C++은 C를 확장시킨 언어이며, C는 절차지향 패턴을 따르는 반면 C++은 객체지향 패턴을 따름
C에서는 같은 이름을 가진 함수가 존재할 수 없지만, C++에서는 오버로딩/오버라이딩을 통한 존재 가능
오버로딩: 같은 이름의 함수를 여러 개 정의하고, 매개변수의 유형과 개수를 다르게 해 유형의 호출에 응답하게 함
오버라이딩: 상위 클래스가 갖는 멤버변수가 하위 클래스로 상속되듯이, 상위 클래스가 갖고 있는 메소드도 하위 클래스로 상속 되어 하위 클래스에서 사용 가능. 즉, 상속 관계에 있는 클래스 간에 같은 이름의 메소드를 정의하는 기술을 오버라이딩 (하위 클래스에서 해당 메소드 재정의해 사용 가능)
C에서는 변수, 함수를 코드 초반에 선언해야 하지만, C++에선 중간 어디서든 선언 가능
2. 클래스와 구조체의 차이점
C의 구조체
구조체는 하나의 구조로 묶일 수 있는 데이터, 즉 변수들의 집합
C에서도 클래스처럼 함수 포인터를 이용해 클래스처럼 함수를 포함시킬 수 있음
구조체(struct)는 default가 public
C++의 클래스
클래스는 구조체처럼 변수 뿐만 아니라, 합수(메서드)까지 포함 가능
클래스(class)는 default가 private
3. 객체지향 프로그래밍과 절차지향 프로그래밍과의 차이점은?
각각 객체지향 프로그래밍은 Object Oriented Programming(OOP), 절차지향 프로그래밍은 Procedural Programming
절차지향, 구조적 프로그래밍(C)
초창기에 많이 사용한 방법으로 순차적 프로그래밍이라고도 함
해야할 작업을 순서대로 코딩
구조적 프로그래밍에서는 함수 단위로 구성되며 기능별로 묶어놓은 특징이 있음
장점
컴퓨터의 처리구조와 유사해 실행속도가 빠름
단점
유지보수가 어려움
실행 순서가 정해져있으므로 코드의 순서가 바뀌면 동일한 결과를 보장하기 어려움
디버깅이 어려움
객체지향 프로그래밍(JAVA, C++, C#, Python)
주 구성요소는 클래스와 객체
상속과 다형성을 특징으로 들 수 있음
다형성은 오버로딩/오버라이딩을 의미
클래스를 활용해 각각의 기능별로 구성이 가능하며, 이를 나중에 하나로 합쳐서 프로그램의 완성이 가능
객체 별로 개발이 가능하기에 팀 프로젝트를 하기에도 유리한 장점을 갖고 있음
코드의 재사용이 가능하며 오류 발생 가능성이 적고 안전성이 높음
장점
코드의 재활용성이 높음
코딩이 절차지향보다 간편함
디버깅이 쉬움
단점
처리속도가 절차지향보다 느림
설계에 많은 시간소요가 들어감
4. C++ 클래스의 소멸자에 virtual 키워드 붙이는 이유
상속 받았을 때 virtual 키워드가 없다면 최상위 부모 객체에 대한 소멸만 이루어져 메모리 누수의 원인이 됨
C++에서 가상함수(virtual)는 파생클래스에서 재정의할 것으로 기대하는 멤버 함수를 의미
자신이 호출하는 객체의 동적 타입에 따라 실제 호출할 함수가 결정됨
기초클래스에서 virtual 키워드를 사용해 가상함수를 선언하면 파생 클래스에서 재정의된 멤버 함수도 자동으로 가상함수가 됨
5. 동적 바인딩이란?*
C++ 컴파일러는 함수 호출 시 어느 블록에 있는 함수를 호출해야 하고, 해당 함수가 저장된 정확한 메모리 위치까지 알아야 함
이처럼 함수를 호출하는 코드에서 어느 블록에 있는 함수를 실행하라는 의미로 해석하는 것을 바인딩(binding) 이라고 함
C++의 경우 함수가 오버로딩 될 수 있으므로 이 작업이 복잡해짐
대부분 함수를 호출하는 코드는 컴파일 타임에 고정된 메모리 주소로 변환되는데, 이것을 정적 바인딩 또는 초기 바인딩 이라고 함
C++에서는 가상함수가 아닌 멤버함수는 모두 정적 바인딩
가상함수의 호출은 컴파일러가 어떤 함수를 호출해야 하는지 미리 알 수 없음
따라서 가상함수의 경우에는 런타임에 올바른 함수가 실행되도록 해야 하는데, 이를 동적 바인딩이라고 함
6. 가상 함수 테이블이란?*
클래스 안에 가상함수가 포함되어 있을 시 객체를 생성할 때 가상함수를 가리키는 포인터가 생성됨
이 포인터는 가상테이블의 시작주소를 가리키는 포인터이며, 각 클래스마다 하나의 고유 가상테이블이 생성됨
가상함수를 호출하면 C++ 프로그램은 가상함수 테이블에 접근해 자신이 필요한 함수의 주소를 찾아 호출함
가상 함수를 사용하면 이처럼 함수 호출의 과정이 복잡해지므로 메모리와 실행속도 측면에서 부담이 가중됨
7. malloc()과 new에 대해
malloc()은 함수이고 new는 연산자
malloc()은 시스템함수로서 함수 안에서 메모리를 할당함
new는 연산자로 바로 메모리를 할당하는것이 아니라 생성자를 호출해 메모리를 할당
생성자를 통해 호출하기때문에 new로 메모리를 할당하면 생성 시 초기화가 가능한 장점이 있음
realloc()은 메모리 할당이 실패할 경우 null이 반환되기 때문에 기존의 메모리가 할당되어있는 포인터를 잃어버리게되는 문제가 있음
8. 오버로딩과 오버라이딩
오버로딩: 하나의 클래스에 같은 이름을 가진 메서드를 재정의
변환형, 매개변수의 타입이 다르거나 매개변수의 개수가 달라야 함
오버라이딩: 클래스 간 상속 관계에서 메서드를 재정의
단순 재사용이 아니라 자식 클래스에서 상속 받은 메서드를 재정의하며 다른 연산을 수행토록 함
조건: 메서드 이름, 매개변수, 리턴 타입이 같아야 함
9. Volatile 키워드
Volatile로 선언된 변수는 외부적인 요인으로 그 값이 언제든지 바뀔 수 있음을 뜻함
따라서 컴파일러는 volatile 선언된 변수에 대해서는 최적화를 수행하지 않음
사용 이유
Memory-mapped I/O처럼 메모리 주소에 연결된 하드웨어 레지스터에 값을 쓰는 프로그램이라면 이런 컴파일러의 최적화 방식(반복작업 하지 않도록 하는)은 오류를 야기할 수 있음
각각의 register writing 과정이 하드웨어에 특정 명령을 전달하는 것이므로, 주소가 같다는 이유만으로 중복되는 쓰기 명령을 없애버리면 하드웨어가 오작동할 수 있음
사용되는 분야: 임베디드 프로그래밍, 인터럽트 서비스 루틴의 사용, 멀티 쓰레드 환경
공통점은 현재 프로그램의 수행 흐름과 상관없이 외부 요인이 변수 값을 변경 가능하다는 점
10. Call by value, Call by reference
함수 호출 시, 메모리 공간 안에서는 함수를 위한 별도의 임시 공간이 생성됨(C++은 스택에 저장)
함수 종료시 해당 메모리 공간은 사라짐
Call-by-value, 즉 값에 의한 호출 방식은 함수 호출 시 전달되는 변수의 값을 복사해 함수의 인자로 전달하는 방식 이며, 이 인자는 함수 안에서 지역적으로 사용되는 local 변수의 성격을 가짐
따라서 함수 외부에서 값이 변경돼도 외부 값은 그대로 유지됨
Call-by-reference, 즉 참조에 의한 호출 방식은 함수 호출 시 전달되는 변수의 레퍼런스(주솟값)를 인자로 전달하는 방식 이며, 함수 안에서 값이 변하면 외부의 전달해준 값도 변경됨
그냥 전달받은 변수가 저장된 메모리 주소에 접근해 해당 값을 갖고 연산한다고 생각하면 됨
11. C에서 구조체(struct)의 sizeof 적용시 주의점
typedefstructtemp{chara;intb;}T;
위 경우, 1byte의 cher와 4byte의 int의 변수를 가지므로 sizeof(T)를 하면 5가 나올 것으로 예상 할 수 있음
하지만, 실제로는 sizeof(T)=8
이는 구조체 안에서 가장 큰 자료형을 따라가기 때문이며, 순서에 따라 또 달라짐
12. const 키워드
포인터 변수에 const 키워드를 붙이는 방법은 2가지가 있음
const int* MAX = &value: const가 앞에 붙는 경우로, *MAX = 10으로 다른값으로 초기화 불가
int* const MAX = &value: const가 뒤에 붙는 경우로, MAX = &other로 다른 포인터 변수로 초기화 불가
const int* const MAX = &value: 둘 다 불가능 (값 및 다른 포인터 변수로 초기화 불가)
구조체 멤버 변수에 const 키워드가 붙는 경우 구조체 변수를 생성할 때마다 초기화를 해줘야 함
클래스 멤버 변수에 const를 뒤에 붙이면 그 함수 내에선 클래스 멤버 변수 값을 변경 할 수 없음
즉, const 함수 내에서는 const 함수가 아니면 호출 불가
함수 내에서 매개변수를 const로 상수화시키는 경우는 값이 변하면 안되는 매개변수에 const를 사용해줘 실수로 발생하는 버그를 줄임
13. 함수 포인터
함수를 배열 또는 구조체에 넣거나, 함수 자체를 함수의 매개변수로 넘겨주고, 반환값으로 가져오기 위해 만든 포인터
voidhello(){printf(“Hello,world!\n”);}intmain(){void(*fptr)();//반환 없는 void, 매개변수가 없는 함수포인터 fptr 선언// int (*fptr)(int, int); << 반환형이 int이고, 매개변수가 int 2개를 받는 함수포인터 fptrfp=hello;fp();// Hello, world! 출력}
14. 메모리 단편화를 해결할 수 있는 기법
메모리 단편화: 사용가능한 메모리가 충분히 존재해도 할당(사용)이 불가능한 상태
내부 단편화: 할당될 크기에 비해 실제 나뉘어 있는 메모리의 크기가 커서 해당 단위 자원 내부에 사용하지 않는 메모리 공간이 발생 할 때를 의미
즉, 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 상황
ex. 메모장을 사용할 때 OS가 4kb를 할당해줬지만, 실제론 1kb만큼만 사용하고 있다면 3kb만큼의 내부 단편화가 발생함
외부 단편화: 나뉘어 있는 단위의 크기보다 할당될 크기가 더 커서 남는 메모리의 전체 합은 충분하나 할당이 불가능할 때를 의미
즉, 메모리 할당/해제의 반복 작업에서 사용되지 않는 작은 메모리가 중간중간 존재하게 되고, 이 작은 메모리들이 많아져서 총 메모리 공간은 충분하지만 실제로 할당 할 수 없는 상황
ex. 32MB 램에 처음에 8mb, 다음에 16mb, 마지막에 8mb 메모리가 할당되는 프로세스가 돌아가고 첫 번째와 마지막 프로세스가 종료된 경우, 총 빈 공간은 16mb가 되지만 9mb가 필요한 새 프로세스에 대한 메모리를 할당할 공간이 부족해지는 현상
해결방법
압축: 여러 곳에 분산되어 있는 단편화된 메모리 공간들을 결합해서 하나의 큰 공간으로 만듦
페이징: 가상메모리 사용, 외부 단편화 해결, 내부 단편화 존재
보조기억장치를 이용한 가상메모리를 같은 크기의 블록으로 나눈 것을 페이지라 하고, RAM을 페이지와 같은 크기로 나눈 것을 프레임이라고 할 때
사용하지 않는 프레임을 페이지에 옮기고 필요한 메모리를 페이지 단위로 프레임에 옮기는 기법
페이지와 프레임을 대응시키기 위해 page mapping 과정이 필요해서 paging table을 만듦
페이징 기법을 사용하면 연속적이지 않은 공간도 활용 가능하기에 외부 단편화 문제를 해결 가능
하지만 페이지 단위에 맞게 꽉채워 쓰는게 아니므로 내부 단편화의 문제는 여전히 존재
페이지 단위를 작게하면 내부 단편화 문제도 해결 가능하지만 page mapping 과정이 복잡해져 효율이 떨어지게 됨
세그멘테이션: 논리 메모리와 물리 메모리를 서로 다른 크기의 논리적 단위인 세그먼트로 분할
메모리에 적재될 때 빈공간을 찾아 할당하는 사용자 관점의 가상 메모리 관리기법
공간들을 계속 쓰다보면 결국 외부 단편화가 발생 할 수 잇음
15. 인터페이스와 추상클래스의 차이
추상 클래스의 목적
기존의 클래스에서 공통된 부분을 추상화하여 상속하는 클래스에게 구현을 강제화
메서드의 동작을 구현하는 자식클래스로 책임을 위임/공유의 목적
인터페이스의 목적
구현하는 모든 클래스에 대해 특정한 메서드가 반드시 존재하도록 강제
인터페이스는 다중 구현이 가능하지만 추상클래스는 다중 상속이 불가능
16. 인라인 함수
일반적인 함수를 호출할 때, 새로운 스택을 생성해 프로그램 카운트 루틴을 새롭게 시작하게 됨
이 경우 성능저하를 초래할 수 있음
인라인 함수는 실제 함수를 호출하는것이 아닌, 정의된 함수가 호출의 시기의 루틴에 그대로 코드를 옮겨놓는 것과 같은 결과를 만들어냄
빨라진다!
17. 수많은 생성자에 관해
디폴트 생성자: 인수도 없고 내용도 없는 생성자
클래스 내에서 아무런 생성자도 정의하지 않은 경우 호출됨
내용이 비었기에 멤버 변수는 쓰레기 값을 갖고 있음
복사 생성자: 같은 클래스의 객체끼리의 대입을 할 때 사용되는 생성자
디폴트 복사 생성자: 같은 클래스 타입의 객체를 인수로 받아 멤버 대 멤버 복사를 하는 생성자
얕은 복사: 복사 생성자를 통해 다른 객체가 힙에 할당된 동일한 메모리에 있는 변수를 참조
결국 새로운 주소값을 생성한 것이 아닌, 받아온 객체가 갖고 있는 멤버 변수의 메모리에 다리만 얹어놓는 꼴
깊은 복사: 이를 위해선 컴파일 상에서 제공된 디폴트 복사 생성자를 오버로딩 해야함
myClass(constmyClass&T){a=T.a;name=newchar[strlen(_name)+1];strcpy(name,_name);}// 매개변수로 자신 객체가 들어올 때 상황에 대해 똑같이 한번 더 오버로딩 해줌
18. void 포인터
포인터 주소를 저장하는 변수
포인터의 크기는 4byte (32bit OS 기준)
void 포인터는 자료형이 결정되지 않은, 어떤 자료형의 주소든 그 주솟값을 저장하는 포인터
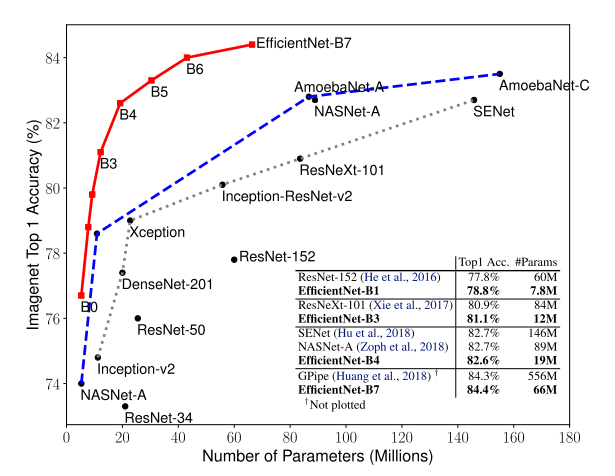
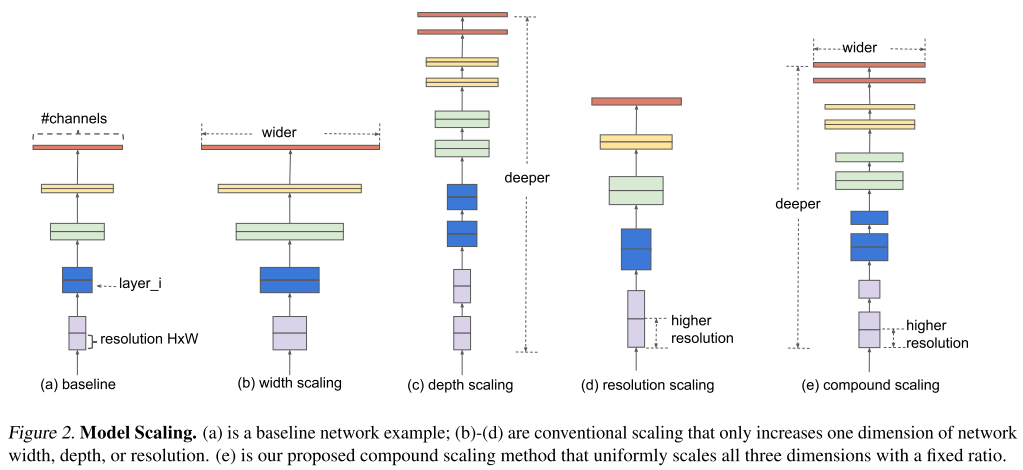
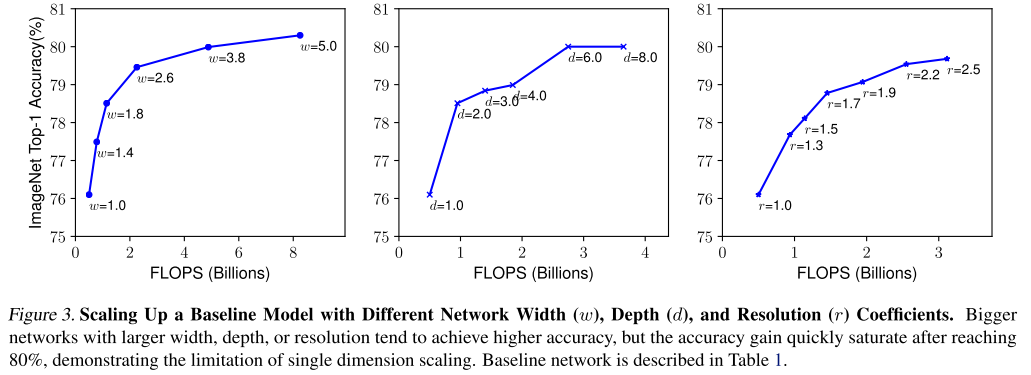
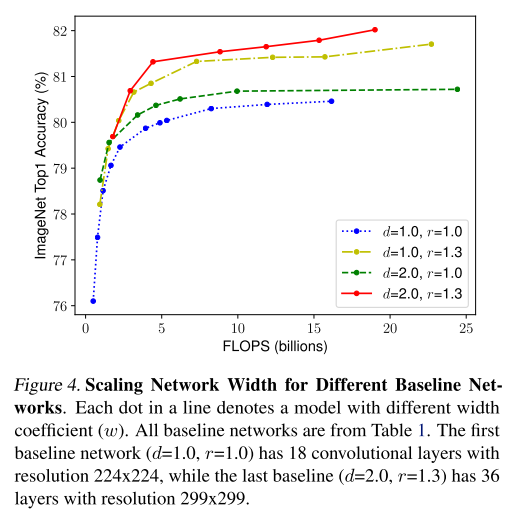
Pretrained 된 모델을 이용해 다른 task에서 transfer learning을 하는것은 computer vision 분야에서 매우 효과가 좋음
하지만 여기엔 슬픈 전설이 있음
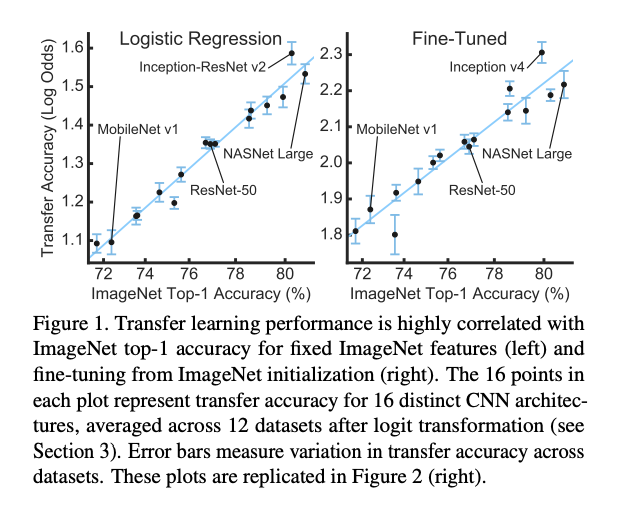
ImageNet에서의 성능이 좋은 모델일수록 해당 모델을 backbone으로 사용해서 transfer learning을 하면 성능이 더 좋음
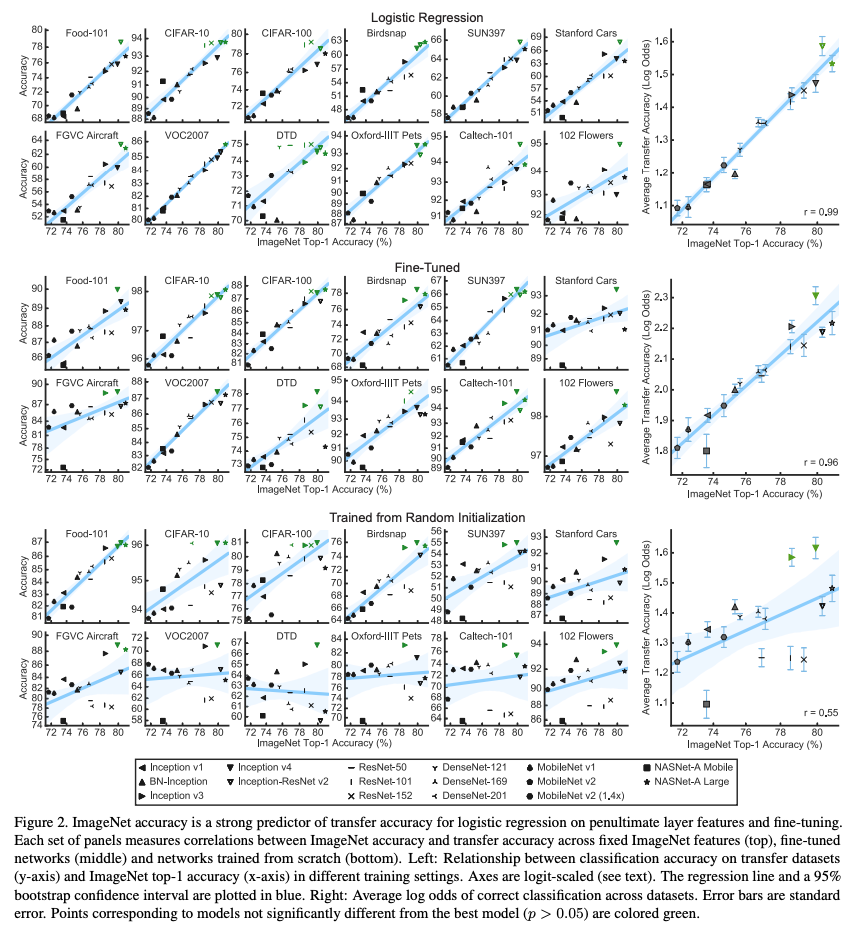
본 논문에서는 12개의 데이터 셋, 16개의 classification 모델을 비교해서 위의 가설이 사실인지 검증함
실제 backbone과 tranfer task와의 성능에 대한 상관 관계가 매우 높은것을 확인함
Introduction
지난 십여년간 computer vision 학계에서는 모델간 성능 비교를 위한 벤치마크 측정 수단을 만들이는데 공을 들임
그 중 가장 성공한 프로젝트는 ImageNet
ImageNet으로 학습된 모델을 이용해 transfer learning, object detection, image segmentation 등의 다양한 task에 대해 성능평가를 수행함
여기서 암묵적인 가정은
ImageNet에서 좋은 성능을 보이는 모델은 다른 image task에서도 좋은 성능을 낸다는 것
더 좋은, 성능이 좋은 모델을 사용할수록 transfer learning에서 더 좋은 성능을 얻을 수 있음
이전의 다양한 연구들을 토대로 위 가정들은 어느정도 맞는듯 함
본 논문에서는 실험 기준을 세우기 위해 ImageNet feature와 classification model 모두를 살펴봄
16개의 최신 CNN 모델들과 12개의 유명한 classification dataset을 사용해 검증
논문에서는 총 3가지 실험을 수행
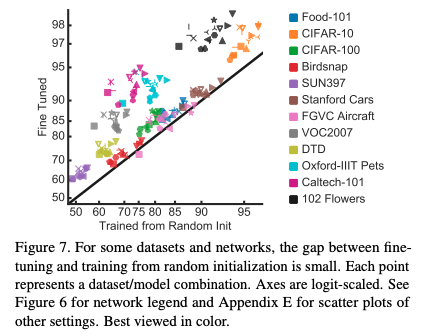
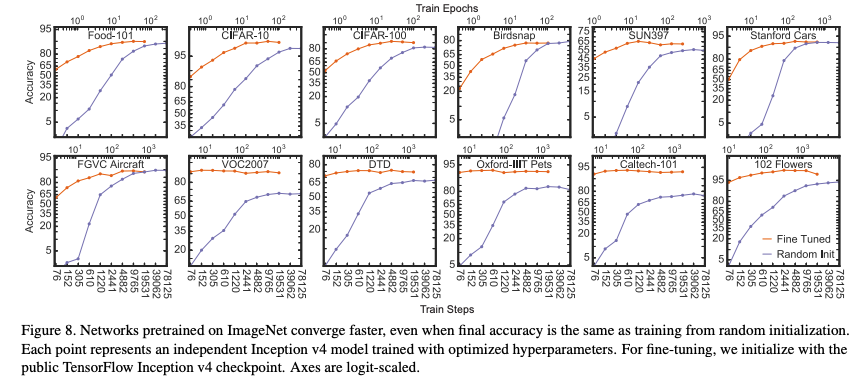
Pretrained ImageNet에서 고정된 feature 값을 추출한 뒤, 이 결과로 새로운 task를 학습
Transfer learning as a fixed feature extractor
Feature extractor는 그대로, 뒤 쪽은 학습
Pretrained ImageNet을 다시 fine-tuning 하여 학습
Transfer learning
일반적인 전이학습으로, pretrained 모델로 weight parameter 초기화 후 해당값을 시작점으로 하여 재학습
그냥 각 모델들을 개별 task에서 from scratch로 학습
처음부터 모델을 학습시키는 방법
Main contributions
더 나은 성능의 imageNet pretrained model을 사용하는것이 linear classification의 transfer learning에서 더 나은 feature extractor의 feature map을 만들어내며(r=0.99), 전체 네트워크가 fine-tuning 되었을 때 더 나은 성능을 보임(r=0.96)
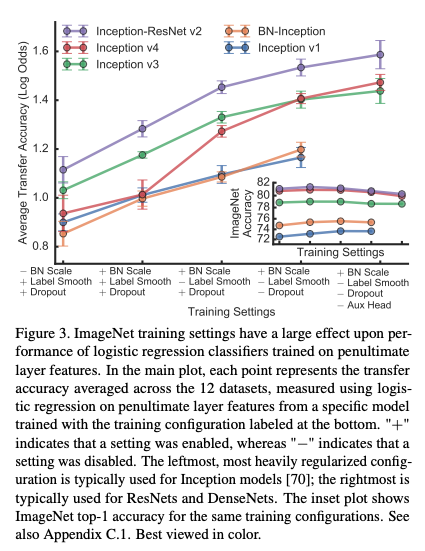
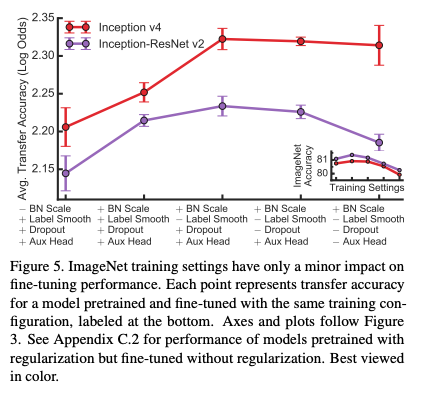
ImageNet task에서 모델의 성능을 향상시키는 regularizer들은 feature extractor의 출력 feature map의 관점에서 transfer learning에 오히려 방해가 됨
즉, transfer learning에서는 regularizer들을 사용하지 않는것이 성능이 더 좋았음
ImaegNet에서 성능이 좋은 모델일수록 다른 task에서도 비슷하게 성능이 더 좋았음
Statistical methods
서로 다른 난이도를 가진 여러 데이터 집합을 통해 각 모델의 성능의 상관관계를 제대로 측정하는것은 매우 어려운 일
따라서 단순하게 성능이 몇% 올랐는지를 확인하는 방식에는 문제가 있음
예를 들어 현재 정확도가 50%일때와 정확도가 99%일때, 성능을 1%향상시키는 것은 서로 다른 의미를 가짐
논문에서는 log-odd를 사용해서 변환된 성능 측정 방식을 사용함
Logit 변환은 비율 데이터 분석에서 가장 흔하게 사용되는 계산방식
사용되는 스케일이 log단위로 변경되기에 갑싱 변화량 $\Delta$ 는 $exp$ 의 비율로 적용되는것을 알 수 있음
Error bar도 Morey가 제안한 방법으로 적당히 잘 구성함(논문 참고)
이제 ImageNet의 정확도와 log-transformed 정확도의 상관 관계를 측정
자세한 내용은 논문의 appendix 참고
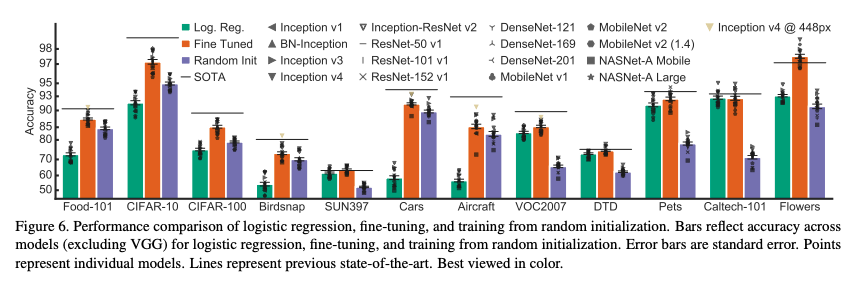
실험 결과
16개의 모델로 ImageNet(ILSVRC2012) validation set의 top-1 accuracy 비교
각 모델들은 71.6~80.8%의 정확도 성능을 보임
공평한 비교를 위해 모든 모델은 직접 재학습을 함
여기서 BN scale parameter, label smoothing, dropout auxiliary head 등은 나누어 확인
논문의 appendix A.3에 더 자세히 기술되어 있음
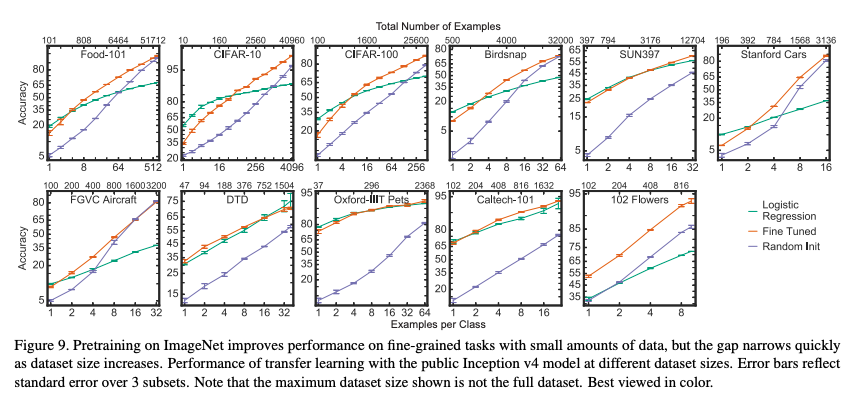
총 12개의 classification dataset을 실험
데이터셋의 training set size는 2,040개부터 75,750개까지 다양함 (Appendix H 참조)

 Seongkyun Han's blog
Seongkyun Han's blog