
 Seongkyun Han's blog
Seongkyun Han's blog
CenterNet (Objects as Points)
28 Oct 2019 | Deep learningCenterNet (Objects as Points)
Original paper: https://arxiv.org/pdf/1904.07850v2.pdf
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi
- 참고 글
- https://nuggy875.tistory.com/34
- 코드
- https://github.com/xingyizhou/CenterNet
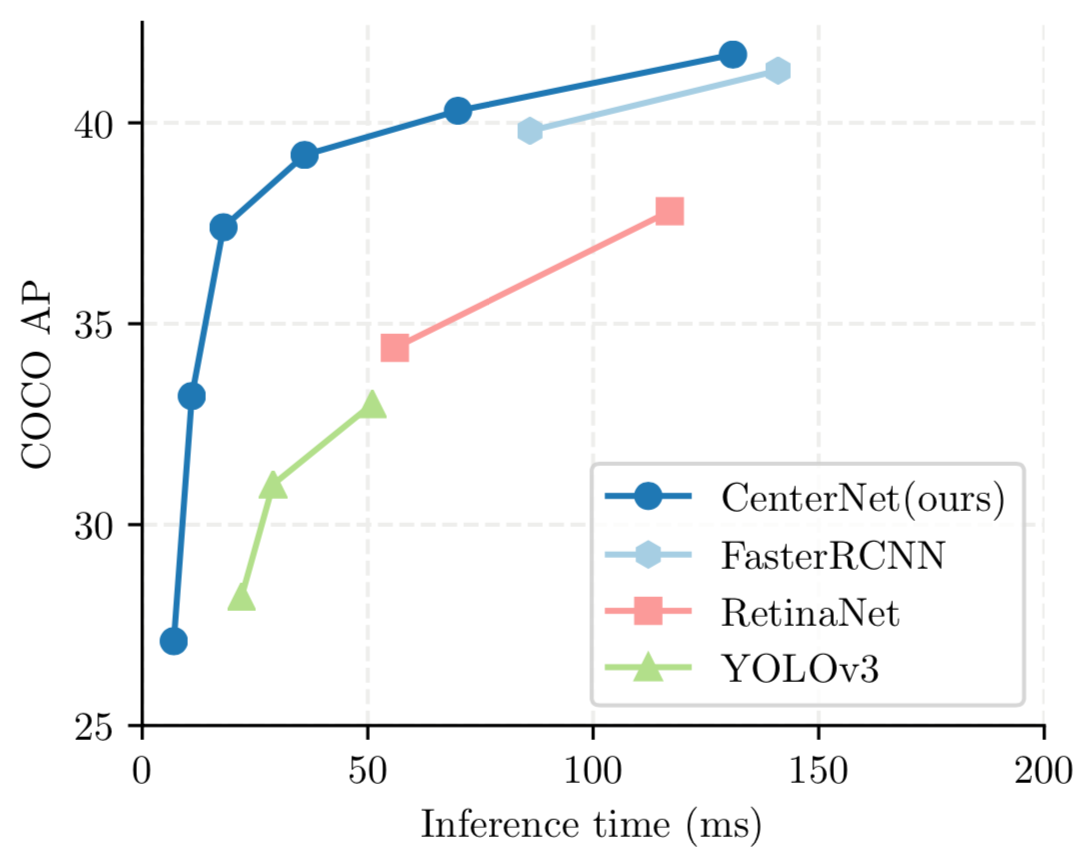
- 기존의 real-time object detection 모델들의 성능을 가볍게 제치는 single shot 방식의 detector
- CenterNet은 기존의 anchor box를 사용하는 single-stage detector인 SSD, YOLO와 비슷하지만 크게 다름
- CenterNet은 box overlap이 아닌, 오직 위치만 갖고 anchor를 할당
- CenterNet은 오직 한 크기의 anchor만을 사용
- CenterNet은 더 큰 output resolution을 갖음
- DSSD의 경우엔 40k가 넘는 anchor box를, RetinaNet에선 100k개가 넘는 anchor box들을 사용했음
- 이는 할당된 anchor box가 실제값(Grount-Truth box)과 충분히 겹처지도록 하기 위해서였음
- 이렇게 많은 anchor box를 사용하면 정확해지긴 하지만 positive anchor box와 negative anchor box 사이의 불균형이 발생
- 이로 인해 모델의 학습 속도가 느려짐
- 또한, anchor box의 aspect ratio를 결정해야 하는 등, 말 그대로 “비 논리적인” 결정과 hyperparameter를 설정해야 함
- Anchor box의 aspect ratio는 어떻게 보면 비 논리적인, 비 합리적이라고 생각 할 수 있음
- 단순히 해당 비율로 존재하는 객체만 찾도록 학습되어지므로 다양한 비율을 갖는 객체들을 찾는데에는 문제가 있음
- Anchor box의 aspect ratio는 어떻게 보면 비 논리적인, 비 합리적이라고 생각 할 수 있음
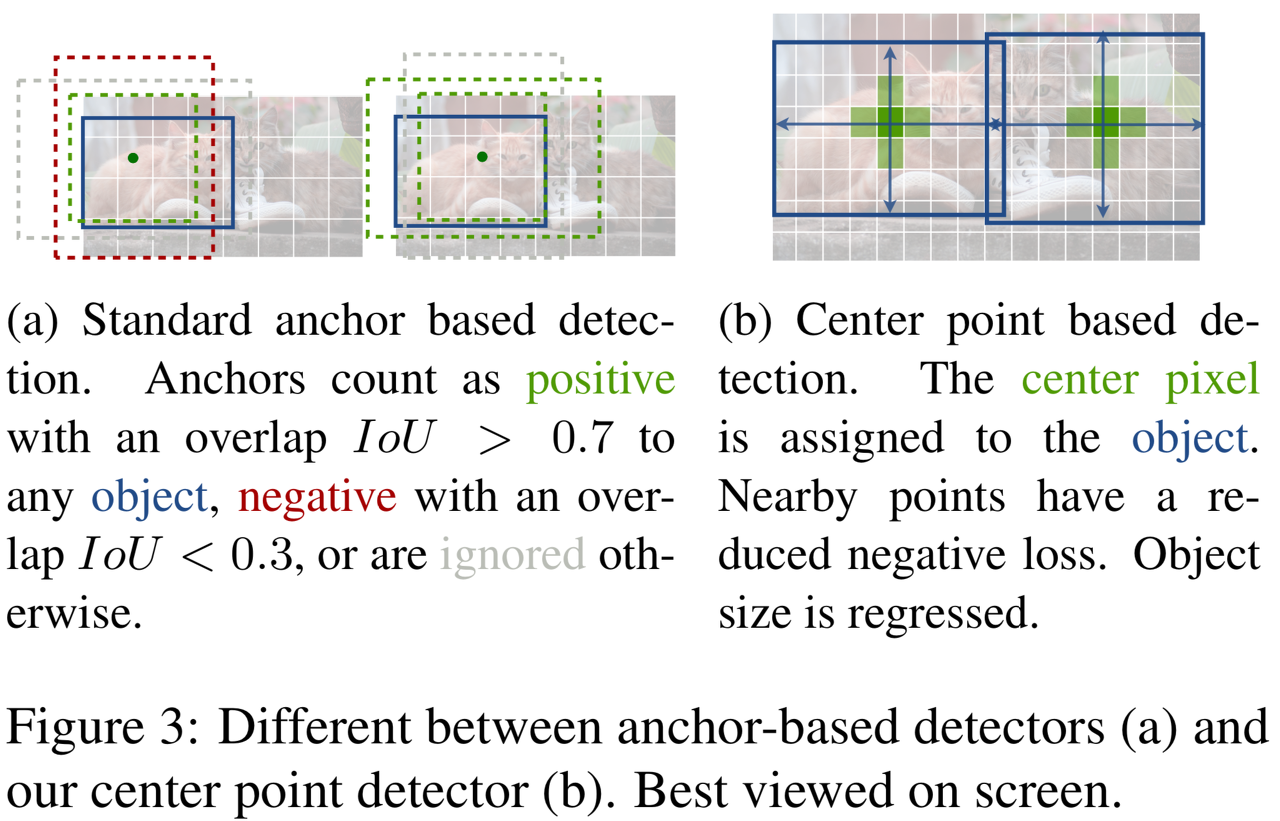
- CornetNet은 anchor box를 사용하는 것에 대한 단점을 위와 같이 열거했으며, Key point estimation을 사용해 고정적이지 않은 단 하나의 anchor를 사용하는 방법을 소개했음
- CornetNet은 Key point estimation을 사용해 detection을 수행
Keypoint Estimation for Object Detection
- CenterNet은 단 하나의 anchor를 keypoint estimation을 통해 얻어내고, 이러한 개념은 CornerNet에서 처음 소개됨
CornetNet
- ECCV 2018

- CornetNet은 왼쪽 위, 오른쪽 아래의 두 점을 찾고 이를 바탕으로 bounding box를 친다.
ExtremeNet
- CVPR 2019

-
Top-most, left-most, bottom-most, right-most, center 점을 찾은 후 이를 바탕으로 bounding box를 그린다.
-
CornerNet, ExtremeNet 모두 CenterNet과 같은 robust한 Keypoint Estimation Network를 기반으로 만들어진다.
- 단, keypoint들에 대한 grouping 과정이 필요하며, 이로 인해 속도가 느려짐
CenterNet
- 물체의 중심 포인트 (Center point)을 찾음
- 즉, 객체의 중심점 하나를 찾고 이를 바탕으로 bounding box를 그림
- 하나의 점만 찾기 때문에 위의 grouping 과정이 필요 없고, 또한 하나의 anchor box를 사용하므로(1-point detection) NMS과정이 필요 없어짐
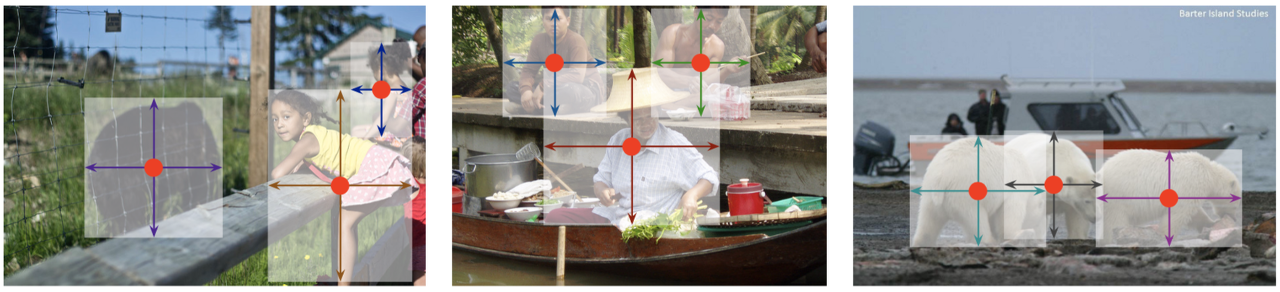
- 또한, 예측된 중심점을 기준으로 object size, dimension, 3D extend, orientation, pose 등의 추가 정보를 찾을 수 있다.
- 따라서 object detection 뿐만 아니라 3D object detection, Multi-person pose estimation 등에 쉽게 확장 가능하다.
- 위의 Github 데모 코드를 통해 위 세 종류의 task를 수행
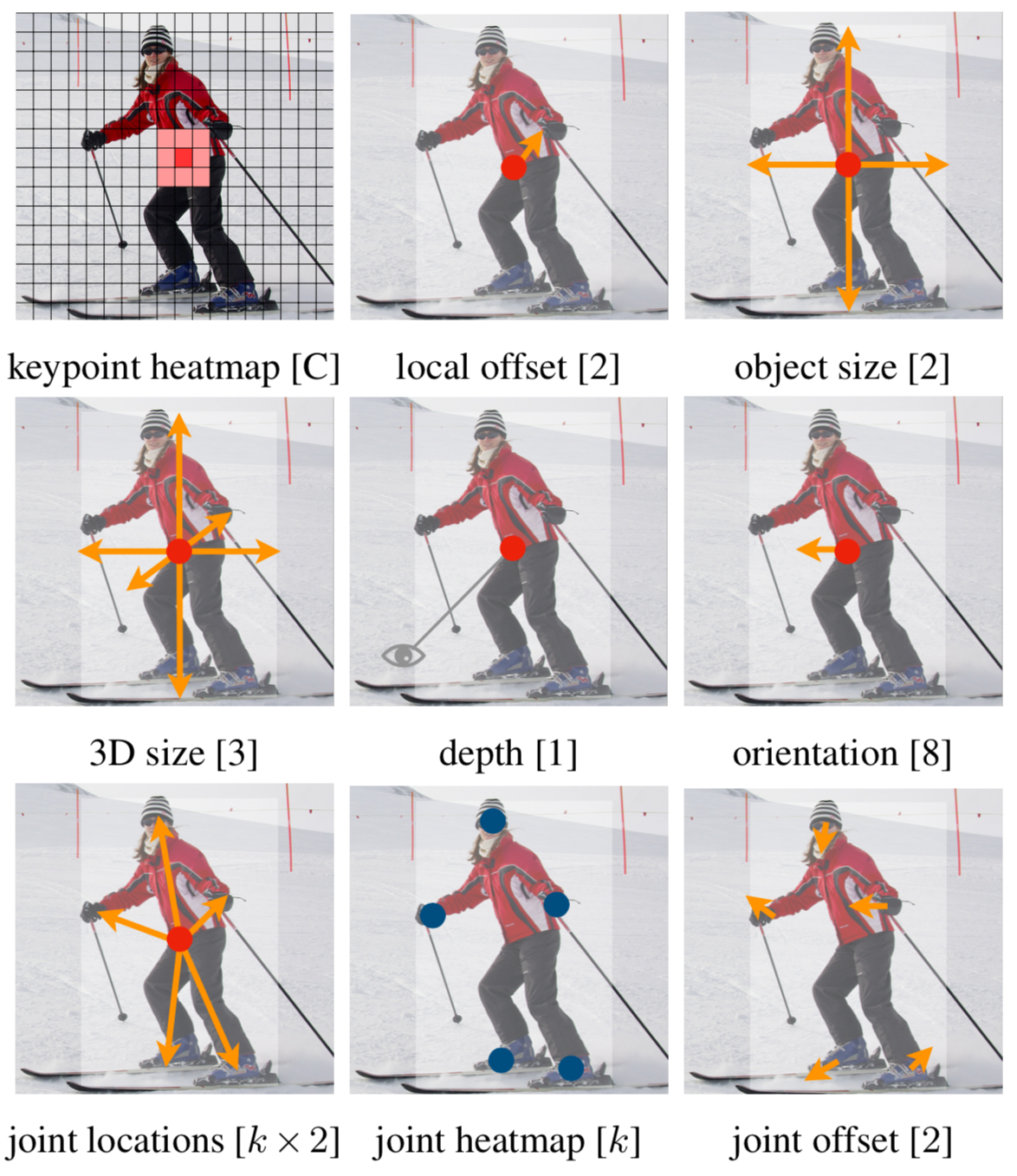
Keypoint estimation이란?
- Key estimation은 주로 pose estimation 분야에서 많이 쓰이는 방법
- https://www.youtube.com/watch?v=pW6nZXeWlGM&t=15s
-
Pose estimation의 keypoint들은 머리, 목, 어깨, 손목, 무릎 등이 있으며, pose estimation에서 이러한 keypoint들을 찾는데 자주 쓰이는 알고리즘이 keypoint estimation임
- CenterNet에선 keypoint가 객체의 중심이 됨
- CenterNet은 network를 이용해 keypoint의 heatmap을 찾는데 주 목적이 있음

- CenterNet은 4개의 architecture(Fully-Convolutional Encoder-Decoder Network)에서 학습되며, 이를 이용해 heatmap을 추론함
- ResNet-19, ResNet-101, DLA-34, Hourglass-104
- ResNet: Deep residual learning for image recognition. In CVPR, 2016.
- DLA: Deep layer aggregation. In CVPR, 2018.
- HourGlass: Stacked hourglass networks for human pose estimation. In ECCV, 2016
- ResNet-19, ResNet-101, DLA-34, Hourglass-104
CenterNet의 구조
- CenterNet은 CornetNet과 비슷한 네트워크 구조를 사용해 keypoint를 찾음
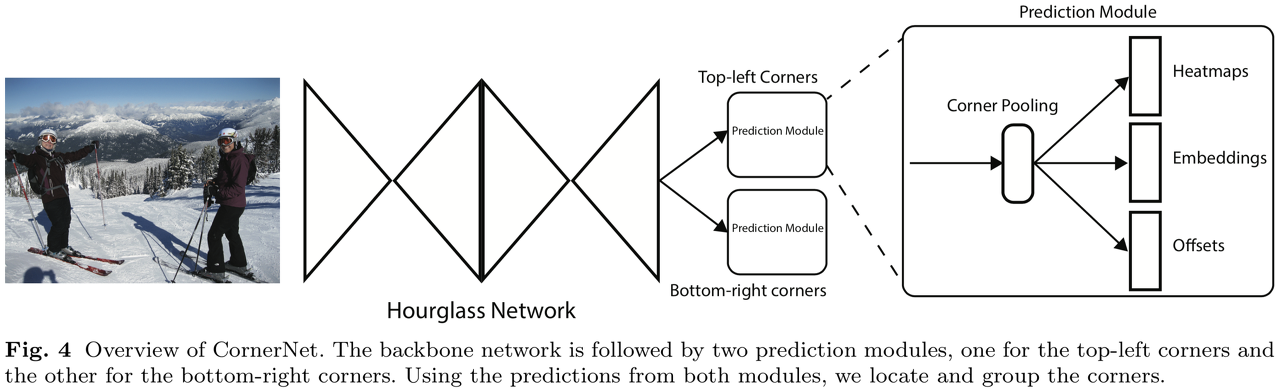
- 아래 그림은 CornetNet에서 가져온 그림
- 다만 CornetNet이 좌상단, 우하단 두 점을 찾는것과 다르게 CenterNet은 중심 한 점을 찾고 이를 이용해 heatmap과 offset, size를 추론
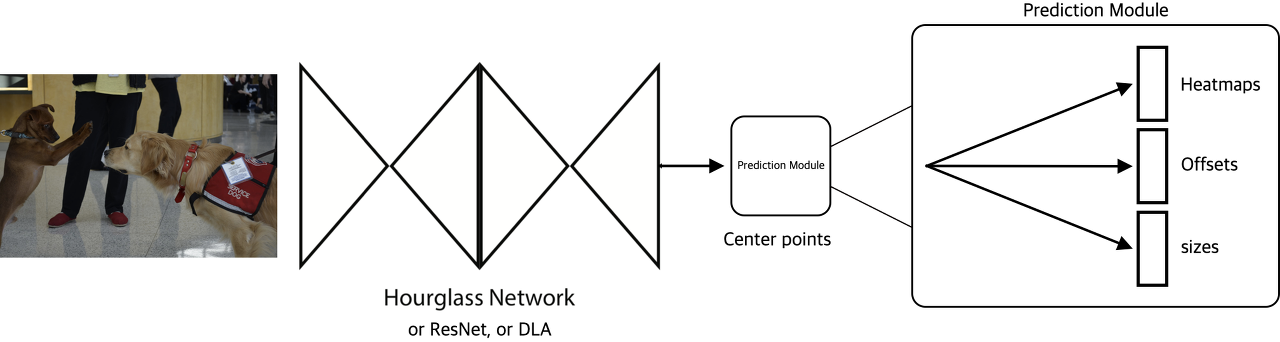
- CenterNet은 keypoints, offset, object size를 찾기 위해 하나의 네트워크를 사용
- Keypoint $\hat{Y}$, offset $\hat{O}$, object size $\hat{S}$
1. Keypoints
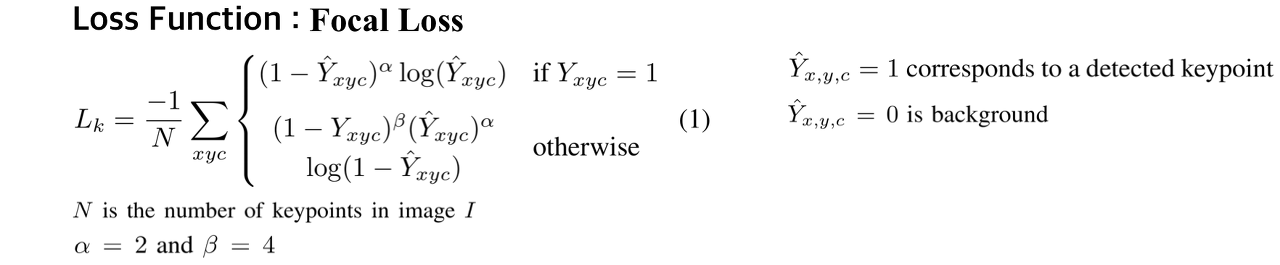
- Keypoint 학습에는 Hard positives (keypoint) « Easy negatives (background) 환경에 적합한 RetinaNet의 Focal Loss를 사용
2. Offsets
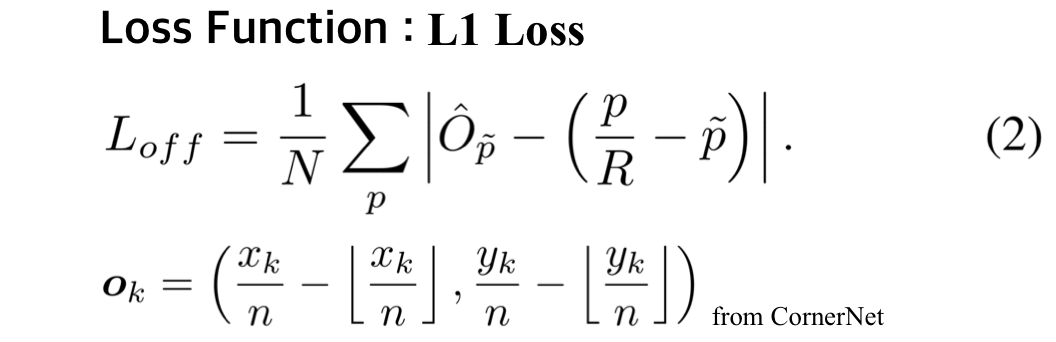
- 이미지가 네트워크를 통과하게 되면 output의 사이즈는 보통 이미지 크기보다 줄어듦
- 이로인해 예측된 heatmap에서 keypoint들의 위치를 다시 input image에 mapping할 때 정확성이 떨어지게 됨
- 이를 조절해주는 역할이 바로 offset (CornetNet에서 적용)
- Offset의 학습에는 L1 loss를 사용해 학습
3. Object sizes

- CenterNet은 측정한 keypoint들로부터 추가적으로 객체의 크기를 추론
- 객체 크기를 추론하기 위해 L1 loss를 사용
4. Overall training objective
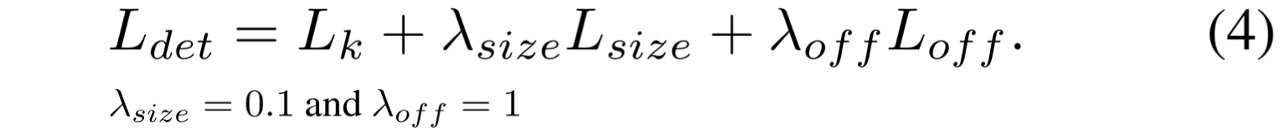
- CenterNet은 Keypoints, Offset, Size를 추론하기 위해 single network를 사용
From points to bounding boxes
- 앞에서 얻어진 keypoint들로부터 객체탐지를 위한 bounding box를 얻는 과정
- CenterNet은 우선 heatmap으로부터 각 category별로 peaks들을 뽑아냄
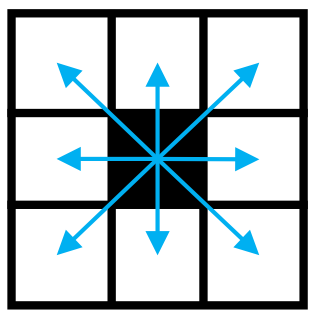
- Heatmap에서 주변 8개 픽셀보다 값이 크거나 같은 중간값들을 모두 저장하고, 값이 큰 100개의 peak 값들을 남겨놓음
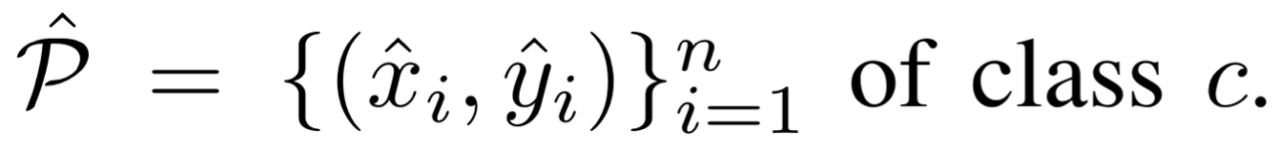
- 뽑아낸 peaks (keypoints)의 위치는 정수 좌표 형태로 표현됨 (x, y)
- 이를 통해 bounding box의 좌표를 아래와 같이 나타냄
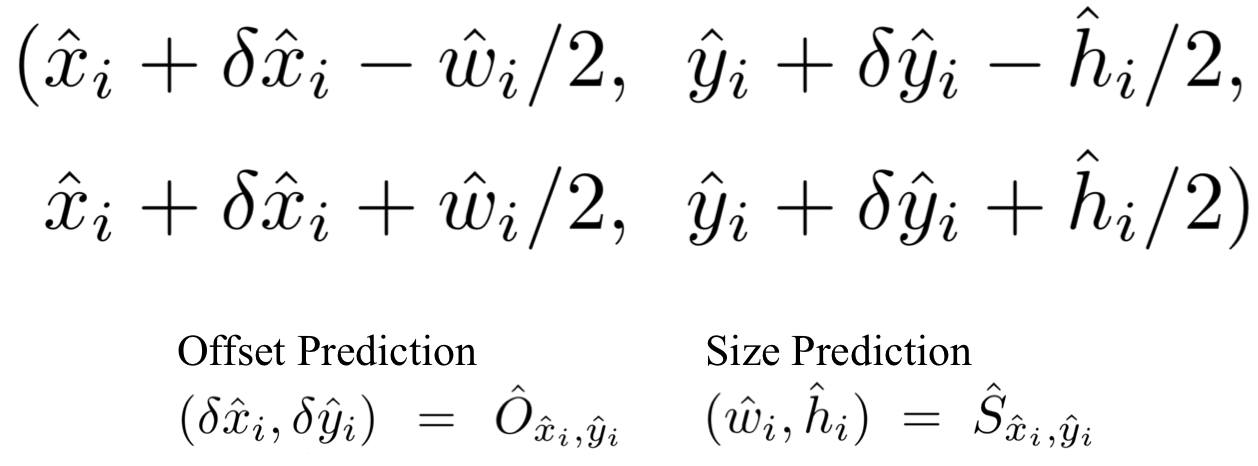
- CenterNet에서는 이런 모든 output들이 Single Keypoint Estimation으로부터 나왔다는 것을 강조함
CenterNet의 성능
- CenterNet은 ResNet-18, ResNet-101, DLA-34, Hourglass-104 총 4개의 네트워크 모델을 사용해 학습을 진행
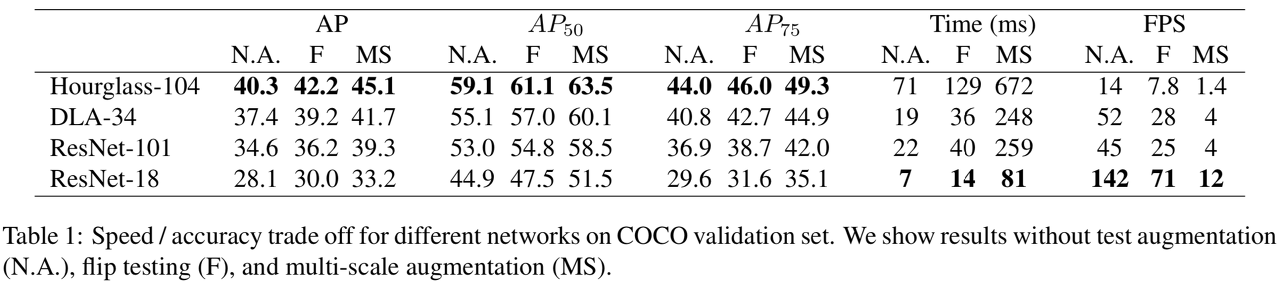
- MS COCO기준 ResNet-18 backbone에 대해 142FPS가 나왔으며, 그 때의 정확도는 28.1mAP로 매우 높음
- 또한 간단한 구조임에도 Hourglass-104 backbone 사용시 45.1mAP가 나옴 (multi-scale augmentation 기준)
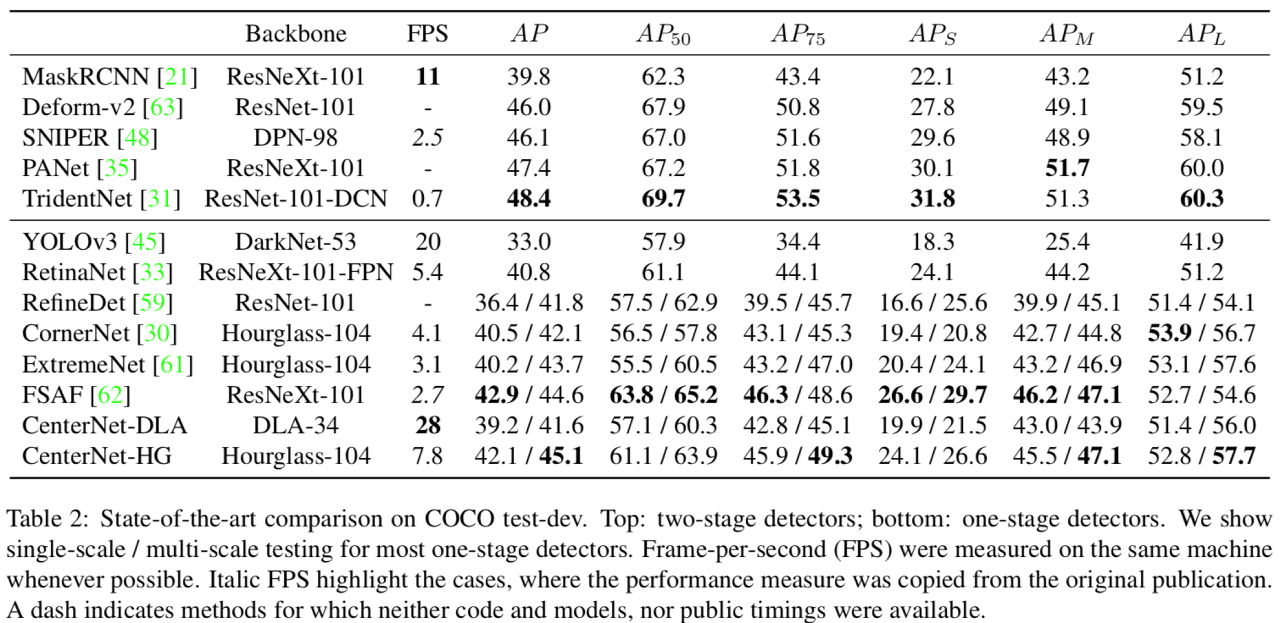
- 위의 결과에서 봤을 때 다른 SOTA 논문들과 비교해 성능면에서 큰 차이가 나지는 않음