Seongkyun Han's blog
Seongkyun Han's blog
자율주행 자동차에 대해서
30 Oct 2019 | 자율주행 Autonomous driving자율주행 자동차에 대해서
- 자율주행 자동차란?
- 자동차관리법 제 2조 제 1호의 3항에 따라 “승객의 조작 없이 자동차 스스로 운행이 가능한 자동차”를 의미함
- 즉, 운전자의 핸들, 가속페달, 브레이크 조절이 필요없이 정밀지도와 각종 센서를 이용해 상황을 파악하고 스스로 목적지까지 움직여주는 자동차
자율주행의 필요성
- 인적요인으로 발생하는 교통사고(90% 이상)를 방지
- 음주, 과속, 피로누적 등등..
- 전 세계적으로 매년 125만명의 사람이 운전자 과실로 인한 교통사고로 사망
- 자율주행을 적용해 이러한 인적요인을 제거
- 안전한 차간거리 유지, 적절한 속도 관리로 정체를 발생시킬 수 있는 요소를 차단해 교통의 효율화 가능
- 고령 운전자 및 장애인을 위해 필요
- 운전의 효율화
- 정리하자면
- 안전성: 인적요인에 의한 사고 감소
- 효율성 및 친환경성: 교통체증 완화, 운전의 효율화를 통한 환경오염 감소
- 편의성: 사용자의 편의성 향상
- 사회적 수용성: 노약자의 이동성 향상
- 접근성: 도시 주요부로의 접근성 향상
자율주행 기술
자율주행 단계
- 자동차기술자협회(SAE)의 5단계와 미국도로교통안전국(NHTSA)의 4단계가 존재
- SAE 기준
- 0단계: 자동제어 장치 없이 일반적으로 사람이 운전
- 1단계: Foot off. 자동긴급제동장치(AEB), 어뎁티브 크루즈 컨트롤(ACC), 핸들 조향 지원 및 자동보조시스템 등의 적용
- 2단계: Hands off. 핸들 방향 조종 및 가감속 등 하나 이상의 첨단운전자보조시스템(ADAS) 적용
- 3단계: Eye off. 자율주행으로 정의되는 단계. 가속, 주행, 제동이 모두 자동으로 수행되나 특정 상황시 운전자의 개입이 필요한 조건부 자동화 단계
- 4단계: Head off. 시내주행을 포함한 도로 환경에서 운전자의 개입이나 모니터링이 필요 없는 자율주행. 고도의 자동화 단계
- 5단계: Driver off. 완벽한 자율주행 수준. 모든 환경하에 운전자의 개입 없이 자율주행이 가능한 완전 자동화 단계
자율주행차의 주요 요소
- 주요 기술로는 환경 인식, 위치인식 및 맵핑, 판단, 제어, HCI 로 나뉨
- 환경 인식: 레이더, 라이다, 카메라, 초음파 센서 등의 각종 센서로 정적 장애물(가로등, 건물, 전봇대 등)과 동적 장애물(차량, 보행자 등), 도로 표식(차선, 신호, 횡단보도 등)을 인식하고, V2X통신을 통해 도로 인프라 및 주변 차량과 주행정보를 교환
- 위치인식 및 맵핑: GPS, INS, Encoder, 기타 맵핑을 위한 센서를 사용. 자동차의 절대/상대 위치를 계산
- 판단: 목적지 이동, 장애물 회피 경로 계획, 주행상황별(신호등 처리, 차선유지 및 변경, 회전, 추월, 유턴, 급정지, 끼어들기, 주정차 등) 행동을 스스로 판단
- 제어: 운전자가 지정한 경로대로 주행하기 위해 차량의 조향, 속도 변경, 기어 등의 엑츄에이터 제어
- HCI: Human Computer Interaction. 주로 HMI(Human Machine Interaction)으로 정의됨. 운전자에게 경고 또는 정보를 제공하고 운전자의 명령을 입력받음
- 자율주행의 메커니즘
- 주행 주변 환경에 대한 각종 정보를 센서들을 이용해 수집하는 단계
- 센서를 통해 수집된 정보들을 처리하고 차량을 통제하는 알고리즘 단계
- 알고리즘을 실시간으로 처리하는 전산처리 단계
- 시스템적 요소는 인지, 판단, 제어로 나뉨
- 인지: 자동차의 센서들이 차량 주변에 대한 데이터를 수집
- 경로탐색: 고정밀 디지털 지도
- 센서: 카메라, 레이더, 라이다 등
- V2X: V2V, V2I 등의 통신
- 판단: 수집된 데이터를 소프트웨어 알고리즘으로 분석/해석
- 경로탐색: 차량의 절대적, 상대적 좌표, 3D 지도정보
- 센서: 차량 주변의 장애물, 도로 표식, 신호
- V2X:도로의 인프라 및 주변차량 정보
- 위의 정보들을 취합해 목적지까지의 주행 경로 설정, 돌발상황에 대한 판단과 주행 전략 등을 결정
- 제어: 앞 단계에서 취합된 정보들을 바탕으로 운행 계획에 따라 자동차의 동작을 제어
- 차량 제어
- 조향 조절, 엔진 가/감속
- 운전자에게 경고 및 정보 제공
- 인지: 자동차의 센서들이 차량 주변에 대한 데이터를 수집
- 자율주행차 주요 기술 구성
- 자율주행 차량의 센싱
- 레이더, 라이다, 레이저 센서
- HD급의 vision camera
- 적외선/자외선 센서
- 환경 센서
- 자율주행 소프트웨어
- 주행상황 인지 소프트웨어
- 센싱 융합처리 드라이빙 컴퓨팅
- 인공지능(AI)기반 컴퓨팅
- 클라우드 기반 컴퓨팅
- 통신보안
- 차량 무선통신 시스템
- 협력주행 네트워킹
- 이동통신망 연동 네트워킹
- V2V, V2I(infra) 정보보호 및 보안
- 통신 이상징후 탐지
- 안전운전
- 교통약자 안전운전 지원 HMI
- 운전자 케어 UI/UX
- 다중 차량 무선충전
- 인포테인먼트
- 자율주행 차량의 센싱
- 자율주행 소프트웨어 구조
- Cloud map, GPS, INS/IMU, Vehicle State, Lidar 등을 이용한 Localization (Map matching)
- Lidar, Camera 등의 센서에서 얻어진 정보들을 이용해 Object detecion, tracking, Lane detection 등을 수행
- 위의 결과들과 RNDF, Traffic light information을 토대로 Navigation
- Global/local path planning, Path following, Speed planning
- Navigation 결과를 VCU(Vehicle Control Unit)로 전달
- Steering, Brake, Acceleration
자율주행 주요 기술
- 컴퓨터 플랫폼: Nvidia Drive PX2, Xavier, Mobileye EyeQ, TI TDA 3X 등의 인공지능 플랫폼
- V2X 통신: C-ITS, 5G, WAVE(도로 인프라 및 주변차량 정보 수집/취합)
- 보안: 전장 플랫폼 보안, 내/외부 네트워크 보안, KMS(암복호화 키 관리 시스템), AFW(어플리케이션 방화벽)
- AI: 강화학습, 딥러닝 학습
- 인지: 차선, 보행자, 차량 검출등의 Object detection
- 판단: 의도 판단, 경로 예측
- 제어: 사용자 개인화 기반 최적 제어
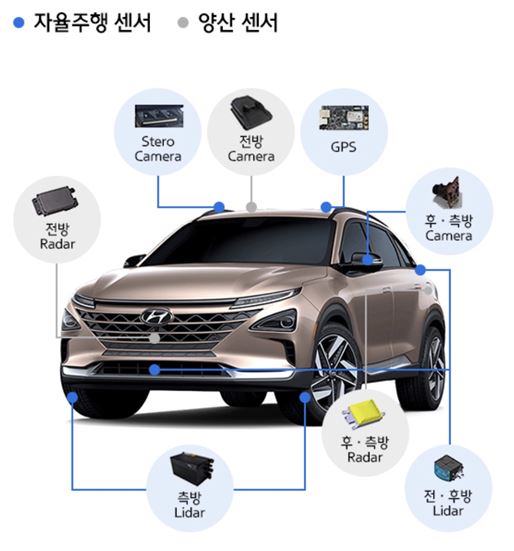
자율주행 차량의 센서
- 주로 인지를 위해 사용
- 핵심센서는 다음과 같음
- 카메라: 대상 물체에 대한 형태 정보를 제공하며 차선, 표지판, 신호등, 차량, 보행자 등을 탐지하기 위한 정보를 센싱
- 라이다: 레이저를 이용해 현재위치부터 목표물까지의 거리, 방향, 속도, 온도 등의 특성을 감지하며 전파에 가까운 성질을 가진 레이터 광선을 이용하여 활용가능범위가 매우 넓음
- 레이다: 전자기파를 발사해 반사 신호 분석을 통해 거리, 높이, 방향, 속도 등 주변정보를 습득
- 센서들은 외적인 요인들로 인해 클리닝 문제, 내구성 문제 등이 발생 할 수 있기 때문에 해당 문제 또한 중요함
- 정상적인 자율주행을 위해선 최적 상태의 센서가 유지되어야 함
카메라
- 장점
- 스테레오 카메라를 이용해 얻어진 영상에 양안시차의 원리를 적용하여 객체와의 거리를 계산하고 어떤 객체인지 종류도 분류 가능
- Object detection
- 비교적 먼 거리를 볼 수 있으며, 시야 내의 모든 정보를 센싱 가능
- 다른 센서에 비해 월등히 저렴함
- 스테레오 카메라를 이용해 얻어진 영상에 양안시차의 원리를 적용하여 객체와의 거리를 계산하고 어떤 객체인지 종류도 분류 가능
- 단점
- 시스템의 분석능력이 아직 정확하지 않음
- 딥러닝 모델등을 이용해 극복 가능
- 사람의 눈과 같은 메커니즘으로 악천후 등의 기상상황에서 주변환경을 인지함에 있어 매우 불리함
- 센서 퓨전을 통해 극복 가능
- 시스템의 분석능력이 아직 정확하지 않음
- 현재 모빌아이의 자율주행 시스템이 카메라를 중심적으로 활용하고 있음
- 테슬라가 사용했었음 (현재는 NVIDIA)
라이다(Lidar)
- 자율주행차량의 센서 중 객체 감지에 잇어 핵심이 되는 센서
- 주변 환경에 레이저를 조사하고, 반사된 레이저광이 센싱될 때 까지의 시간을 측정해 비교적 정확하게 주변 사물과의 거리를 측정 할 수 있음
- 이를 통해 SLAM의 기반이 되는 맵을 생성 할 수 있음
- 실시간으로 주변 환경에 대한 3차원 데이터를 수집해 도심과 같이 수많은 객체가 존재하고 움직이는 환경에서 매우 중요한 역할을 함
- 하지만 가격이 비싸고 고도의 데이터 처리 능력이 필요하다는 단점이 있음
- 라이다는 레이더와 다르게 카메라와 병렬로 구동할 필요가 없음
- 적외선 레이저를 사용해서 주변의 빛(햇빛 등) 요소에 강건한 단색의 3D맵을 실시간으로 생성 할 수 있음
- 파장이 짧은 펄스 레이저를 사용해 해상도가 좋기 때문에 정밀하게 맵을 생성하고, 이로 인해 비춰지는 대상이 무엇인지 파악 가능함
레이더(Radar)
- 라이다처럼 주변에 신호를 보내 반사된 신호의 시간을 측정해 거리를 탐지하는 센서
- 레이저를 사용하는 라이다와 다르게 라디오 주파수를 사용함
- 이로인해 유효 감지거리가 라이다에 비해 길고 라이다보다 손쉽게 주변 차량의 상대속도 등을 측정 할 수 있음
- ACC(Adaptive Cruise Control)과 같은 차량 보조 시스템에서 사용됨
- 이로인해 유효 감지거리가 라이다에 비해 길고 라이다보다 손쉽게 주변 차량의 상대속도 등을 측정 할 수 있음
- 하지만 레이더는 단단한 물체에서 반사되는 파장만을 탐지하기때문에 금속과 같은 성문 이외의 물체 탐색이 어려움
- 일반적인 상황에서 사람을 찾을 수 없음
- 또한 앞에 존재하는 객체가 밟고 지나가도 되는 봉지인지, 아니면 돌맹이인지 구분을 하지 못하므로 카메라에서 얻어지는 정보를 같이 사용해야 함
- 이로인해 레이더 단독으로 자율주행 구현이 불가능하며, 센서퓨전을 통해 단점을 보완해야 함
초음파 센서
- 1~10m 거리 내의 사물에 대한 탐지 능력이 우수하며 상대적으로 저렴
- 주로 주차 보조 시스템에 많이 활용됨
적외선 센서
- 주변에 조명이 없는 경우 적외선을 조사해 반사된 적외선을 통해 적외선 영상정보를 획득 할 수 잇음
- 악천후 상황 속에서도 객체 감지가 가능함
- 야간에도 보행자와 자전거 등 사람 및 사물등의 감지가 가능
-
하지만 탐지 가능 거리가 짧아 보조 센서의 역할로만 사용됨
- 외에도 다양한 센서 관련 내용이 있지만 이는 후술
센서 퓨전
- 자율주행의 레벨이 높아짐에 따라 여러 센서를 퓨전하여 사용하는 방법들이 제시됨
- 어느 센서로 들어온 데이터를 중심으로 전반적인 데이터 취합을 하느냐에 따라 방법이 나뉨
- LIDAR와 GPS를 이용해 구성된 맵데이터를 보조적으로, 카메라로 획득된 정보를 주로 사용하는 Incremental approach
- Tesla, GM, Ford, Volvo 등의 주요 OEM
- 가성비가 매우 높으며, 하드웨어 복잡도가 낮음. 또한 맵에 대한 의존도도 낮기때문에 Robust한 장점이 있음
- 반면 높은 수준의 센서 퓨전 기술이 필요하고, 딥러닝 기반으로 동작해야 하기 때문에 고성능 하드웨어 프로세서 필요(가격상승요소)
- LIDAR와 GPS를 이용해 구성된 맵데이터를 주로, 카메라로 획득된 정보를 보조적으로 사용하는 Disruptive approach
- 맵 구성에 필요한 자원을 아낄 수 있어 경쟁성이 있음
- 반면 대량의 지도 데이터를 확보하지 않은 상태에선 자율주행의 동작이 불가하며 라이다 가격이 매우 비쌈. 또한 회전하는 기계식 라이다 채용으로 인해 디자인적 요소가 훼손됨
- LIDAR와 GPS를 이용해 구성된 맵데이터를 보조적으로, 카메라로 획득된 정보를 주로 사용하는 Incremental approach
V2X
- 위급상황과 같은 안정성 제고를 위한 필수적인 시스템으로 차량의 고속주행 속에서도 높은 패킷전송률과 낮은 지연율을 요구하는 기술
- 5G 통신의 보급으로 해결
- 카메라 등의 다양한 센서들과 다르게 악천후 조건에서도 무리없이 통신 가능하기 때문에 안정성을 높여주는 역할로 주로 적용
고정밀 위치 측위
- GPS의 경우 거리적 오차가 크고, 서울과 같은 도심에서는 위성 신호가 반사되어 신호 포착이 어렵기 때문에 자율주행에는 고정밀 디지털 지도가 필수적으로 필요함
- 도로의 모든 정적정보를 3차원으로 표현한 고정밀 디지털지도를 통해 도로에 위치하고 있는 물체의 위치, 형태 등의 정보를 얻을 수 있음
- 이를 이용해 곡선로, 교차로 합류와 같은 어려운 상황에 쉽게 사전 대응이 가능
인공지능
- 차량에 탑재된 센서들과 V2X를 통해 습득된 교통, 도로 정보들을 분석하고 자체적인 판단을 통해 차량을 제어
- 차량을 운행하는 과정 중 지속적으로 제공되는 광범위한 정보를 빠르게 처리하고 판단
- 인공지능의 자율주행 적용엔 강화학습 방법과 End-to-end 방법이 있음
- 강화학습: 주행 데이터 확보의 제약으로 충분한 학습이 어려운 분야에 적용되는 방법으로, 사람의 개입이 없어도 반복 학습을 통해 인공지능이 스스로 목적을 달성하는 과정을 터득
- End-to-end: 차량의 카메라 정보와 조향 정보를 사전에 학습용 데이터셋으로 쌓고, 이를 기반으로 특정 상황에 대한 주행 방법 및 알고리즘을 딥러닝 모델이 스스로 학습
- Drive.ai는 타 업체와는 다르게 딥러닝 시스템을 인지 센서 뿐만 아니라 동작 프로세스까지 확대하여 적용
- 타 업체의 경우 사전에 취득된 차량 센서 데이터(영상 등)을 사전 주석작업을 통해 GT를 만들고 이를 인지 학습시켜 인지 과정에서만 딥러닝을 적용
- Drive.ai는 주행 자체를 주행 시나리오로 학습시켜 전반적인 주행 과정을 차량이 학습하여 자율주행을 구현토록 함
객체 탐지
- 시내주행 상황
- 차량 존재여부, 거리, 상대속도 정보 획득
- 차종을 통해 운전자의 성격, 주행 습관 등 예측 및 추측 가능
- 표지판 인식
- 내용 인식 후 주의
- 사람 인식
- 어른과 아이를 인식하고, 아이의 돌발행동 대비 가능
- 바람부는 상황 등 인식
- 강풍으로 인해 무언가 날아 올 수 있을 수 있는 상황에 대비 가능
- 차량 존재여부, 거리, 상대속도 정보 획득
- 고속도로주행 상황
- 차량 존재여부, 거리, 상대속도 정보 획득
- 차종 분석을 통해 운전자의 성격, 행동 예측 가능
- 트럭 등의 선행차량 탐지를 통해 상대속도를 예측하고, 주변 차량의 주행차량 앞으로 끼어들기 등의 상황 예측 가능
- 차선 인식
- 노면 상태 및 차선 인식 가능
- 차량 존재여부, 거리, 상대속도 정보 획득
- 정체도로 상황
- 차량 인식
- 선행차량의 상대속도 탐지를 통해 차선변경 시 빠르게 갈 수 있는지 여부 등을 판단
- 트럭 등의 인식을 통해 주변 차량의 차선변경 등 예측 가능
- 차량 인식
- 날씨변화 상황
- 노면 인식
- 노면이 젖어있는지, 얼어있는지 등을 인식
- 결과를 토대로 안전을 위한 예측운전 등 가능
- 노면 인식
- 객체 탐지를 통해 보행자의 움직임, 차량 진행 방향, 도로인지 차도인지 등과 같은 문맥적 의미(Context awareness)를 이해 할 수 있음
딥러닝 학습 지능의 적용
- 기존의 규칙기반 방식(Rule-based approach)은 몇 가지 한계점이 존재
- 산업 내 전문성을 갖춘 인력들을 영입하고 오랜 시간에 걸쳐 정교하게 규칙들을 모델링 해야 하기에 매우 비효율적
- 또한 실제 상황에 지속적으로 적용하며 테스트를 반복해 검증하는 과정이 필요함
- 확장성이 매우 떨어짐
- 정교하게 모델링된 규칙을 만들었다고 하더라도 주행 규칙이 다른 국가에 적용하거나 기후적/지역적 주행환경이 다른 지역에 바로 적용하는것이 매무 어려움
- 이 경우 만들어진 모델을 새로운 환경에 맞게 재조정하는 과정이 필요하며, 또한 시간이 많이 소요되는 검증과정이 필요함
- 아무리 정교하게 만들어진 규칙이라 할지라도 주행 중 발생 가능한 모든 상황을 사전에 반영하는것은 불가능
- 산업 내 전문성을 갖춘 인력들을 영입하고 오랜 시간에 걸쳐 정교하게 규칙들을 모델링 해야 하기에 매우 비효율적
- 특화 센서+전문가 중심 구현
- BOSCH, Google, Continental 등(2009년 개발 초기)
- 범용 센서+딥러닝 중심 구현
- comma.ai, drive.ai
- 최소의 범용센서를 사용해 딥러닝을 통해 기능 구현
- 카메라+딥러닝 중심 구현
- AutoX, NVIDIA, UBER AI Labs
- 딥러닝 기반의 고도화된 비전 기술을 활용해 기능 구현
- 딥러닝 기반은 인간의 주행과정을 데이터화해 인공지능이 주행 방법을 학습하게 됨
- 사람이 운전을 반복하며 익숙해져 가능 과정과 유사
- 인공지능이 주행을 지속할 수록 다양한 상황에서의 대응 방법을 획득하고 터득함
- 강화학습 기반은 반복학습을 통해 인공지능이 다양한 주행 상황별 대응 방법을 스스로 터득하게 됨
- 수많은 반복 학습 과정을 통해 최적의 대응
- 방법을 스스로 깨우침
- 학습 과정에서 일일이 방법을 정의할 필요 없이 상황별 달성 목표와 보상만 정의함
- 아직은 선행연구단계.(2017년 기준)
사람처럼 사고하는 지능의 적용
- 인간처럼 생각하며 주행하는 자율지능 주행을 가능하게 하는 관계형 추론(Relational Reasoning) 모델
- 주변 상황들을 각각 개별적인 정보로 인식하고 이해하는것을 넘어 정보들 사이의 상대적 관계를 논리적으로 파악
- 이를 통해 각 사물 사이의 상대적인 관계를 직관적으로 인식 할 수 있음
- 이는 사람이 운전할 때 주변에 존재하는 차량들 간의 거리를 각각 개별적으로 인식하는것이 아니라 서로간의 상대적 거리와 속도를 종합적으로 인지해 주행하는 것과 마찬가지인 맥락임
- 사물의 움직이는 패턴을 학습하는 관계형 추론 모델의 적용도 가능
- 딥마인드 논문으로 화면 내 공들의 움직임을 6프레임만 학습시키면 향 후 150프레임까지 실제와 거의 일치하는 수준으로 예측
- 이러한 관계형 추론 모델을 이용해 상대적 관계를 이해할 경우 급차선변경이나 과속하는 차량의 정보를 토대로 해당 차량의 움직임을 미리 예측해 사고를 사전에 방지하는것 또한 가능해짐
- 출처: https://www.hyundai.co.kr/TechInnovation/Autonomous/Autonomous.hub
고속도로 자율주행
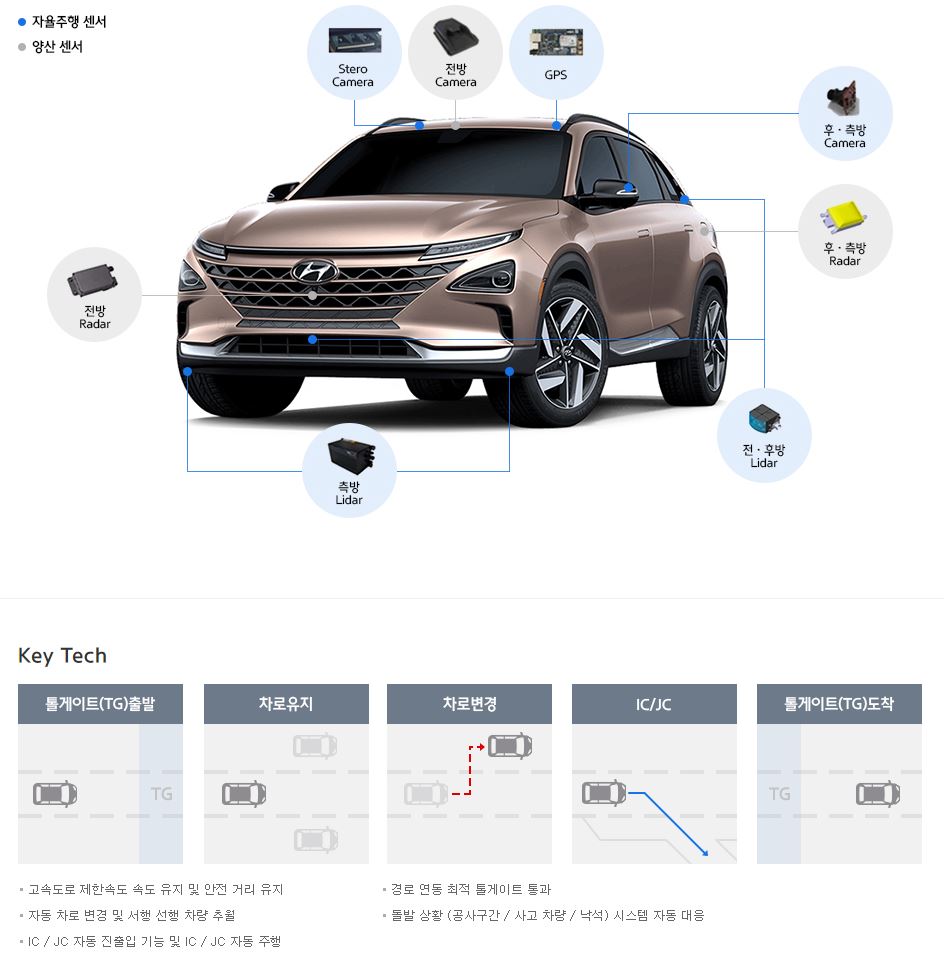
도심 자율주행
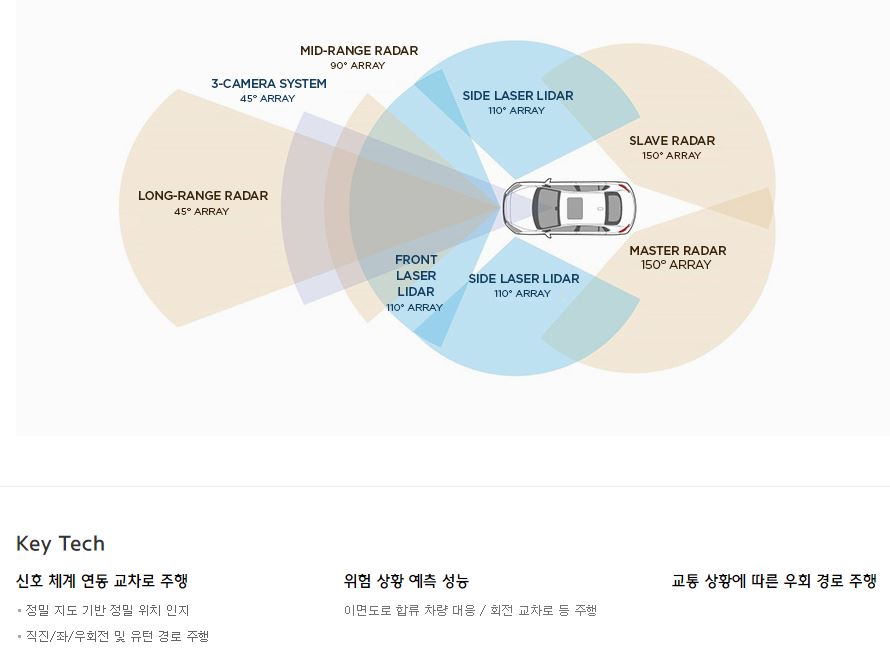
자율주차
- 자율 발레 파킹(AVPS, Automated Valet Parking System)
- 운전자의 개입 없이 스스로 이동하여 빈 공간을 찾아 차량을 주차/출차 하는 기술
- 전기차의 경우 알아서 충전소를 찾아 충전하고 다시 주차장으로 귀환해서 주차를 수행하게 됨
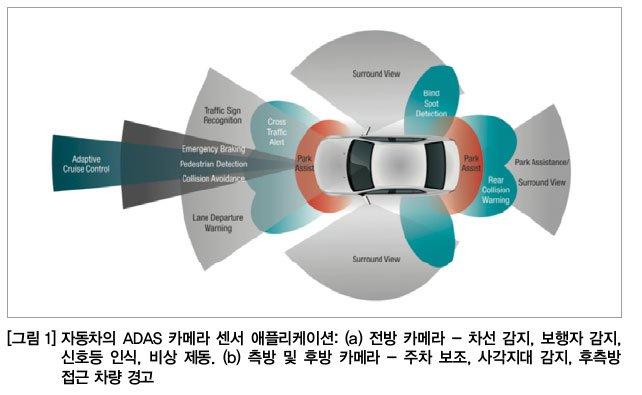
능동안전(ADAS)
- Adaptive Driver Assistance System
- 사고 발생 시/위협 감지 시 스스로 운전자에게 위험을 경고하고 브레이킹/핸들조향을 수행

현대자동차의 자율주행 기술
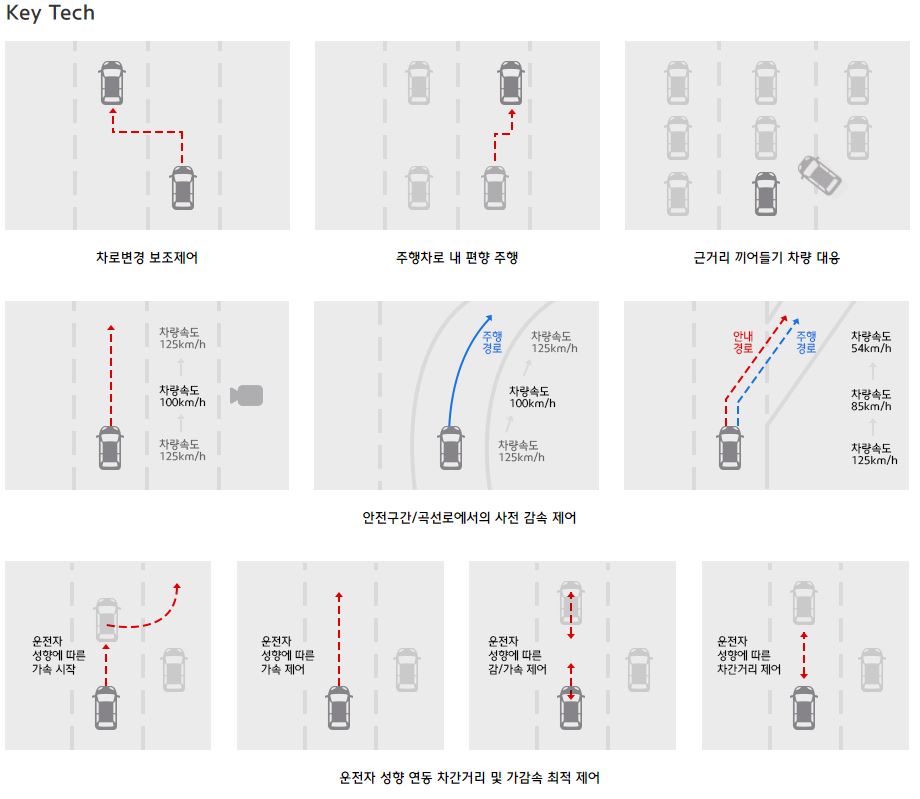
현대기아차 인공지능 기반 운전자 맞춤형 ADAS 기술(SCC-ML)
-
출처: Link
- 기존의 스마트 크루즈 컨트롤(SCC, Smart Cruise Control)에 머신러닝 인공지능 기술을 기반으로 자동차가 스스로 운전자의 주행 성향을 파악(학습)해 운전자 맞춤형 SCC를 구현
- 기존의 SCC는 차간 거리, 가속도 등의 주행 패턴을 차량이 임의로 결정하거나 운전자가 직접 설정해야 했으며, 조절 단계가 세밀하지 않았음 (4단계)
- 사용자가 이질감을 느끼지 않도록 주행 성향과 거의 흡사한 패턴으로 자율주행을 구현하는것이 SCC-ML의 핵심기술 (ML: Machine Learning)
- 인공지능의 적용?
- 머신러닝 알고리즘을 적용해 운전자의 패턴을 파악함
- 복잡한 딥러닝 구조가 아닌 단층 퍼셉트론의 머신러닝 모델을 사용해 운전자의 주행성향을 학습하도록 함
- 현대차에선 단층 네트워크만으로도 충분한 특징을 추출 할 수 있었다고 함
- 머신러닝 알고리즘을 적용해 운전자의 패턴을 파악함
- SCC-ML의 구현 원리
- 전방 카메라, 레이더 등의 센서로 주행중에 얻어진 정보를 지속적으로 수집해 ADAS의 두뇌인 ADAS 제어컴퓨터로 보냄
- 제어컴퓨터는 입력된 정보로부터 운전자의 주행 습관을 판단 할 수 있는 정보만을 추출함 (네트워크 학습)
- 학습된 네트워크의 추론결과를 토대로 SCC를 가동시킬 때 운전자와 가장 유사한 자율주행을 구현함
- ADAS 제어컴퓨터의 역할
- ADAS 기술을 관장하는 두뇌로, 센서로부터 각종 정보를 받고 취합
- 센서퓨전 기술을 적용하여 여러 센서들에서 동시에 얻어진 신호들을 정리하여 하나의 인터페이스로 처리
- SCC-ML은 융합된 정보를 통해 주행 패턴을 결정하고 그에 상응하는 주행을 실시
- SCC-ML이 판단하는 주행 패턴은 얼마나 될까?
- 총 1만개 이상의 주행 패턴을 구분 할 수 있음
- 차간거리, 가속성, 반응성의 세 가지 항목을 모두 조합 했을 때 1만개 이상의 경우의 수 설정 가능
- 운전자 데이터 분석 결과 주행 성향이 현재의 주행속도에 따라 다르다는것을 파악함
- 저속에서 가속을 과감하게 하는 운전자는 중/고속에서도 같은 성향을 보이는것은 아님
- 저속에서 차간거리를 가깝게 유지해도 고속에선 차간거리를 멀게 설정함
- SCC-ML은 다양한 상황을 가능한 한 모두 고려함
- 향후에는 더 다양한 상황도 결정할 수 있게끔 연구중
- 저속에선 대형차량을 추월해 가지 않지만 고속에서는 추월해간다던지 등등..
- 실제 사람이 운전하는 것처럼 구현하기 위하여 기술개발 수행중
- 총 1만개 이상의 주행 패턴을 구분 할 수 있음
- 주행 패턴은 어떻게 학습되나?
- 학습에 필요한 시간은 약 1시간 정도이며, 이후에는 데이터가 누적되며 새로운 주행정보를 지속적으로 업데이트함
- 주행성향에 관한 정보는 센서로 계속 업데이트되기때문에 최근 성향을 반영하도록 설계됨
- 학습에 필요한 시간은 약 1시간 정도이며, 이후에는 데이터가 누적되며 새로운 주행정보를 지속적으로 업데이트함
- 인공지능 적용으로 인해 기존 패턴에 없는 새로운 주행 패턴을 만들기도 하는지?
- 1만개 이상의 패턴도 부족하다 생각하고 주행패턴을 추가하는 기술도 개발하긴 함
- 하지만 SCC-ML은 안전을 최우선으로 하는 기술이므로 검증되지 않은 패턴 적용 시 안전에 악영향을 끼칠것을 우려하여 배재함
- 즉, 안전이 검증된 패턴 내에서 운전자와 가장 가까운 패턴으로 매칭됨
- 향 후 안전 검증된 패턴이 추가로 개발된다면 데이터 업데이트를 통한 업그레이드 가능
- 하지만 OTA등의 극복 과제가 있으며, 기술이 성숙되면 SCC-ML의 OTA 업데이트 가능
- SCC-ML의 적용으로 고객이 불편함을 느끼는지?
- 따로 없음
- 단, 필요 시 사용 할 수 있도록 수동 조작 기능은 그대로 유지됨
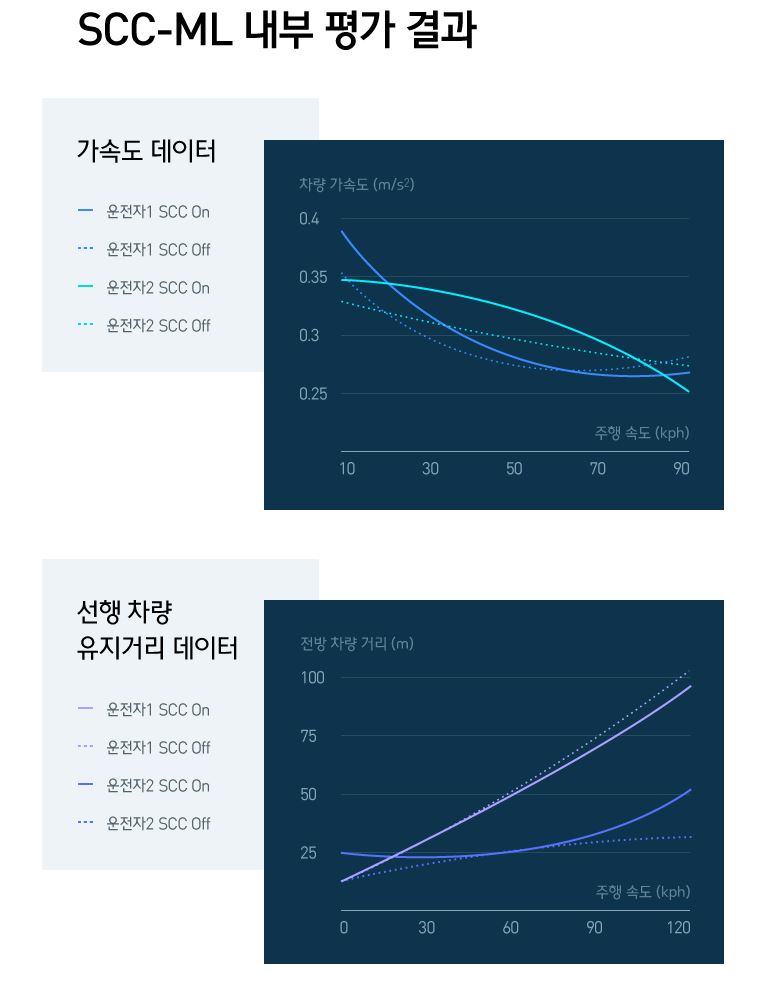
- 이처럼 SCC-ML은 운전자 주행 패턴을 매우 흡사하게 재현함
- 개발 기간
- 2년 반 정도 소요됨
- 통상적으로 3년도 되지 않은 기간에 신기술을 양산 적용하는것은 상당히 도전적인 시도임
- 2년 반 정도 소요됨
- 자율주행 시대에 운전 패턴 학습이 어떤 방향으로 진화할 것인가?
- SCC-ML은 완전 자율주행 시대에는 필요 없는 기술이 될 수 있음
- SCC-ML과 같은 기술은 자율주행 기능이 좀 더 운전자에게 가깝게 세팅되도록 돕는 기술
자율주행을 구성하는 핵심 기술
- 출처: Link
- 자율주행 구현을 위해 필요한 기술
- 측위, 인지, 판단, 제어 기술이 필요함
- 측위: 차가 도로 위 어디에 위치해 있는지를 계산. GPS를 이용함.
- 인지: 카메라, 레이더, 라이다 등 정밀 센서로 차량 주변 상황을 감지하는 기술
- 판단: 인지 기술로 취합된 데이터를 분석해 어디로 가야 하는지, 멈춰야 하는지, 신호등 신호처리 등등을 결정하는 기술
- 제어: 판단 결과를 차량의 구동계와 조향계에 명령을 내리는 단계
- 측위와 인지의 차이점
- 측위는 GPS와 고정밀 지도를 이용해 실제 차량의 위치와 차량이 스스로 인식하고 있는 위치를 디지털 지도상에서 일치시키기 위한 기술
- 실제 GPS는 도심환경에서 신호간섭등의 영향으로 오차가 큰 편임
- 차량에 부착된 센서로 주변 환경을 감지하는 인지기술이 병합되어야 함
- 차량 앞의 장애물, 차선, 인도와 도로 경계면, 노면 표식 등의 주변 환경 인식해 GPS의 한계를 보완해줌
- 이러한 것을 맵 매칭(Map Matching) 기술이라고 함
- 측위는 GPS와 고정밀 지도를 이용해 실제 차량의 위치와 차량이 스스로 인식하고 있는 위치를 디지털 지도상에서 일치시키기 위한 기술
- 각 센서가 주변 환경을 인식하는 방법
- 카메라는 광학계를 통해 취득한 영상을 데이터로 변환
- 차선, 차량, 보행자, 속도 표지판, 신호등, 방지턱 등 주행 방향에 있는 모든 물체의 형상을 인식하고 현재 차량과의 거리를 파악
- 레이더는 전자기파를 사용해 사물(형상)과 현재 차량과의 거리를 파악
- 밤이나 악천후 상황에서도 물체의 거리나 속도, 각도 등을 감지 할 수 있음
- 라이다는 빛(펄스 레이저, Pulsed Laser)을 이용해 주변을 탐색
- 카메라와 레이터로 확인 불가능한 사각지대를 감지할 수 있음
- 이렇게 카메라, 레이더, 라이다는 서로 상호 보완적인 관계로 모든 결과를 취합해 센서 퓨전 을 통해 필요한 맵 정보를 만들어냄
- 카메라는 광학계를 통해 취득한 영상을 데이터로 변환
- 주변 환경 인지에서의 기술적 한계
- 센서의 성능을 높이는데 많은 시간과 비용이 듦
- 라이다의 가격이 매우 비쌈
- 센서 퓨전을 통해 각 센서의 단점을 보완해 기술적 한계를 극복해나갈 수 있음
- 취합된 정보를 어떻게 자율주행에 이용하는가
- 취합된 많은 정보는 자율주행 ECU로 보내짐
- 자율주행 ECU에는 고성능 연산이 가능한 프로세서와 안전을 실시간으로 계산하는 프로세서가 각각 존재
- 취합된 정보를 토대로 향후 벌어질 일을 예측하고 가장 안전한 경로를 생성
- 차량 전방에 보행자나 장애물이 있다면 이것을 피해갈 것인지, 아니면 그냥 갈 것인지
- 어떤 길이 안전한지 위험한지 등 사전에 입력된 로직을 이용해 판단을 내림
- 판단 로직은 모든 상황에 대응 가능하도록 확률적 계산을 통해 설계됨
- 확률적으로 가장 위험도가 낮은 쪽으로 진행시키는게 기본 개발 방향임
- 자율주행 중 윤리적 판단이 필요한 경우의 대응
- 이는 자율주행 기술이 레벨 4이상으로 넘어가기 위해 해결해야 할 중요 과제
- 하지만 자율주행 기술은 실제로 엄청 안전하게 설계되므로 이런 상황조차 미리 예측하고 대응 및 준비가 가능해짐
- 자동차 메이커 입장에선 아예 윤리적 판단을 내려야 하는 상황이 생기지 않도록 해야함
- 자율주행 분야에서 현대차그룹이 가진 강점
- 다양한 자회사를 갖고 있으므로 측위, 인지, 판단, 제어에 필요한 기술 모두 직접 개발 가능함
- 따라서 매우 빠르게 자율주행 기술을 개발 할 수 있음
- 현대자동차그룹, APTIV와 Joint venture 설립
- 현대기아차 전략적 협업
- 현대모비스 미래 기술 집중 전략
- 세계 최초 AI 자동차 고장진단 시스템 개발
- 구동계 부분 부품의 고장 시 발생하는 이음의 특징을 추출해 딥러닝 모델을 학습시킴
- 사람의 정확도 8.7%의 10배 수준인 87%의 정확도를 보임