
 Seongkyun Han's blog
Seongkyun Han's blog
EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks
07 Nov 2019 | Deep learningEfficientNet:Rethinking Model Scaling for Convolutional Neural Networks
Original paper: https://arxiv.org/pdf/1905.11946.pdf
Authors: Mingxing Tan, and Quoc V. Le
- 참고 글
- https://hoya012.github.io/blog/EfficientNet-review/
- CVPR2019에 발표된 논문으로, image classification task에서 성능이 좋은 model인 efficientnet을 제안함
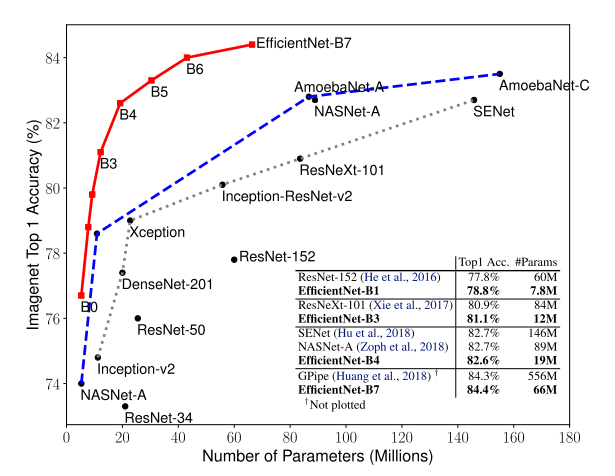
- ImageNet 데이터셋에 대해 정확도를 초점으로 한 모델과 효율성(efficient)을 초점으로 한 모델들이 굉장히 많이 제안됨
- 이러한 모든 모델들의 성능을 크게 상회하는 모델을 제안함
- 아래에선 어떻게 이렇게 좋은 성능을 달성했는지에 대해 설명
Model Scaling
- 일반적으로 CNN의 정확도를 높일 때 잘 짜여진 모델 자체를 찾는 방법도 있지만, 기존 모델을 바탕으로 complexity를 높히는 방법도 많이 사용됨
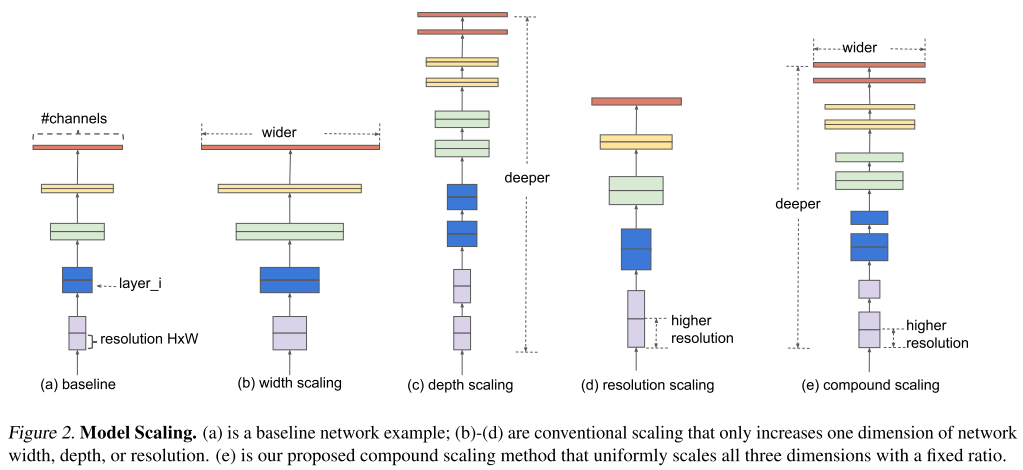
- 위의 그림은 존재하는 모델의 size를 키워주는 방법들의 예시를 보여줌
- 대표적으로 filter의 개수(channel의 개수)를 늘리는 width scaling 과 layer의 개수를 늘리는 depth scaling , 그리고 input image의 해상도를 높이는 resolution scaling 이 자주 사용됨
- ResNet이 depth scaling을 통해 모델의 크기를 조절하는 대표적인 모델(ex. ResNet-50, ResNet-101)
- MobileNet, ShuffleNet 등이 width scaling을 통해 모델의 크기를 조절하는 대표적인 모델(ex. MobileNet-224 1.0, MobileNet-224 0.5)
- 하지만 기존 방식들에서는 위의 3가지 scaling을 동시에 고려하는 경우가 거의 없었음
-
또한 3가지 scaling 기법 중 어떤 기법을 사용할지에 대해서도 마땅한 가이드라인이 없으며, 실제로 scaling한다고 해서 linear하게 정확도가 향상되는 것이 아니기에 일일이 실험을 해봐야 한다는 어려움이 존재
- 본 논문에서는 실제로 3가지 scaling 기법에 대해 각 scaling 기법마다 나머지는 고정하고 1개의 scaling factor만 키워가며 정확도의 변화를 측정함
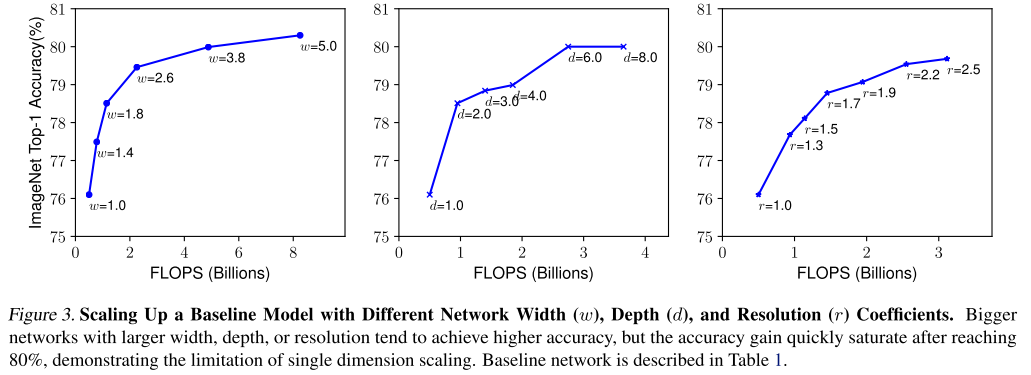
-
위의 그림에서 width scaling, depth scaling 은 비교적 이른 시점에 정확도가 saturation되며 그나마 resolution scaling 이 키우면 키울수록 정확도가 더 향상되는 모습을 보임
-
비슷한 방식으로 depth(d)와 resolution(r)을 고정하고 width만 조절해서 정확도의 변화를 측정하는 실험을 수행
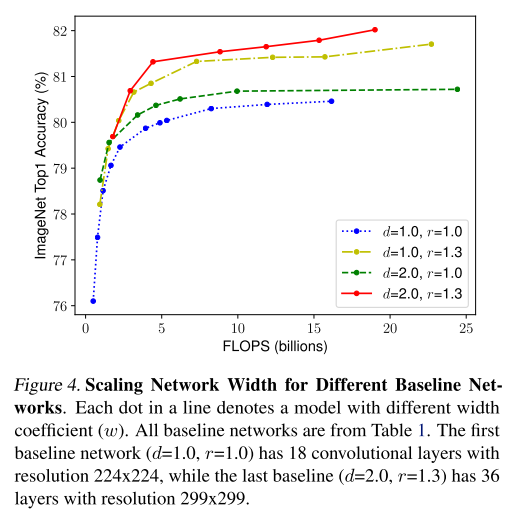
- 같은 연산량(FLOPS)임에도 불구하고 크게는 1.5%까지 정확도가 차이가 날 수 있음
- 초록색 선과 노란색 선을 비교하면 depth를 키우는 것 보다는 resolution을 키우는 것이 정확도가 더 좋아지는 것을 확인 할 수 있음
-
빨간 선을 보면 1가지, 혹은 2가지 scaling factor만 키우는것보다 3가지 scaling factor 모두 동시에 키워주는것이 가장 성능이 좋아지는 것을 실험적으로 보여줌
- 직관적으로 생각해봐도 input image가 커지면 그에 따라서 convolution의 receptive field도 늘려줘야 하고, 더 커진 fine-grained pattern들을 학습하기 위해 더 많은 channel이 필요한건 합리적인 주장임
- 즉, 모델의 크기를 키워줄 때 위의 3가지 요소들을 동시에 고려하는 것이 좋다는 것은 어찌보면 당연한 주장
- 이제, 어떻게 이 3가지 요소들을 고려할 것인지에 대해 설명함
Compound Scaling
- 위의 실험들을 통해 3가지 scaling factor를 동시에 고려하는 것이 좋다는 것을 입증함
- 이번엔 최적의 비율을 찾아서 실제 모델에 적용을 해서 다른 모델들과 성능을 비교하는 과정을 설명함
- 이 논문에선 모델(F)을 고정하고 depth(d), width(w), resolution(r)의 3가지를 조절하는 방법을 제안하는데, 여기서 고정하는 모델(F)을 성능이 좋은 모델로 선정하는것이 굉장히 중요함
- 아무리 scaling factor를 조절해도 초기 모델 자체의 성능이 낮다면 최대 임계 성능도 낮아지기 때문
- 이 논문에서는 MnasNet과 거의 동일한 search space 하에서 AutoML을 통해 모델을 탐색했고, 이 과정을 통해 찾은 작은 모델을 EfficientNet-B0 라고 함
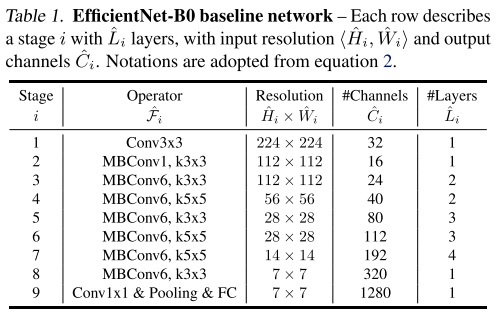
- 모델 구조는 MnasNet과 거의 유사하며, 위와 같이 구성됨
- 이 모델을 base로 하여 3가지 scaling factor를 동시에 고려하는 Compund Scaling 을 적용하여 실험을 수행
- Depth: $d=\alpha^{\phi}$
- Width: $w=\beta^{\phi}$
- Resolution: $r=\gamma^{\phi}$
- 단, 다음의 조건을 만족
- $\alpha\cdot \beta^2\cdot \gamma^2\approx 2$
- $\alpha\geq1, \beta\geq1, \gamma\geq1$
- 우선 depth, width, resolution은 각각 알파, 베타, 감마로 나타내며 각각의 비율은 $\alpha\cdot \beta^2\cdot \gamma^2\approx 2$ 조건을 만족해야 함
- 여기서 width와 resolution에 제곱항이 들어간 이유는 depth는 2배 키워주면 FLOPS도 비례해서 2배 증가하지만, width와 resolution은 공간 방향으로 2차원이므로 제곱 배 증가하기 때문임
- 따라서 제곱을 곱해서 계산함
- 다음에 전체 모델 사이즈는 알파, 베타, 감마에 똑같은 파이만큼 제곱해서 조절하게 됨
- EfficientNet의 알파, 베타, 감마 값은 간단한 grid search를 통해 구하는 방식을 제안하며, 처음 단계에서는 파이를 1로 고정한 뒤 타겟 데이터셋에서 좋은 성능을 보이는 알파, 베타, 감마 값을 찾아냄
-
이 논문에선 $\alpha=1.2$, $\beta=1.1$, $\gamma=1.15$를 사용하며, 이 3개의 scaling factor들을 고정한 뒤 $\phi$를 키워주며 모델의 사이즈를 키워주며 실험
- 기존 사람이 디자인한 CNN, AutoML을 통해 찾은 CNN들과 비교를 한 결과는 아래와 같음
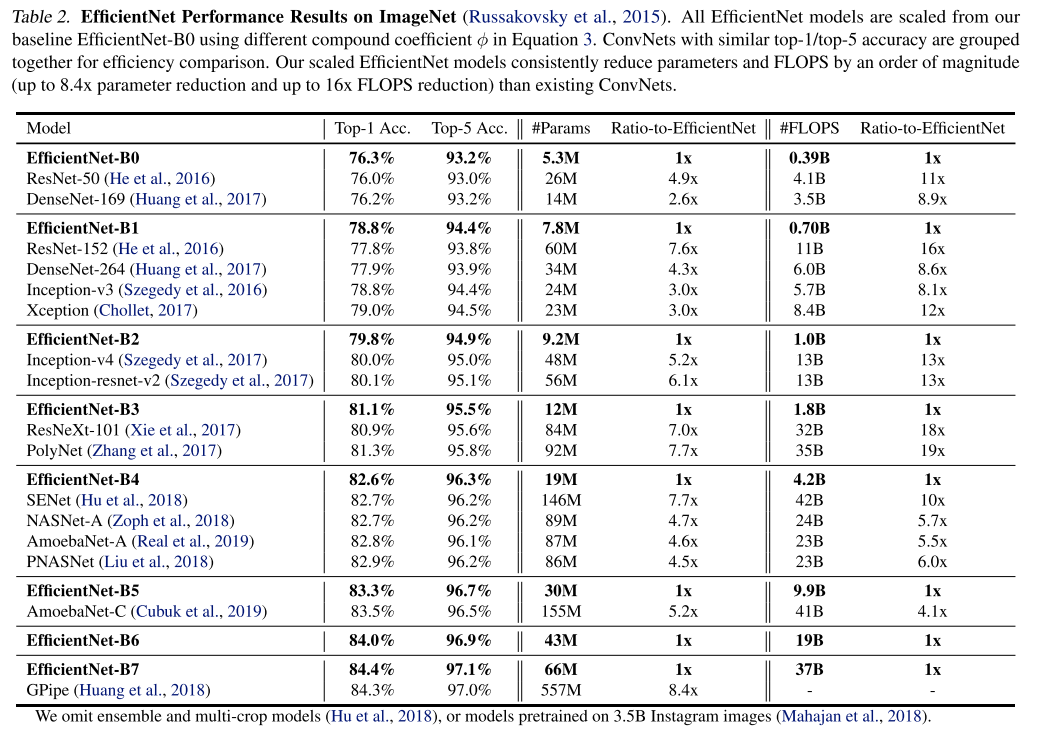
- 결과를 보면 알 수 있듯이 기존 ConvNet들에 비해 비슷한 정확도를 보이면서 parameter 수와 FLOPS 수를 굉장히 많이 절약 할 수 있음
- 또한 기존에 ImageNet 데이터셋에서 가장 높은 정확도를 달성했던 GPipe보다 더 높은 정확도를 달성함
- 동시에 parameter수와 FLOPS 수도 굉장히 많이 절약함
- 실험 결과가 상당히 의미있고 좋음
- 이 외에도 다양한 실험 결과들은 논문에서 확인 가능
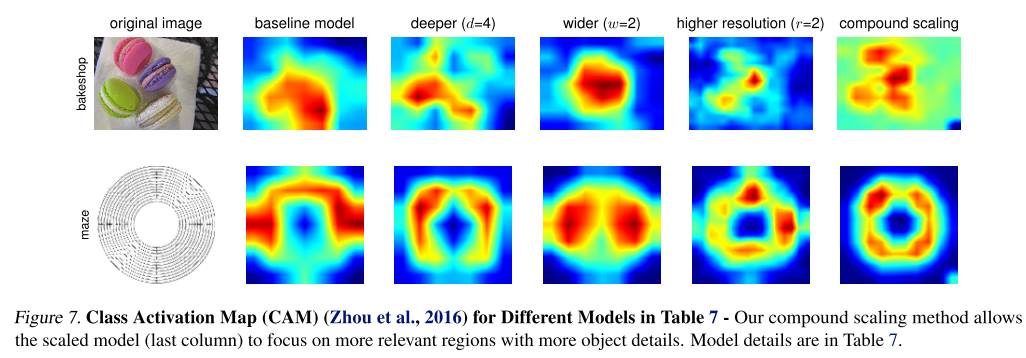
- 마지막으로 모델이 이미지를 분류할 때 영상 내 어느 영역에 집중했는지 확인 할 수 있는 class activation map(CAM)을 뽑았을 때, 3개의 caling factor를 각각 고려하는 경우보다 동시에 고려했을 때 더 정교한 CAM을 얻을 수 있었음
결론
- 직관적이고 간단한 방식을 적용해 우수한 성능을 내는 점이 인상깊었음