
 Seongkyun Han's blog
Seongkyun Han's blog
Multi-Scale Context Aggregation by Dilated Convolutions
09 Jul 2019 | Deep learningMulti-Scale Context Aggregation by Dilated Convolutions
Original paper: http://vladlen.info/papers/dilated-convolutions.pdf
Authors: Fisher Yu, Vladlen Koltun
- 참고 글
- https://m.blog.naver.com/PostView.nhn?blogId=laonple&logNo=220991967450&proxyReferer=https%3A%2F%2Fwww.google.com%2F
- FCN(Fully Convolutional Network)에 대한 분석과 약간의 구조 변경을 통해 FCN의 성능을 좀 더 끌어올리게 할 수 있는 방법을 제시
- Dilated convolution
- 본 논문에서는 dilated convolution이라는 단어를 Fisher Yu의 segmentation 방법을 지칭하는것과 실제 dilation 개념이 적용된 convolution을 섞어서 표현함
Dilated convolution이란?
- Dilated convolution 자체는 Fisher Yu가 처음 언급한것이 아니라, FCN을 발표한 Jonathan Long의 논문에서 잠깐 언급이 있었고, FCN 개발자들은 dilated convolution 대신 skip layer와 upsampling 개념을 사용함
- 그 후 DeepLab의 논문 “Semantic image segmentation with deep convolutioonal nets and fully connected CRFs”에서 dilated convolution이 나오지만, Fisher Yu의 방법과 조금 다른 방법으로 사용
- Dilated convolution의 개념은 wavelet decomposition 알고리즘에서 “Atrous algorithm” 이라는 이름으로 사용되었으며, DeepLab 팀은 구별하여 부르기 위해 atrous convolution이라고 불렀는데, Fisher Yu는 이를 dilated convolution이라고 불렀으며 주로 이렇게 표현됨
- 참고로 atrous는 프랑스어로 a trous고 trous는 hole(구멍)의 의미를 갖음.
- Dilated convolution이란 아래 그림처럼 기본적인 conv와 유사하지만 빨간색 점의 위치에 있는 픽셀들만 이용하여 conv 연산을 수행함
- 이렇게 하는 이유는 해상도의 손실 없이 receptive field의 크기를 확장할 수 있기 때문임
- Atrous convolution이라고 불리는 이유는 전체 receptive field에서 빨간색 점의 위치만 계수가 존재하고, 나머지는 모두 0으로 채워지기 때문임
- 아래 그림에서 (a)는 1-dilated convolution이며 이는 흔히 알고있는 convolution과 동일함.
- (b)는 2-dilated convolution이며, 빨간 점들의 값만 conv 연산에서 참조되어 사용되고 나머지는 0으로 채워짐.
- 이렇게 되면 receptive field의 크기는 7x7 영역으로 커지게 됨(연산량의 증가 없이 RF가 커짐)
- (c)는 4-dilated convolution이며, receptive field의 크기는 15x15로 커지게 됨
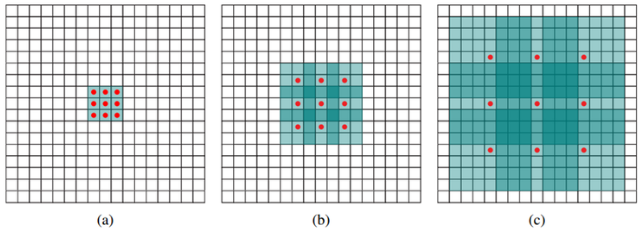
- Dilated conv를 사용하여 얻을 수 있는 이점이 큰 receptive field(RF)를 취하려면 일반적으로 파라미터의 개수가 많아야 하지만(large kernel size conv를 사용 후 pooling해야함) dilated convolution을 사용하면 receptive field는 커지지만 파라미터의 개수는 늘어나지 않기에 연산량 관점에서 탁월한 효과를 얻을 수 있음
- 위 그림의 (b)에서 RF는 7x7이기 때문에 normal filter로 구현 시 필터의 파라미터 개수는 49개가 필요하며, conv 연산이 CNN에서 가장 많은 연산량을 차지한다는점을 고려한다면 이는 부담이 상당한 연산이 됨
- 하지만 dilated conv를 사용하면 49개의 파라미터중 빨간점에 해당하는 9개의 파라미터만 사용하고 나머지 값 40개는 모두 0으로 처리되어 연산량 부담이 3x3 filter 처리량과 같아지게 됨
Dilated convolution을 하면 좋은점
- 우선 RF의 크기가 커지게 된다는 점이며, dilation 계수 조절 시 다양한 scale에 대한 대응이 가능해짐.
- 다양한 scale에서의 정보를 끄집어내려면 넓은 receptive field를 볼 수 있어야 하는데, dilated conv를 사용하면 별 어려움이 없이 이것이 가능해짐
- 기존의 일반적인 CNN에서는 RF의 확장을 위해 pooling layer를 통해 feature map의 크기를 줄인 후 convolution 연산을 수행하는 방식으로 계산
- 기본적으로 pooling을 통해 크기가 줄었기에 동일한 크기의 filter를 사용하더라도 CNN망의 뒷단으로 갈수록 넓은 RF를 커버할 수 있게 됨
- Fisher Yu의 논문에서는 자세하게 설명하지 않았기에 아래의 DeepLab 논문 그림을 참조하여 이해하면 이해가 훨씬 쉬워짐
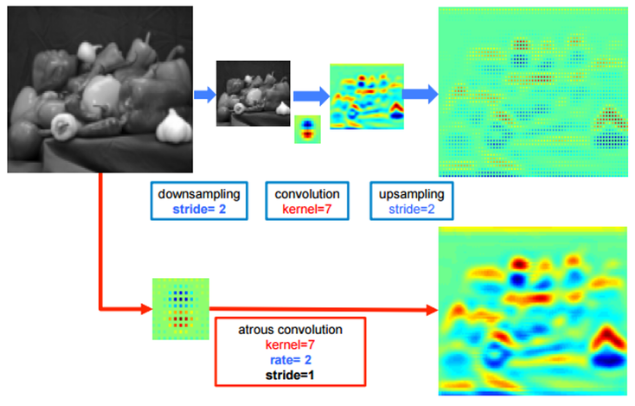
- 그림에서 위쪽은 앞서 설명한 것처럼 down-sampling(pooling) 후 conv를 통해 large RF를 갖는 feature map을 얻고, 이를 이용해 픽셀 단위 예측을 하기위해 다시 up-sampling을 통해 영상의 크기를 키운 결과임
- 아래는 dilated convolution(atrous conv)을 통해 얻은 결과
- Fisher Yu는 context module이라는것을 개발하여 segmentation의 성능을 끌어 올렸으며, 여기에 dilated convoluton을 적용함
Front-end 모듈
- FCN이 VGG16 classification 모델을 거의 그대로 사용한 반면 논문에서는 성능 분석을 통해 모델을 수정함
- VGG16의 뒷단을 그대로 사용하였지만 오히려 크게 도움이 되지 않아 뒷부분을 아래처럼 수정했다고 함
- 먼저 pool4, 5는 제거함. FCN은 이를 그대로 두었기에 feature map의 크기가 1/32까지 작아지고 이로 인해 좀 더 해상도가 높은 pool4, 3의 결과를 사용하기 위해 skip layer라는 것을 포함시킴
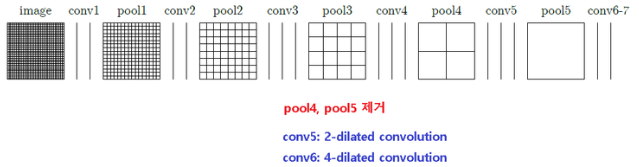
- 하지만 Fisher Yu는 pool4와 pool5를 제거함으로써 최종 featue map의 크기는 원영상의 1/8수준으로만 작아지게 하였고 이로인해 up-sample을 통한 원영상 크기로의 복원 과정에서도 상당한 detail 정보들이 살아있게 됨
- 또한 conv5, 6(fc6)에는 일반적인 conv 사용하는 대신 conv5는 2-dilated conv를, conv6에는 4-dilated conv를 적용함
- 결과적으로 skip layer도 없고 망도 더 간단해졌기에 연산 측면에서는 훨씬 가벼워졌음
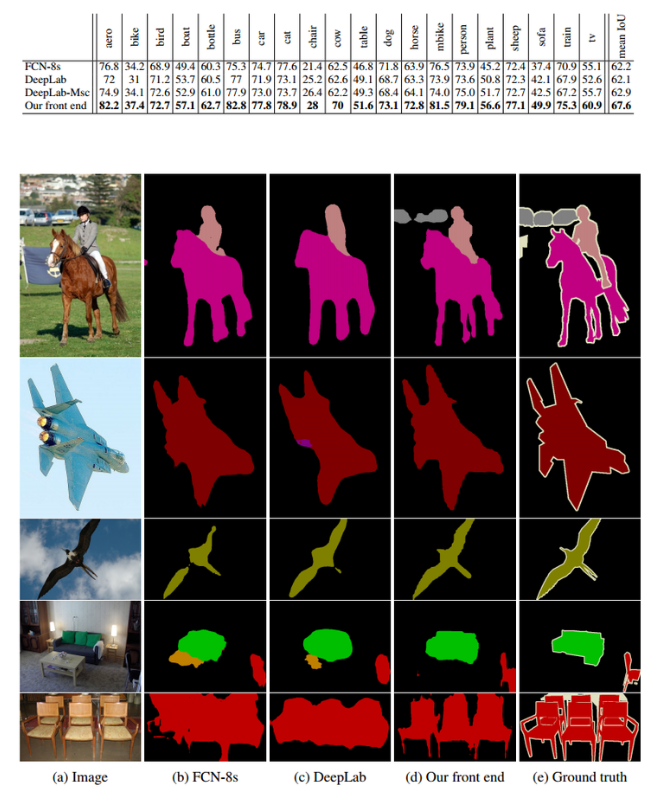
- 아래 표와 그림을 보면 front-end의 수정만으로도 이전 결과들보다 정밀도가 상당히 향상된 것을 확인 가능
- 아래 표와 그림에서 DeepLab은 dilated conv를 사용했지만 구조가 약간 다른 모델
Context 모듈
- Front-end 모듈뿐만 아니라 다중 scale의 context를 잘 추출해내기 위한 context 모듈도 개발했고, basic과 large 모듈이 있음
- Basic type은 feature map의 개수가 동일하지만 large type은 feature map의 개수가 늘었다가 최종단만 feature map의 개수가 원래의 개수와 같아지도록 구성됨
- Context 모듈은 기본적으로 어떤 망이든 적용이 가능할 수 있도록 설계되었으며 자신들의 front-end 모듈 뒤에 context 모듈을 배치함
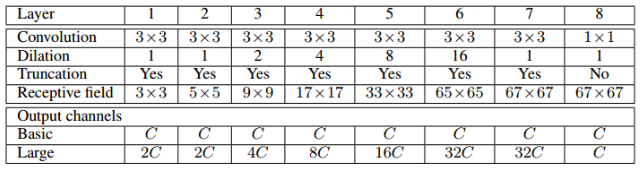
- Context 모듈의 구성은 아래 표와 간으며 전부 convolutional layer로만 구성됨
- 아래 표에서 C는 feature map의 개수를, dialteion은 dilated conv의 확장 계수(rate), convolution만으로 구성이 되었지만 뒷단으로 갈수록 RF의 크기가 커지도록 구성된것을 확인 가능함
- 표를 이해해보면, layer 1에서 3x3 conv, layer 2에서 3x3 conv가 되면 RF가 5x5가 되는것을 확인 할 수 있음
- 쉽게 생각해서 3x3 conv 두번 했을때 RF나 5x5 한번했을때 RF나 coverage가 동일해지는데 이런식으로 이해하면 됨
결과
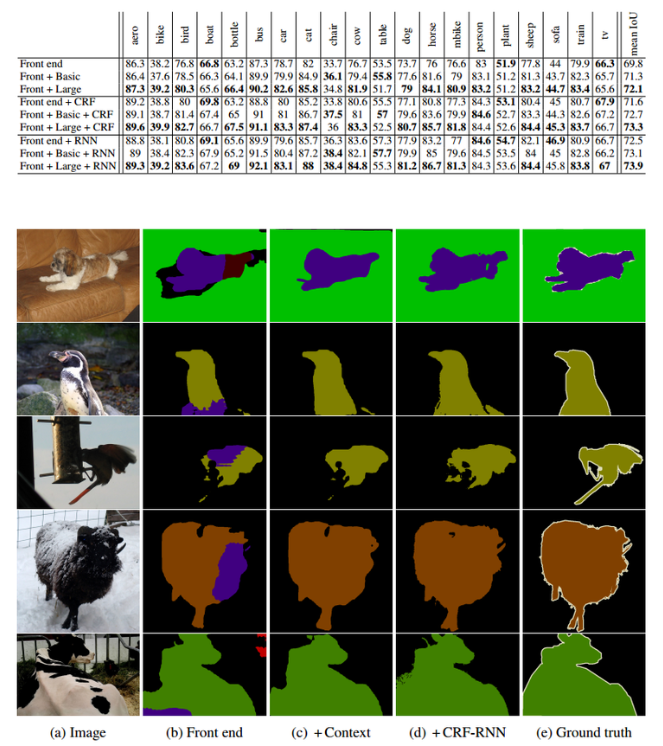
- Front-end 모듈만 적용해도 기존 segmentation 논문들보다 성능이 개선되었고, context 모듈을 추가하면 추가적인 성능의 개선이 있었으며 CRF-RNN까지 적용하면 더 좋아지는것을 알 수 있음
- 아래 표에서 front-end는 front-end 모듈만 있는 경우이고, basic/large는 context 모듈까지 적용된 경우이며 CRF는 CRF까지 적용된 경우, RNN은 CRF-RNN이 적용된 경우를 의미
결론
- 이 글에선 Fisher Yu의 dilated conv를 이용한 segmentation 방법에 대해 살폈음
- 이들은 FCN의 VGG16을 그대로 사용하지 않고 분석을 통해 뒷부분을 수정한 front-end 모듈을 만들어냄
- 또한 dilated convolution을 사용하여 망의 복잡도를 높이지 않으면서도 receptive field를 넓게 볼 수 있어 다양한 scale에 대응이 가능하게 함
- Receptive field는 필터가 한번에 보는 영역으로 feature를 잘 추출하기 위해선 receptive field가 넓을수록 좋다고 한다.
- 그리고 그 개념을 활용한 context 모듈까지 만들어 성능의 개선을 꾀함