
 Seongkyun Han's blog
Seongkyun Han's blog
Do Better ImageNet Models Transfer Better?
06 Nov 2019 | Deep learningDo Better ImageNet Models Transfer Better?
Original paper: https://arxiv.org/pdf/1805.08974.pdf
Authors: Simon Kornblith, Jonathon Shlens, and Quoc V. Le (Google Brain)
- 참고 글
- https://norman3.github.io/papers/docs/do_better_imagenet_models_transfer_better.html
Abstract
- Pretrained 된 모델을 이용해 다른 task에서 transfer learning을 하는것은 computer vision 분야에서 매우 효과가 좋음
- 하지만 여기엔 슬픈 전설이 있음
- ImageNet에서의 성능이 좋은 모델일수록 해당 모델을 backbone으로 사용해서 transfer learning을 하면 성능이 더 좋음
- 본 논문에서는 12개의 데이터 셋, 16개의 classification 모델을 비교해서 위의 가설이 사실인지 검증함
- 실제 backbone과 tranfer task와의 성능에 대한 상관 관계가 매우 높은것을 확인함
Introduction
- 지난 십여년간 computer vision 학계에서는 모델간 성능 비교를 위한 벤치마크 측정 수단을 만들이는데 공을 들임
- 그 중 가장 성공한 프로젝트는 ImageNet
- ImageNet으로 학습된 모델을 이용해 transfer learning, object detection, image segmentation 등의 다양한 task에 대해 성능평가를 수행함
- 여기서 암묵적인 가정은
- ImageNet에서 좋은 성능을 보이는 모델은 다른 image task에서도 좋은 성능을 낸다는 것
- 더 좋은, 성능이 좋은 모델을 사용할수록 transfer learning에서 더 좋은 성능을 얻을 수 있음
-
이전의 다양한 연구들을 토대로 위 가정들은 어느정도 맞는듯 함
- 본 논문에서는 실험 기준을 세우기 위해 ImageNet feature와 classification model 모두를 살펴봄
- 16개의 최신 CNN 모델들과 12개의 유명한 classification dataset을 사용해 검증
- 논문에서는 총 3가지 실험을 수행
- Pretrained ImageNet에서 고정된 feature 값을 추출한 뒤, 이 결과로 새로운 task를 학습
- Transfer learning as a fixed feature extractor
- Feature extractor는 그대로, 뒤 쪽은 학습
- Pretrained ImageNet을 다시 fine-tuning 하여 학습
- Transfer learning
- 일반적인 전이학습으로, pretrained 모델로 weight parameter 초기화 후 해당값을 시작점으로 하여 재학습
- 그냥 각 모델들을 개별 task에서 from scratch로 학습
- 처음부터 모델을 학습시키는 방법
- Pretrained ImageNet에서 고정된 feature 값을 추출한 뒤, 이 결과로 새로운 task를 학습
- Main contributions
- 더 나은 성능의 imageNet pretrained model을 사용하는것이 linear classification의 transfer learning에서 더 나은 feature extractor의 feature map을 만들어내며(r=0.99), 전체 네트워크가 fine-tuning 되었을 때 더 나은 성능을 보임(r=0.96)
- ImageNet task에서 모델의 성능을 향상시키는 regularizer들은 feature extractor의 출력 feature map의 관점에서 transfer learning에 오히려 방해가 됨
- 즉, transfer learning에서는 regularizer들을 사용하지 않는것이 성능이 더 좋았음
- ImaegNet에서 성능이 좋은 모델일수록 다른 task에서도 비슷하게 성능이 더 좋았음
Statistical methods
- 서로 다른 난이도를 가진 여러 데이터 집합을 통해 각 모델의 성능의 상관관계를 제대로 측정하는것은 매우 어려운 일
- 따라서 단순하게 성능이 몇% 올랐는지를 확인하는 방식에는 문제가 있음
- 예를 들어 현재 정확도가 50%일때와 정확도가 99%일때, 성능을 1%향상시키는 것은 서로 다른 의미를 가짐
- 논문에서는 log-odd를 사용해서 변환된 성능 측정 방식을 사용함
- Logit 변환은 비율 데이터 분석에서 가장 흔하게 사용되는 계산방식
- 사용되는 스케일이 log단위로 변경되기에 갑싱 변화량 $\Delta$ 는 $exp$ 의 비율로 적용되는것을 알 수 있음
- Error bar도 Morey가 제안한 방법으로 적당히 잘 구성함(논문 참고)
- 이제 ImageNet의 정확도와 log-transformed 정확도의 상관 관계를 측정
- 자세한 내용은 논문의 appendix 참고
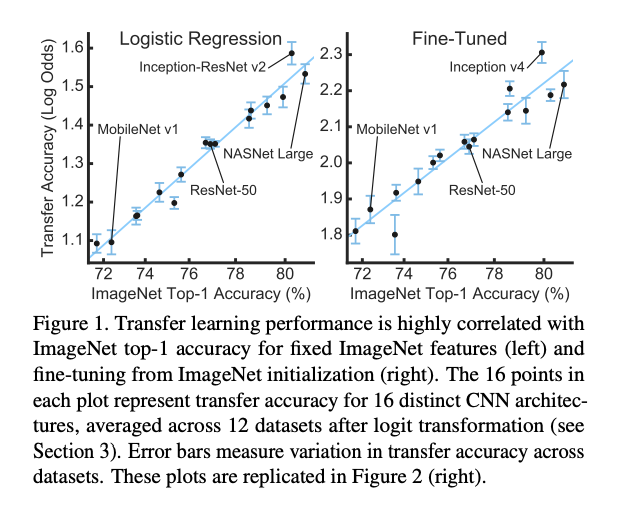
실험 결과
- 16개의 모델로 ImageNet(ILSVRC2012) validation set의 top-1 accuracy 비교
- 각 모델들은 71.6~80.8%의 정확도 성능을 보임
- 공평한 비교를 위해 모든 모델은 직접 재학습을 함
- 여기서 BN scale parameter, label smoothing, dropout auxiliary head 등은 나누어 확인
- 논문의 appendix A.3에 더 자세히 기술되어 있음
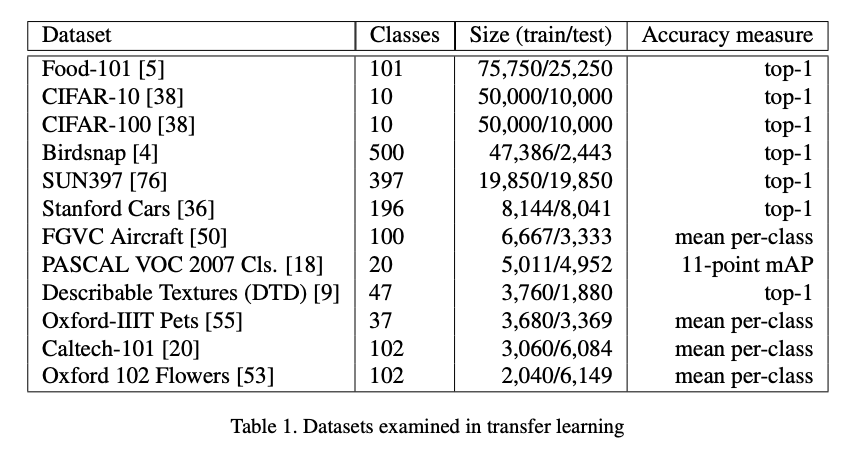
- 총 12개의 classification dataset을 실험
- 데이터셋의 training set size는 2,040개부터 75,750개까지 다양함 (Appendix H 참조)
- CIFAR-10, CIFAR-100, PASCAL-VOC-2007, Caltech-101, Food-101, Bird-snap, Cars, Aircraft, Pets, DTD, scene-classification etc.
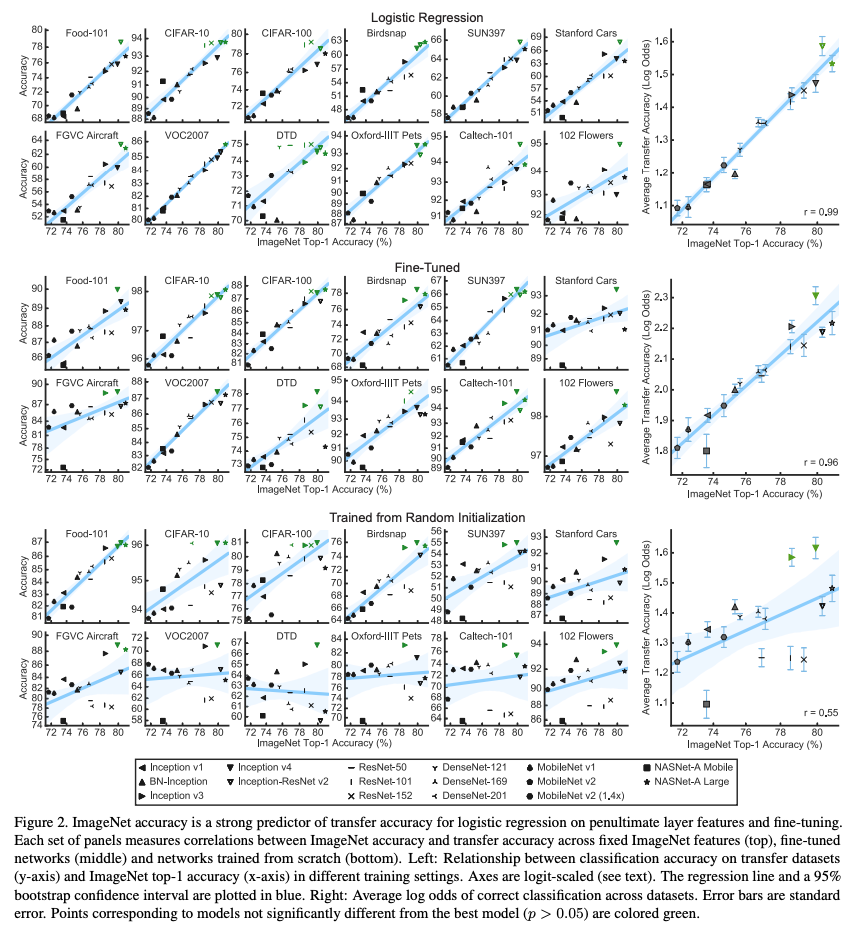
- 그림 2는 실제 테스트 결과를 보여줌
- ImageNet에 대한 top-1 accuracy 결과와 새로운 task에 대한 상관관계를 나타냄
- 다음 설정으로 실험 수행
- Logistic regression classifier (마지막 전 레이어 fixed feature 사용)
- ImageNet을 기본으로 fine-tunning 작업 수행
- 동일한 아키텍쳐 모델로 새로운 task에서 재학습
Fixed feature extractor
- Fixed feature를 먼저 추출한 뒤 이 값으로 logistic regression을 수행
- L-BFGS를 사용했으며 data augmentation은 공정한 실험을 위해 적용하지 않음
- 최대한 같은 실험조건으로 실험
- 공개된 pretrained checkpoint 값들을 사용해 테스트 할 경우
- ResNet과 DenseNet이 다른 모델에 비해 일관적으로 높은 성능을 얻음을 확인함
- 다만 ImageNet과 transfer 정확도의 사이의 상관관계가 매우 낮음 (appendix B)
- 이는 regularizer의 적용 유무에 따른 차이로 보여짐
- 그림 3은 각 regularizer의 적용 여부에 따른 성능을 확인
- 총 4개 종류로 여러 방식을 조합해 성능을 확인
- BN scale parameter 제거 ($\gamma$)
- Label smoothing 적용여부
- Dropout 적용여부
- Auxiliary classifier head 적용여부
- 위의 사항들은 ImageNet에서 top-1 정확도에 1% 이내의 성능 영향을 미침
- 하지만 transfer learning의 정확도에는 각각 미치는 영향도가 모두 다름
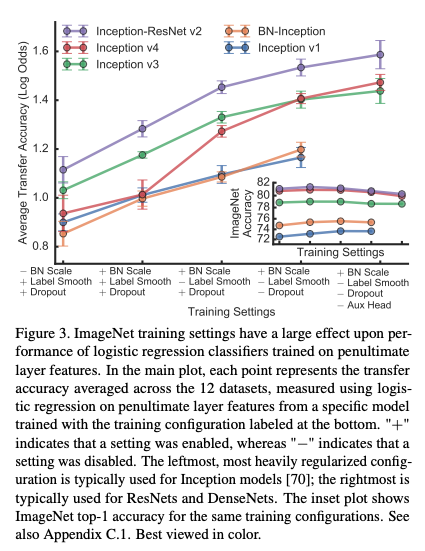
- Embedding에서도 차이가 있음

- 자세한 내용은 appendix C 참조
Fine tuning
- 그림 2가 fine tuning의 실험 결과
- ImageNet으로 학습된 모델을 사용해 각 task에 대해 fine tuning 수행
- 총 20,000 step동안 학습을 진행하며, Nesterov momentum(SGD momentum)과 cosine-decay lr을 적용
- Batch size는 256 사용
- Grid search 기법을 이용해 최적의 hyperparameter(lr, weight decaying rate)를 찾음 (appendix A.5)
- 이 실험에서는 ImageNet top-1 정확도와 다른 dataset에 해당 모델이 transfer learning 적용되어 학습되어졌을 때의 정확도를 비교
- 둘의 상관관계가 높음을 확인함 (r=0.96)
- Logistic regression과 비교해서 regularization(정규화) 기법들을 적용시켜 학습시 regularizer의 영향도는 작아짐
- 그림 5는 Inception v4와 Inception-ResNet-v2에 대해 마찬가지로 regularizer들을 적용시켜본 결과
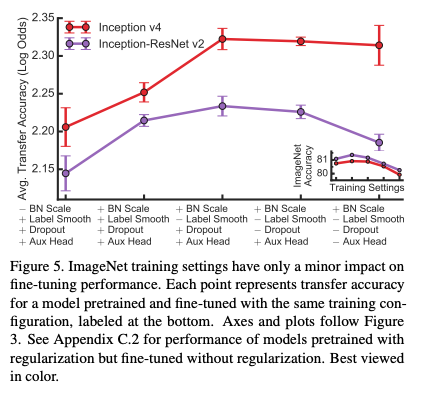
- Logistic regression 실험과 마찬가지로 BN scale은 사용하고 label smoothing은 적용하지 않았을 때의 결과가 가장 좋았음
- Dropout과 auxiliary head는 경우에 따라 성능 향상이 될 수도 있고 아닐 수도 있음
- 자세한 내용은 appendix C.2
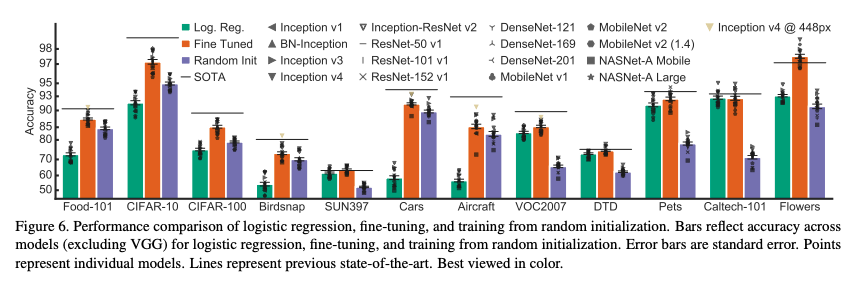
- 무엇보다도 fine-tuning 방식이 transfer learning햇을 때 정확도가 가장 좋았음(성능이 가장 좋았음)
- 하지만 어떤 데이터셋을 사용하느냐에 따라 얻을 수 있는 이득의 정도는 달라짐
- 자세한 내용은 그림 6과 appendix E를 참고
Random initialization
- 앞선 결과들만 살펴본다면 성느으이 향상이 ImageNet pretrained weight 값들로 인한 것인지, 아니면 architecture 자체에서 오는 것인지 확인하기 어려움
- 여기서는 순수히 동일한 architecture를 이용해서 초기 weight parameter를 랜덤하게 초기화해 학습시킴
- 각종 옵션 및 hyperparameter는 fine-tuning 실험과 동일하게 설정
- 여기서 상관관계는 어느 정도 유의미한 결과를 보임(r=0.55)
- 특히 10,000개 미만의 데이터를 가지는 7개 데이터셋에서는 상관관계가 매우 낮았음(r=0.29)
- 자세한 내용은 appendix D
- 반면 데이터 셋의 크기가 클 경우 상관관계가 매우 높았음 (r=0.86)
Fine-tuning with better models is comparable to specialized methods for transfer learning
- ImageNet 정확도와 transfer learning시 정확도의 상관관계가 매우 높다고 확인됨
- ImageNet에서 더 정확한 모델이 transfer learning 적용시켜도 더 정확한지 확인
- 그림 6에서 확인가능하듯이 12개 데이터셋 중 제일 정확한 모델이 7개 데이터 셋에서도 SOTA의 성능을 보임 (appendix F)
- 이는 ImageNet으로 학습된 모델의 성능이 transferred model의 성능에 큰 영향을 준다는 의미
ImageNet pretraining does not necessarily improve accuracy on fine-grained tasks
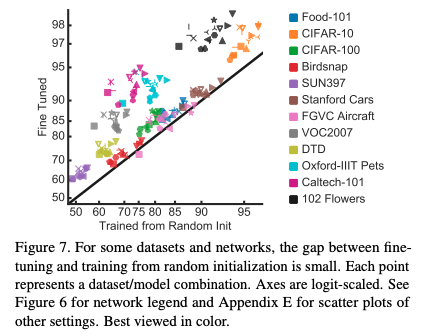
- FGVC task에서는 transfer learning을 적용해도 성능 향상의 폭이 적었음
- Stanford car, FGVC Aircraft등…
- ImageNet에서 car class는 10개정도로 적음
- Stanford car의 car class는 196개로 이로 인해 잘 동작하지 않는것으로 판단됨
ImageNet pretraining accelerates convergence
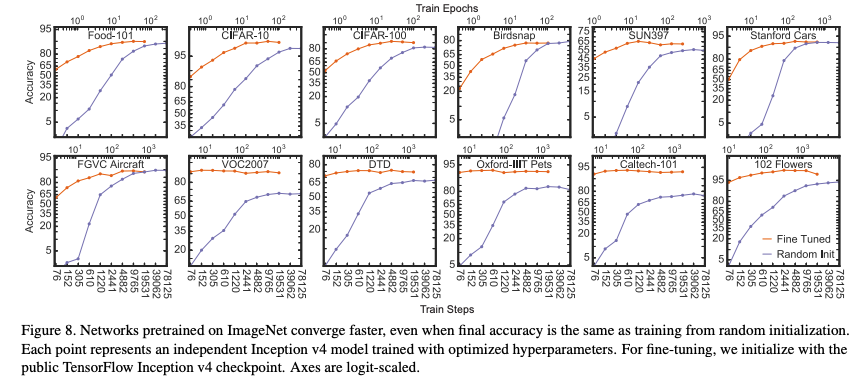
- Stanford car와 FGVC-Aircraft에서 2와 3(SURF)의 방식에 따른 성능 차이가 없는 것을 확인
- 위의 그림을 볼 때 2의 방식이 수렴 속도 면에서 유의미한 차이가 존재
- 학습 속도면에서 fine-tuned model이 훨씬 학습속도가 빠름
Accuracy benefits of ImageNet pretraining fade quickly with dataset size
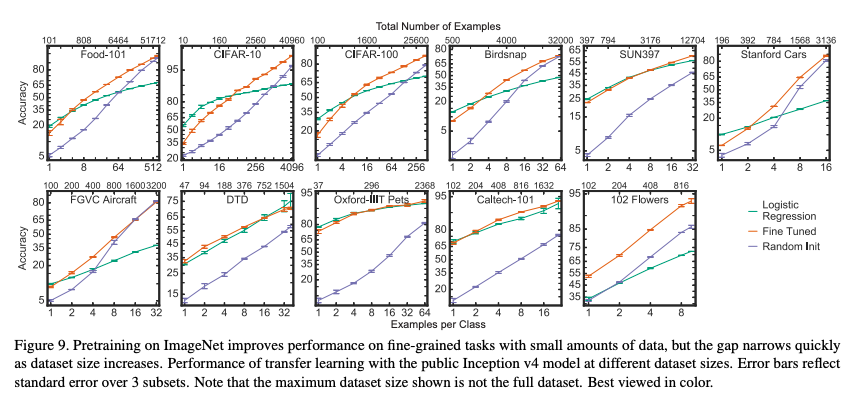
- 결과를 놓고 보면, ImageNet pretrained model을 사용하는것이 최고다…