
 Seongkyun Han's blog
Seongkyun Han's blog
Dont't decay the learning rate, increase the batch size
04 Jan 2019 | Deep learningDont’t decay the learning rate, increase the batch size
Original paper: https://arxiv.org/abs/1711.00489
Authors: Samuel L. Smith, Pieter-Jan Kindermans, Chris Ying, Quoc V. Le (Google Brain)
Practical view of Generalization
- 기존 연구들은 어떻게 해야 generalization이 되는지를 많이 제안했었음.
- Imagenet challenge에서 제안된 여러 구조들이 generalization이 잘 되는 구조와 hyper parameter setting들을 전부 다 포함
- Generalization 성능이 좋은 구조와 hyper parameter들을 유지하면서 응용하려면?
- 본 논문에서는 generalization에 크게 영향을 끼치는 learning rate, batch size에 대해 다룸
Batch size in the Deep learning
- Batch size가 크면 연산이 효율적(빠른 학습 가능)
- Batch size가 작으면 generalization이 잘 됨
- 연산 효율을 좋게 하면서 generalization을 잘 시키는 방법에 대해 본 논문에서는 연구
Batch size and Generalization
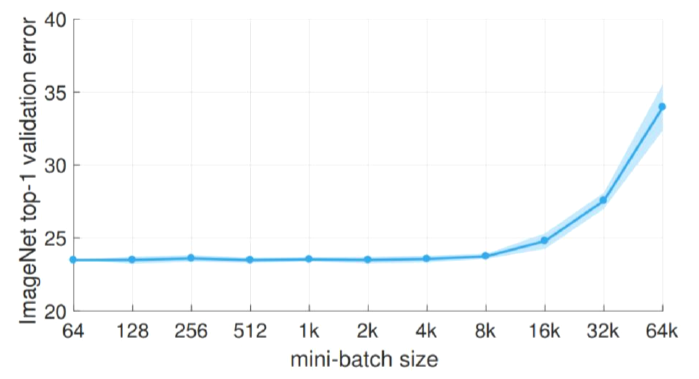
- Imagenet을 1시간 안에 학습 시키는 논문
- P.Goyal et al. (2017), “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”
- 위 논문에서 주요하게 사용한게 Linear scaling rule
- Batch size 크기에 비례해서 learning rate를 조절해야한다는 rule
- Batch size가 2배가 되면, learning rate도 2배가 되어야 함
Contribution
- Learning rate decaying 하는게 simulated onnealing하는것과 비슷함.
- Simulated annealning 이론을 기반으로 learning rate decaying에 대해 설명.
- Linear scaling rule / learning rate를 decaying 하지말고, batch size를 늘리자
- SGD momentum coefficient 또한 batch size 조정하는 rule에 포함 시킬 수 있음
위의 방법들을 사용하여 2500번의 parameter update로 ImageNet dataset을 traning했음(Inception-Resnet-V2)
Noted items
- Batch size와 generalization의 관계
- Sharp한 minimum이 generalization에 나쁘다고 표현됨
- 그렇지 않은(broad) minimum은 generalization이 잘 된다고 봄
- SGD가 batch size가 작으면 SGD가 갖는 noise 성분이 커지게 됨
- 따라서 자연스럽게 broad한 minimum을 갖게 됨
- 즉, Sharp minimum -> bad to generalization / Broad minimum -> good to generalization
- SGD와 batch size의 관계에서 보는 generalization의 영향
- SGD W/O noise: $\Theta_{t+1} \leftarrow \Theta_{t} + \alpha_{t}\nabla\Theta$
- SGD W/ noise: $\Theta_{t+1} \leftarrow \Theta_{t} + \alpha_{t}(\nabla\Theta + N(0, \sigma^2_t))$
- Noise term: $N(0, \sigma^2_t)$ -> Noise가 minima를 general하게 만들어줌
- 작은 batch 사이즈
- Weight parameter 업데이트 횟수가 많음
- SGD가 많은 noise component를 가짐
- 더 broad한 minima를 가짐
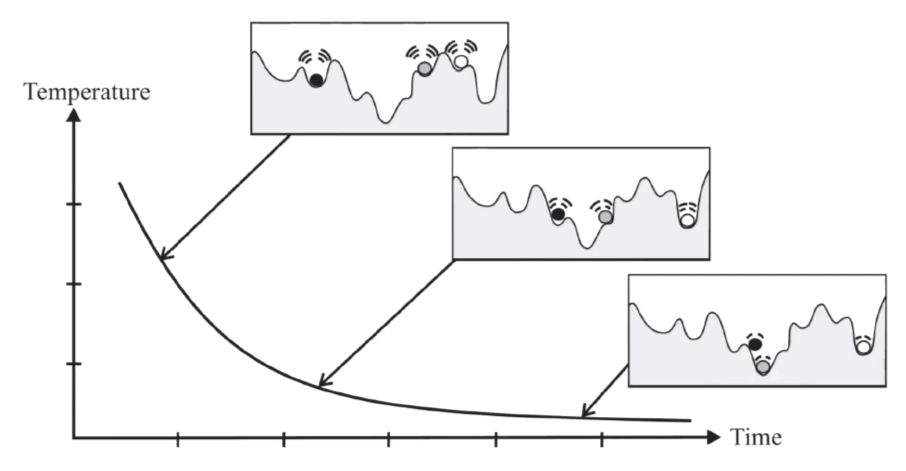
- Simulated annealing
- Optimum을 찾는데 gradient를 이용해서 하는것이 아니고, Random하게 움직여서 값이 좋아지면 그 방향으로 가는 optimization
- Gradient descent와 같이 local minima에 빠지는 문제를 해결하기 위해 temperature라는 option를 이용하여 조금 움직여서 결과가 좋아지지 않더라도 temperature option에 의해 그 결과를 accept함.
- 사진에서, 움직였는데 공이 조금 더 위로 올라가도 그냥 올라가는것을 의미
- SGD에서 noise가 하는 역활과 같이 temperature가 local minima를 빠져나가게 함
- 시간 갈수록 SGD에서 learning rate를 decaying하듯이 temperature를 조절하여 global minima에 도달할 수 있도록 함
- Momentum
- Gradient descent 최적화 알고리즘의 한 종류
- 종류로는 momentum, Nestrov momentum이 많이 쓰임
- 모멘텀 알고리즘은 누적된 과거 gradient가 지향하고 있는 어떤 방향을 현재의 gradient에 보정하려는 방식
- 일종의 관성가속도 정도로 이해하면 쉬움
Stochastic gradient descent and Convex optimization
- Convergence conditions of SGD
- Convex surface(Convex loss function)에서 수렴하는 조건(SGD가 수렴하기 위한 조건)
- For fixed batch size
- 1에서, 수렴하기 위해서는 lr의 sum이 무한대
- 2에서, lr의 제곱의 모든 sum이 유한해야 함
- 직관적으로
- 1에서, 시작 point와 global optimum이 얼마나 멀든지 간에 다가갈 수 있어야 함
- 2에서, SGD가 noise가 있으니 그 noise에 의해 optimum 근처에서 진동 할 때, noise가 있음에도 수렴해야 할 조건
- Interpretation of SGD for various batch size
- 위의 논의를 다양한 batch size에 대해서도 확장
- $\frac{dC}{dw}$은 Cost function의 gradient, $\eta(t)$은 gradient를 의미
-
위 식에서 $\eta(t)$(SGD를 쓰기때문에 발생하는 noise)의 variance가 가 된다고 분석(mean = 0)
- Noise scale $g$
- $\epsilon$은 learning rate, $N$은 전체 traning data size, $B$는 batch size를 의미
- $g$를 수학적(stochastic differential equation)으로 풀어서 왼쪽의 관계가 나옴(과정은 다른논문)
- 결론적으로, SGD를 사용함으로써 생기는 variance가 위의 식에 비례
- 위의 식이 linear scaling rule을 의미
- 보통 $N»B$이므로, -1항은 무시 가능하여 아래의 식으로 근사화가 가능
- Batch size를 조절하면 똑같이 lr($\epsilon$)을 비례해서 키워줘야 하고, SGD로부터 발생한 noise(random fluctuation)가 동일(일정)하게 유지 될 수 있다(linear scaling rule)
- 이로부터 generalization이 유지가 된다고 생각 할 수 있음
- Random fluctuation이 generalization에 가장 영향을 크게 미침(일정하게 유지되어야 함)
- 실험적인 결과도 Random fluctuation이 일정하게 유지 될 때 가장 좋았음
- $g$의 식에서 -1을 무시하기 위해서는 batch size가 너무 많이 커지면 안됨
- $B\approx\frac{N}{10}$정도까지는 가능하지만, 더 커지면 -1항을 무시 할 수 없게 됨
Simulated annealing and the generalization gap
- Simulated annealing
- learning rate를 decaying하는 dynamics가 simulated annealing과 동일
- Lr을 decaying하는것과 같이 simulated annealing도 random flucuation을 줄임
- Simulated annealing이라는 개념을 가져와서 lr의 decaying을 정당화 시킴(lr decaying 하는것이 generalization에 좋다)
- Simulkated annealing이 random flucuation을 줄이듯, lr decaying하는것이 좋음
- Generalization gap -> batch size가 작으면 generalization이 잘 된다
- Large batch size보다 test 결과가 더 좋다
- SGD에 들어가는 noise가 sharp minima를 벗어나 generalization에 좋은 broad minima를 찾는데 도움이 됨
- Simulated annealing이 annealing을 천천히 하는것이 sharp minima에 converge하고, 급격히 하는게 broad minima를 찾는데 효과적
- 보통 lr 조절 시 exponential 하게 하지 않고, 유명한 논문들에서 30, 60, 90 epoch 등에서 1/10 수준으로 확 decaying하는것이 simulated annealing에서 정당화 시키는 내용
- Simulated annealing에서도 확확 annealing 하는게 더 broad한 minima를 찾는데 도움이 됨
The effective learning rate and the accumulation variable
- Noise scale of random fluctuation in the SGD with momentum dynamics
- 즉, momentum ($m$: momentum coefficient)함수 쓸 때 $g$는 위의 관계를 가짐
- 하지만, 실제로는 결과가 좋지 않게 나옴
- Problem analysis
- 이유: momentum이 처음에 0으로 초기화
- 즉, 0에 초반에 biased 되어 있게 되므로 weight update가 원래 계산보다 더 적게 수행됨
- $g=\approx\frac{\epsilon N}{B(1-m)}$이므로, $g$를 유지하면서 batch size($B$)를 키우려면 momentum ($m$)을 키워야 함
- Momentum을 높이면 weight update가 초반에 잘 되지 않는 문제 발생
- 그 해결책으로 Training epoch를 더 해야함
Experiment 환경
- Cifar-10 dataset
- 50,000 images for training
- $B_{max}=5120$ (by $N\gg B$, $1/10$ rule)
- 학습 시 batch size를 증가시키며 진행하다 $B_{max}$ 되면 lr을 decaying
- ImageNet dataset
- 1.28 million images
- $B_{max}=65536$
- Ghost batch normalization 사용
- Batch normalization 또한 batch size가 바뀜에 따라 noise의 양이 변하게 됨 (parameter update 횟수 변경에 의한 batch size 증가 시 전체 noise 감소)
- 따라서, 전체가 아닌 Sampled data에 대해서만 Statistics(variance, mean)을 계산하여 batch normalization을 수행
Simulated annealing in Wide ResNet
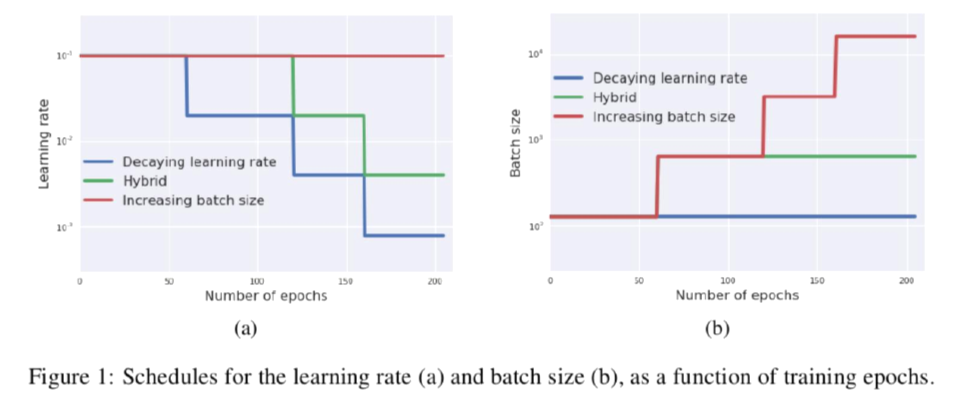
- Three scheduling strategies (Cifar-10 datset)
- Lr decay factor: 5, 3가지 Scheduling rule 사용
- 파란 선: 일반적인 방법
- 초록 선: 초반에는 Batch size 증가, 그다음엔 lr decaying
- 빨간 선: lr을 유지하면서 batch size를 5배씩 증가
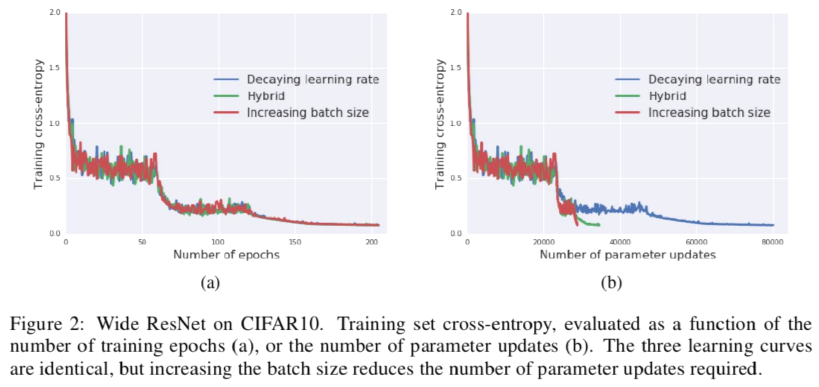
- Training loss curve
- Loss curve가 동일하다는것을 보여주려 함
- (a): Loss curves are identical
- (b): Increasing batch size strategy significantly reduces the number of parameter updates
- Batch size가 커지는 경우 parameter update 수는 줄어들어 더 빠른 학습이 가능
- Batch size를 조절하는 것이 random fluctuation에 끼치는 영향이 같으므로 generalization이 똑같이 잘 된다(Traning)
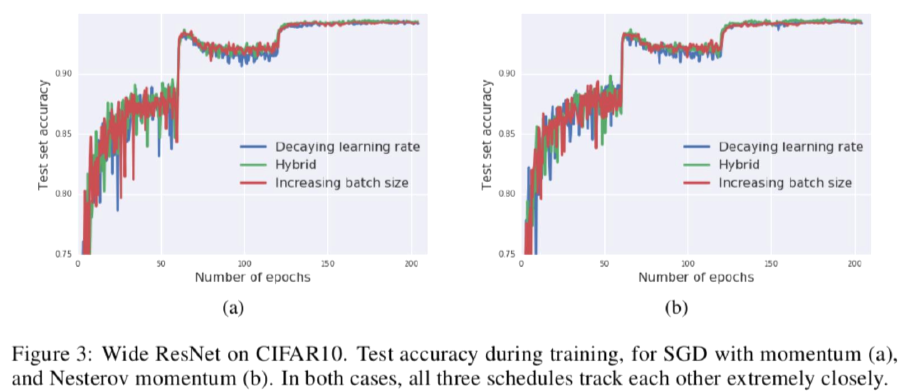
- Test loss curves A(Test set에 대한 accuracy)
- (a): SGD with momentum, (b): SGD with Nestrov momentum
- 다른 momentum을 사용하더라도 결과는 거의 동일한것을 알 수 있음
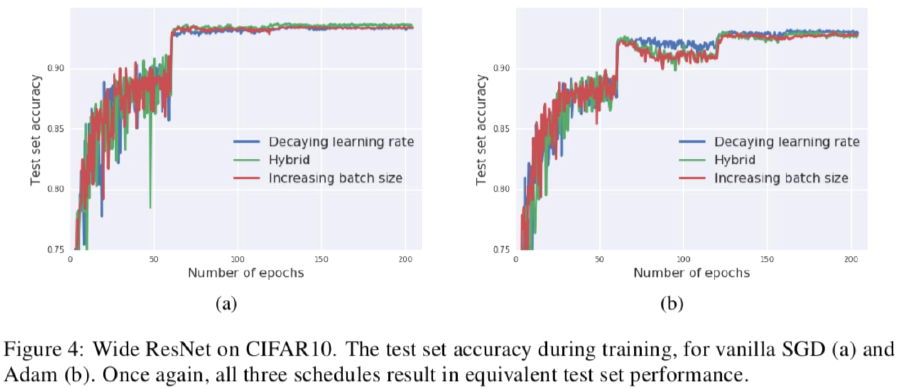
- Test loss curves B
- (a): Vanilla SGD, (b): Adam
- 결국 논문에서 제안하는 방법과 기존 방법의 차이에 대한 성능 변화가 적음
Increasing the effective learning rate
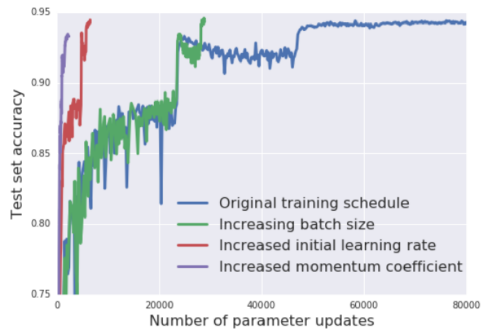
- Momentum coefficient를 변화시킨 실험 결과
- Default settings: initial LR 0.1, decay factor 5, momentum 0.9, batch size 128
- “Increasing batch size”: increasing batch size by a factor 5
- “Increased initial learning rate”: initial LR 0.5, initial batch size 640, increasing batch size
- “Increased momentum coefficient”: initial LR 0.5, momentum 0.98, initial batch size 3200
- The final result of “Increased momentum coefficient” is 93.3%, lower than original 94.3%
- 결과적으로 increased momentum coefficient는 결과가 좋지 않음(1%정도 하락)
- 논문에선 보라색 그래프(제일 좌측)가 아직 수렴하지 않았으므로 더 학습 할 경우 정확도가 개선 될 것이라 판단하나 실험적으로 내용을 넣진 않음…
Training ImageNet in 2500 parameter updates
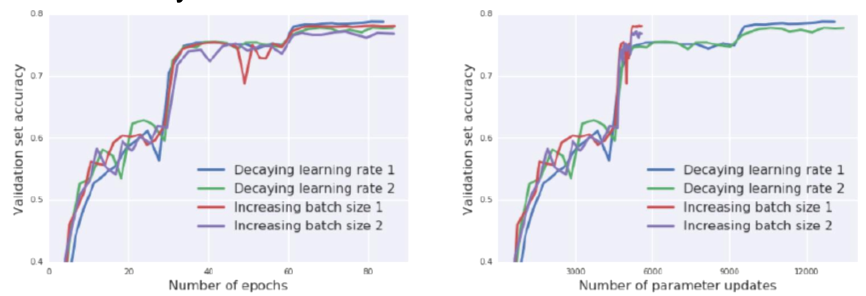
- Control batch size only (ImageNet dataset)
- 실험 1, 2는 두 실험 간의 variance를 보이기 위하여 두 번을 수행
- Trained Inception-ResNet-V2
- Ghost batch size 32, initial LR 3.0, momentum 0.9, initial batch size 8192
- Increase batch size only for first decay step
- The result are slightly drops, form 78.7% and 77.8% to 78.1% and 76.8%, the difference is similar to the variance
- Reduced parameter updates from 14,000 to below 6,000
- 결과가 조금 안좋아짐. 논문에선 원래 실험 자체 variance가 있으니 그 variance 안에 들어가므로 상관이 없다고 주장…
- 하지만 실제로는 1%정도의 정확도 하락을 보임
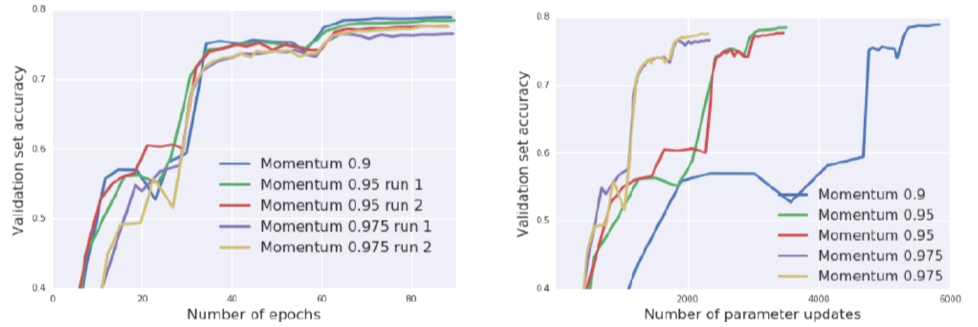
- Control batch size and momentum coefficient
- Initial LR 3.0 and Ghost batch size 64
- “Momentum 0.9”: initial batch size 8192
- “Momentum 0.95”: initial batch size 16384
- “Momentum 0.975”: initial batch size 32768
- Momentum coefficient 조절 시 실험 결과가 조금씩 나빠짐
- Batch size는 늘리고, 거기에 momentum까지 조절
Conlusion
- Scaling rule
- 더 빠른 학습을 수행
- Large batch size와 momentum을 증가시킴
- 더 낮은 accuracy loss
- Inception-ResNet-V2를 사용해 ImageNet datset에 대해 2500번의 weight parameter update만을 가지고 77%의 정확도를 달성
- [참고 글]
https://www.youtube.com/watch?v=jFpO-E4RPhQ