
 Seongkyun Han's blog
Seongkyun Han's blog
DeepLab
10 Jul 2019 | Deep learningDeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Original paper: https://arxiv.org/pdf/1606.00915.pdf
Authors: Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille
- 참고 글
- https://laonple.blog.me/221000648527
- DeepLab에는 v1과 v2가 있지만, 본 글은 v2에 대해 다루며 앞으로 나오는 DeepLab은 모두 v2이다.
- 논문 제목에 다 나열되어있듯이 Deep convolutional neural networks(DCNN)와 astrous convolution 및 fully connected CRF 개념을 잘 활용해 semantic segmantation을 더 잘하게 되었다. 재미있는건 DeepLab v1에서는 hole algorithm이라는 용어를 사용했으나, v2부턴 atrous convolution으로 바꿔 부른다
Classification 기반 망을 semantic segmentation에 적용할 때의 문제점
- Classification이나 detection은 기본적으로 대상의 존재 여부에 집중하기에 object-centric하며, 강력한 성능을 발휘하기 위해선 여러 단계의 conv+pooling을 거쳐 말 그대로 영상 속에 존재하며 변화에 영향을 받지 않는(robust하게 영향을 덜 받는) 강인한 feature만을 끄집어내야 함
- 따라서 details보다는 global 한 것에 집중을해야 함
- 반면 semantic segmentation은 픽셀 단위의 조밀한 예측이 필요한데, classification 망을 기반으로 segmantation망을 구성하게 되면 계속 feature map의 크기가 줄어들기에 detail한 정보를 얻는데 어려움이 있음
- 그래서 FCN 개발자는 skip layer를 사용하여 1/8, 1/16, 1/32 결과를 결합(concat)하여 detail이 줄어드는 문제를 보강하였으며, DeepLab과 앞서 본 dilated convolution 팀(Fisher Yu)은 망의 뒷 단에 있는 2개의 pooling layer를 없애고 dilated conv(atrous conv)를 사용하여 receptive field를 확장시키는 효과를 얻었으며, 1/8 크기까지만 feature map을 줄이도록 하여 detail한 정보들을 보존함
- 하지만 1/8까지만 사용하더라도 다음과 같은 문제가 발생
- Receptive field가 충분히 크지 않아 다양한 scale에 대응이 어렵다
- 1/8크기의 정보를 bilinear interpolation을 통해 원 영상 크기로 키우면 1/32 크기를 확장한것보다는 details가 살아있지만 여전히 정교함이 떨어진다
- 이러한 문제를 DeepLab 팀과 dilated convolution 에서는 다른 방식으로 해결하였으며, dilated convolution 팀은 DeepLab 팀의 atrous conv에서 많은 힌트를 얻은 것으로 보여짐
Atrous convolution
- Atrous conv란 wavelet을 이용한 신호 분석에 사용되던 방식이며, 보다 넓은 scale을 보기 위해 중간에 hole(0)을 채워 넣고 convolution을 수행하는 것을 말함
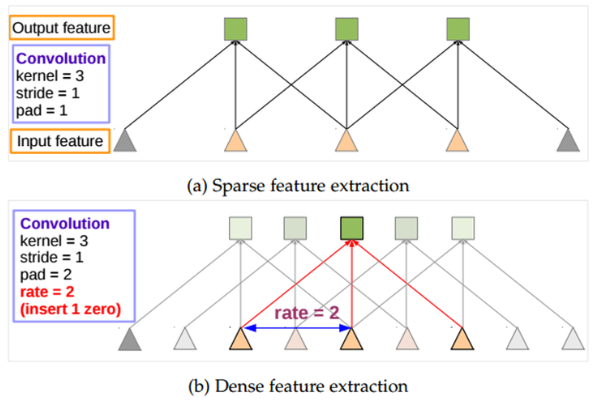
- 직관적인 이해를 위해 논문의 1차원 conv 그림을 살펴보면
- 위 그림 (a)는 기본적인 conv이며, 인접 데이터를 이용해 kernel size 3인 conv를 보여줌
- (b)는 확장 계수 k가 2인 경우로 인접한 데이터가 아닌 중간에 hole이 1개씩 들어오는 점이 (a)와 차이가 나며, 똑같은 kernel size 3이더라도 대응하는 영역의 크기가 커졌음을 확인 할 수 있음
- 이처럼 atrous conv(dilated conv)를 사용하면 kernel 크기는 동일히 유지하기에 연산량은 동일하지만 receptive field의 크기가 커지는 효과를 얻을 수 있음
- 영상 데이터와같은 2차원에 대해서도 아래와같이 좋은 효과가 있는것을 확인 할 수 있음
- 자세한 설명은 dilated convolution 참고
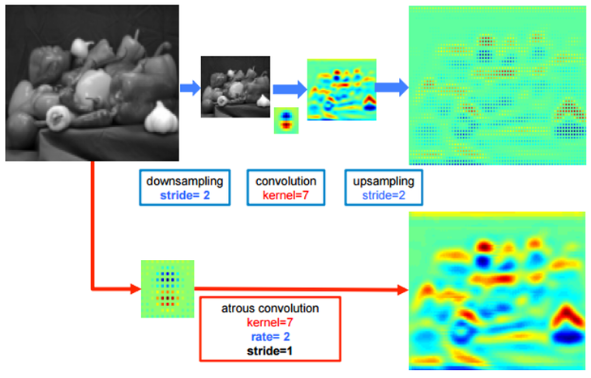
Atrous convolution 및 bilnear interpolation
- DeepLab v2에선 VGG16뿐만 아니라 ResNet101도 DCNN망으로 사용했으며, ResNet 구조를 변형시킨 모델을 이용해 VGG16모델보다 성능이 더 좋아짐
- DCNN에서 max-pooling layer 2개를 제거함으로 1/8 크기의 feature map을 얻고, atrous conv를 통해 넓은 RF를 갖도록 함
- Pooling 후 동일 크기의 conv를 수행하면 자연스럽게 RF가 넓어짐
- 논문에선 details때문에 pooling layer를 제거하였기에 이 부분을 atrous conv를 사용해 더 넓은 RF를 가질 수 있도록 하였으며, 이를 통해 pooling layer가 사라졌을때의 문제점들을 해소시킴
- 이후FCN이나 dilated conv와 마찬가지로 bilear interpolation을 이용해 원 영상 크기로 복원해냄(아래 그림 참고)
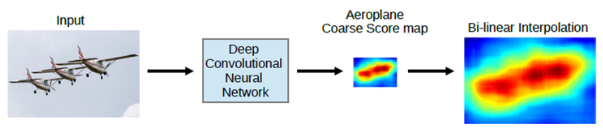
- Atrous conv는 RF 확대를 통해 입력에서 feature를 찾는 범위를 넓게 해주기 때문에 전체 영상으로 찾는 범위를 확대하면 좋겠지만, 이렇게 하려면 단계적으로 수행을 해야하기에 연산량 증가가 불가피함
- 그래서 이 팀은 적정한 선에서 deal을 했으며, 나머지는 모두 bilinear interpolation을 선택함
- 하지만 bilinear interpolation만으론 정확하게 객체의 픽셀 단위까지 위치를 정교히 segmentation하는게 불가능하므로 뒷부분은 CRF(Conditional Random Field)를 이용하여 post-processing을 수행하도록 함
- 결과적으로 전체적인 구조는 DCNN+CRF의 형태이며, DCNN의 앞부분은 일반적인 conv를, 뒷부분은 atrous conv를 이용했고 전체 구조는 아래와 같음
ASPP(Atrous Spatial Pyramid Pooling)
- DeepLab v1과 달리 v2에선 multi-scale에 더 강인하도록 fc6 layer에서의 atrous conv를 위한 확장 계수를 아래와같이 6, 12, 18, 24로 적용하고 그 결과를 취합(concat)하여 사용함
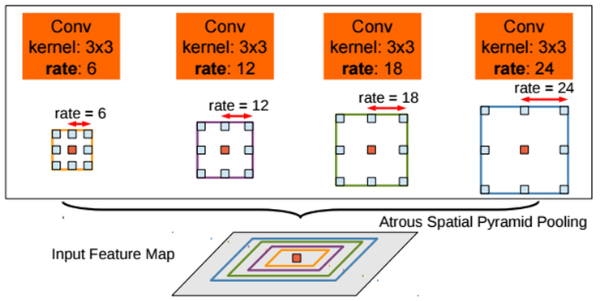
- ResNet 설계자인 Kaiming He의 SPPNet 논문에 나오는 Spatial Pyramid Pooling 기법에 영감을 받아 ASPP로 이름을 지었으며, 확장 계수를 6부터 24까지 다양하게 변화시켜 다양한 RF가 고려된 feature map을 생성할 수 있도록 함
- SPPNet에서의 방식처럼 이전 단계까지의 결과는 동일하게 사용을 하고, fc6 layer에서 atrous conv를 위한 확장계수 r 값만 다르게 적용시킨 후 그 결과를 합치게(concat) 되면 연산의 효율성 관점에서 큰 이득을 얻을 수 있음
- 참고로 구글의 inception 구조도 여러 RF의 결과를 같이 볼 수 있게 되어있음
- 논문 저자들의 실험에 따르면 단순히 확장계수 r을 12로 고정하는것보다 ASPP를 지원하여(다양하게 r을 변화시킨 후 그 feature map들을 합침) 1.7%가량의 성능 향상이 있었다고 함
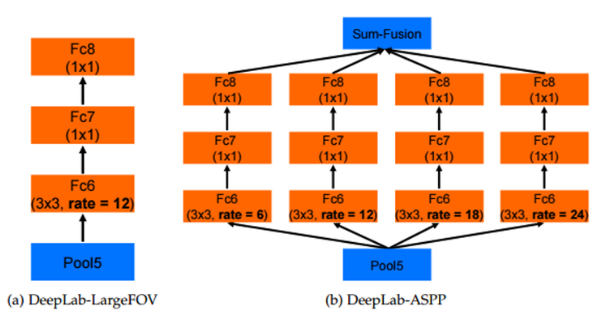
- 위 그림에서 (a)는 DeepLab v1의 구조이며 ASPP를 치원하지 않는 경우 fc6의 확장 계수를 12로 고정한 경우임
- (b)는 v2에서 fc6의 계수를 6, 12, 18, 24로 하여 ASPP를 수행하는 구조를 나타냄
- 성능은 아래 표와 같음
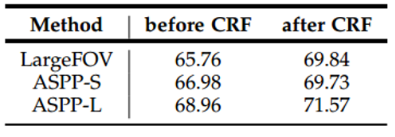
- 표에서 LargeFOV는 기존처럼 r=12로 고정한 경우이며, ASPP-S가 r이 2, 4, 8, 12로 좁은 RF만 커버하는 branch들을 사용한 경우, ASPP-L은 r이 6, 12, 18, 24로 넓은 RF를 커버하는 branch를 갖도록 ASPP를 수행한 경우임
- 실험에 사용한 네트워크는 VGG16이며 결과는 scale을 고정시키는것보다는 multi-scale을 사용했을때의 성능이 좋았고, 좁은 RF보단 넓은 RF를 갖는 branch들을 사용하는게 성능이 더 좋은것을 알 수 있음
Fully Connected CRF
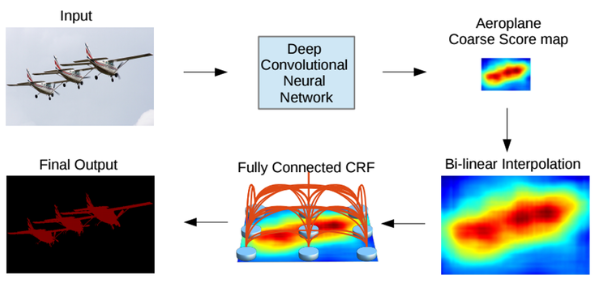
- 앞의 것들만 사용하더라도 FCN보다는 결과가 좋지만, 아래 그림처럼 CRF(Conditional Random Field)를 사용하는 후보정 작업을 해주면 결과가 더 좋아지는것을 확인 할 수 있음
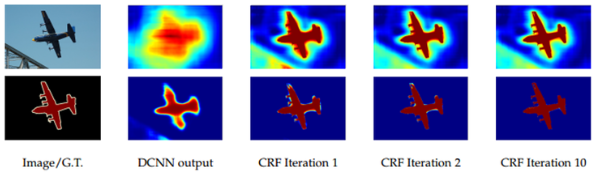
- 일반적으로 1/8크기 해상도를 갖는 DCNN 결과를 bilinear interpolation을 통해 원영상 크기로 확대하면 아래처럼 해상도가 떨어지는 문제가 있음
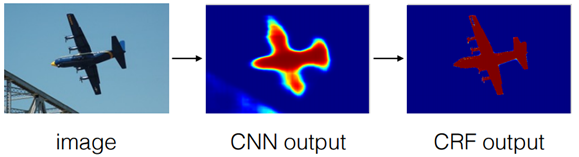
- DeepLab 구조에서는 이 문제 해결을 위해 CRF(Conditional Random Field)를 사용하는 후처리를 이용해 성능을 향상시킴
왜 CRF(Conditional Random Field)가 필요한가?
- Classification과 같이 object-centric한 경우 가능한 높은 수준의 공간적인 불변성(spatial invariance)를 얻기 위해 여러 단계의 conv+pooling을 통해 영상 속에 존재하며 변화에 영향을 크게 받지 않은 강인한 특징을 추출해야하며, 이로인해 detail한 정보보단 global한 정보에 집중하게 됨
- 반면 semantic segmenation은 픽셀 단위의 조밀한 예측이 필요해 classification 네트워크 기반으로 segmentation 망을 구상하게 된다면 계속 feature map의 크기가 줄어들게되는 특성상 detail한 정보들을 잃게 됨
- 이 문제에 대한 해결책으로 FCN에선 skip connection을 사용하였고, dilated conv나 DeepLab에서는 마지막에 오는 pooling layer 2개를 없애고 dilated/atrous conv를 사용함
- 하지만 이러한 방법을 사용하더라도 분명히 한계는 존재하기에 DeepLab에서는 atrous conv에 그치지 않고 CRF를 후처리 과정으로 사용하여 픽셀 단위 예측의 정확도를 더 높일 수 있게 됨
Fully Connected CRF
- 일반적으로 좁은 범위(short-range)의 CRF는 segmentation을 수행한 뒤 생기는 segmentation noise를 없애는 용도로 많이 사용됨
- 하지만 앞서 살펴본 것처럼 DCNN에서는 여러 단계 conv+pooling을 거치며 feature map의 크기가 작아지게 되고 이를 upsampling을 통해 원 영상 크기로 확대하기에 이미 충분히 smoothen되어있는 상태이며, 여기에 기존처럼 short-range CRF를 적용하면 결과가 더 나빠지게 됨
- Noise 성분도 같이 upsampling 되므로
- 이에 대한 해결책으로 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials (Philipp Karahenbuhl)라는 논문이 발표되었으며, 해당 논문에선 기존에 사용되던 short-range CRF대신 전체 픽셀을 모두 연결한 (fully connected) CRF 방법을 개발해 놀라운 성능향상을 얻어내었고 이 후 많은 사람들이 fully connected CRF를 후처리에서 사용하게 됨
- Fully connected CRF에 대한 설명은 아래에서 잘 설명되어 있음
- http://swoh.web.engr.illinois.edu/courses/IE598/handout/fall2016_slide15.pdf
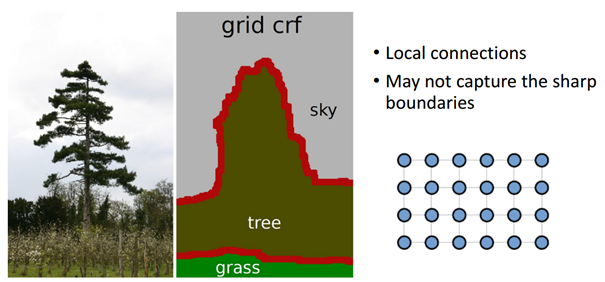
- 기존에 사용되던 short-range CRF는 아래 그림처럼 local connection 정보만을 사용함
- 이렇게되면 details 정보가 누락되게 됨
- 반면 fully connected CRF를 사용하면 아래처럼 detail 정보들이 살아있는 결과를 얻을 수 있음
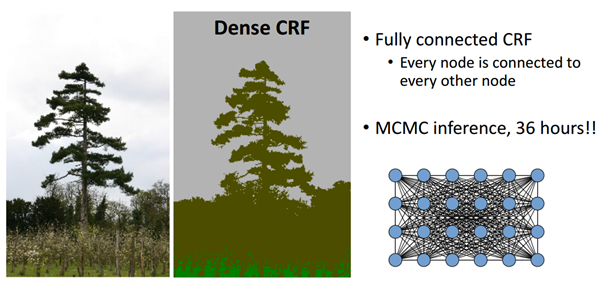
- 위처럼 MCMC(Markov Chain Monte Carlo) 방식을 사용할 경우 좋은 결과가 나오지만 연산량이 많다는 단점이 있어 적용이 불가했으나, Philipp Karahenbuhl의 논문에선 이를 0.2초만에 효과적으로 연산가능하게 함
- Philipp Karahenbuhl는 일명 mean field approximation 방법을 적용해 message passing을 사용한 iteration 방법을 적용하여 효과적으로 빠른 fully connected CRF를 수행 가능하도록 함
- 여기서 mean field approximation이란 물리학이나 확률이론에서 많이 사용되는 방법으로, 복잡한 모델을 설명하기 위해 더 간단한 모델을 선택하는 방식을 의미함. 수많은 변수들로 이루어진 복잡한 관계를 갖는 상황에서 특정 변수와 다른 변수들의 관계의 평균을 취하게 되면, 평균으로부터 변화(fluctuation)를 해석하는데도 용이하고, 평균으로 단순화/근사화된 모델을 사용하면 전체를 조망하기에 좋아짐
- CRF의 수식을 보면 unary term과 pairwise term으로 구성됨. 아래의 식에서 x는 각 픽셀의 위치에 해당하는 픽셀의 label이며, i와 j는 픽셀의 위치좌표를 나타냄. Unary term은 CNN 연산을통해 얻어질 수 있으며, 픽셀간의 detail한 예측에서 pairwise term이 중요한 역할을 함. Pairwise term에서는 마치 bi-lateral filter에서 그러듯이 픽셀값의 유사도와 위치적인 유사도를 함께 고려함

- 위 CRF 식을 보면, 2개의 가우시안 커널로 구성된 것을 볼 수 있으며 표준편차 $\rho_{\alpha}, \rho_{\beta}, \rho_{\gamma}$를 통해 scale을 조절 할 수 있음. 첫 번째 가우시안 커널은 비슷한 컬러를 갖는 픽셀들에 대해 비슷한 label이 붙을 수 있도록 하며, 두 번째 가우시안 커널은 원래 픽셀의 근접도에 따라 smooth 수준을 결정함. 위 식에서 $p_{i}, p_{j}$는 픽셀의 위치(position)를 나타내며 $I_{i}, I_{j}$는 픽셀의 컬러값(intensity)임
- 이것을 고속처리하기 위해 Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현 할 수 있게되어 고속 연산이 가능해짐
DeepLab의 동작 방식
- CRF까지 적용된 DeepLab의 최종 동작방식은 아래와 같음
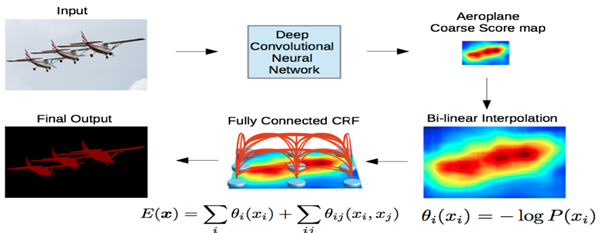
- DCNN을 통해 1/8 크기의 coarse score-map을 구하고, 이것을 bilinear interpolation을 통해 원영상 크기로 확대시킴. Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은 CRF의 unary term에 해당함. 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있음
DeepLab 최종 결과
- DeepLab v1은 VGG16 기반이며 ASPP가 적용되지 않음
- DeepLab v2의 경우 ResNet-101 기반이기에 아래 그림처럼 실험결과가 좋아진것을 볼 수 있음.
- CRF 적용 전 후 결과를 보면 CRF가 적용되었을 때 detail 정보가 상당히 개선된것을 알 수 있음.

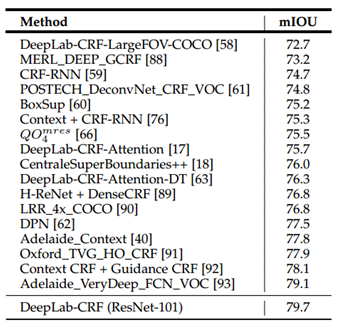
- 아래 표는 PASCAL VOC2012 데이터셋에 대한 실험결과인데, ResNet-101에 CRF를 적용하면 평균 IoU가 79.7%수준으로 매우 높다는것을 확인 할 수 있음
- 그 외에도 다양한 데이터를 바탕으로 실험한 결과 역시 매우 좋지만 자세한 결과는 논문 참조