CH9. 우선순위 큐 (Priority Queue) 2-1 (힙의 구현과 우선순위 큐의 완성)
07 Aug 2019
|
data structure
자료구조
CH9-2. 힙의 구현과 우선순위 큐의 완성
- 힙을 이용해 우선순위 큐를 구현
- 힙은 우선순위 큐의 구현에 사용되는 도구
- 우선순위 큐와 힙은 어느정도 맥락이 상통하지만, 엄연히 다름
- 힙의 데이터 저장 및 삭제가 가장 관건
- 힙은 우선순위 큐의 구현에 가장 효율적인 자료구조형
힙에서의 데이터 저장과정
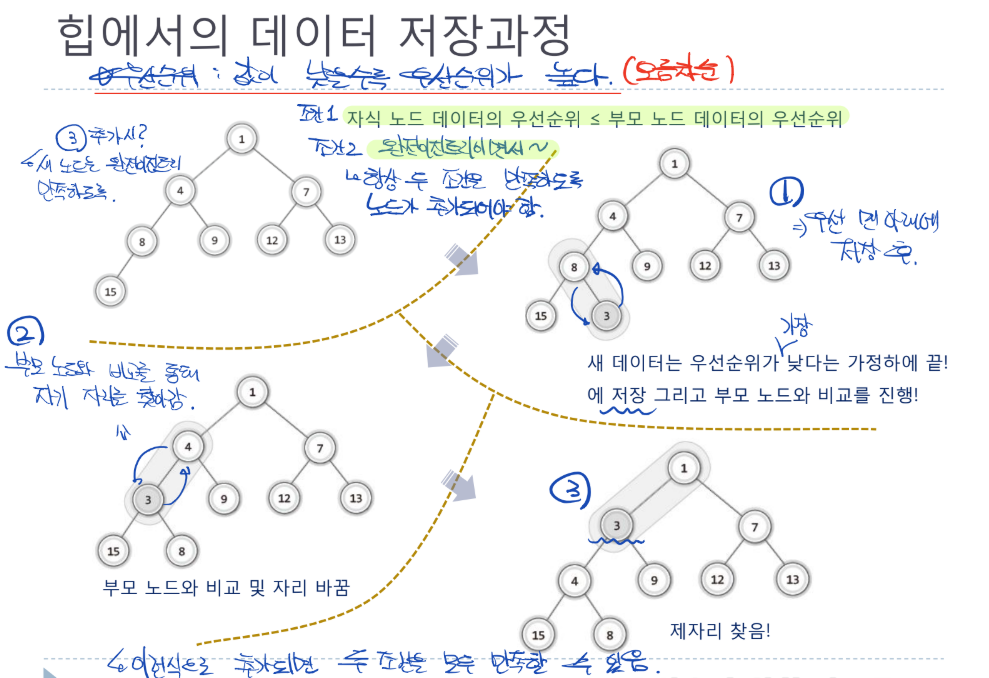
- 우선순위는 값이 낮을수록 우선순위가 높다고 가정 (오름차순)
- 새로운 노드의 추가에는 반드시 아래의 두 조건이 만족되어야 함
- 부모 노드 데이터의 우선순위는 항상 자식 노드 데이터의 우선순위보다 같거나 높아야 함
- 트리의 형태는 항상 완전이진트리를 만족해야 함
- 새로운 노드의 추가
- 우선 새 노드가 들어올 경우 맨 아래에 저장
- 다음으로, 저장된 위치 상단의 부모 노드와 비교를 통해 자기 자리를 찾아감
- 부모 노드보다 중요도가 떨어질 경우, 해당 자리에 저장됨
- 이런 방식으로 추가되면 위의 두 조건을 모두 만족하며 새 데이터를 저장 할 수 있음
- 단, 우선 순위 정렬을 봤을 때 같은 층에는 왼쪽엔 작은 수(우선순위가 높은 수)가, 오른쪽으로 갈수록 큰 수 (우선순위가 낮은 수)가 저장되어야 함
힙에서의 데이터 삭제과정
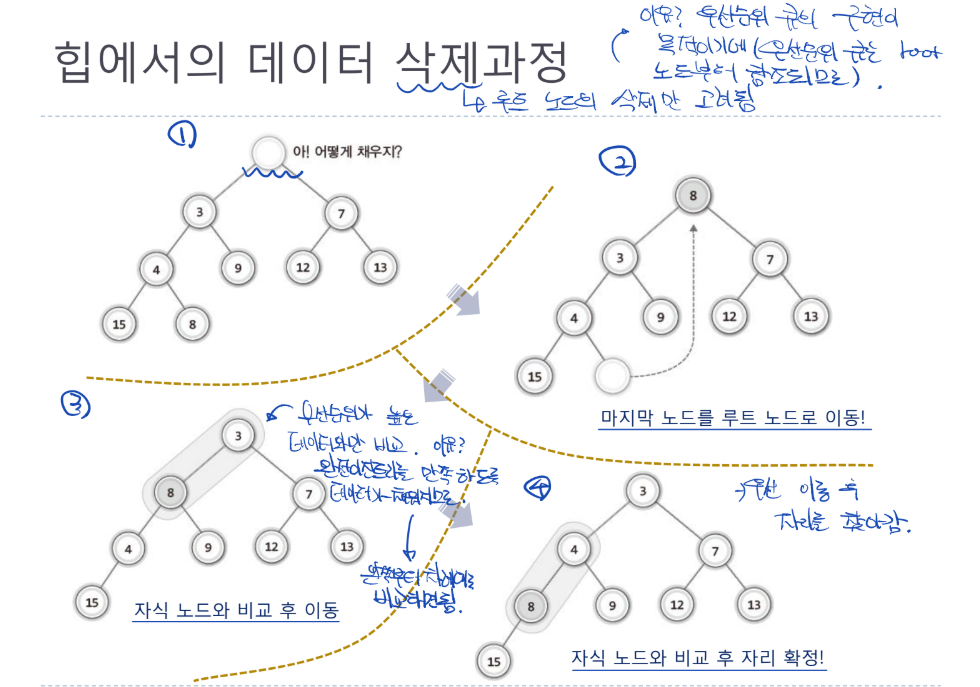
- 루트 노드의 삭제만 고려됨
- 우선순위 큐의 구현이 목적이기 때문에
- 우선순위 큐는 우선순위가 가장 높은 루트 노드의 값만 한번에 하나씩 참조되므로
- 기존 노드의 삭제는 반드시 아래의 과정을 따름
- 우선 루트 노드가 참조되어 사라짐
- 참조된 루트노드의 빈자리는 트리의 가장 마지막 노드의 데이터가 이동되어 채워짐
- 루트 노드에 위치한 가장 마지막 노드의 데이터는 우선순위 비교를 통해 자신의 자리로 찾아감
- 자신의 자리가 찾아 진 경우 해당 위치에 데이터가 최종적으로 저장됨
- 루트 노드에 위치한 데이터의 비교는 우선순위 비교를 통해 우선순위가 높은 데이터와만 1대1로 비교가 됨
- 애초에 힙에 데이터 저장 시 같은 층에서 맨 왼쪽이 가장 우선순위가 높은 데이터가 저장되므로 맨 왼쪽 노드와의 비교만 수행하면 됨
삽입과 삭제의 과정에서 보인 성능의 평가

- 배열 및 연결리스트 기반의 데이터 삽입/삭제 시간 복잡도는 worst case에서 O(n)임
- 이는 n개 데이터에 대한 참조 및 비교를 수행해야 하기 때문임
- 힙은 $O(\log_{2}{n})$ 의 시간 복잡도를 보임
- 이는 heap의 각 단계가 2의 최대 2의 배수개 만큼의 데이터를 저장 할 수 있기 때문
- 새로운 데이터가 저장 될 경우, 층수 만큼의 참조 및 비교 연산만을 수행하면 되기 때문임
- 만약 15번째까지 데이터가 저장되어있고 16번째 데이터가 들어오는 경우
- 배열 및 연결리스트는 참조 및 비교가 최대 16번 수행되어야 함(worst case)
- 힙은 각 층별 1, 2, 4, 8개로 총 15개의 데이터에 대해 층별 비교만 수행하면 되므로 최대 4번의 참조 및 비교만 수행되면 됨
배열을 기반으로 힙을 구현하는데 필요한 지식들
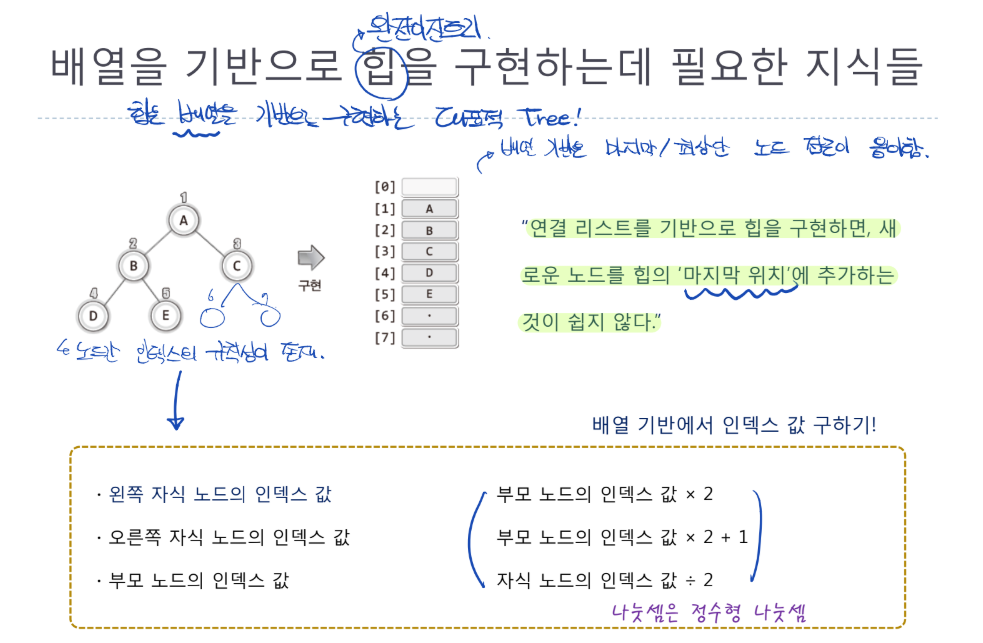
- 힙은 배열을 기반으로 구현하는 대표적인 이진 트리 구조임
- 연결 리스트 기반으로 힙을 구현할 경우 새 노드를 힙의 마지막 노드에 위치시키는것이 어려움
- 또한 연결리스트 기반은 참조의 과정도 복잡함 (루트부터 타고 넘어가야 하므로)
- 배열 기반의 이진트리를 이용할 경우, 각 노드의 배열 인덱스가 갖는 규칙성을 이용하여 쉽게 자식/부모간의 인덱스 상관관계를 찾을 수 있음
- 각 관계는 위 사진 참고
- 2번 인덱스 기준 왼쪽 자식은 4, 오른쪽 자식은 5이므로 관계 성립
- 5번 인덱스 기준 부모는 5//2=2 이므로 관계 성립
- 무엇보다 배열 기반의 이진트리는 최상단/마지막 노드의 접근이 용이함
- 참고로 배열 기반의 이진트리는 앞 챕터에서 설명된것처럼 0번 인덱싱을 사용하지 않음(안정성)
원리 이해 중심의 힙 구현: 헤더파일의 소개

- 위에서 정의된 힙 헤더는 우선순위 큐에 최적화되어 구현됨
- 각각 heap에 저장되는 data의 구조체와 heap의 구조체가 차례대로 정의
- 여기서 데이터와 우선순위 정보
pr을 구분하여 저장함
HDelete 함수도 우선순위 큐에 최적화되어 구현됨
원리 이해 중심의 힙 구현: 숙지할 내용

- 힙은 완전 이진 트리
- 힙의 구현은 배열을 기반으로 하며 0번 인덱스는 사용하지 않음
- 힙에 저장된 노드의 개수와 마지막 노드 인덱스는 일치
- 이는 index가 1부터 시작되기 때문임
- 새로 추가될 노드는 마지막 index + 1로 쉽게 정의 가능
- 노드 고유번호가 노드에 저장되는 인덱스 값
- 우선순위를 나타내는 정수 값이 작을수록 높은 우선순위를 나타낸다고 가정
- 무엇보다 배열을 사용하므로 첫번째/마지막번째 노드의 인덱스 값을 쉽게 얻을 수 있음
원리 이해 중심의 힙 구현: 초기화와 Helper

- 각 helper function은 앞에서 정의된 부모 노드간의 인덱스 관계를 이용하여 각 인덱스 값을 반환함
원리 이해 중심의 힙 구현: Helper

- 위 함수는 우선순위가 높은 자식의 인덱스 값을 반환함
- 우선순위 숫자
pr이 작을수록 우선순위가 높게 정의됨
- 우선, 자식 노드가 존재하지 않는다면 0을 반환
numOfData는 마지막 노드의 인덱스이므로, 자식 노드의 인덱스가 이 값보다 크다면 존재하지 않는 자식 노드임
- 만약, 자식 노드가 왼쪽 자식 노드 하나만 존재한다면
- 완전 이진트리 형식으로 데이터가 저장되므로
numOfData값은 자식 노드가 왼쪽 자식 노드 하나만 존재할경우 항상 왼쪽 자식 노드의 인덱스와 동일하게 됨
- 자식 노드가 양쪽에 존재할 경우
- 오른쪽 자식 노드의 우선순위가 높으면 오른쪽 자식 노드의 인덱스 값을
- 아니라면 왼쪽 자식노드의 인덱스 값을 반환

 Seongkyun Han's blog
Seongkyun Han's blog