
 Seongkyun Han's blog
Seongkyun Han's blog
CH9. 우선순위 큐 (Priority Queue) 1 (우선순위 큐의 이해)
06 Aug 2019 | data structure 자료구조CH9. 우선순위 큐 (Priority Queue) 1 (우선순위 큐의 이해)
- 기존에 공부했던 큐의 연장선이 아님
- 적절한 비교가 아님
- 기존의 큐는 반드시 선입선출 되는 꼴
- Chapter 8의 이진트리의 연장선상에서 보는게 옳음
- 선형 자료구조의 큐와 우선순위 큐는 완전히 다름! (비교하기 애매함)
- 우선순위 큐는 비선형 자료구조
CH9-1. 우선순위 큐의 이해
- 내용 자체는 어렵지 않음
- 기존의 선형 자료구조의 큐
- 선입 선출
- 먼저 들어온 자료가 먼저 출력됨
- 우선순위 큐
- 큐와 구조만 동일
- 입구 출구가 구분되어 있어서 큐라고 불림
- 저장되는 데이터의 우선순위를 정하고, 그 우선순위에 따라 데이터가 저장되어 그 순서대로 데이터가 출력됨
- 예를 들어
- 중요도가 A>B>C 인 자료가 우선순위 큐에 C, A, B 순으로 저장될 경우?
- 저장시에 자동 정렬되어 중요도 순으로 저장이 됨
- 출력은 중요도 순인 A - B - C 순으로 출력됨
- 중요도가 A>B>C 인 자료가 우선순위 큐에 C, A, B 순으로 저장될 경우?
우선순위 큐와 우선순위의 이해

- 일반 큐와 우선순위 큐는 이름만 같지 완전히 다른 구조를 가짐
- 우선순위 큐는 들어간 순서에 상관없이 우선순위를 근거로 dequeue 연산이 진행됨
- 우선순위의 근거는 활용에 따라 프로그래머가 직접 정할 수 있음
우선순위 큐의 구현 방법

- 우선순위 큐의 구현 방법
- 배열을 기반으로 구현
- 연결 리스트를 기반으로 구현
- 힙을 이용하여 구현
- 위 구현 방법 중 배열과 연결리스트의 구현 방법은 쉬움
- 하지만 두 방법은 치명적인 단점이 존재
- 배열 기반으로 우선순위 큐가 구현 될 경우
- 저장될 data가 많아 질 경우 매우 불리해짐
- 새로 저장 될 데이터를 중요도에 근거해 일일히 전체 비교를 거쳐 알맞은 자리를 찾은 후
- 알맞은 자리에 자료를 넣기 위해 전체 자료를 밀어내야 함
- 자료가 참조되어 삭제 될 경우 빈 자리를 메꾸기 위해 뒤의 모든 자료를 당겨야 함
- 저장될 data가 많아 질 경우 매우 불리해짐
- 연결 리스트 기반으로 우선순위 큐가 구현 될 경우
- 저장될 data가 많아 질 경우 불리함
- 배열과 다르게 이동은 필요 없지만, 노드간의 연결을 타고 모든 노드에 접근하여(주소) 비교연산을 해야 함
- 비교 연산시의 비용이 매우 큼
- 저장될 data가 많아 질 경우 불리함
- 결과적으로 배열/연결리스트 기반 구현은 쉽지만 동작이 굉장히 비효율적
- 힙을 이용한 우선순위 큐의 구현이 가장 효율적으로
힙 (Heap) 의 소개
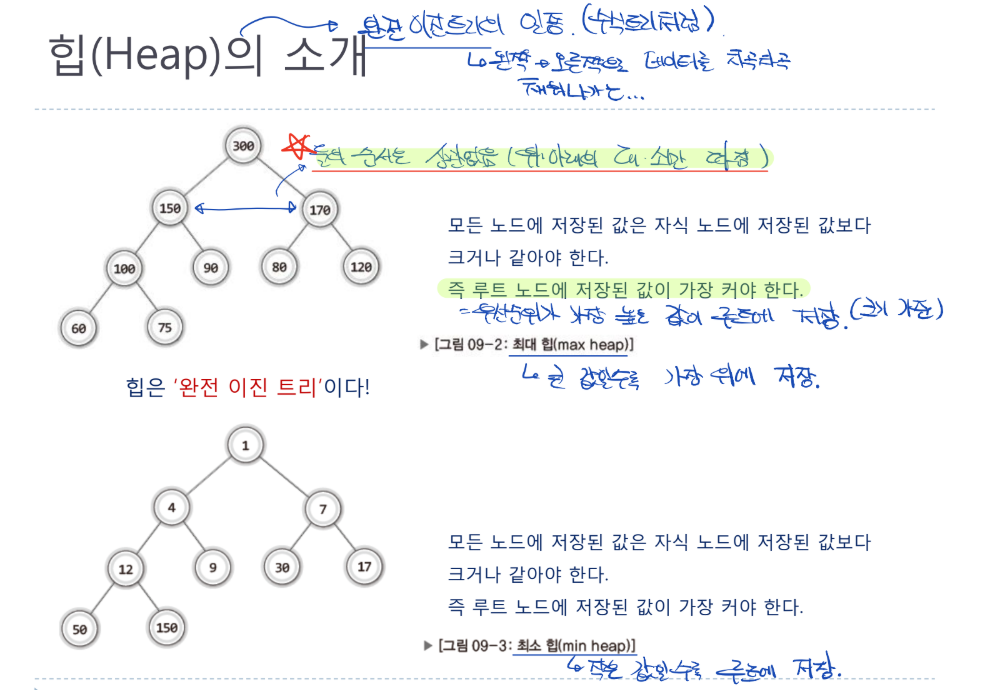
- 완전 이진트리의 일종 (수식트리처럼)
- 완전이진트리: 왼쪽에서 오른쪽으로 데티러르 차곡차곡 채워나가는 꼴
- 최대 힙에서, 중요도 순서는 상 하 관계만 따짐
- 좌 우 관계는 상관없음.
- 즉, 우선순위가 가장 높은 값이 루트 노드쪽에 저장 되어야 함
- 모든 노드에 저장된 값은 자식 노드에 저장된 값보다 크거나 같아야 함
- 최소 힙은 최대 힙과 반대로 작은 값일수록 루트 노드쪽에 저장됨
- 힙은 우선순위 큐의 구현에 가장 효율적인 방법임