
 Seongkyun Han's blog
Seongkyun Han's blog
Semantic Segmentation (FCN, Fully Convolutional Network)
08 Dec 2019 | CNN Deep learningSemantic Segmentation (FCN, Fully Convolutional Network)
- 참고
- https://medium.com/hyunjulie/1%ED%8E%B8-semantic-segmentation-%EC%B2%AB%EA%B1%B8%EC%9D%8C-4180367ec9cb
- https://medium.com/nanonets/how-to-do-image-segmentation-using-deep-learning-c673cc5862ef
- https://www.youtube.com/watch?v=nDPWywWRIRo&feature=youtu.be
Introduction
- Fully Convolutional Network(FCN)에 대한 내용은 아래에서 다룸


- 사진을 보고 분류하는 것이 아니라, 장면을 완벽히 이해해야 하는 높은 수준의 문제임
- 자율주행 등 적용 가능 분야가 매우 큼
- 실제 구글 Pixel 2와 Pixel 2X 스마트폰에선 구글의 DeepLab V3+ 논문의 방법을 이용해 Portrait Mode를 구현함
- 아이폰의 Portrait Mode와 유사하지만, 2개의 스테레오 카메라를 이용하는 아이폰 X의 방법과는 다르게 단안 카메라의 영상을 이용해 딥러닝을 적용시켜 동일한 결과를 얻어냄

- 즉, Semantic Segmentation은 영상 내 모든 픽셀의 레이블을 예측하는 task를 의미함
- FCN, SegNet, DeepLab 등
-
이미지에 있는 모든 픽셀에 대한 예측이므로 dense prediction이라고도 불림
- Semantic Segmentation은 같은 class의 instance를 구별하지 않음
- 즉, 아래의 짱구 사진처럼 같은 class에 속하는 사람 object 4개를 따로 구분하지 않음

- Semantic segmentation에선 해당 픽셀 자체가 어떤 class에 속하는지에만 관심이 있음
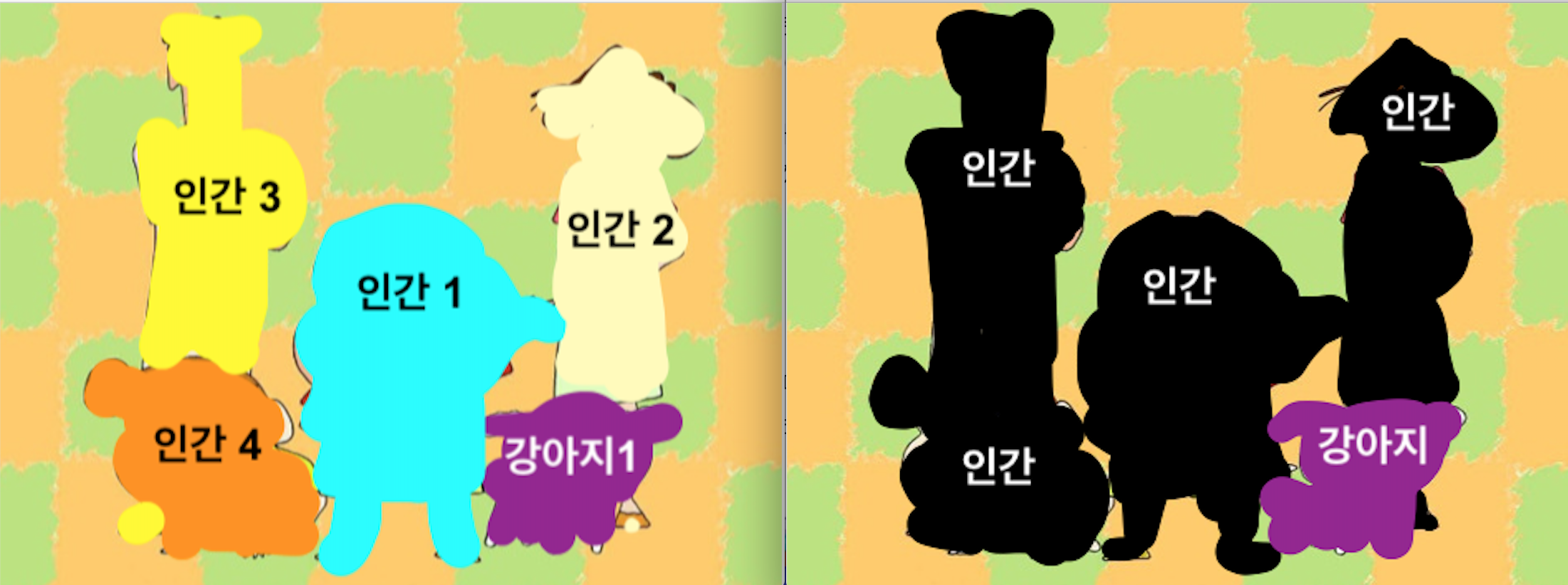
- 위의 좌측 사진처럼 각각 객체의 종류와 어떤 객체인지에 대한 분류가 아니라
- 이처럼 instance를 구별하는 task는 Instance Segmentation이라고 불림
-
위의 우측 사진처럼 각각 객체의 종류의 분류만을 목적으로 함
- MS COCO detection challenge는 80개의 class, PASCAL VOC challenge는 21개의 class를 갖고 있음
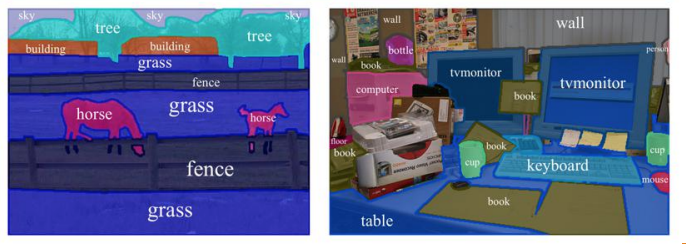
Semantic Segmentation 이해하기
- Input: RGB color 이미지 ($height\times width\times 3$) 또는 흑백 이미지
- Output: 각 픽셀별 어느 class에 속하는지를 나타내는 레이블을 나타낸 Segmentation Map
- 아래에선 단순화된 segmentation map 예시를 확인 가능하며, 실제론 입력과 동일한 resolution의 map을 가짐
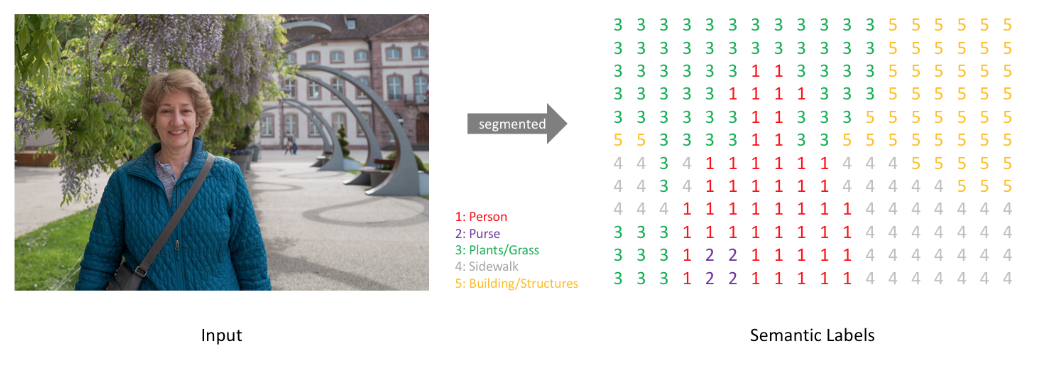
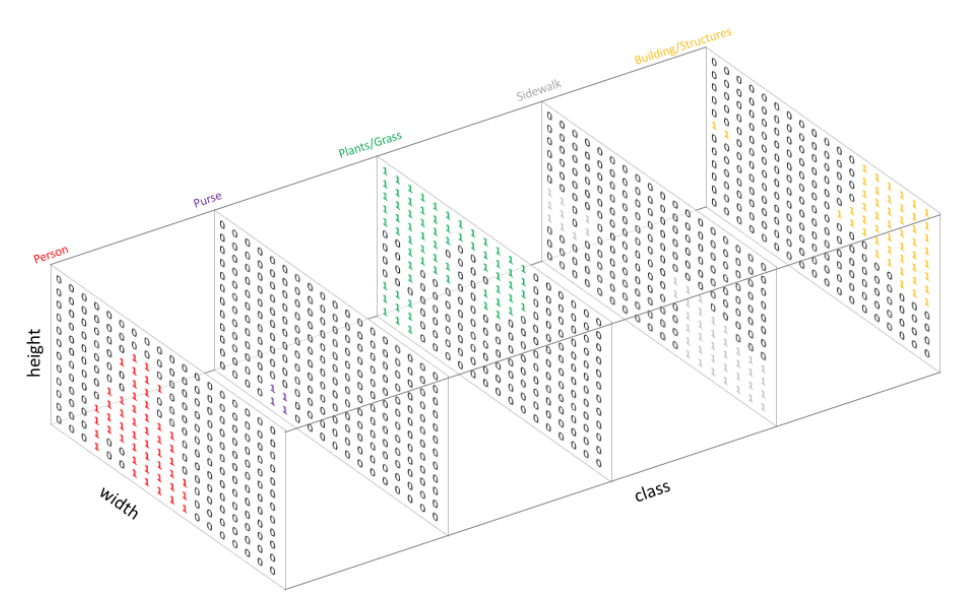
- One-Hot encoding으로 각 class에 대해 출력 채널을 만들어서 segmentation map을 생성함
- Class의 개수 만큼 만들어진 채널을
argmax를 통해 위에 있는 이미지처럼 하나의 출력물을 내놓음argmax? channel 방향으로 가장 큰 값의 index를 출력- ex. x = [0, 1, 4, 3] 일 때, argmax(x)의 결과는 2
- 직관적 이해는 아래의 사진 참고
다양한 Semantic Segmentation 방법들
- AlexNet, VGG등 classification에서 자주 쓰이는 깊은 신경망들은 Semantic Segmentation을 하는데 적합하지 않음
- 이러한 모델들은 파라미터의 개수와 차원(depth)을 줄이는 layer들을 갖고 있어서 자세한 위치정보를 잃게 되기 때문
- 또한 보통 마지막에 쓰이는 Fully Connected Layer에 의해서 위치에 대한 정보를 잃게 됨
- 만약 공간/위치에 대한 정보를 잃지 않기 위해 Pooling과 Fully Connected Layer을 없애고, stride가 1이고 padding도 일정한 convolution을 적용시킬 수 있음
- 하지만 이렇게 될 경우 input의 차원(depth)은 보존 할 수 있겠지만, 파라미터의 개수가 너무 많아져서 메모리 문제나 계산하는데 비용이 너무 많이 들어서 현실적으로 불가능함
- 이 문제의 중간점을 찾기 위해서 보통 Semantic Segmentation 모델들은 일반적으로 Down-sampling & Up-sampling의 형태를 가짐
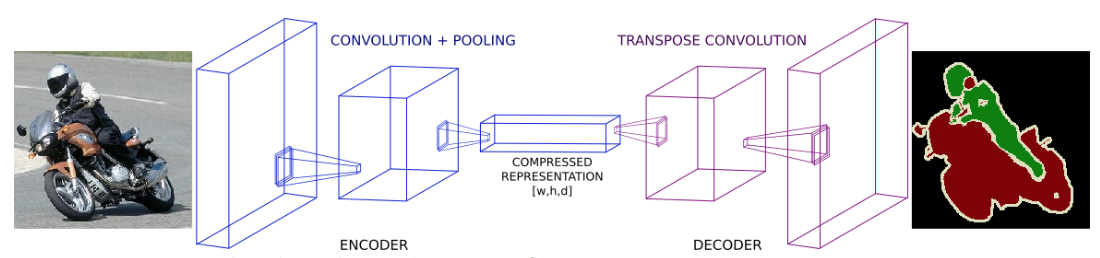
Down-sampling
- 주 목적은 차원을 줄여서 적은 메모리로 deeper CNN의 구조적 이점을 취하기 위함임
- 일반적으로 stride를 2 이상으로 하는 convolution을 사용하거나 pooling을 사용함
- 이 과정에서 semantic feature의 정보를 잃게 됨
- 마지막에 Fully-Connected Layer (FC Layer) 대신 마지막 레이어까지 Conv layer로 구성된 Fully Convolutional Network (FCN)를 사용함
- FCN모델에서 이와 같은 방법을 제시한 이후 나온 대부분의 모델들이 FC layer 대신 이러한 구조를 갖게 됨
- 파라미터나 연산의 효율성 측면에서 이점이 큼
- FCN모델에서 이와 같은 방법을 제시한 이후 나온 대부분의 모델들이 FC layer 대신 이러한 구조를 갖게 됨
Up-sampling
- Down-sampling을 통해서 얻어진 output feature map의 차원을 늘려서 input과 같은 차원으로 만들어주는 과정
- Depth 방향으로는 전체 클래스 갯수만큼, spatial 방향으로는 input resolution만큼
- 주로 Strided Transpose Convolution을 사용함
- 논문들에서는 Downsampling이라고 하는 부분을 인코더(Encoder), Upsampling 하는 과정을 디코더(Decoder) 라고 칭함
- GAN에서 쓰이는 모델과 비슷한 형태 및 이름을 갖고 있음
-
인코더를 통해서 입력받은 이미지의 정보를 압축된 벡터의 형태로 표현하고, 디코더를 통해서 원하는 결과물의 크기로 만들어냄
- 이러한 인코더-디코더 형태를 가진 유명한 모델들로는 FCN, SegNet, UNet등이 있음
- Shortcut connection을 어떻게 활용하느냐에 따라서 몇가지 모델들이 존재함
- e.g. pooling indices를 활용한 SegNet, feature map을 복사해 합치는 U-Net 등
- Shortcut connection을 어떻게 활용하느냐에 따라서 몇가지 모델들이 존재함
- 이러한 형태의 모델에 대한 연구를 불지핀(?) 역할을 한 FCN에 대해 조금 더 자세히 알아보면 아래와 같음
Fully Convolutional Network for Semantic Segmentation (FCN)
- 2014년 Long et al.의 유명한 논문인 Fully Convolutional Network가 나온 후 FC layer가 없는 CNN이 통용되기 시작함
- 이로 인해 어떤 크기의 이미지로도 segmentation map을 만들 수 있게 되었음
- 당시 SOTA였던 Patch Classification보다 훨씬 빠르게 결과를 낼 수 있었음
- 이후 나온 Semantic Segmentation 방법론은 거의 대부분 FCN을 기반으로 했다고 할 정도로 큰 임팩트를 줌
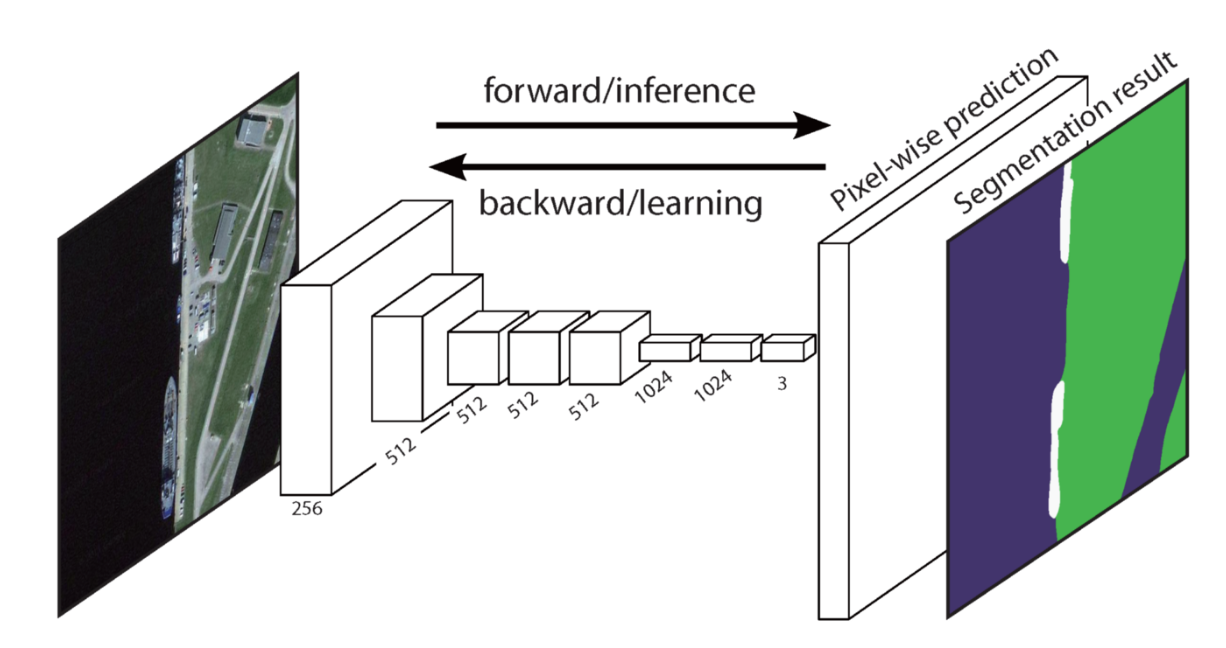
FCN의 특징
- VGG16을 backbone으로 이용해 Transfer learning
- VGG16의 마지막 레이어인 FC layer들을 1x1 convolution layer로 바꿈
- 이 부분에서 이 모델의 이름인 Fully Convolutional 이 나옴
- 이 과정을 통해 낮은 해상도의 Class Presence Heat Map을 얻게 됨
- FC layer를 없앤 이유?
- 네트워크 마지막 부분에서 FC layer를 거치고 나면 위치 정보가 사라지는 문제가 있기 때문임
- Segmentation은 위치정보가 핵심이기에 이는 심각한 문제임
- Transposed Convolution을 통해서 위에서 생성된 낮은 해상도의 heat map(feature map)을 upsampling해서 input과 같은 크기의 map을 만듦
- Upsampling 시 VGG16의 low-level layer에서 만들어진 feature map과 residual connection 형성
- Pixel by pixel 더하기
- 여러 단의 convolution layer중 후반부에 있는 feature map을 결합하면 중요한 semantic 정보를 얻을 수 있음
-
각 convolution block이 끝난 후 skip connection을 통해서 이전에 pooled된 특징들을 다시한번 합쳐줌
- 하지만, FCN 모델은 정해진 fixed Receptive Field(RF)를 사용함
- 이로 인해 작은 물체들은 무시되거나 오탐되는 경우가 있거나
- 큰 물체를 작은 물체로 인식하거나 일정하지 않은 결과가 나올 수 있음
- 또한 pooling을 거치면서 해상도가 줄어든 것을 upsampling을 통해 spatial 방향의 복원을 수행함
- 이로인해 결과가 정확하지 않다는 문제점을 갖고 있음

Deeplab V3 (Dilated/Atrous Convolution을 사용하는 방법)
- Deeplab이 제시하는 방법으로, 신호가 소멸되는 것을 제어하고 다양한 scale의 feature를 학습가능하게 하는 방법을 제시
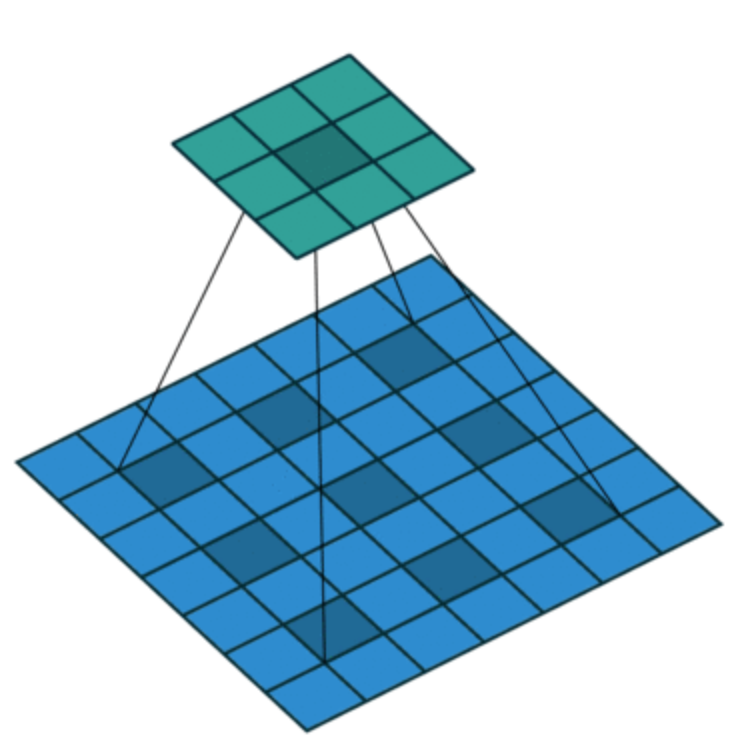
- Atrous Convolution은 dilation rate라는 새로운 변수를 활용함 (참고 1, 참고 2)
- 일반적인 convolution은 dilation rate = 1 인 경우에 해당함
- 3x3 크기의 커널이 2의 dilation rate를 갖는다면 실제로는 5x5의 RF와 동일한 spatial 범위를 커버함
- 이러한 방법은 동일한 연산 비용으로 보다 넓은 RF를 커버 할 수 있게 함
- Deeplab V3은 ImageNet pretrained ResNet을 backbone(feature extractor)으로 사용함
- ResNet의 마지막 block에서는 여러가지의 dilation rate를 사용한 Atrous Convolution을 사용해서 다양한 RF로 생성된 multi-scale feature들을 뽑아낼 수 있도록 함
- 이전 Deeplab 버전에서 소개되었던 Atrous Spatial Pyramid Pooling (ASPP, 참고) 을 사용함
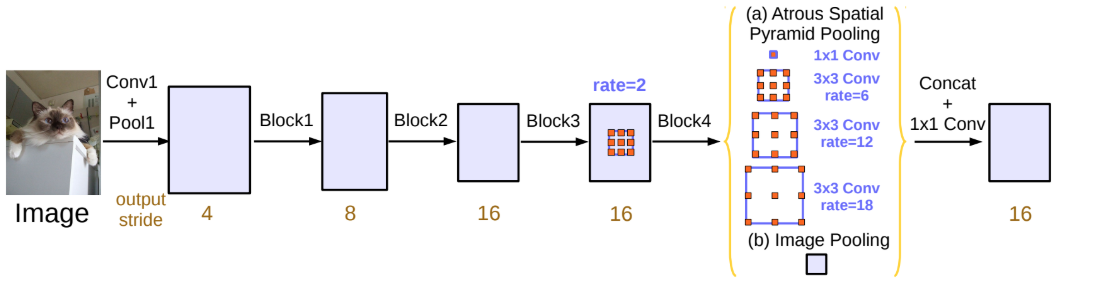
- Deeplab V3은 새로운 아이디어라기보단 좋은 성능을 보였던 모델들의 방법들과 특징들을 섞어서 만든 모델
- 다양한 dilation rate를 가진 커널을 병렬적으로 해 multi-branch 구조를 갖도록 한 convolution임
Conclusion
- 지금까지 Semantic Segmentation과 접근방법에 대해 알아봄
- 다음엔 DeepLab V3 논문을 조금 더 자세히 봐야할듯 (참고)