
 Seongkyun Han's blog
Seongkyun Han's blog
Object detection at 200 Frames Per Second
11 Apr 2019 | Deep learningObject detection at 200 Frames Per Second
Original paper: https://arxiv.org/pdf/1805.06361.pdf
Authors: Rakesh Mehta, Cemalettin Ozturk
Abstract
- 논문에선 수백FPS로 동작하는 효율적이고 빠른 object detector를 제안한다. 이를 위해 network architecture, loss function, traning data(labeled and unlabeled)의 세 가지 관점에서 연구했다. 작은 network architecture를 얻기 위해 몇몇의 연산량이 적은 light-weight 모델이면서 성능은 합리적인 연구들에 근거한 몇몇의 제안점들을 설명한다. 연산복잡도는 유지하면서 성능의 향상을 위해 distillation loss를 활용한다. Distillation loss를 사용함으로써 더 정확한 teacher network의 정보(knowledge)를 제안하는 light-weight student network에 전달한다. 논문에선 제안하는 one stage detector pipeline의 distillation이 효율적으로 동작하게 하기위해 objectness scaled distillation loss, feature map non-maximal suppression, detection을 위한 single unified distillation loss function을 제안한다. 마지막으로 distillation loss이 unlabeled data를 활용하여 얼마나 모델의 성능을 끌어올릴 수 있는지에 대해 탐구한다. 제안하는 모델은 teacher network의 soft label을 사용하는 unlabeled data도 이용하여 학습되어진다. 제안하는 네트워크는 VGG based object detector보다 10배 적은 파라미터를 갖고, 속도는 200FPS를 넘어서며 PASCAL dataset에 대해 제안하는 방법을 적용하여 14mAP의 정확도를 달성하는것이다.
1. Introduction
- [25, 27, 22, 26, 7, 10, 21]의 연구들에선 deep convolutional network를 이용하여 정확도가 좋은 모델들이 제안되었다. [22(SSD), 26(YOLO9000)]등의 최신 연구에선 일반적인 객체를 정확하고 합리적인 속도로 검출했다. 이러한 연구들로 인해 감시, 자동주행, 로보틱스 등 다양한 산업분야에서 객채탐지가 사용가능해졌다. 해당 분야의 주요 연구들은 pubil benchmarks [21, 10]에 대해 SOTA의 성능을 내도록 집중되었다. 이러한 연구들로 인해 네트워크는 점점 더 깊어져만 갔고(Inception[33], VGG[32], Resnet[11]) 그결과 연산비용이 비싸지며 메모리를 많이 필요로하게 되었다. 이러한 연구들로 연산량증가로 인해 산업에 full-scale로 적용하는것은 불가능하다는 문제가 존재했다. 예를들어 30FPS로 동작하는 50개의 카메라들로 구성된 시스템에 SSD512를 적용하기 위해선 60개의 GPU가 필요하다[22]. 이는 처리해야 할 데이터량이 많아질경우 연산능력이 critical하며 필요한 GPU의 수는 더 많아진다. 하지만 몇 연구들에선 이러한 빠르고 low memory만 요구하며 효율적인 object detector의 중요성을 간과하였다[17]. 본 논문에선 단일GPU로 low memory만 사용하는 효율적이고 빠른 연산시간을 갖는 object detector에 대해 연구한다.
- 빠르고 효율적인 object detector를 디자인하기 위해 딥러닝 object detector에 필수 요소, 해당 필수요소를 만족하는 객채탐지기의 개발가능여부에 대해 중점적으로 탐구했다. [25, 27, 22, 26, 7]에 근거하여 딥러닝 기반의 객채탐지기 famework의 key component를 다음과 같이 정의했다. (1) Network architecture, (2) Loss function, (3) Traning data. 논문에선 각 component들에 대해 개별적으로 연구하고 본 논문에서 제안하거나 related work에 근거한 broad set of customizations을 설명하며, 그것들 중 뭐가 속도와 정확도의 trade-off에 있어서 가장 중요한지에 대해 연구한다.
- 네트워크 architecture는 객체탐지기의 속도와 정확도를 결정짓는 key factor다. 최근의 탐지기들[15]은 VGG나 Resnet등의 깊은 구조를 기반으로 하며 이는 정확도를 좋게하나 연산량이 많아지는 단점이 존재한다. Network comparison과 puning[9, 5, 13]은 detection architecture가 더 간단하도록 해주는 방법을 제안햇다[36, 31, 38]. 하지만 이러한 방법들은 아직도 속도의 향상이 필요한데, 예를들어 [31]의 작은 네트워크는 17FPS로밖에 동작하지 않으면서 17M의 파라미터를 갖는다. 본 연구에선 compact archicture 뿐만아니라 고속으로 동작하는 object detector의 design principle을 개발한다. Densenet[14], Yolo-v2[26], SSD[22]의 deep하고 narrow한 네트워크 구조에서 영감을 받았다. 깊은 구조를 사용하면 정확도는 향상되며 narrow한 layer로 인해 네트워크의 복잡도를 조절할 수 있게 된다. Architecture의 변경을 통해 정확도가 5mAP정도 향상 가능하다는것을 확인했다. 이러한 연구들을 기반으로 architecture design의 main contribution은 딥러닝 기반의 객체검출기를 간단하지만 효율적인 네트워크 아키텍쳐를 개발하면서 200 FPS 속도로 동작하게 하도록 한다. 게다가 제안하는 모델은 15M의 파라미터만을 사용하여 VGG16기반의 모델[3]이 138M개의 파라미터를 사용하는것에 비해 매우 작으므로 가장 작은 모델이 된다. 제안하는 모델의 속도는 Figure 1에서 비교 가능하다.
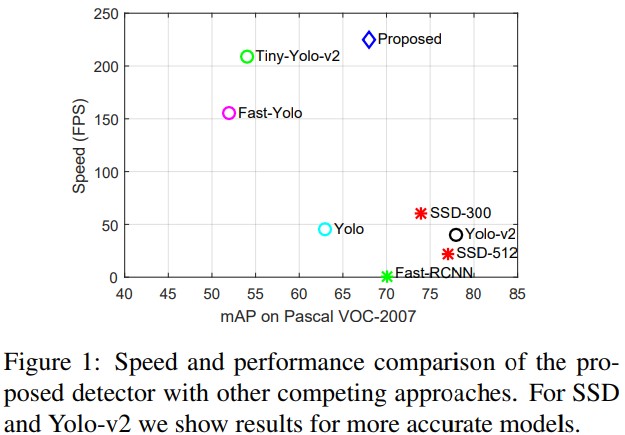
- 간단하고 빠른 architecture만을 사용해야 하기에 성능 향상을 위한 효율적인 학습 방법에 대해 조사했다. 어느정도 정확한 light-weight detector에 대해 더 정확한 모델을 이용하여 training 방법을 더 잘 하게 만든다. 이러한 목적으로 [12, 2, 1]의 network distillation 방법을 고려하였으며, 이는 큰 네트워크의 정보(knowledge)가 효율적으로 더 작은 네트워크의 표현력이 좋아지도록 사용되는 것이다. 비록 이러한 아이디어가 object detection에 최근 사용되었지만[3, 20], 본 논문에선 주요 contribution을 distillation의 적용의 측면에서 중요하게 적용되었다. (1) 본 논문의 방법은 첫 번째 single pass detector(Yolo)에 대한 적용이며, 이전의 연구들이 RCNN계열을 사용한것과 차이점을 갖는다. (2) 본 논문의 접근방식에서 가장 중요한 것은 object detection이 end-to-end 학습과정 외부의 non-maximal suppression(NMS)를 포함한다는 observation(관찰)에 기반한다는 점이다. NMS step 이전에 detection network의 마지막 layer는 detection된 region의 dense activation으로 구성되어지며 만약 student network에 직접 teacher의 이러한 정보(dense activation)가 전달되게 된다면 overfitting으로 이어져 성능이 떨어지게 될 것이다. (3) Teacher detection에서 더 질좋은 탐지를 강조하여 problem을 objectness scaled distillation loss로 공식화하였다. 논문의 실험결과들은 distillation이 연산복잡도는 낮게하면서 성능은 향상시키는 효율적인 접근방법임을 보여준다.
- 마지막으로 object detection의 관점에서 “the effectiveness of data”[8]에 대해 연구했다. 레이블링 된 데이터들은 그 양이 제한적이나, 매우 정확한 object detector와 엄청나게 많은 unlabeled data를 적용하게 될 경우 제안하는 light-weight detector의 성능이 얼마나 향상될지에 대해 연구했다. 제안하는 아이디어는 object detector 분야에 대해서만 연구되지 않은 semi-supervised learning 방법들[29, 35, 4]를 따른다. 최근에 object detector 앙상블을 사용하여 annotation들을 생성되도록 하는 [23]의 방식은 본 연구와 매우 관련성이 높다. 제안하는 방법은 [23]과 다음의 차이점들을 보인다. (1) Network distillation에서 더 효율적이게 teacher network에서의 convolutional feature map에서 나온 soft label을 전달한다[28]. (2) Objectness scaling과 distillation weight을 이용하는 본 논문의 loss공식은 teacher label의 weight given을 조절 할 수 있게 한다. 이러한 공식을 통해 ground truth의 학습에서의 중요성을 더 높게하면서도 상대적으로 정확도가 낮게 예측한 teacher의 결과를 flexible하게 이용 할 수 있게 된다. 게다가 제안하는 traning loss formulation은 detection loss와 distillation loss를 균일하게 이어주며, 이로인해 network는 labeled data와 unlabeled data의 정보를 모두 학습 할 수 있게 된다. 논문에선 이 논문이 labeled/unlabeled data를 jointly하게 이용하여 네트워크를 학습시키는 첫 번째 deep learning object detector 모델이라고 한다.
2. Architecture customizations
- 대부분의 성능좋은 객체탐지모델은 좋은성능을 위해 깊은 모델을 쓴다. 하지만 가장 빠른모델이라해도 속도가 20~60FPS로 제한된다[22, 26]. 더 빠른 객체탐지모델을 개발하기 위해 Tiny-Yolo[26]과 같은 성능은 중간정도지만 제일 빠른 모델을 baseline으로 선택했다. 이는 더 적은 convolutional layer를 가지는 Yolo-v2 모델이며, Yolo-v2와 동일한 loss function, optimization strategies(batch normalization[16]), dimenstion cluster, anchor box등을 갖는다. 이 모델을 기반으로 모델이 더 정확하고 빨라지도록 적용된 몇 가지 구조적 커스터마이징에 대해 설명한다.
Dense feature map with stacking
- [(Densenet)14, (SSD)22]와 같은 최근의 연구에서 영감받아 이전 레이어의 feature map을 합침으로써 성능 향상이 되는 것을 관찰했다. 논문에선 주요 convolution layer의 마지막부분에서 몇몇의 이전 layer에서의 feature map을 합쳤다. 이전 레이어에서 온 feature map의 차원이 뒤쪽것과 다르다. [22]와 같은 논문에선 max pooling을 통해 resize 후 concat 했다. 하지만 max pooling은 곧 정보의 손실이므로 논문에선 더 큰 feature map을 크기를 조절해서 activation이 다른 feature map에 분산되도록 feature map을 stacking했다[26].
- 게다가 feature를 merging하면서 넓은 범위에서 bottleneck layer를 적용하였다. Bottleneck layer를 사용하는 이유는 정보를 더 적은 layer에 넣을 수 있기 때문이다[14, 34]. Bottleneck의 1x1 convolution layer는 depth를 추가시키는 동시에 compression ratio를 유연하게 표현하도록 해준다. Advanced layer(뒤쪽 레이어)들의 feature map들을 합치게 되면 성능이 향상되므로 initial layer들에 대해선 높은 compression ratio를, advanced layer들에 대해선 낮은 ratio를 사용했다.
Deep but narrow
- Baseline인 Tiny-Yolo의 구조는 2014라는 큰 숫자의 feature channel을 마지막 몇 convolution layer에서 사용한다. 이전 layer에서의 feature map concat을 사용할 때는 이렇게 많은 feature map이 필요 없다. 따라서 filter의 숫자를 줄였으며, 이로인해 속도가 향상되었다.
- SOTA 객체탐지기와 비교할 때 제안하는 구조는 depth가 좀 모자르다. 몇 conv layer를 쌓으면서 depth를 늘릴 순 있지만 이는 곧 연산량의 증가로 이어지므로 본 논문에선 연산량 제한을 위해 1x1 conv layer를 사용하였다. 마지막 major conv layer 이후 1x1 conv layer를 추가하여 network의 depth는 늘리면서도 연산복잡도는 증가시키지 않을 수 있었다.
Overall architecture
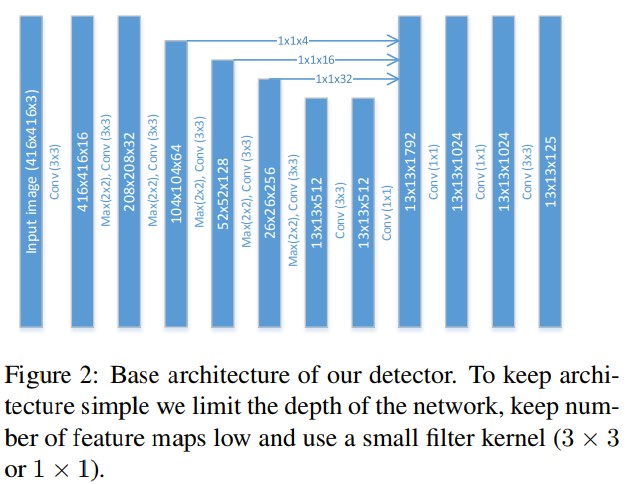
- 앞의 간단한 concept들을 묶어서 light-weight 객체탐지기를 제안한다. 이러한 modification들로 인해 baseline인 Tiny-Yolo에 비해 성능이 5 mAP정도 향상되었다. 게다가 속도도 20%가 더 빨라졌다. 이는 더 적은 convolutional filter 갯수덕분이라고 판단된다. Baseline인 Tiny-Yolo의 PASCAL dataset 성능은 54.2 mAP이지만, 제안하는 구조는 59.4 mAP를 달성했다. 전체적인 구조는 Figure 2에서 보여준다. 그리고 이 구조를 F-Yolo라고 명명한다.
3. Distillation loss for Training
- 논문에선 고속 동작을 위해 네트워크의 구조를 간단하게 했다. 그리고 network distillation[28, 12]방법의 적용을 통해 연산량은 늘리지 않으면서도 정확도의 향상을 꾀했다. Network distillation의 적용은 light-weight network를 student로 하여 large accurate network(teacher)의 정보를 이용하여 student 모델을 학습시키는것이다. 정보의 전달은 teacher network의 추론결과를 soft label 식으로 넘겨주게 된다.
- Distillation 접근법을 묘사하기 전에 Yolo loss function이 어떻게 구성되었고 last convolution layer가 어떤지 간단하게 짚고 넘어간다. Yolo는 one stage 구조로써 RCNN계열과는 다르게 각 bounding box 좌표와 classification 확률이 동시에 마지막 레이어의 출력에서 이루어지게 된다. 따라서 마지막 레이어의 feature map의 갯수는 N x (K + 5)개로 설정되며 이 때 K는 클래스의 갯수, 5는 해당하는 bounding box의 좌표와 4개와 objectiveness value 1로 구성된다. 따라서 각각 anchor box와 cell에 대해 네트워크는 class probabilities, objectness value, bounding box coordinates를 학습하게 된다. 전체적인 objective는 다음의 3개 파트로 구분되며, 각각 regression loss, objectness loss, 그리고 classification loss이다. 이를 수식적으로 표현하면 아래와 같다.
- 각각 $\hat{o_{i}}, \hat{p_{i}}, \hat{b_{i}}$는 student의 objectnessm class probability, boundinb box coordinates이며 $o_{i}^{gt}, p_{i}^{gt}, b_{i}^{gt}$는 ground truth value들이다. Objectness는 예측결과와 ground truth사이의 IOU에 의해 결정되며, class 확률은 객채가 존재하는 경우의 class의 조건부 확률이고, box 좌표는 image size와 $L_{1}$ 나 $L_{2}$같은 loss function에 관계되어 있다. [25, 26] for details.
- Distillation을 적용하기 위해 teacher network의 마지막 레이어의 출력을 가져와서 ground truth $o_{i}^{gt}, p_{i}^{gt}, b_{i}^{gt}$값을 대체하면 된다. Loss는 teacher network의 activation을 student network로 전파하게 된다. 하지만 single stage detector의 dense sampling으로 인해 이러한 간단한 방식의 application은 distillation을 효율적이지 못하게 만든다. 이에 대한 해결 방안은 아래에서 논해질것이며 이를통해 간단히 single stage detector에 distillation을 적용할 수 있게된다.
3.1 Objectness scaled Distillation
- RCNN 계열에 distillation을 적용한 연구[20, 3] 에선 정보 전달을 위해 teacher의 마지막 출력만을 사용하여 student로 정보를 넘겼다. Yolo에도 이와 유사하게 적용하려고 했지만 single stage detector이기도 하고 prediction이 객체위치와 클래스를 한번에 추론하도록 하는 dense set of candidate를 이용하여 추론되기 때문에 어렵다. Yolo teacher는 image의 background region에도 많은 bounding box를 추론한다. 그 동안에 이러한 필요없는 background box들은 candidate의 objectness값으로 인해 무시되어진다. 하지만 standard distillation approach는 이러한 background detection 또한 student로 학습에 필요한 정보로써 넘어간다. 이는 bounding box training $f_{bb}()$에 영향을 주고, 이로인해 student network가 background영역에 teacher에 의해 잘못 추론된 결과를 학습하게 된다. RCNN based 객체탐지기들의 경우 비교적 적은 region proposal을 예측하도록하는 region proposal network를 사용하여 이러한 문제를 피해갔다. Background 지역의 잘못된 teacher의 prediction을 학습하는것을 피하기 위해 distillation loss를 objectness scaled function으로써 공식화했다. 기본 아이디어는 bounding box coordinate와 class probability를 teacher prediction의 objectness value가 높을때만 학습하도록 하는것이다. 함수의 objectness part는 objectness scaling이 필요하지 않는데, 이는 noisy candidate의 objectness value가 낮기 때문이다. Objectness part는 다음과 같이 정의된다.
- Student network의 objectness scaled classification function은 다음과 같이 정의된다.
- 위 함수의 첫 번째 부분은 original detection function이며 두 번째 파트는 objectness scaled distillation part다. 비슷하게 student network의 bounding box coordinate도 objectness를 사용하며 scale되어있다.
- 표현력 좋은 teacher network는 background에 해당하는 대다수의 candidate에게 매우 작은 objectness value를 할당한다. Objectness based scaling은 single stage detector에서 distillation을 위한 filter역할을 하며, background cell에 매우 낮은 weight를 할당하게된다. Object같은 foreground 영역은 teacher network에서 높은 objectness값을 갖게되며, formulated distillation loss는 이러한 영역의 teacher knowledge를 이용하게 된다. Loss function은 원래와 같지만 distillation을 위해 ground truth 대신 teacher output만을 추가한 형태가 된다. 모델 학습을 위한 loss function은 아래와 같다.
- 이는 classification을 위한 detection과 distillation loss, bounding box regresssion, objectness를 고려한 식이다. 이 식은 모든 anchor box들과 마지막 conv feature map에서의 모든 cell location을 이용하여 최소화 되어지도록 학습되어진다.
3.2 Feature Map-NMS
- Another challenge that we face comes from the inherent design of the single stage object detector. 모델은 하나의 cell에 대해 single anchor에서 하나의 박스만 추론하도록 학습되어지지만 실제로는 몇몇의 cell과 anchor box들에 의해 같은 객체에 대해 수 많은 박스를 추론하게 된다. 따라서 NMS가 object detecor 구조에서의 필수 후처리 과정이 된다. 하지만 NMS step은 end-to-end network 구조에서 맨 마지막에 붙으며 highly overlapping 추론결과는 detector의 last conv layer에서 표현되어진다. 이러한 추론결과가 teacher에서 student로 전달되어진다면 이는 쓸모없는 정보의 전달이 되는것이다. 따라서 teacher network가 highly overlapping detections에 대한 information loss을 전달하므로 위에서 설명된 distillation loss로 인해 모델의 전체적 성능이 떨어지게 된다. Higly overlapping detection의 feature map은 결국 같은 object class와 dimension에 대한 large gradient를 propagation하게되어 network가 over-fitting되게 만든다.
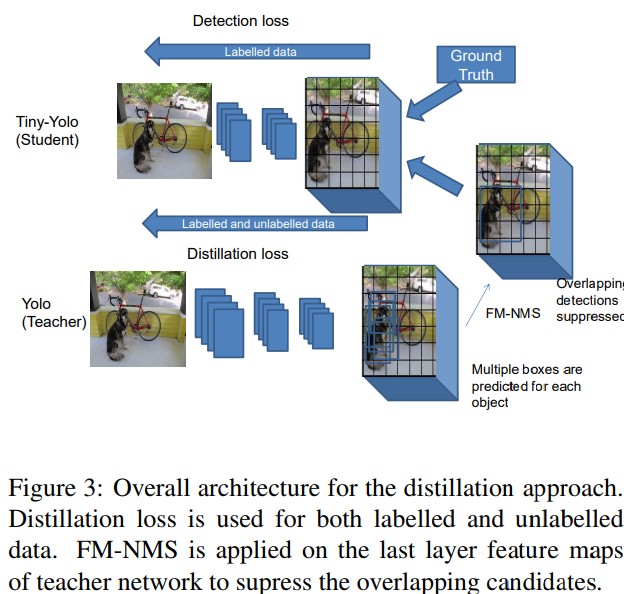
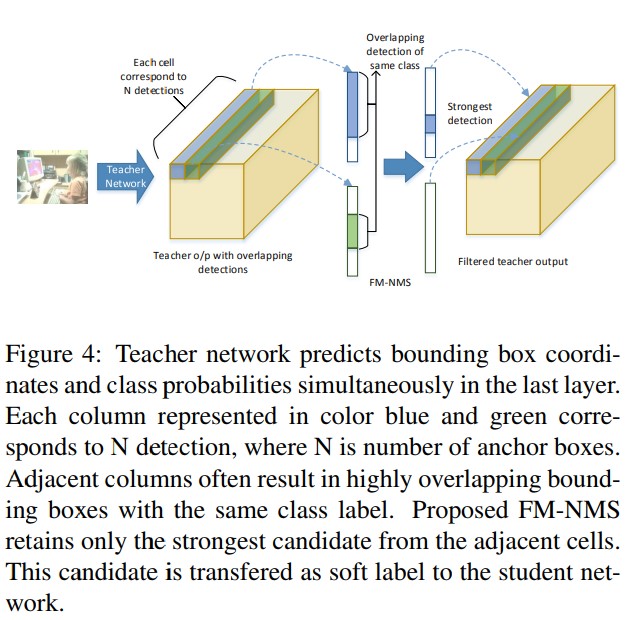
- 이러한 overlapping detections에서 발생하는 문제를 해결하기 위해 Feature Map-NMS(FM-NMS)를 제안한다. FM-NMS의 기본 idea는, 만약 같은 클래스에 상응하는 KxK cell 지역에 multiple candidate가 존재한다면 그것들은 image에서 같은 하나의 객체일 확률이 높다. 따라서 가장 높은 objectness 값을 선택해 단 하나의 candidate를 선택한다. 실제로 last layer feature maps에서 class probability에 해당하는 activation을 확인하고, activation이 동일한 class에 해당하는 0으로 설정한다. Figure 3에 idea가 설명되어있으며, detection form으로 teacher network의 soft label들이 보여진다. Teacher net의 last layer가 개 주변에 여러 box들을 추론한다. 동일 지역의 겹치는 추론을 피하기 위해 가장 높은 objectness 값을 선택한다. 겹치는 candidate중 가장 강한 candidate가 student network로 전달된다. 두 cell에 대한 idea의 예시가 figure 4에 나와있다. 실험에선 3x3 인접 cell에 대해서만 적용되었다.
4. Effectiveness of data
- 마지막으로 학습 데이터가 많다면 얼마나 성능이 좋아지는지에 대해 연구했다.
Labeled data
- [37, 22]에선 더 많은 레이블링된 데이터를 통해 모델의 성능이 향상된다는것을 보였다. 하지만 초기연구는 모델의 용량을 제한하지않고 실험을 수행햇다. 본 연구에선 간단한 모델로 모델의 용량을 제한하고 평가해서 학습데이터가 많아질 경우 정확도가 좋아지는지를 확인했다.
Unlabeled data
- 레이블링된 데이터에는 한계가 있으므로 unlabeled 데이터와 distillation loss를 조합하여 네트워크를 학습시켰다. 제안하는 방법의 main idea는 사용가능한 soft label와 ground truth label을 이용하여 모델을 학습시키는것이다. 하지만 ground truth 레이블이 사용 불가한 경우 teacher에서의 soft label만 사용되어진다. 실제 논문에선 ground truth가 없을 경우 loss의 teacher part만 propagation하고 그렇지 않다면 식 (2)~(4)에 설명된 loss combination을 propagation한다. Objective function은 soft label과 ground truth로 균등히 조합되어 있기때문에 network를 학습시킴에 있어서 labeled data와 unlabeled data를 모두 사용 가능하게 된다.
5. Experiments on Object detection
- 실험은 PASCAL VOC 2007 dataset[6]을 이용하였으며 20개 클래스에 16K training image가 존재한다.
5.1 Implementation Details
- 평가에 darknet framework[24]를 사용했다. ImageNet[30]에 대해 학습된 Tiny-Darknet classifier가 parameter initialization으로 되었다. Pre-trained network의 마지막 두 레이어를 제거한 후 추가 conv layer들을 마지막에 달았다. Detection에 있어서 네트워크는 SGD로 최적화되고 initial learning rate는 $10^{-3}$으로 120 epoch까지, $10^{-4}$로 다음 20epoch, 마지막으로 $10^{-5}$로 20epoch를 학습시켰다. Momentum 0.9와 0.0005 weight decay를 적용했다. Batch size는 모두 32로 동일하다. 입력 이미지의 크기는 416x416이다. Network distillation 실험에선 $\lambda_{D=1$이고 이는 동일한 weight로 distillation과 detection loss가 적용되어진것을 의미한다. 하지만 loss에서 distillation part가 objectness로 곱해지므로 final distillation part weight는 항상 detection loss보다 적게 된다.
5.2 Architecture
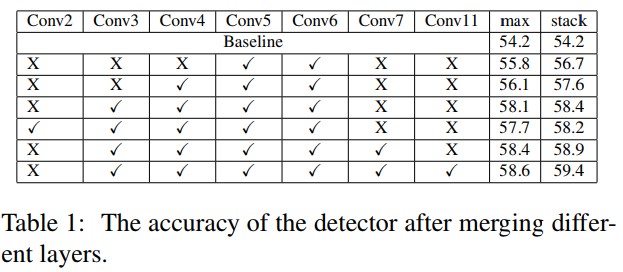
- 본 섹션에선 서로다른 모델 구조 configuration에 대한 실험결과를 다룬다. 우선 base architecture에서 feature map merging으로 인한 효과를 측정했다. 다양한 레이어 merging 조합은 table 1에서 보여진다. 더 많은 레이어에서 feature map들이 같이 병합될 경우 정확도는 점점 더 좋아졌다. 또다른 중요한점으로, 네트워크 초기 레이어의 feature map을 합치는것보다 뒤쪽 레이어의 feature map을 병합하는것이 더 성능향상에 도움이 된다. Table 1의 레이어 출력 combination 결과에서 중간에 살짝 정확도가 떨어지는 경우가 있는데 이는 초기 레이어가 기초적인 정보만을 담을 수 있기 때문이다. Table 1에서 conv 11 column은 네트워크의 구조를 깊게 하기 위해 마지막에 추가된 1x1 conv layer다. 이러한 레이어로 인해 0.5mAP의 상승이 있었고 이러한 1x1 conv layer로 인해 연산량 측면에서 효율적으로 네트워크의 깊이를 증가시킬 수 있었다.
- 또한 두 개의 다른 방법을 이용한 feature map merging에 대해서도 실험비교결과를 보였다. 대부분의 이전 연구[22, 17]에서 사용한 maxpooling과 달리 feature stacking은 덜 흔한 방법이다[26]. 실험으로 feature stacking이 max pooling보다 더 나은 성능을 보인다는것을 확인했다. 더 나은 정확도를 위해 모든 merging combination에서 feature stacking을 사용했다.

- Table 2에선 baseline detector의 다양한 변화에 따른 속도 차이를 보여준다. 속도는 GTX 1080 8GB GPU와 16GB CPU memory환경에서 측정되었다. 더 좋은 GPU를 쓰면 속도는 더 빨라진다. For the baseline Tiny-Yolo, we are able to achieve the speed of more than 200 FPS, as claimed by the original authors, using parallel processing and batch implementation of the original Darknet library. 모든 속도측정은 4952장의 Pscal VOC 2007 test image에 대한 평균시간이며, 파일 쓰기와 detection 시간을 모두 포함한 시간이다. 실험 결과에서 merging operation은 detector의 속도를 감소시키지만 feature map을 많게 해 준다. Combined feature maps layer의 convolutional operation은 detector의 속도를 줄인다. 따라서 feature map의 수를 줄이는것이 속도 향상에 큰 도움이 된다. 1024개의 feature map을 512개로 줄으로써 200FPS 이상의 속도를 달성 할 수 있었다. 마니막으로 1x1 conv layer를 구조의 끝에 추가하여 연산량의 증가를 최소화했다. 이러한 간단한 구조적인 modifications로 인해 popular한 architecture에 비해 더 빠른 속도로 동작한다.
5.3 Distillation with labeled data
- 우선 teacher와 student 네트워크에 대해 설명한다. 학습에 Yolo based teacher의 soft label을 사용한다. 전달되는 soft label을 이용하여 학습되므로 student와 teacher의 input image resolution은 같아야 한다. 따라서 Darknet-19 base Yolo-v2를 teacher model로 사용했다. 연산량이 적어 매우 빠른 제안하는 F-Yolo를 student로 사용했다. 실험에선 더 많은 labelled data가 성능 향상에 도움이 되는지를 Pascal과 COCO dataset의 조합으로 확인했다. Pascal에선 2007, 2012 training/validation set을, COCO에선 Pascal에서 클래스가 존재하는 카테고리의 training image를 사용했다. 65K개의 추가 이미지를 COCO에서 얻을 수 있었다.
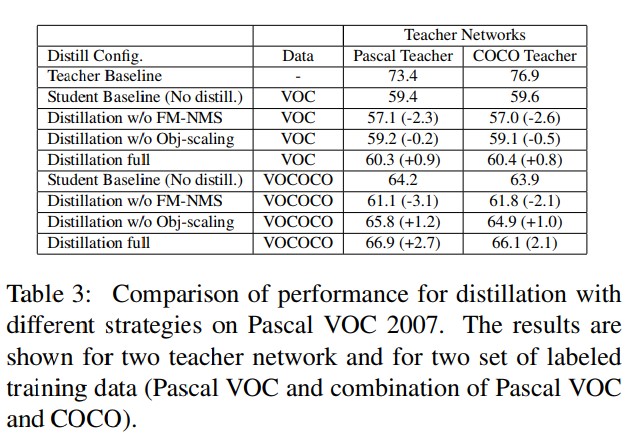
- Distillation traning에서의 teacher network의 효과를 연구하기 위해 teacher model을 두 개의 다른 데이터셋으로 학습시켰으며, 하나는 Pascal data와 다른 하나는 Pascal 과 COCO dataset의 combination된 set으로 학습을 시켰다. Baseline teacher 모델은 Table 3에서 보여진다. Yolo-v2를 COCO로 학습시킨 모델의 경우 성능이 3.5mAP가 좋아졌다. 이 과정을 통해 더 정확한 teacher model의 효과를 확인 할 수 있었다.
- 첫 번째 실험에서 제안하는 방법의 효과를 정의하기위한 다양한 방법들을 실험하고 비교했다. 이를 통해 single stage detector에 대한 다음의 두 가지 innovation을 제안한다. Objectness scaling and FM-NMS. Distillation을 FM-NMS와 objectness scaling step 없이 수행했다. 실험 결과는 table 3에서 확인가능하다. Distillation이 적용된 student network의 성능은 FM-NMS가 적용되지 않은 경우 성능이 baseline보다 더 떨어지게되는것을 확인할 수 있었다. 두 teacher network에 대해 네트워크 성능의 큰 하락이 확인 가능하다. 실험 결과를 통해 single stage detector에서 FM-NMS가 distillation이 동작하도록 하는 중요한 요소입을 확인했다. Objectness scaling 없이 진행된 실험에서 또한 약간의 성능이 하락하였다.
- COCO의 추가 레이블링된 데이터셋을 이용한 실험의 경우 유사한 trend를 보이며, 따라서 FM-NMS과 object scaling이 중요함을 확인했다. 그리고 더 많은 학습 데이터를 이용해 full distillation 방법을 적용햇을 때 성능이 가장 많이 향상되었다. COCO training dataset을 사용한 full distillation 방법은 2.7mAP의 증가가 있었다. 학습 데이터셋이 클수록 더 많은 soft label이 이용 가능해지며, 이를 통해 더 많은 object like section의 정보가 이용이 가능해진다.
- 또한 baseline detector의 성능이 더 많은 traning dataset을 이용할 때 더 좋아진다는것을 확인했다. 이는 제안하는 light-weight 모델이 더 많은 traninig sample이 있을 때 충분한 용량을 갖는다는 것을 의미한다. Distillation loss와 추가 학습 데이터를 통해 제안하는 detector는 200FPS가 넘는 속도로 67mAP를 달성했다.
- 놀랍게도, 고정된 student에 있어서 teacher detector는 학습에 주요하게 동작하지 않았다. COCO teacher가 VOC와 COCO data의 조합으로 학습된 teacher보다 성능이 떨어졌다. 이는 teacher의 성능 차이가 크지 않기 때문에 teacher quality의 영향력을 평가하는게 어렵다고 판단된다.(¡ 4mAP)

- 각 PASCAL VOC 2007 test set에 대한 각 클래스별 정확도를 table 4에서 확인 가능하다. 제안하는 F-Yolo(구조변경만 적용된 모델)의 성능과 D-Yolo(구조 변화와 distillation loss의 적용)의 성능은 original Yolo와 Yolo-v2와 비교되어있다. 흥미롭게도 bottle이나 bird와 같이 작은 객체의 경우 distillation loss와 많은 training data가 적용된 경우 정확도가 10AP정도 향상되었다. Tiny-Yolo와 제안하는 방식의 성능비교는 Figure 5에서 그림으로 보여진다.

5.4 Unlabeled data
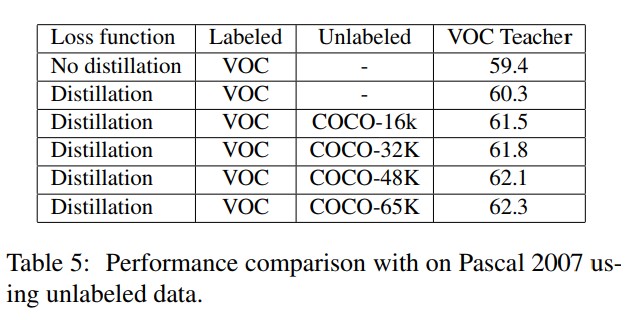
- 앞에서 COCO와 VOC를 섞은 데이터셋을 이용한 실험에선 F-Yolo가 더 많은 학습 데이터에 대해 학습이 가능한 충분한 용량이 있음을 밝혔다. 이번 section에선 제안하는 모델이 얼마나 많은 unlabeled data를 통해 학습이 가능한가를 확인한다. 이번 실험에선 traning set에서 unlabelled data를 늘려가며 정확도를 측정한다. 레이블링 데이터는 VOC에서만 사용하고 레이블이 없는 데이터는 COCO에서 사용한다. 레이블링/언레이블링 된 영상들은 함께 조합되어 학습에 사용되며, 레이블이 없는 이미지의 경우 teacher만 통과해서 추론된 soft-label 을 넘기도록 학습되어진다. 네트워크는 각 16K, 32K, 48K, 65K개의 unlabelled data를 이용하여 학습되어지도록 하며 그에대한 student network의 영향을 파악한다. 실험결과는 table 5에서 보여진다. 추가 data가 있을 경우 baseline detector의 성능이 3~4mAP정도 크게 증가하는것을 알 수 있다. 더 많은 unlabelled data가 있을 경우 성능은 더 향상 될 것이다.
- It is interesting to compare the change in the performance with unlabeled data and COCO labeled data separately to understand the importance of annotation in the training. 레이블이 있는 COCO 데이터셋을 확용하여 제안하는 모델을 학습시켰을 때 64.2mAP가 측정되었으며(Table 3 student baseline) Yolo-v2를 teacher로 하여 unlabeled COCO 영상들을 사용했을 때 62.3mAP를 달성했다. 이는 비록 annotation이 중요하긴 하지만 정확한 teacher network가 간단하게 추가된 unlabeled training data를 이용하게 함으로써 더 큰 성능의 향상이 가능했음을 보여준다.
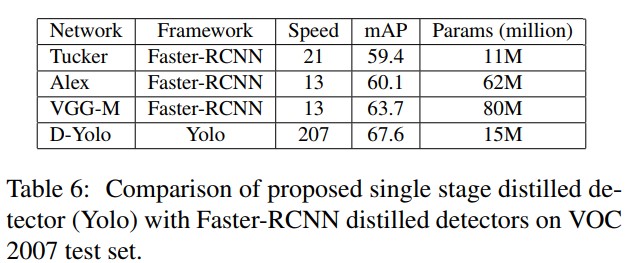
- 마지막으로 제안하는 distillation 방법을 경쟁하는 방법인 [3]과의 실험 결과를 비교했다. 비교대상 방법은 Fater-RCNN에 대한 distillation 방법이며, 제안하는 방법은 single stage용, 비교대상 방법은 two stage용이다. 실험 결과는 table 6에서 보여진다. 성능은 다음의 architecture에 대해 비교된다. Alexnet[19], Tuckernet [18], VGG-M [32]이며 이는 VGG-16[32]로부터 distillation된 정보를 이용한다. 제안하는 distilled network는 RCNN detector에 비해 엄청 빠르다. 파라미터 수 관점에서도 제안하는 방법과 Tucker 방법이 비교 가능하지만, Faster-RCNN based detector에 비해 엄청 빠르다. 이러한 방법들에 대해 속도 향상은 single stage detector의 효율적인 설계와 속도에 최적화 된 기본 네트워크 구조 및 훈련에 사용되는 추가적인 데이터 때문이다. 실험결과는 이러한 변화로 인해 9mAP이상의 정확도 향상과 더불어 더 빠르게 동작하는것을 보여준다.
Conclusion
- 논문에선 효율적이고 빠른 object detector를 제안했다. 객체검출모델의 speed performance의 trade-off를 조절하기위해 네트워크의 구조, loss function, training data의 역할에 대해 연구했다. 네트워크의 설계에는 이전에 수행되었던 연구들을 이용하여 계산복잡도를 적게 유지하기 위해 몇 가지의 간단한 idea들을 확인하고, 이 아이디어들의 방법을 활용하여 light-weight network를 개발했다. 네트워크 학습 과정에서 FM-NMS와 objectness scaled loss와 같이 carefully하게 설계된 components와 더불어 disitillation이 powerful한 idea임을 보였고, 이를 통해 light-weight single stage object detector의 성능이 향상되었다. 마지막으로 distillation loss를 기반으로 unlabeled data의 traning에 대한 연구를 수행했다. 논문의 실험에선 제안하는 design principle이 적용된 모델이 SOTA object detector들보다 훨씬 빠르게 동작하며 동시에 resonable한 성능을 얻을 수 있다는것을 보였다.