
 Seongkyun Han's blog
Seongkyun Han's blog
Rethinking the Inception Architecture for Computer Vision (Inception v2, v3)
05 Jul 2019 | Deep learningRethinking the Inception Architecture for Computer Vision (Inception v2, v3)
Original paper: https://arxiv.org/pdf/1512.00567.pdf
Authors: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna
- 참고 글
- https://norman3.github.io/papers/docs/google_inception.html
Inception v2/v3
- ILSVRC 2014에서 우승한건 GoogLeNet이지만 실제론 VGG 모델을 많이 사용
- VGG는 연산량도 많고 AlexNet에 비해 파라미터수가 3배가 많음에도 불구하고 많이 사용됨
- 간단하고 직관적인 구조로 응용이 쉽기 때문
- 따라서 VGG와 같이 3x3 conv filter만 사용하도록 하는 모델을 제안하려 함
Neural-Net 디자인 원칙
- (1) Avoid representational bottlenecks, especially early in the network
- (2) Higher dimensional representations are easier to process locally within a network.
- (3) Spatial aggregation can be done over lower dimensinal embeddings without much or any loss in representational power
- (4) Balance the width and depth of the network.
더 작은 단위의 conv를 사용
- Convolution factorization
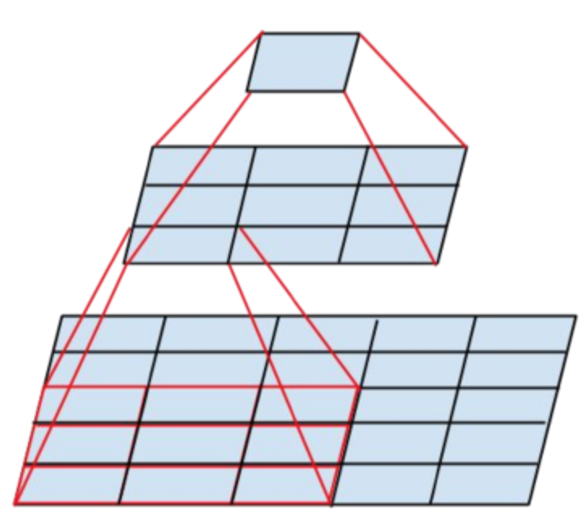
- 5x5 크기의 conv도 연산량이 많으므로 이걸 3x3 conv 2개로 바꾸면
- 5x5 : 3x3 = 25 : 9 (25/9=2.78 times)
- 5x5 conv 연산 한번은 3x3 conv보다 2.78배의 비용이 소모됨
- 만약 크기가 같은 2개의 layer를 하나의 5x5로 변환하는 것과 3x3 2개로 처리하는것 사이의 비용을 계산해보면
- 5x5xN : (3x3xN) + (3x3xN) = 25 : 9+9 = 25 : 18 (약 28% 의 reduction 효과
- 이를 기존의 inception module에 적용하면
- 5x5 : 3x3 = 25 : 9 (25/9=2.78 times)
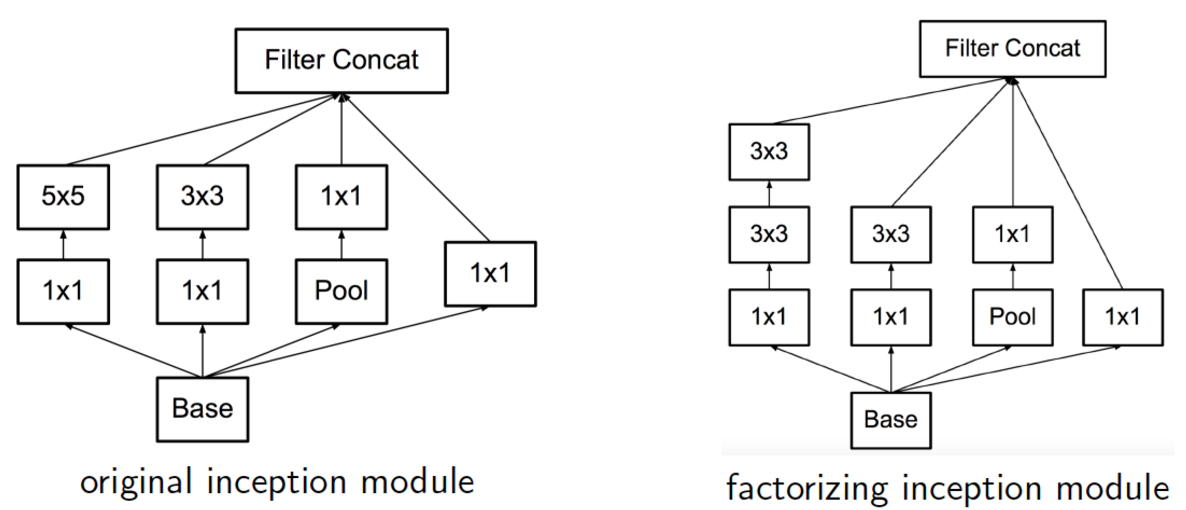
- 이런 모델로 변경했을 때의 의문점들
- 새롭게 설계한 모듈의 결과가 loss 계산에 영향을 주는가?
- conv를 두개로 나누게되면 첫번째 conv에서 사용하는 activation 함수는 뭘 사용해야하는가?
- 실험적으로 결과가 좋음
- 성능에는 문제가 없으며
- Activation은 ReLU, linear 모두 실험해봤지만 ReLU의 결과가 약간 더 좋음
- 그렇다면 위 모듈이 inception v2 module인가?
- 그렇진 않고, 이 뒤에서 소개될 이런 잡다한 기술 몇 개를 묶어 Inception v2로 명명
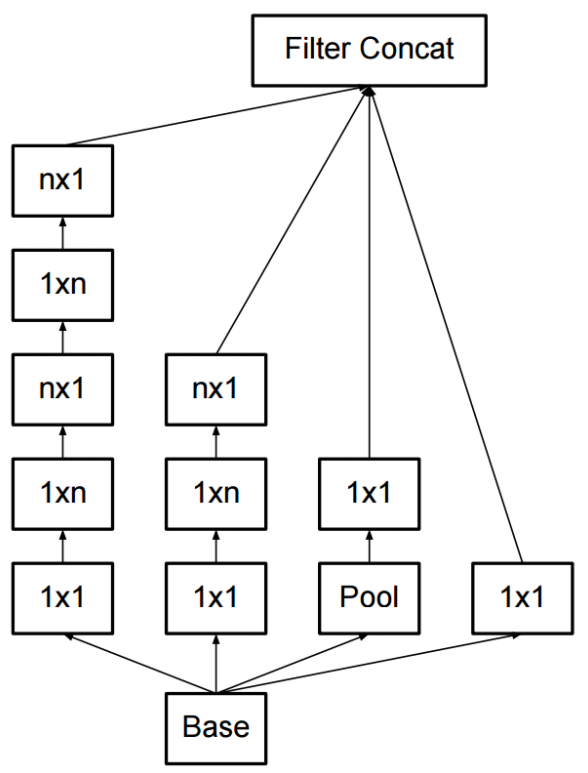
비대칭(asymmetric) conv를 사용한 factorization
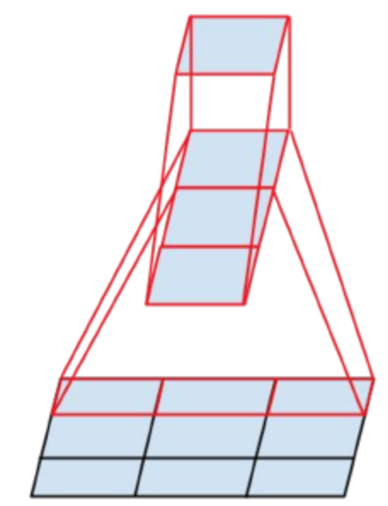
- 마찬가지로 연산량을 줄이면서 conv를 할 수 있는 꼼수 기법중 하나
- 일반적으로 NxN 형태로 conv를 수행하게되는데, 이를 1xN과 Nx1로 factorization 하는 기법
- 계산을 해보면 연산량이 33% 줄어듦
보조 분류기 (Auxiliary Classifier)
- 앞서 inception v1에서는 맨 마지막 softmax 말고도 추가로 2개의 보조 softmax를 사용했었음
- Backprop시 weight 갱신을 더 잘하게 하도록
- 이 중 맨 하단 분류기는 삭제. 실험을 통해 영향력이 없는것을 확인했음.
효율적인 grid 크기 줄이기
- CNN은 feature map의 grid 크기를 줄여가는 과정을 max-pooling을 이용함
- 언제나 conv와 함께 pooling을 사용
- 그럼 어떤걸 먼저 해야 효율적인 grid 줄이기를 할 수 있을까?
- Pooling을 먼저할까 conv를 먼저할까? (최종적으로 얻어지는 feature map의 크기는 동일)
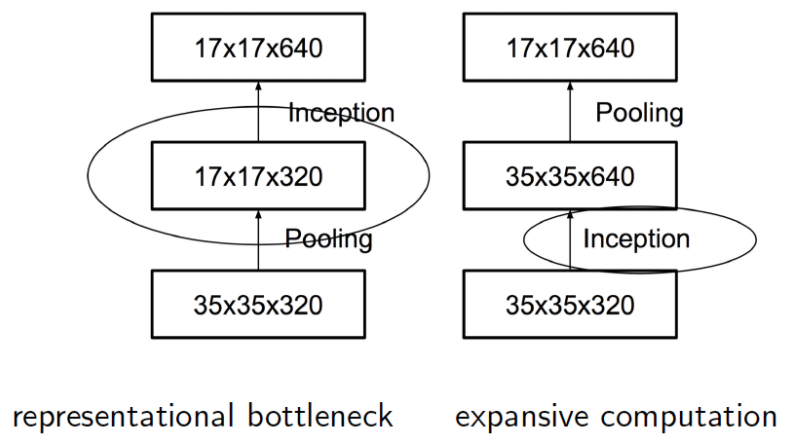
- 위 그림에서 왼쪽은 pooling 먼저, 우측은 conv를 먼저 하는것
- 결론부터 말하면 둘 다 별로다!
- Pooling을 먼저하면?
- 이 때는 representational bottleneck이 발생하게 됨
- 즉, pooling으로 인한 정보손실이 먼저 발생한 후 conv에 의한 feature가 얻어지므로 좋지 못한 구조
- 예제로 드는 연산은 $(d,d,k)$ 를 $(d/2,d/2,2k)$ 로 변환하는 Conv 로 확인. (따라서 여기서는 $d=35, k=320$)
- 이렇게 할 경우 실제 연산량은
- pooling + stride.1 conv with 2k filter => $2(d/2)^2 k^2$
- strid.1 conv with 2k fileter + pooling => $2d^2 k^2$
- 즉, pooling 먼저하면 연산량은 좀 더 작지만 representational bottleneck이 발생하고
- pooling을 나중에 하면 연산량은 2배가 됨
- 이렇게 할 경우 실제 연산량은
- 결론을 이야기하면
- 결국 둘 중 하나를 선택하지 못하면 섞이도록 하는 구조를 고안
- 연산량을 낮추면서 representation bottleneck을 업새는 구조를 고안
- 결국 둘 중 하나를 선택하지 못하면 섞이도록 하는 구조를 고안
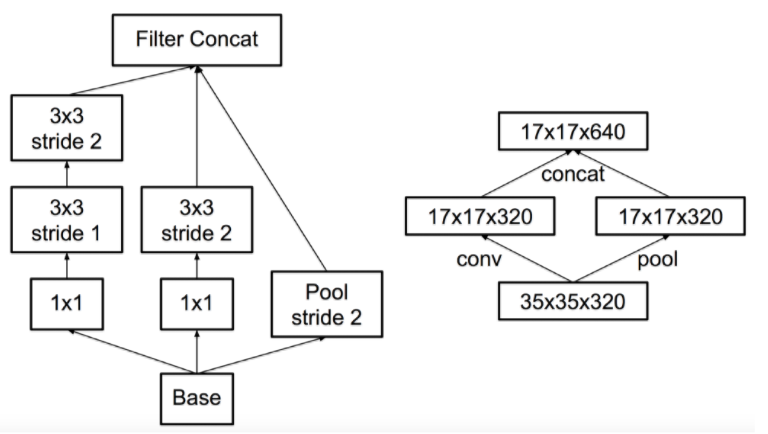
- 대단한 구조는 아니고, 두개를 병렬로 수행한 뒤 합치는것.(오른쪽 구조)
- 이러면 연산량은 좀 줄면서도 conv layer를 통해 representational bottleneck이 줄어들게 됨
- 이걸 대충 변경한 모델이 왼쪽의 모델이라고 생각하면 됨
Inception v2
- 지금까지 설명했던것들을 모으면 Inception v2 모델이 된다.(아래 그림)
- 아래 모델을 Inception v3로 알고 있는경우가 많은데 그 이유는 뒤에서 셜명됨
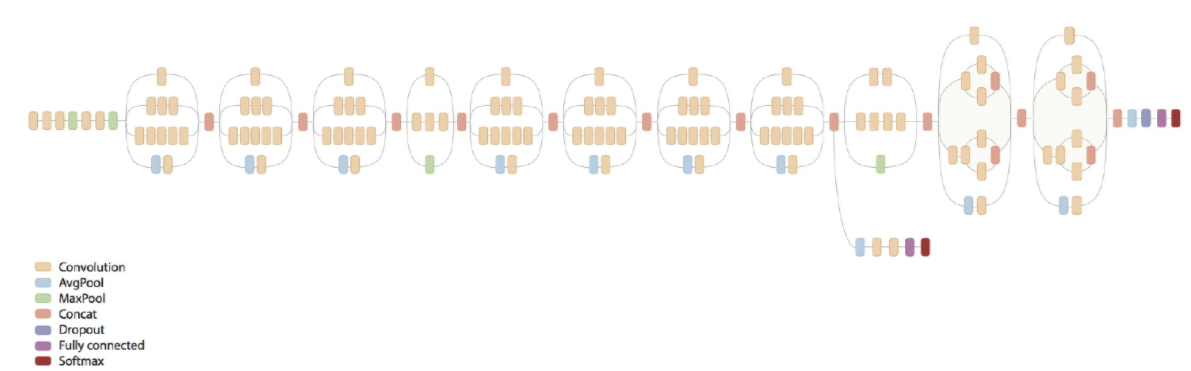
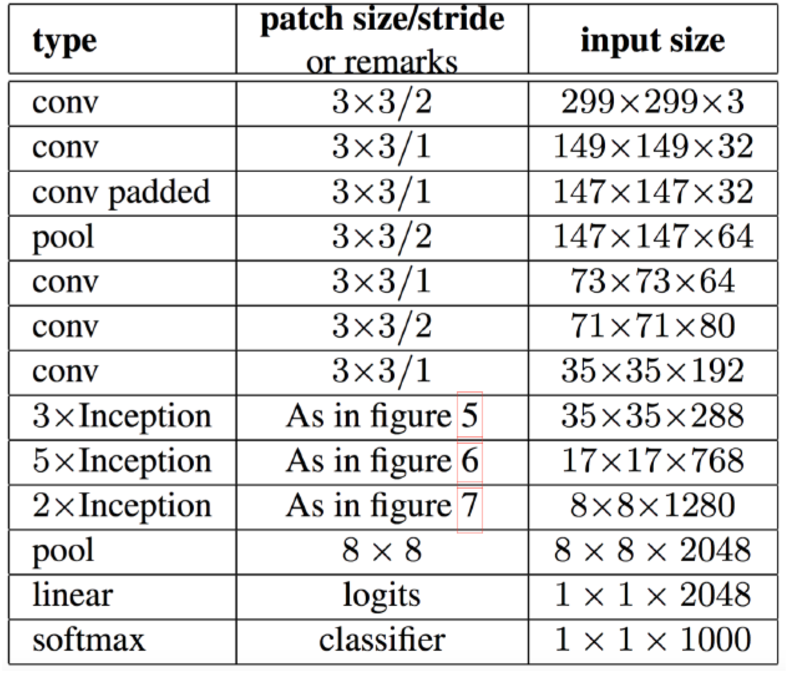
- 위 표를 잘 보면 레이어 앞단은 기존 conv layer들과 다를바 없음(stem layers)
- 중간부터는 앞에서 설명한 기본 inception layer들이 등장함
- 중간 아래에는 figure 5, 6, 7로 표기되어있으며, 이는 앞서 설명한 여러 기법들이 차례차례 적용된것
- 자세한 구조는 아래 그림 참고
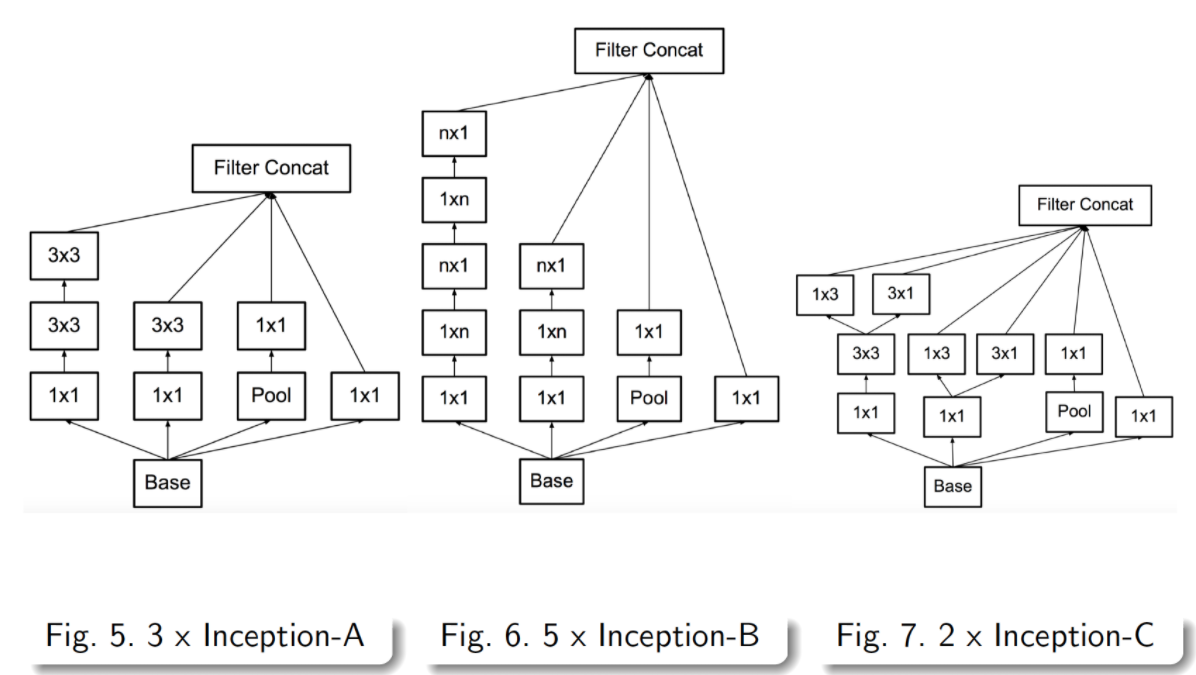
Inception v3
- Inception v3는 v2를 만들고 난 후 이를 이용해 이것저것 해보다가 결과가 더 좋은것들을 묶어 판올림한 모델
- 따라서 모델 구조는 바뀌지 않으므로 inception v2 구조를 그대로 inception v3라 생각해도 됨
- 사실 inception v3은 inception v2++ 정도로 봐도 무방…
- 간단하게 정확도로 결과를 확인하면 아래와 같음
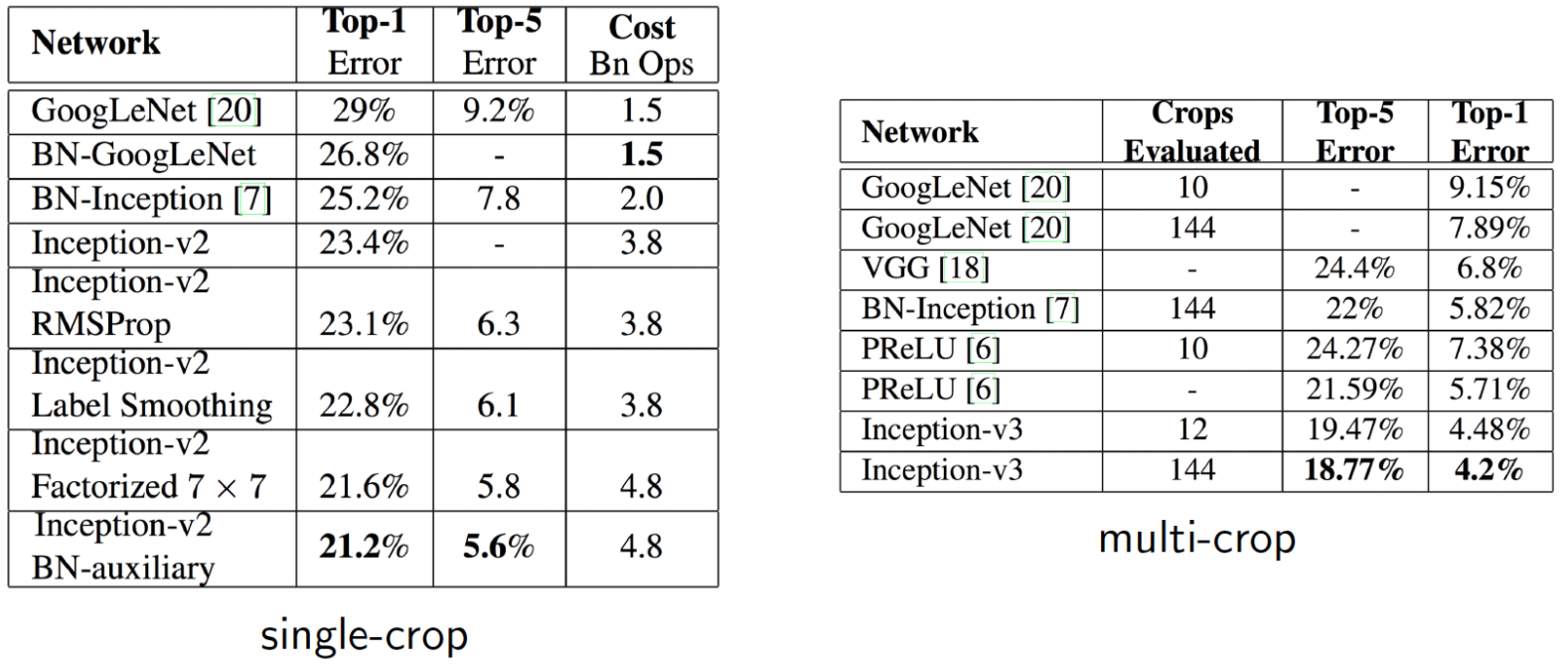
- 왼쪽의 표에서 inception v2 기본 버전의 top-1 error 값이 23.4%임을 확인 가능
- 여기에 각종 기능을 붙여본다.
- RMSProp: Optimizer를 바꾼다
- Label Smoothing
- 논문에 자세히 나오지만, 간단히 설명하면 target 값을 one-hot encode된 값을 사용하는것이 아니라 값이 0인 레이블에 대해서도 아주 작은 값 $e$을 배분하고, 정답은 대충 $1-(ㅜ-1)\times e$ 로 하여 반영하는것임
- Factorized 7x7
- 맨 앞단 conv 7x7 레이어를 3x3 레이어 두개로 factorization 한 것임(앞에서 설명된 내용)
- 그런데 inception v2 레이어 표를 보면 이미 적용되어있기는 함…
- BN-auxiliary
- 마지막 fully connected 레이어에 Batch Normalization(BN)을 적용
- 위의 것들을 모두 적용한게 Inception v3다.
- 최종 결과는 다음과 같음
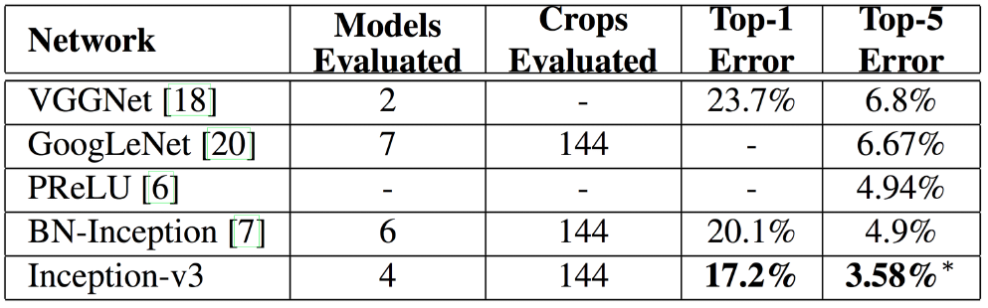
- 성능은 매우 좋다고 한다..
참고사항
- Pre-trained model로 주로 사용하는 모델은 inception v3이다.
- 하지만 논문에서 설명하는 inception v3과는 완벽히 일치하지 않는다
- 내부적으로도 버전 구분이 잘 되지 않아 날짜로 확인해야 한다고 한다..