
 Seongkyun Han's blog
Seongkyun Han's blog
ubuntu 추가 하드디스크 마운트 방법
05 Mar 2019 | ubuntu hdd mountubuntu 추가 하드디스크 마운트 방법
- 우분투가 설치된 하드디스크 외 추가 하드디스크 마운트 하는 방법에 대해 설명한다.
1. 하드디스크 설치
- 사용하는 PC에 하드디스크를 설치한다.
- PC를 킨 후
sudo fdisk -l로 잘 설치 되었나 확인- 새로 설치한 하드가 sda, sdb, sdc, … 어떤것인지 확인해 둠
- 본 글에선
sdc로 설명하며, 현재 넘버링에 따라 해당 글자만 바꾸면 됨
2. 하드디스크 용량이 2TB 이상인 경우
sudo parted /dev/sdc입력mklabel입력 후gpt- 내부 데이터가 모두 사라진다는 메세지가 출력 됨
yes입력
unit GB입력하여 단뒤 변환print입력하여 용량 확인mkpart primary 0GB 3001GB입력(우측엔 본인 용량 입력하면 됨)q입력하여 커맨드로 돌아옴
3. 하드디스크 용량이 2TB 미만인 경우
sudo fdisk /dev/sdc입력- 커맨드 입력 순서는 다음과 같음
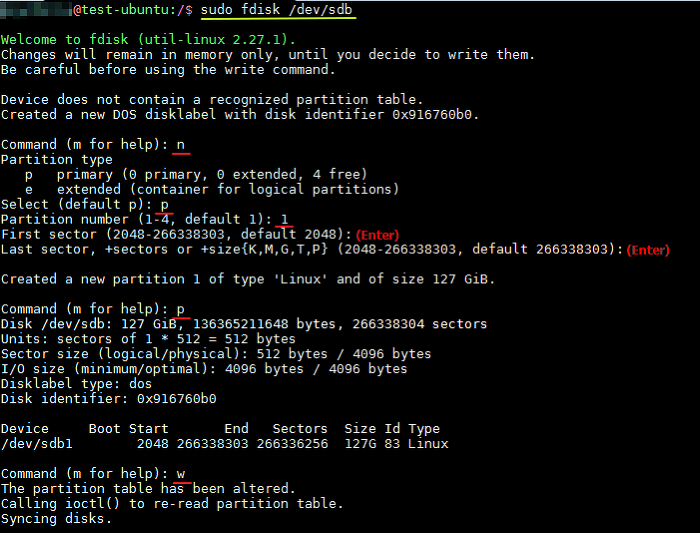
4. 파티션 포맷
mkfs.ext4 /dev/sdc1- 중간에 정보 입력하는 부분은 그냥 엔터 쳐서 무시하고 넘어가도 됨
5. UUID 확인
sudo blkid입력하여 UUID 확인 후 복사해두기
6. 마운트
sudo mkdir /hdd_ext/hdd3000로 외부 하드디스크 마운트 할 디렉터리 생성sudo vim /etc/fstab로 마운트 정보 추가 및 부팅 시 자동 마운트 설정UUID=583eb4bb-6f91-4634-b6f3-088157ae2010 /hdd_ext/hdd3000 ext4 defaults 0 0맨 아랫줄에 입력- 입력 후
:wq로 저장 후 빠져나오기
sudo mount -a로 마운트df -h로 마운트 확인- 마운트가 잘 되었으면 마운팅 된 하드디스크 정보가 보임
7. 마운팅 하드 심볼릭 링크 설정 (Symbolic link)
- 일종의 바로가기 개념
sudo ln -s /hdd_ext /home/han/hdd_ext로 /hdd_ext를 홈 디렉터리에 바로가기 만들어줌cd ~/hdd_ext로 이동sudo chmod 777 hdd3000으로 읽기 쓰기 권한 줌- 링크 만들어진 폴더에
touch test.txt,sudo rm test.txt로 파일 생성이 문제없이 되는가 확인하기
- [참고 글]
https://psychoria.tistory.com/521
https://wikidocs.net/16272