
 Seongkyun Han's blog
Seongkyun Han's blog
Multi-layer Pruning Framework for Compressing Single Shot MultiBox Detector
15 Apr 2019 | Deep learningMulti-layer Pruning Framework for Compressing Single Shot MultiBox Detector
Original paper: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8658776&tag=1
Authors: Pravendra Singh, Manikandan R, Neeraj Matiyali, Vinay P. Namboodiri (IIT)
Abstract
- 본 논문에선 Single Shot MultiBox Detector를 compressing하는 framework를 제안한다. 제안하는 SSD compressing framework는 Sparsity Induction, Filter Selection, Filter Pruning의 stage를 거쳐서 모델을 압축시킨다. Sparsity Induction stage에선 object detector model이 improved global threshold에 따라 sparsified(희박해진다는 의미)되어지며, Filter selection과 Pruning stage에선 두 연이은 convolutional layer의 filter weight에서 sparsity statistics에 근거해서 제거할 filter를 선택하고 제거하게 된다. 이로인해 기존의 구조보다 모델이 더 작아지게 된다. 제안하는 framework를 적용한 모델을 이용하여 다양한 데이터셋을 이용하여 검증하였으며, 그 결과를 다른 compressing 방법과 비교했다. 실험결과 PASCAL VOC에 대해 제안하는 방법을 적용했을 때 각각 SSD300과 SSD512에 대해서 6.7배, 4.9배의 모델 압축을 이뤄냈다. 게다가 SSD512모델에 대한 GTSDB 데이터셋 실험에선 26배의 모델 압축을 이뤄낼 수 있었다. 또한 일반적인 classification task에 대해 VGG16 모델을 이용하여 CIFAR, GTSRB 데이터셋을 학습시킨 모델에 적용시킨 결과 각각 125배, 200배의 모델압축과 90.5%, 96.6%의 연산량(flops)감소를 이루어냄과 동시에 정확도는 하락되지 않았다. 그리고 제안하는 framework를 모델에 적용시키는데엔 다른 추가적인 하드웨어나 라이브러리가 필요없다.
1. Introduction
- Through this paper we make the following contributions:
- Sparsity constraint-based training을 이용하는 multi-layer pruning 알고리즘을 제안하며, 정확한 객채인식을 하면서 줄어든 weight parameter set을 얻기위한 retraining step을 따른다.
- PASCAL VOC와 GTSDB와같은 official benchmark를 통해 제안하는 방법이 적용된 SSD 모델을 평가했다.
- 제안하는 방법은 classification task에 적용 가능하다. 객체분류에 있어서 125~200배의 parameter수를 줄일 수 있었다.
2. Related work
- Pruning and parameter sharing, Compact Architectures, Knowledge Distillation, Object detection에 대해 다룸
3. Multi-layer Pruning Framework
3.1 Famework Overview
- 기본적으로 각 필터의 중요도를 측정한다음에 그에 따라 중요하지 않은 필터를 제거하는 원칙을 따른다.
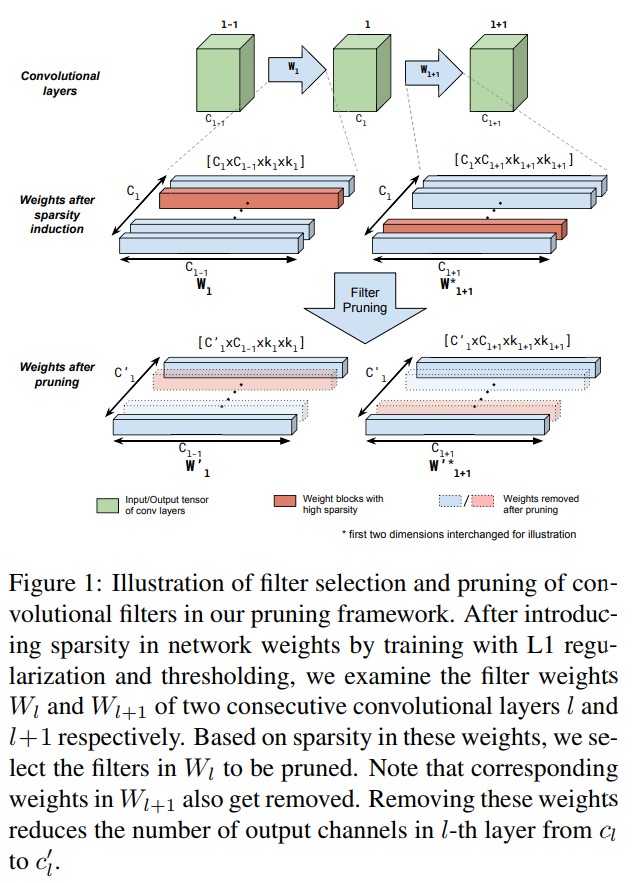
- Figure 1에서 제안하는 filter pruninng strategy를 설명한다. Pre-trained model이 있고 이 모델의 파라미터는 $\Theta$이며, $L$ 이라는 pruning될 연이은 layer set이 존재한다. 전체 framework는 아래의 step을 따른다.
- Sparsity induction: 첫 번째 step에서 sparse model $\Theta_{L1}$을 만들도록 하는 L1-norm이 적용된 loss function을 사용하여 모델을 학습시킨다. 다음으로 제거할 레이어 $L$에서 threshold보다 작은 값을 갖는 weight를 0으로 만든 모델 $\Theta_{L1}^{th}$을 만든다. 이 때 사용될 threshold값은 $\Theta_{L1}^{th}$모델이 validation set에서 돌아갈 때의 결과를 토대로 정한다. Pruning될 레이어 셋 $L$에서 단일 global threshold값을 사용한다. 이로인해 한 번의 step으로 $L$의 filter들을 prune할 수 있게된다. Details는 section 3.3에서 다뤄진다.
- Filter selection: 레이어 집합 $L$에 속한 레이어 $l$의 중요도를 평가한다. 여기서 $\Theta_{L1}^{th}$ 모델에서의 레이어 $l$과 $l+1$의 filter sparsity statics를 사용한다. 주요 아이디어는 zero weights의 large fraction이 있는 $l$의 모든 필터와 zero weights의 large fraction이 있는 $l$의 필터를 제거하는 것이며, 그림 1에서와 같이 다음 layer $l+1$의 필터에서 이 필터를 가져다 연산하게 된다.(The key idea here is to remove all the filters in l that have a large fraction of zero weights in them as well as those filters in l that have a large fraction of zero weights corresponding to them in the filters of the following layer l + 1 as illustrated in Figure 1.) 이 step의 마지막에서 모델에서 제거 될 레이어 $l$의 필터에 대한 list를 얻게 된다. Step 2를 모든 $L$ 레이어에 대해 반복한다. Details는 섹션 3.4에서 다룬다.
- Pruning: Layer $l$ 에서 step 2에서 선택된 필터들과 해당하는 output이 필요한 $l+1$ layer가 모델 $\Theta_{L1}$에서 제거된다. 모든 $L$의 레이어들에 대해 반복된다.
- Retraining: 마지막으로 pruning된 네트워크를 original loss(W/O L1 regularization)를 이용하여 떨어진 정확도 복원을 위해 재학습 시킨다.

4. Experiment
- 논문에선 실험에 다양한 데이터셋과 detection, classification에 대해 다뤗지만 본 글에선 PASCAL VOC object detection에 대해서만 살펴본다.
4.1 Pruning of SSD on PASCAL VOC
- Previous work[37]에선 base network만 pruning했지만, 본 논문에선 SSD 전체를 pruning한다. 하지만 구조가 복잡해 한번에 pruning하면 정확도가 많이 떨어지므로 multiple phase로 수행한다. 실험엔 VGG16 based SSD를 썼으며, SSD512에 대해 conv1 1 - conv4 3, conv4 3 - conv7, conv7- conv8 2, conv8 2 - conv12 2의 4개 phase로 pruning했다. 또한 localization과 classification layer들도 포함했다. SSD 300도 동일하게 4개의 phase로 나뉘었다.
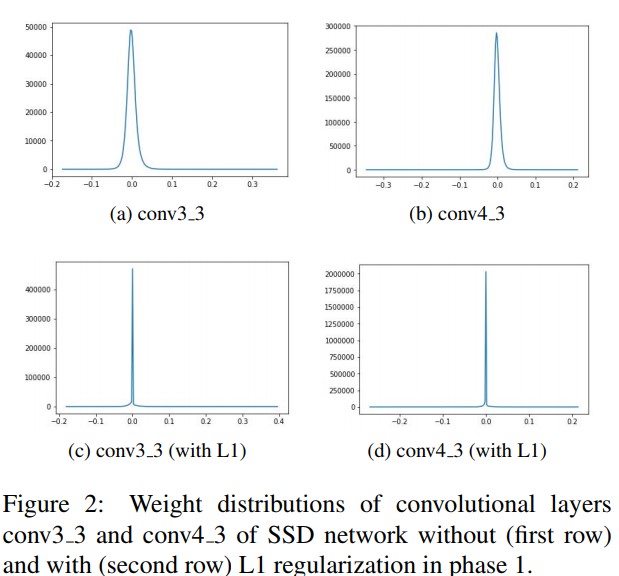
- Figure 2에선 L1 regularization의 효과를 보여준다. 적용하면 weight가 더 모이게 된다.
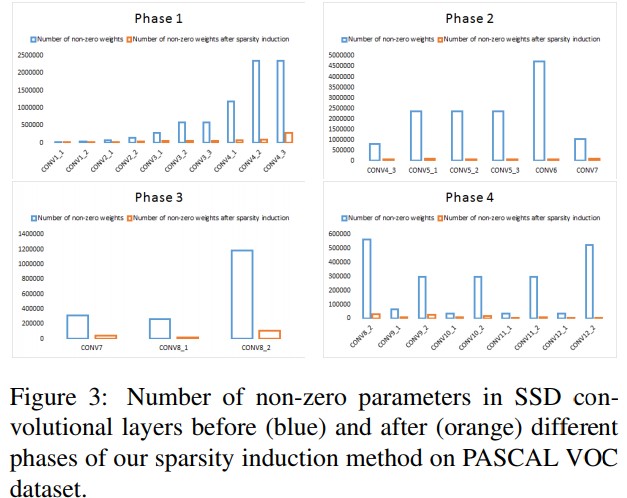
- Thresholding 후 Figure 3에서 non-zero parameter가 확연히 줄어든걸 확인 할 수 있다.
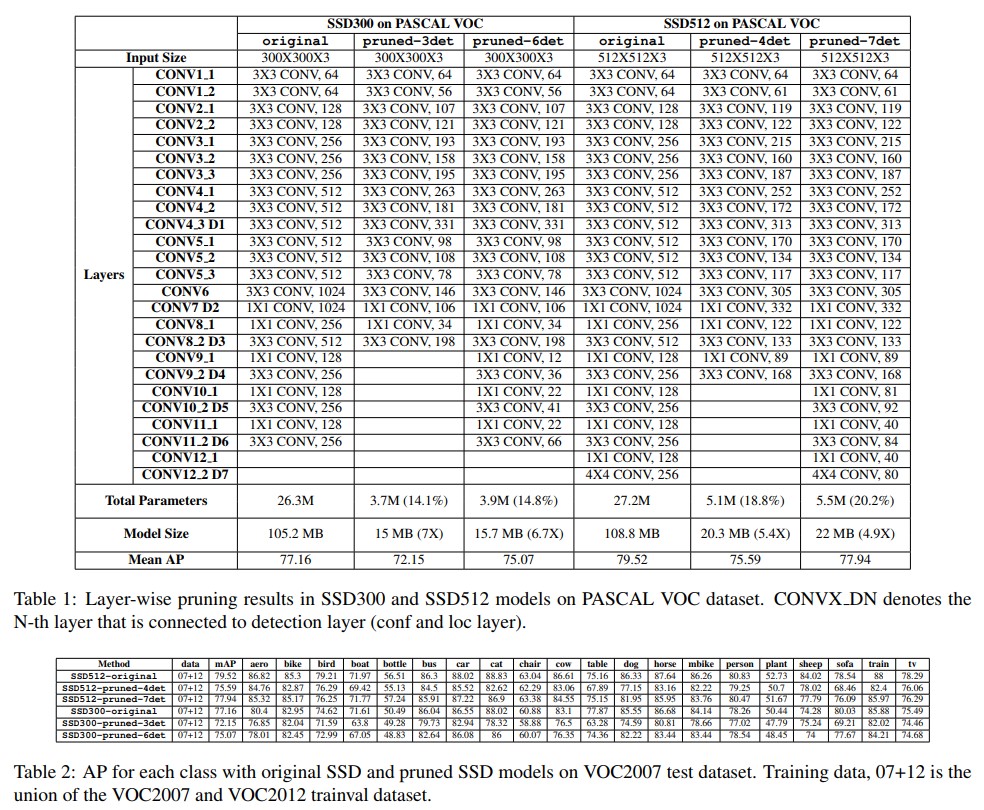
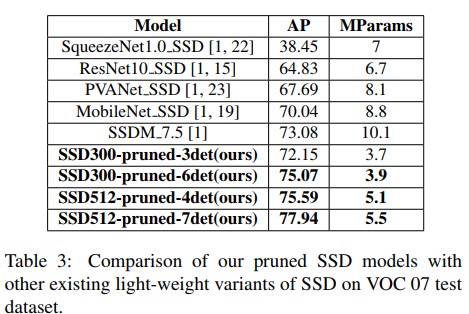
- 각 실험결과는 위의 표에서 확인 가능하며, SSD300-prunded-3det등의 모델명에서 det은 해당 번째 detection layer까지 pruning을 진행하였단 뜻이다. 전체 SSD 모델을 봤을 때, feature extractor에서 만들어진 feature map이 뒤쪽 detection layer로 전달되어 detection 결과를 추론한다. 여기서 기본적으로 모델은 7종류의 feature map을 받게 되며, 해당 feature map을 출력하는 layer까지 pruning을 진행했다는 것을 의미하게 된다. 표 1을 보면 이해가 빠르다.
- 실험 결과 전제척으로 정확도는 많이 떨어지지 않으면서도 모델 사이즈는 엄청나게 줄어들게 되는것을 확인 가능하다.
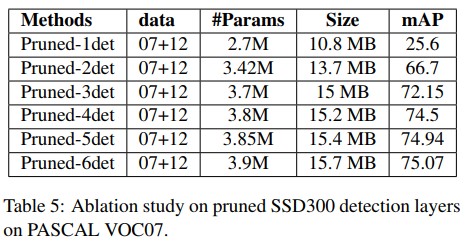
- Table 5를 보면, 각 detection layer가 어디까지 pruning 되었느냐에 따라 정확도와 파라미터 수, 모델 사이즈에 대한 영향력을 확인 할 수 있다.
Conclusion
- 본 논문에선 Multi-layer pruning 방법을 제안했다. 주요 아이디어는 training loss function을 수정해서 첫 번째 procedure로 sparsity(희소성)를 유도하는것이다. 두 번째로, sparsity inducing loss function이 0에 수렴하도록 학습되어진 모델의 filter를 pruning한다. 이로인해 classifier와 detector가 구조적으로 크기가 줄어들면서 정확도가 약간 감소하지만 retraining을 통해 그 정확도를 recover할 수 있게된다. 이로인해 SSD 객채탐지모델을 이용하여 SOTA의 압축률을 달성했다. 더 나아가 visiual recognition task와 다른 관련된 loss를 이용하여 filter를 pruning하는것에 대해 연구할 예정이다.