
 Seongkyun Han's blog
Seongkyun Han's blog
SSD- Single Shot Multibox Detector
01 Jul 2019 | Deep learningSSD: Single Shot Multibox Detector
Original paper: https://arxiv.org/pdf/1512.02325.pdf
Authors: Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
Implementation code: https://github.com/amdegroot/ssd.pytorch (Pytorch)
- 대략적인 SSD의 프로세스를 알지만 구체적으로 정확하고 자세하게 분석되어있지 않아 직관적 이해를 위해 다룸
- 참고 글: https://taeu.github.io/paper/deeplearning-paper-ssd/
Abstract
- SSD discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location(multiple feature map).
- 즉, 아웃풋을 만드는 multi-feature map을 나눈 다음 각 feature map에서 다른 비율과 스케일로 default box를 생성한 후, 모델을 통해 계산된 좌표와 클래스값에 default box를 활용해 최종 bounding box를 생성한다.
Introduction
- 섹션 2.1 Model과 2.2 Training에서 box의 class 점수와 위치좌표 크기를 예측하는데 고정된 default box를 예측하도록 하는 내용을 다룸
- 정확도 향상을 위해 서로 다른 피쳐맵에서 서로 다른 스케일의 예측을 할 수 있게 함.
- YOLO v1의 경우 최종 아웃풋으로 나온 하나의 feature map의 각 그리드 셀당 2개의 bounding box를 예측하도록 했음
- SSD는 이에 반해 여러가지의 grid cell을 갖고 각 feature map당 여러가지(보통 6개) 바운딩박스를 가짐
- 2.1과 2.2에서 상세설명
The Single Shot Detector (SSD)
2.1 Model
- Image detection의 목적상 들어온 영상에서 객체의 위치와 크기, 레이블을 찾아야 함.
- 따라서 input으로는 이미지, output으로는 class score, x, y, w, h가 됨.
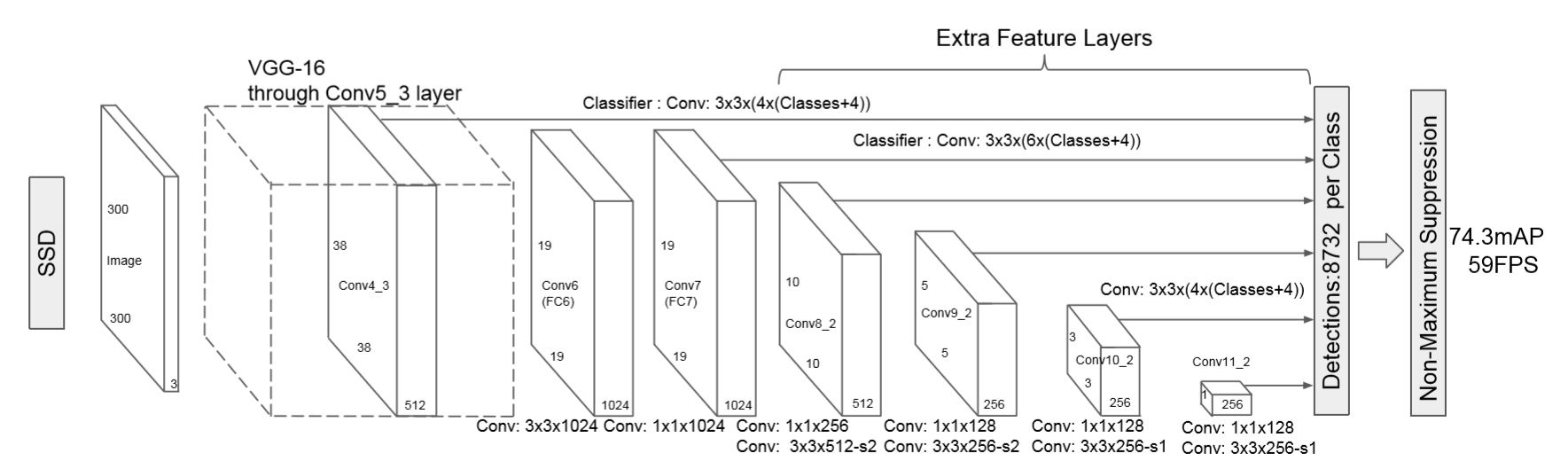
- 논문의 SSD 구조는 위와 같음(VGG16 backbone)
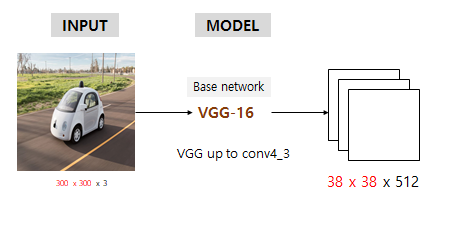
- 우선 SSD는 저해상도에서도 작동이 잘 되기에 300x300 pixel image를 기본적으로 입력받도록 함.
- Input image를 기본적으로 처리할땐 backbone인 VGG16을 갖고와 conv4_3까지만 가져다가 씀
- 300x300x3 input이 backbone 통과 후 38x38x512가 됨
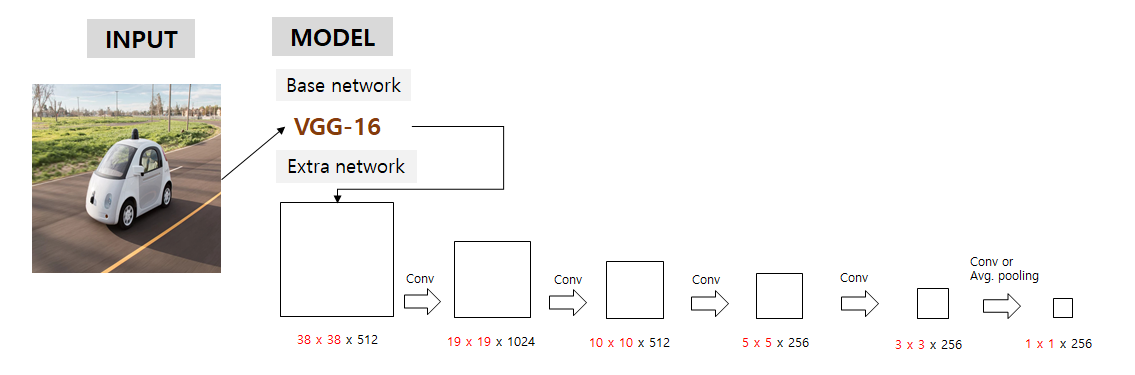
- 다음으로 논문에서 강조하는 multi feature maps에 해당하는 부분으로, 각각 위의 사진의 크기를 갖는 feature map들을 backbone과 extra network가 포함된 feature extractor에서 가져와서 그 multi-feature map들을 이용하여 detection을 수행하게 됨.
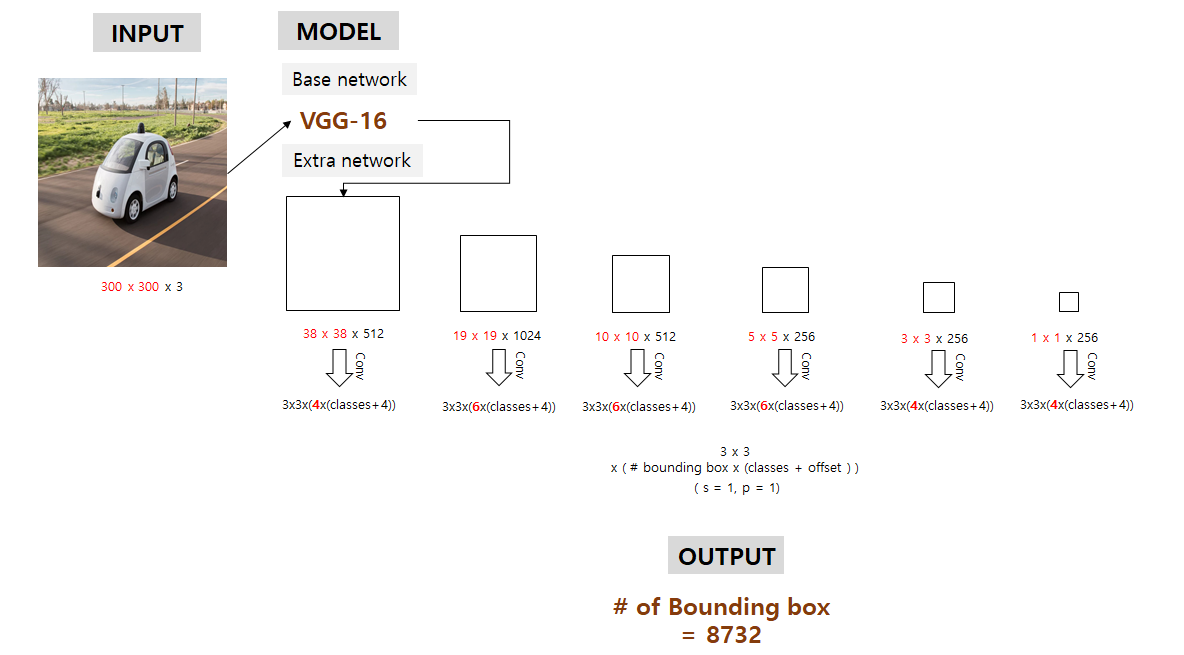
- 각 feature map에서적절한conv 연산을 이용해 우리가 예측하고자 하는 bounding box의 정보들(x, y, w, h, class scores)을 예측함.
- 여기서 conv filter size는 3 x 3 x (# of bounding box x (class score + offset)) 이 됨
- stride = 1, padding = 1로 추정
- 이 6개의 서로 다른 크기를 갖는 feature map들 각각에서 예측된 bounding box의 개수 합은 하나의 클래스당 8732개가 됨
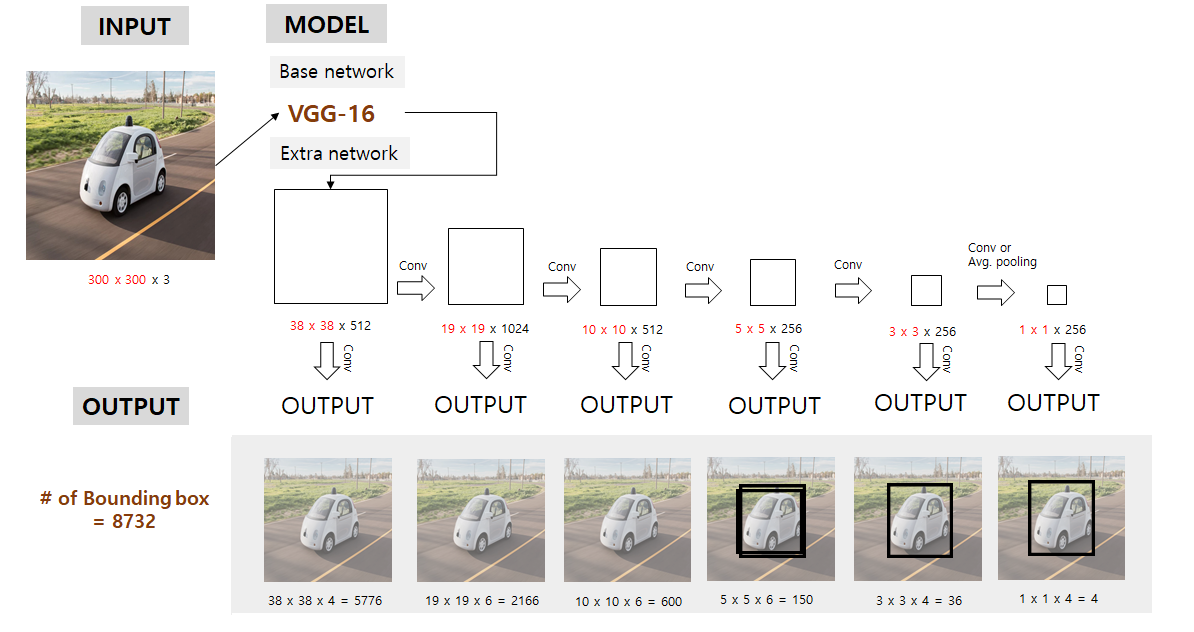
- 8732개의 bounding box의 output이 나온다고 해서 그것을 다 고려하지 않음
- Default box간의 IOU를 계산한 후 0.5가 넘는 box들만 출력결과에 포함시키고 나머지는 0으로 하여 실효성 없는 데이터를 삭제함
- 이 box들을 NMS를 거쳐서 중복되는 box를 제거
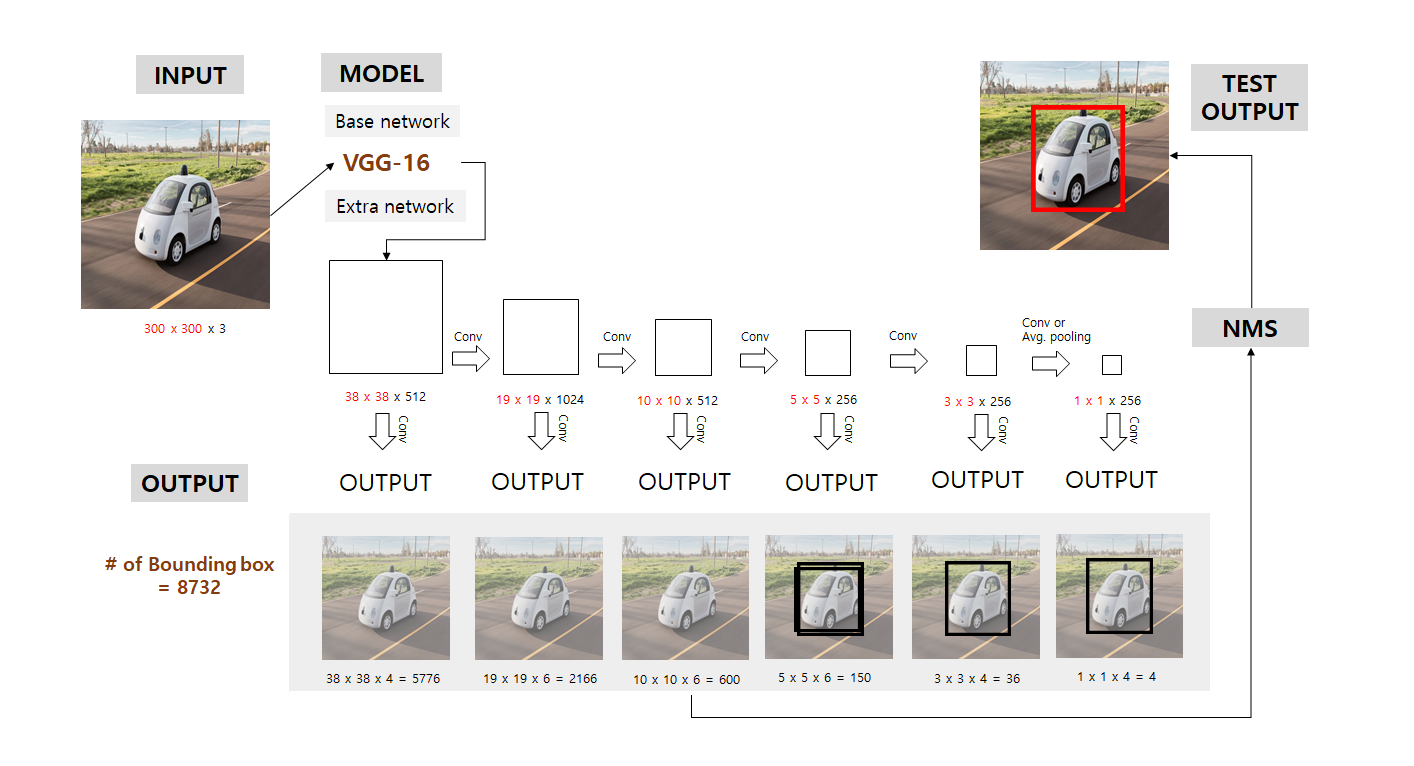
- 마지막으로 NMS를 통해 최종 detection 결과는 위 그림에서 우측 상단과 같음
Multi-scale feature maps for detection
- 38x38, 19x19, 10x10, 5x5, 3x3, 1x1 의 다양한 크기를 갖는 피쳐맵들을 의미
- Yolo는 7x7 grid 만을 이용했지만, SSD는 전체 이미지를 38x38, 19x19, 10x10, 5x5, 3x3, 1x1의 그리드로 나누고 이를 predictor layer와 연결하여 결과를 추론
- 큰 피쳐맵에서는 작은 물체 탐지, 작은 피쳐맵에서는 큰 물체 탐지 (뒤의 2.2 training 부분에서 더 자세히 다룸)
Convolutional predictors for detection
- 위에서 생성된 feature map은 3x3 kernel size stride=2 conv layer와 연결
- Feature map은 3x3xp size의 필터로 conv 연산.
- Yolo v1은 fc layer를 사용하여 x, y, w, h, score를 추론
- 예측된 결과는 x, y, w, h, score(offsets)를 의미
Default boxes and aspect ratios
- 각 feature map에 grid cell을 만들고(5x5와 같이..) default bounding box를 만들어 그 default box와 대응되는 자리에서 예측되는 박스의 offset과 per-class scores(여기서는 박스 안에 객체가 있는지 없는지를 예측)를 예측
- 이 때 per-class scores를 클래스 확률로 생각하면 안되고, 해당 박스 안에 객체가 있는지 없는지를 나타내는 값이라고 생각해야 하며 자세한것은 뒤쪽의 matching strategy에서 설명
- 6개의 feature map(마지막 prediction layer와 연결된 feature map)은 각각 연산을 통해 conv(3*3*(#bbx*(c+offset))) 출력을 생성
- Output은 각 셀당 #bb 개의 bounding box를 예측
2.2 Training
- SSD 모델의 학습에 제대로된 이해를 하기 위해서는 predicted box와 default box가 정확히 구분되어야 하며, Fast R-CNN 논문의 anchor box와 loss function 부분의 이해가 필요함
- 위 모델에서 5x5 크기의 feature map 부분만 따로 떼서 고려해보자.
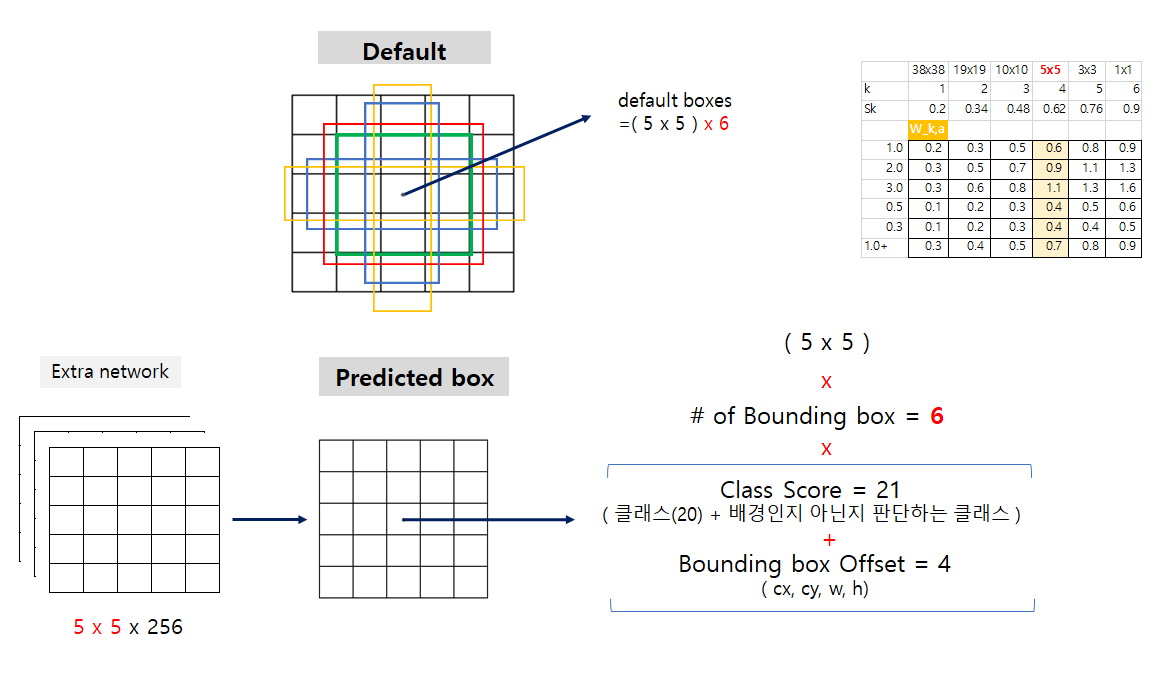
Ground Truth Box: 우리가 예측해야 하는 정답 박스Predicted Box: Extra Network에서 만들어진 5x5 크기의 feature map에서 output(predicted box) 생성을 위해 conv 연산을 하면 총 5x5x(6x(21+4))개의 값이 생성됨. (= Grid cell x Grid cell x (# of bb x (class + offset)))Default Box: 5x5 feature map은 각 셀당 6개의 default box를 갖고있다. (위 그림 참조)) 여기서 default box의 w, h는 feature map의 scale에 따라 서로 다른 S 값(scale factor)과 서로 다른 aspect ratio인 a 값을 이용해 얻어진다. 또, default box의 cx와 cy는 feature map size와 index에 따라 결정된다.- 먼저, default box와 ground truth box간의 IoU를 계산해 0.5 이상인 값들은 1(Positive), 아닌 값들은 0으로 할당한다.
- 이는 아래서 x에 해당하는 값임
- 예를 들어, 위 그림과 같이 5x5의 feature map의 13번째 셀(정 중앙)에서 총 6개의 default box와 predicted bounding box가 있는데, 같은 순서로 매칭되어 loss를 계산한다. 이는 아래의 loss function을 보면 더 쉽게 이해가 가능하다.
- 매칭된 (x=1, positive) default box와 같은 순서의 predicted bounding box에 대해서만 offset에 대한 loss가 update된다.
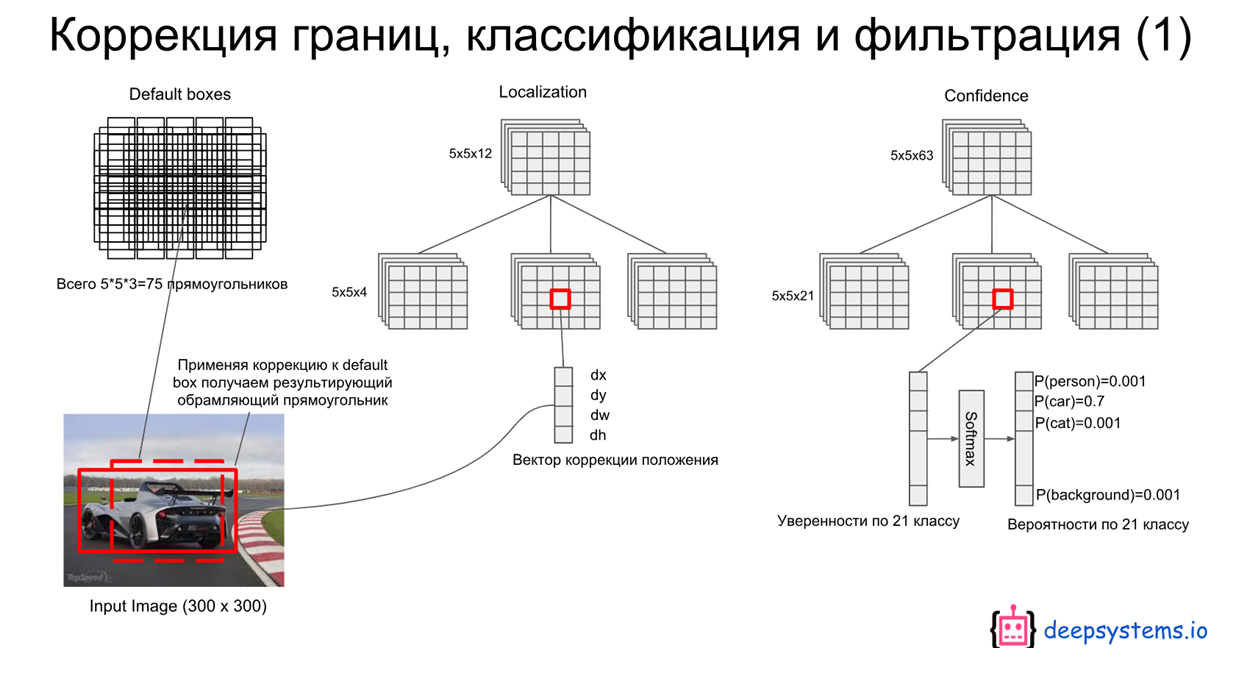
- 위 그림에서 빨간색 점선이 matching된 default box라고 한다면, 거기에 해당하는 cell의 같은 순서의 predicted bounding box의 offset만 update되고 최종적으로는 아래와 같이 predicted된다.

Matching strategy
- Ground truth와 ‘default box’를 미리 매칭 시킴
- 두 영역의 IoU가 0.5 이상인 것들을 match
Training objective
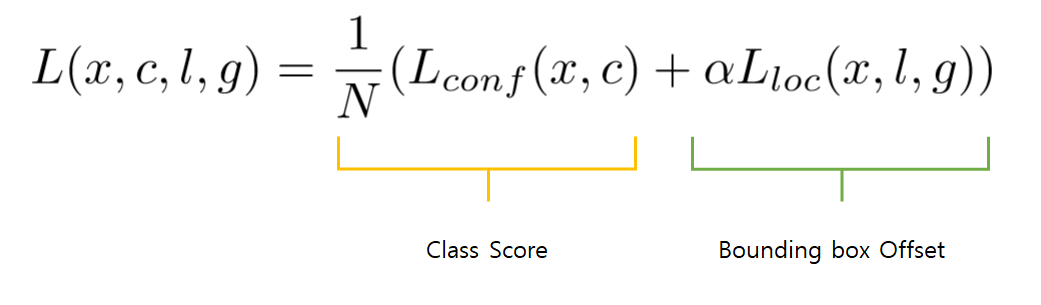
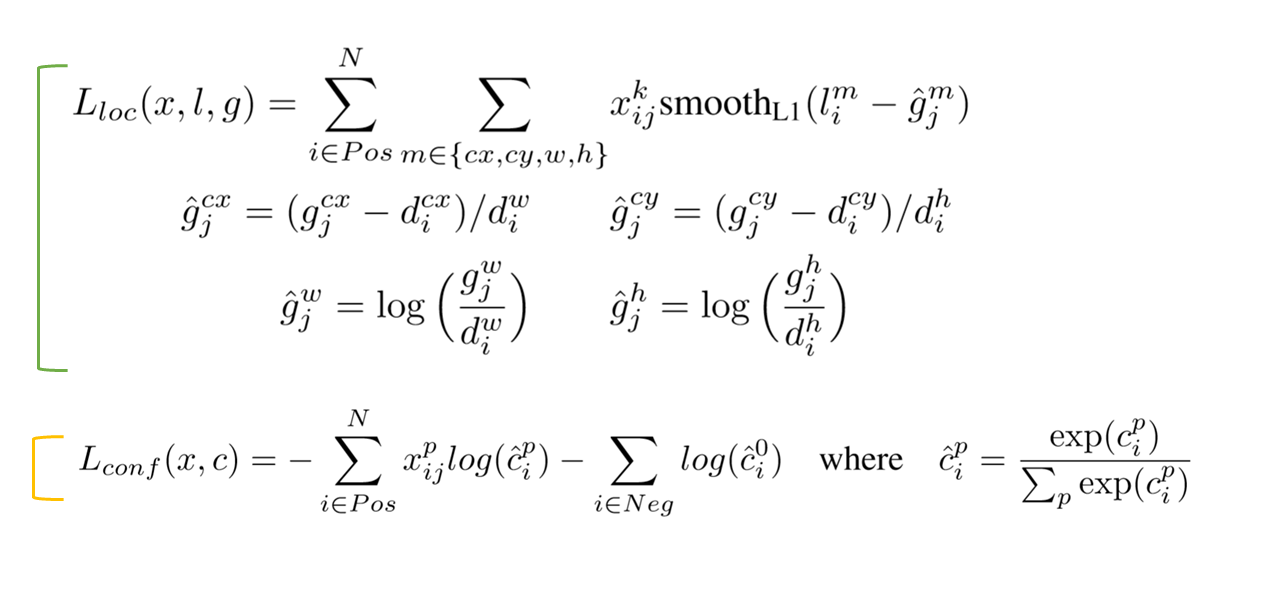
- 용어정리
- $x_{ij}^{p}={1,0}$: i 번째 default box와 j 번째 ground truth 박스의 category p에대한 물체 인식 지표. p라는 물체의 j 번째 ground truth와 i번째 default box간의 IoU가 0.5 이상이면 1, 아니면 0으로 정의됨
- $N$: Number of matched default boxes
- $l$: Predicted box (예측된 상자)
- $g$: Ground truth box
- $d$: Default box
- $cx, cy$: 해당 박스의 x, y좌표
- $w, h$: 해당 박스의 width, heigth
- $\alpha$: 교차검증으로부터 얻어진 값($\alpha = 1$)
- Loss fucntion 은 크게 2부분으로 클래스 점수에 대한 loss와 바운딩 박스의 offset에 대한 loss로 나뉨
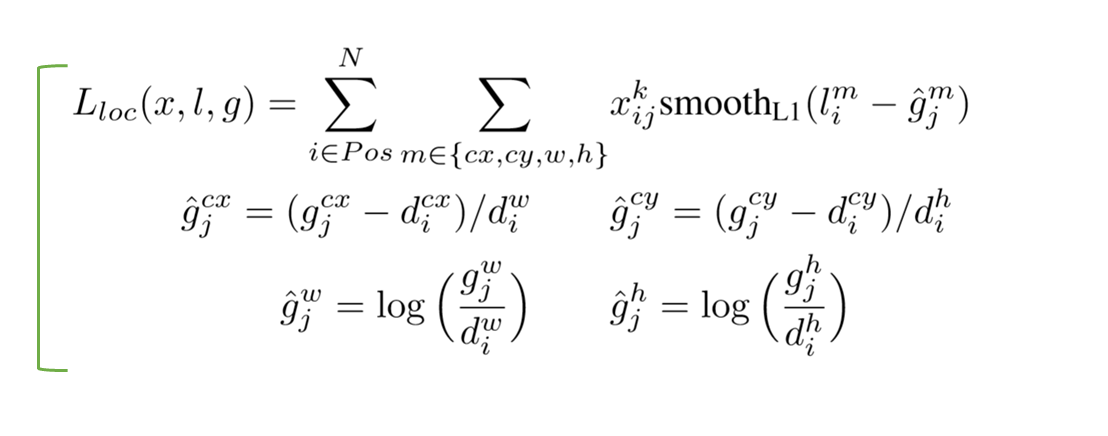
- 우리가 예측해야할 predicted box의 $l_{i}^{m}(cx,cy,w,h)$값들은 특이한 $\hat{g}$ 값들을 예측
- 이때 $\hat{g}$의 cx, cy는 default box의 cx, cy와 w, h로 normalize됨
- 이미 IOU가 0.5 이상만 된 것 부분에서 고려하므로, 상대적으로 크지 않은 값들을 예측해야하고 더불어 이미 0.5 이상 고려된 부분에서 출발하므로 비교적 빨리 수렴할 수 있을 것 으로 예상
- 초기값은 default box에서 시작하며 $\hat{g}$의 w, h도 마찬가지
- 예측된 l 값들을 box를 표현할때(마지막 Test Output) 역시 default box의 offset 정보가 필요
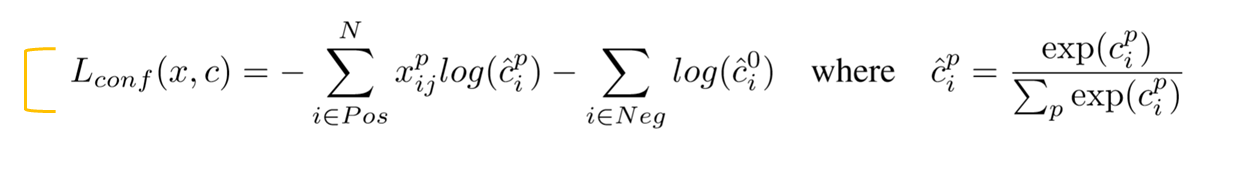
- Positive(매칭된) class에 대해서는 softmax
- Negative(매칭되지 않음) class를 예측하는 값은 $\hat{c}_{i}^{0}$ 이고, background이면 1, 아니면 0의 값을 가짐
- 최종적인 predicted class scores는 예측할 class + 배경 class를 나타내는 지표
Choosing scales and aspect ratios for default boxes
- Default box를 위한 scale. 여러 크기의 default box 생성을 위해 아래와 같은 식을 만듦.
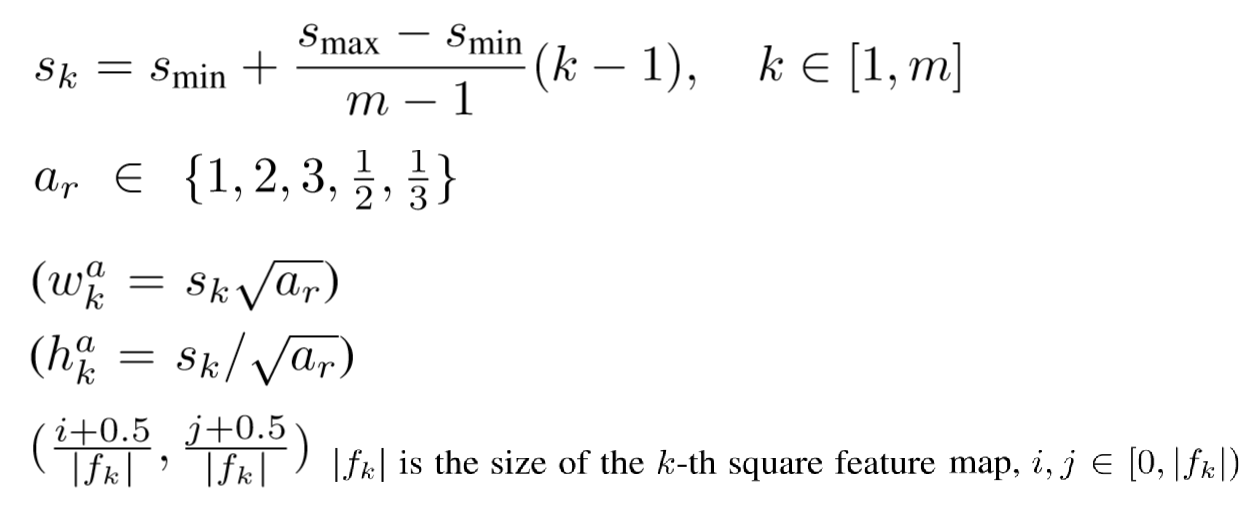
- $S_{min} = 0.2$, $S_{max} = 0.9$
- 위 식에다 넣으면 각 feature map당 서로 다른 6개의 s 값들(scale 값들)이 나옴
- 여기에 aspect ratio = {1,2,3,1/2,1/3} 로 설정
- Default box의 width는 $s_{k} x \sqrt{a_{r}}$
- $a_r = 1$ 일경우 $s_k = \sqrt{s_k \times s_{k+1}}$
- Default box의 cx, cy는 k번째 feature map의 크기를 나눠 사용
- 대략 예측되는 상자가 정사각형이나, 가로로 조금 길쭉한 상자 세로로 조금 길쭉한 상자이니 2,3으로 임의로 정해도 잘 학습이 될테지만, 특이한 경우, 예를들어 가로 방향으로 걸어가는 지네같은 경우 위의 비율로하면 0.5 threshold로 지정했을때 학습되지 않음.
- 학습할 이미지에 따라 aspect ratio를 조정해야할 필요가 있을텐데, 임의로 정한다면 비효율적이므로 knn 같은 알고리즘을 활용하면 더 좋을 것으로 예상
Hard negative mining
- 대부분의 default box가 배경이므로 $x_{ij}^{p}=0$인 경우가 많음
- 따라서 마지막 class loss 부분에서 positive:negative 비율을 1:3으로 정하여 출력(high confidence 순으로 정렬하여 상위만 가져다 씀)
Data augmentation
- 전체 이미지 사용
- 물체와 최소 IoU가 0.1, 0.3, 0.5, 0.7, 0.9가 되도록 패치 샘플
- 랜덤 샘플링하여 패치를 구함
Experimental Results
- PASCAL VOC, MS COCO에 대해서 1-stage detector중 속도, 정확도 성능이 최고
Discussion
- 속도, 정확도 면에서 SOTA의 성능을 내는데는 아래와 같은 이유일것이라고 추측됨
- Output layer로 FC layer 대신 Conv를 사용하여 weight 수 줄이고 속도 향상
- 여러 feature map을 이용해 한 이미지를 다양한 grid로 접근하여 다양한 크기의 물체들을 detect 할 수 있게함
- Default box 사용은 weight initialize와 normalize 효과를 동시에 가져올 수 있음
- 하나의 grid cell당 6개의 bounding box를 통해 겹치는 좌표의 다양한 물체 detect 가능
- 한계점
- 여러개의 feature map 의 detection을 다 계산하므로 computation cost가 커질 수 있음
- default box의 scale이나 aspect ratio는 비과학적. 비교적 쉽게 예측되는 ratio 외에 특이한 ratio를 가진 물체는 예측할 수 없음.
- 구조적 특성상 작은 객체를 탐지하는 feature map에 feature extractor의 앞단에서 가져와지므로 이로인한 작은 객체의 탐지율이 낮을것으로 예상