
 Seongkyun Han's blog
Seongkyun Han's blog
FitNets- Hints for Thin Deep Nets
07 Apr 2019 | Deep learningFitNets- Hints for Thin Deep Nets
Original paper: https://arxiv.org/abs/1412.6550
Authors: Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, Yoshua Bengio
Abstract
- Depth 네트워크는 성능이 좋지만 gradient 방식의 training은 깊은 네트워크의 커진 non-linearity로 인해 학습이 더 어려워졌다. 최근 제안된 knowledge distillation 접근방식은 작고 빠른 모델을 얻기 위하여 큰 네트워크나 앙상블의 soft output을 이용하여 그것을 닮도록 학습하는 방식이다. 본 논문에선 이러한 아이디어를 확장시켜서 깊은 teacher의 중간출력을 이용하여 얕은 student가 더 좋은 성능을 보이도록 학습시키는 방법을 제안한다. Student의 중간 hidden layer가 보통 teacher의 중간 layer보다 작으므로 추가적인 parameter가 teacher hidden layer의 prediction을 student hidden layer가 맞추도록 하는 추가 파라미터가 제안된다. 이로 인해 더 빠르게 동작하거나 더 나은 일반화 성능을 보이는 deeper student net에 대해 capacity를 조정 할 수 있게된다. 예를 들어 CIFAR-10 데이터셋에 대해 deep student network의 경우 10.4배의 적은 파라미터를 이용하여 크고 SOTA 성능을 보이는 teacher network의 성능을 능가 할 수 있게 된다.
Conclusion
- 논문에서는 student의 training process를 guide하기 위해 teacher의 hidden layer에서 intermediate-level hint를 이용하여 wide하고 deep한 네트워크를 thin하고 deeper한 네트워크로 압축하는 새로운 학습방법을 제안했다. 논문에선 이러한 hint를 사용하여 보다 적은 parameter로 very deep student model을 학습 시킬 수 있었으며, 이 student 모델은 teacher보다 더 나은 일반화 성능을 보이고 더 빠르게 동작하였다. 논문에선 teacher net의 hidden state로 thin and deep network의 inner layer들에게 hint를 주는것이 classification target으로 네트워크를 학습시키는것보다 더 나은 일반화 성능을 보인다는것을 실험적으로 증명했다. 벤치마크 데이터셋에 대한 실험은 capacity가 작은 깊은 네트워크가 10배 이상의 parameter를 가진 네트워크보다 비슷하거나 훨씬 뛰어난 feature 추출 능력이 있음을 보여준다. The hint-based training suggests that more efforts should be devoted to explore new training strategies to leverage the power of deep networks.
논문 내용
- 본 논문에선 2개의 신경망을 만들어서 사용한다. 하나는 teacher이고 다른 하나는 student이며, student net을 FitNets라 정의한다. Student net은 teacher에 비해 더 깊고 폭이 좁은(deeper and thinner) 구조로 되어있다. Teacher의 구조도 충분히 deep하고 성능이 괜찮지만 parameter 수에따른 많은 연산량등의 문제를 해결하기 위해 model capacity가 작은 student를 정의하여 이를 해결하겠다는 논문이다. 게다가 성능까지 더 좋게 만들었다는것이 논문의 주요 contribution이다. 또한 딥러닝의 구현에 있어 가용 가능한 capacity가 정해져 있다면 depth가 정말 중요한가에 대해 이를 실험적으로 보여줬다. 물론 depth를 키운다고 성능이 linear하게 좋아지진 않는다고 transferring attention 논문에서 보여준다.(https://arxiv.org/abs/1612.03928)
- 논문에서 주로 언급되는 knowledge distillation(KD) 기법에 대해 알아보면, KD는 wide and deep한 teacher net을 미리 학습시켜 놓고, teacher 의 output을 닮도록 student를 훈련시키는 모델 학습 방법이다. True label이 [0, 1, …, 0, 0] 과 같은 경우 신경망의 출력은 보통 각 class에 대한 확률 분포로 나타나기에 실제론 [0.17, 0.82, …, 0.01, 0.03] 과 같은 식으로 출력된다. KD에선 이러한 True label이 아니라 output을 닮도록 student net을 훈련시킨다. 하지만 depth도 비슷하고 성능도 괜찮아지는것에 비해 여전히 optimization이 힘들다는 단점이 있다고 한다.
- 이 논문에선 optimization에 대한 해결책을 제시함과 동시에 성능까지 더 좋게 만들 수 있는 방법을 제안했다. 이를 Hint-based learning(HT)라고 이름을 붙였는데, 메인 idea는 학습 시 True label, output 말고 intermediate hidden layers(hints)를 닮도록 네트워크를 훈련시키는 것 이다. 이러한 hints를 주는 방법이 parameter space에서 saddle-point(optimal point- optimization이 된 위치, minima)를 찾기 위한 더 좋은 initial position을 알려주게 된다. 이로 인해 모델의 generalization 성능이 좋아지게 된다.
- 이러한 HT 학습 방법을 적용함과 동시에 신경망을 더 좁고 더 깊게 만들었더니 전체적으로 parameter의 수가 확 줄어들면서도 inference에서 소요되는 multiplication 횟수가 적은, 10배 정도 효율이 더 좋은 모델을 만들 수 있게 되었다. 일단 한번 teacher 신경망을 잘 훈련시켜 놓으면 훨씬 가볍고 빠른데 심지어 성능까지 좋은 student 신경망을 만들 수 있게 된다는 의미다.
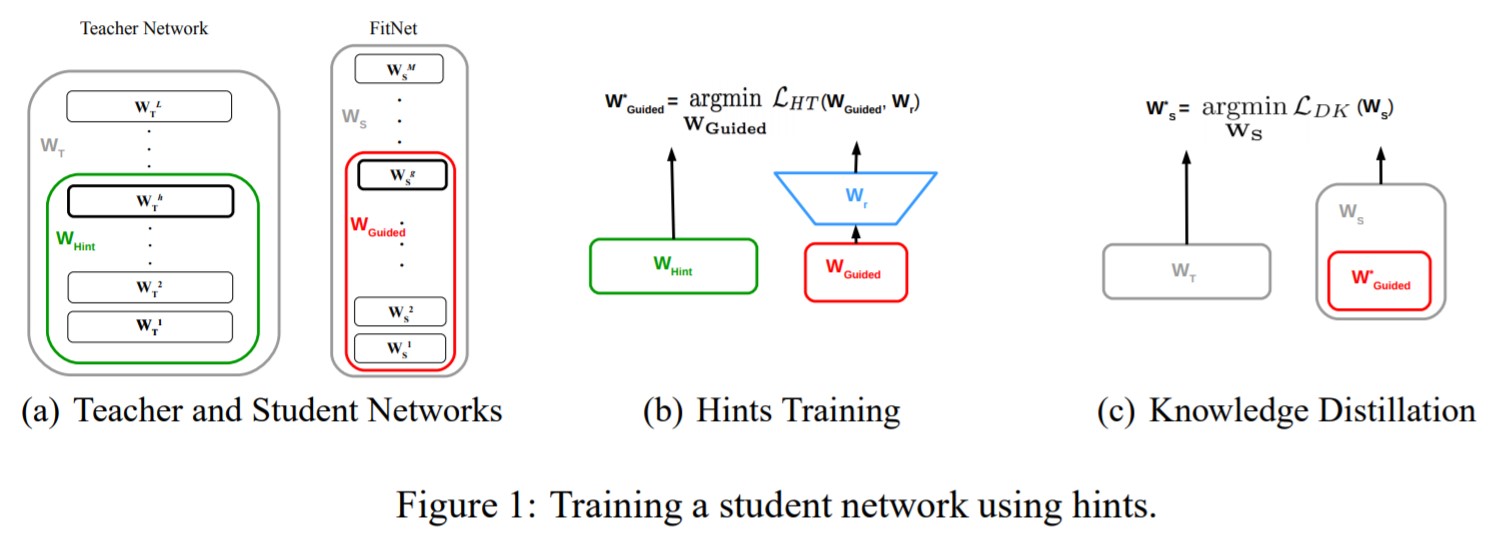
-
Figure 1(a)에서 굵게 칠해져 있는 두 layer가 서로 비슷해지도록 student를 훈련시킨다. 그런데 student는 teacher보다 좁기(thin) 때문에 그냥 비슷하게 하기에는 공간방향으로의 문제가 존재한다. (서로 사이즈가 다르므로 비교시 문제 발생) 즉, 차원의 문제가 발생한다. 그래서 고안한 것이 Figure 1(b)에 파란색으로 그려진 $W_{r}$ 이다. Regressor를 하나 만들어서 차원을 확장시킨 다음에 그 결과값이 비슷해지도록 하는 것인데, 이 regressor에서 사용하는 weight가 바로 $W_{r}$ 이다. Student의 학습시에도 이 $W_{r}$ 도 같이 훈련된다.
-
논외로.. 여기에 한단계 더 나아가는것이 transferring attention이다. 여기선 True label, output, hidden layer 말고 attention layer를 닮도록 훈련시킨다. (https://arxiv.org/abs/1612.03928)
모델의 학습

- 네트워크 학습에는 pre-trained teacher 파라미터인 $W_{T}$와 랜덤하게 초기화된 student(FitNet)의 파라미터들인 $W_{S}$ 를 입력으로 받는다. $h$는 hidden layers, $g$는 guided layer이다. $W_{Hint}$는 hint layer($h$)까지의 teacher의 파라미터이다. $W_{Guide}$는 guided layer($g$)까지의 FitNet의 파라미터들이다. $W_{r}$은 regressor의 파라미터들이다. 첫 번째 stage는 teacher network의 hint layer의 prediction error에 기반으로 student network를 guided layer까지 pre-training 한다(line 4). 두 번째 stage는 전체 네트워크에 대한 KD(knowledge distillation) training이다(line 6).
성능
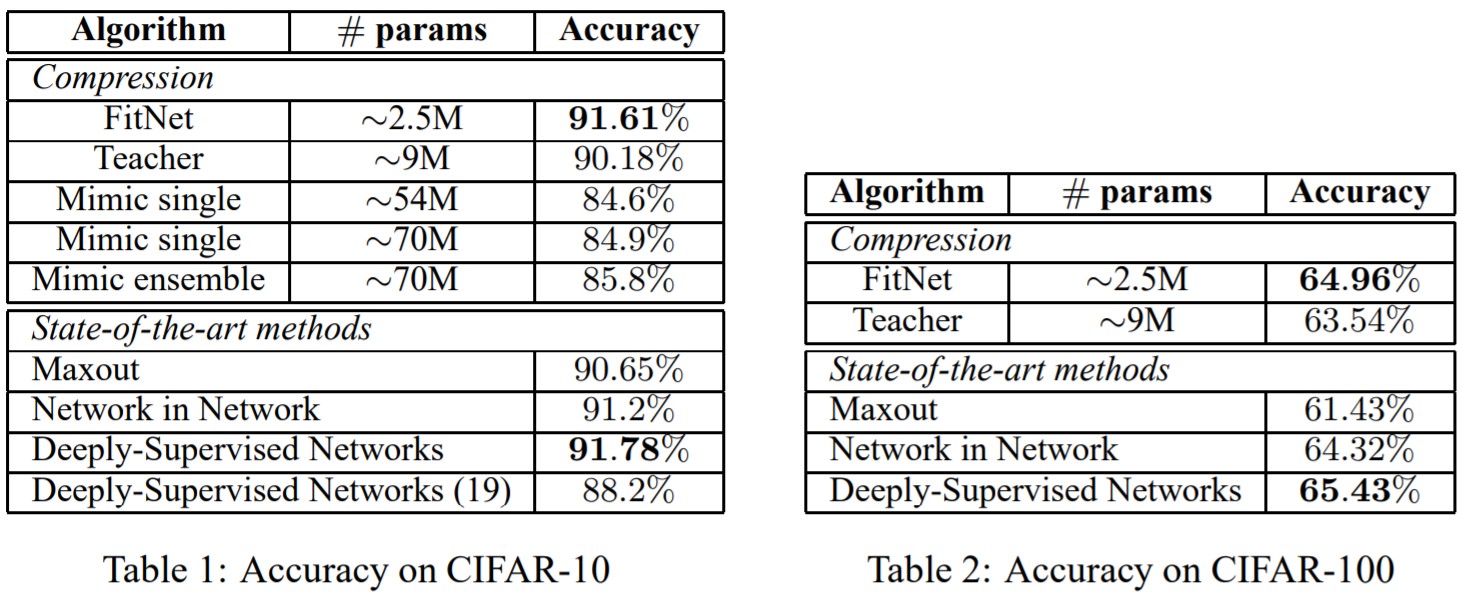
- 이 논문에선 CNN을 이용한 image classification task에 대해 성능을 평가했다. CIFAR-10, CIFAR-100, SVHN, MNIST, AFLW 등의 데이터셋들에 대해 실험을 진행했다. 일단 성능 자체가 teacher보다 student(FitNets)가 훨씬 좋게 나오고, parameter 수가 적은데도 SOTA 기법들에 견줄 수 있을만큼 좋은 성능을 보였다.
- Mimic ensemble: Ba, J. and Caruana, R. Do deep nets really need to be deep? In NIPS, pp. 2654–2662. 2014.
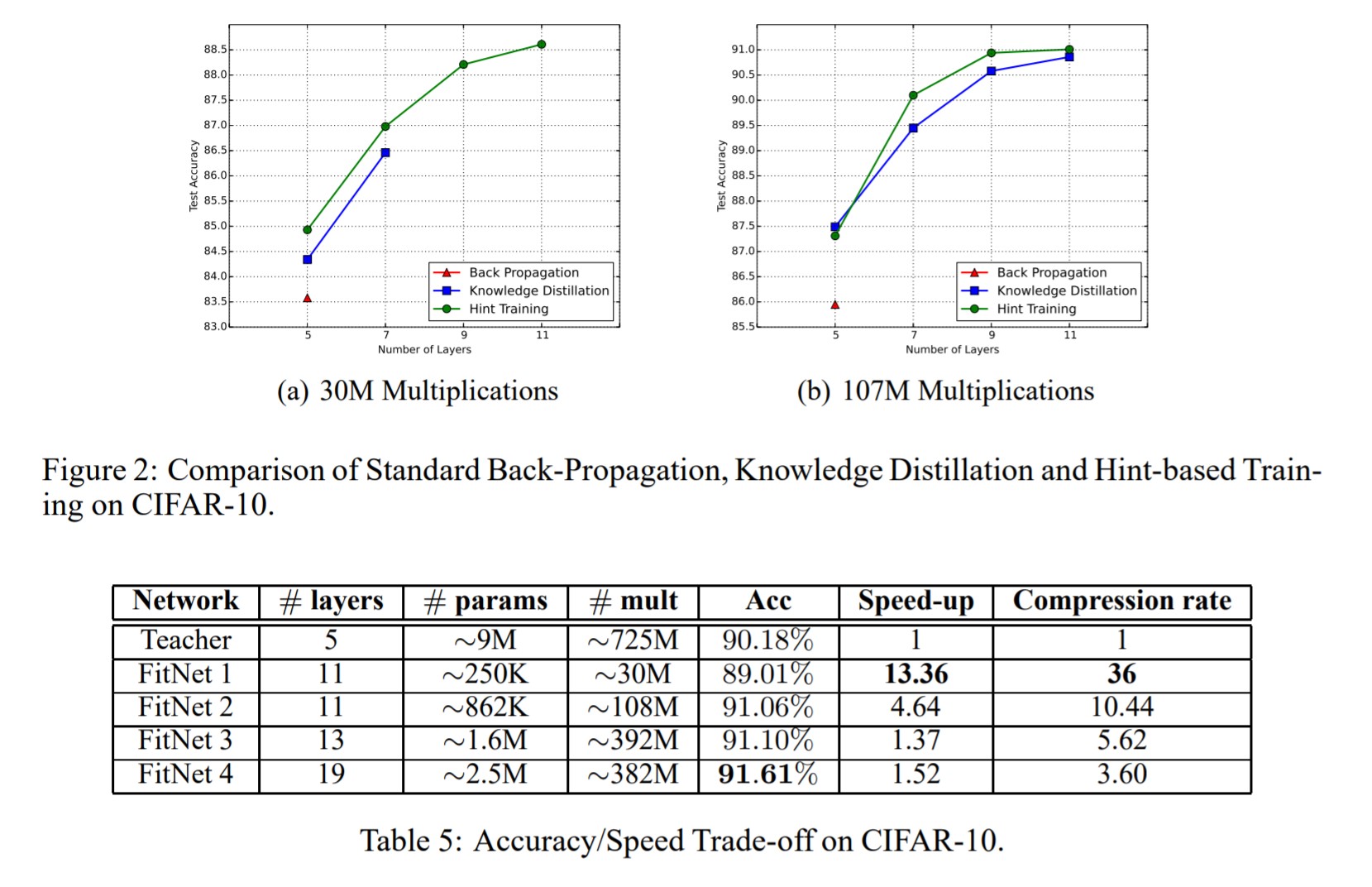
- 실험에선 추가적으로 computing resource를 제한해놓고 depth를 늘리면서 비교를 했다. 더 구체적으로는 30M, 107M 개로 사용 가능한 operation 수를 정해놓고, 평범한 back-propagation(BP) 학습방법, Knowledge Distillation 방법, Hint Training 방법들을 구현한 모델들의 layer 수를 각각 3, 5, 7, 9로 바꿔가며 비교실험했다. 기존의 BP방법은 layer 수가 5개를 넘어서면 operation 숫자가 부족해 아예 훈련을 못마쳤다고 한다. Knowledge distillation은 BP보다 조금 나았지만 여전히 30M 부분에서는 layer 수가 늘어나면 학습이 힘든것을 볼 수 있다. 당연하게도 이 논문에서 제안한 Hint Training 기법은 그런 것에 상관없이 훈련을 잘 마칠 수 있었으며 성능도 더 좋았다.