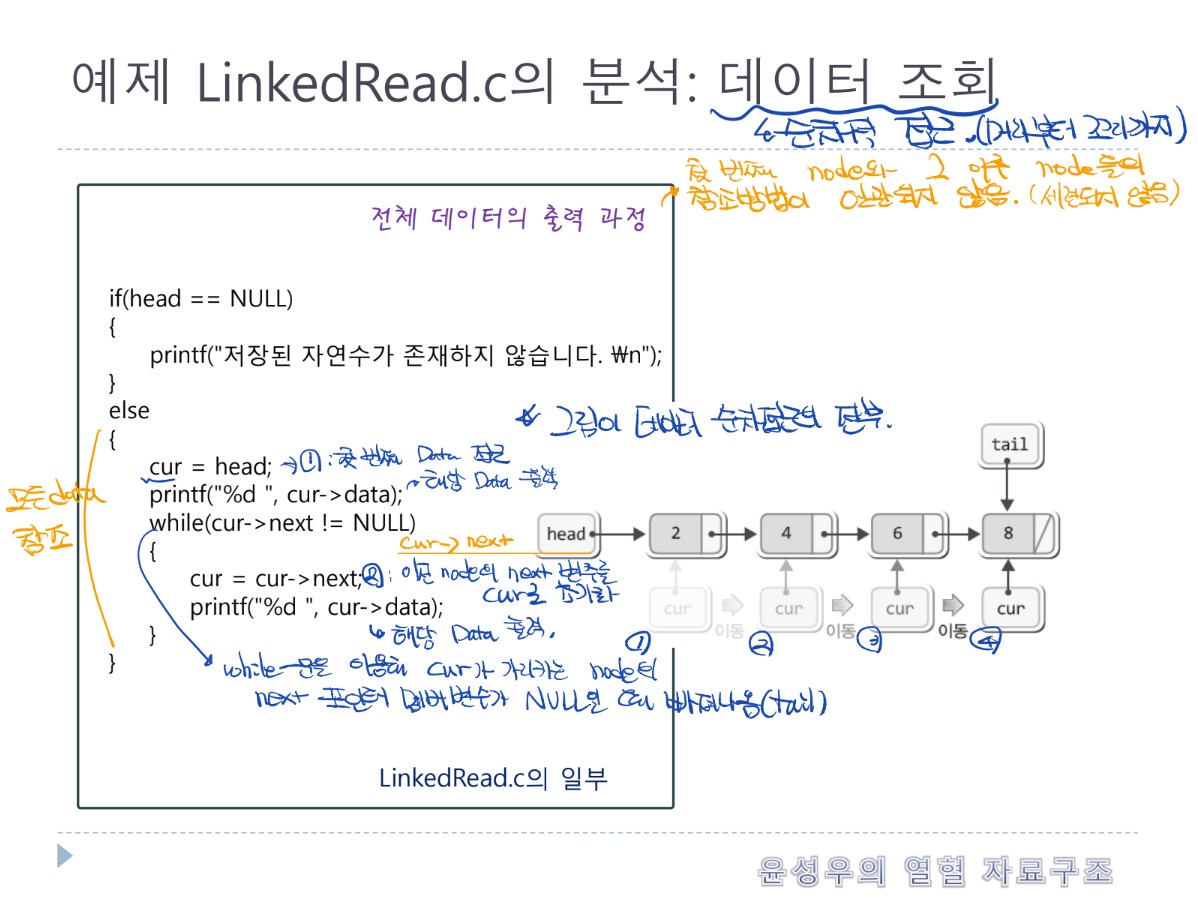
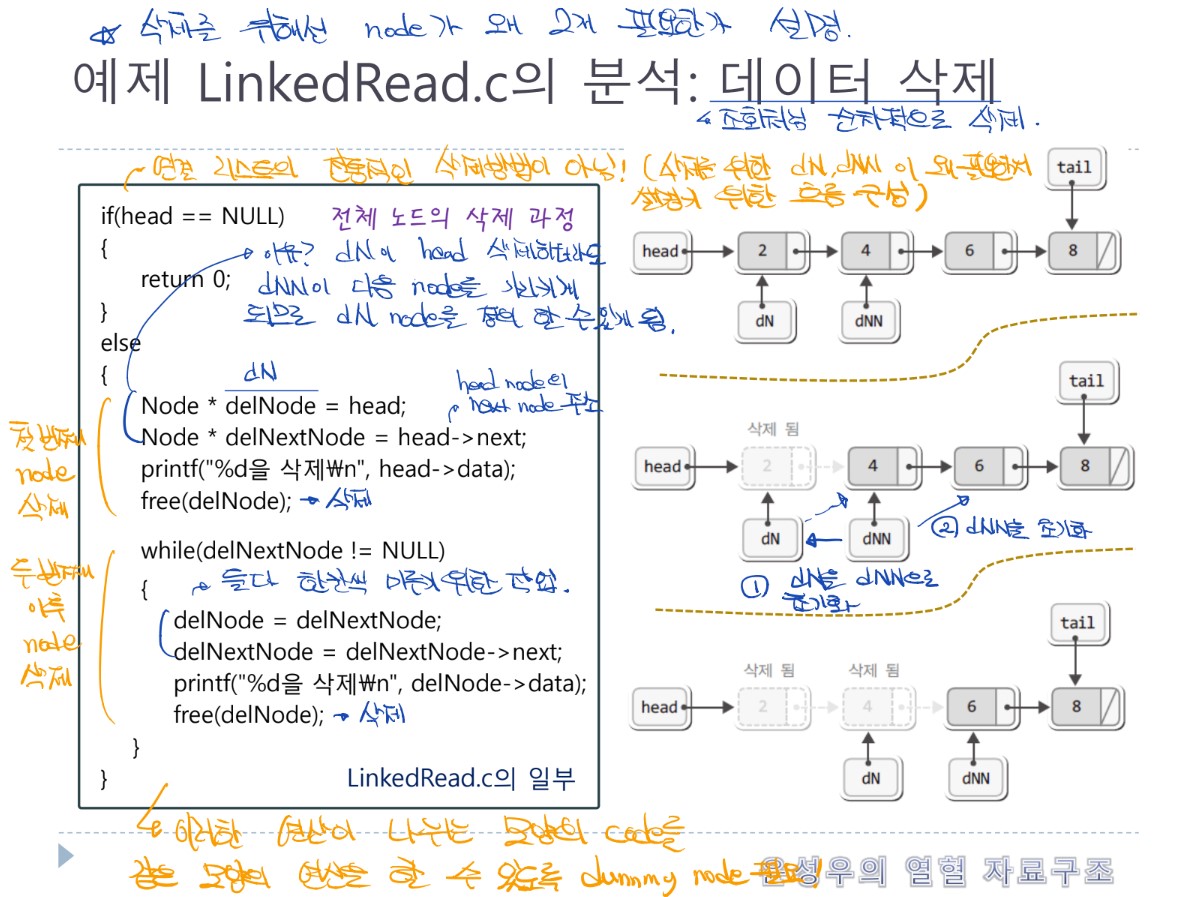
- 단순 연결 리스트는 노드들이 한쪽으로 단순하게 연결됨을 의미
- 강의에서 단순 연결리스트는 연결리스트라고 통칭

정렬 기능 추가된 연결 리스트의 ADT
- Chapter 3의 ADT와 기능적으로 동일하지만 구현방법이 다름
- 또한 배열 기반 연결 리스트의 특징을 따르게 하고자 정렬 함수가 추가됨


- 정렬 기능 함수의 void 함수 포이터는 후술
새 노드의 추가 위치에 따른 장점과 단점
- 각각의 장점과 단점이 존재하지만, 새 노드를 연결 리스트의 머리에 추가하게 하고, 추가 과정에서 정렬 알고리즘을 적용하여 올바른 위치에 정렬하도록 하는것이 좋음
- 포인터 변수의 감소는 코드의 가독성이 좋아짐

- tail 포인터 변수의 관리를 생략하기 위해 머리 부분에 추가하는것을 원칙으로 함
- 정렬을 이용하여 머리, 꼬리 뿐만이 아니라 중간에도 올바른 위치에 새로운 노드를 삽입 할 수 있음
SetSortRule 함수 선언에 대한 이해
void SetSortRule(List *plist, int (*comp)(LData d1, LData d2));- 의미: *comp가 저장할 수 있는 함수의 주솟값의 함수는 반환형이 int형이여야 하고, 매개변수 선언이 (LData d1, LData d2)와 일치해야 함
- Ldata = int이므로 바꿔서 보면 이해하기 수월
void SetSortRule(List *plist, int (*comp)(int d1, int d2));와 동일

WhoIsPrecede함수는 위 조건을 만족시키는 함수 중 하나의 예시WhoIsPrecede는 입력된 두 수 d1과 d2를 비교하여 정렬해주는 알고리즘- d1 < d2: 오름차순 조건
- d1 > d2: 내림차순 조건
- 정렬의 기준 -> d1이 d2보다 Head에 가까웠다면(수가 작다면) 0, 아니면 1 반환
- 배열 기반의 연결 리스트는 이를 기반으로 구현되므로 오름차순 정렬조건을 사용
- 만약 다른 정렬 기준으로 연결 리스트를 정렬하고 싶다면 입력, 반환 조건을 만족하는 다른 함수를 구현하면 됨
- 정렬 함수를 이용해 새 node가 적절한 위치에 연결되도록 할 수 있음
- 정해진 규칙(내림차순/오름차순 등)에 의해 정의된 기준에 근거하여 node가 연결 됨