
 Seongkyun Han's blog
Seongkyun Han's blog
Image Style Transfer Using Convolutional Neural Networks
13 Nov 2019 | Deep learningImage Style Transfer Using Convolutional Neural Networks
Original paper: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
Authors: Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge
- 참고 글
- https://blog.lunit.io/2017/04/27/style-transfer/
- https://www.popit.kr/neural-style-transfer-%EB%94%B0%EB%9D%BC%ED%95%98%EA%B8%B0/
Introduction
- Style transfer는 content image와 style image를 이용해 content image의 화풍을 style image대로 바꾸는 작업
- 이미지의 주된 형태는 content image를 따름
- 스타일은 style image와 유사하게 바꿈

- 위 그림에서 주택사진을 content image로 했을 때, 각 style image에 따른 실험 결과를 보여줌
- 주택의 형태와 배치는 유지되면서 각 화풍만 작품(style image)과 유사하게 바뀜
- Neural network를 이용한 style transfer의 과정은 아래와 같이 두 분류로 구분됨
- ImageNet 등으로 pretrained된 네트워크를 이용한 방법
- Content image와 style image를 네트워크에 통과시킬 때 나온 각각의 feature map을 저장
- 새롭게 합성될 영상의 feature map이 content image와 style image로부터 생성된 feature map과 비슷한 특성(분포)을 갖도록 영상을 최적화
- 장점: 이미지 2장(content, style image)으로 style transfer 가능
- 단점: 매번 이미지를 새롭게 최적화해야하므로 시간이 오래걸림
- Style transfer network를 학습시키는 방법
- 서로 다른 두 도메인(content image와 style image)의 영상들이 주어졌을 때, 한 도메인에서 다른 도메인으로 바꿔주도록 네트워크를 학습시킴
- 장점: 네트워크를 한 번 학습시킨 후 새로운 이미지에 적용할 땐 feed forward만 해주면 됨(빠름)
- 단점: 새로운 네트워크를 학습해야 하므로 각 도메인 별로 다수의 영상이 필요하며, 네트워크 학습에 많은 시간이 소요됨
- GAN 모델을 이용하는 방법
- 서로 다른 두 도메인(content image와 style image)의 영상들이 주어졌을 때, 한 도메인에서 다른 도메인으로 바꿔주도록 네트워크를 학습시킴
- ImageNet 등으로 pretrained된 네트워크를 이용한 방법
Image Style Transfer Using Convolutional Neural Networks
- 본 논문에서 제시한 방법은 content에 대한 정보를 담고있는 $I_{content}$와 style을 담고 있는 $I_{style}$을 입력으로 받음
-
이 두 영상으로부터 각각의 특성을 담고 있는 새로운 영상인 $I_{output}$을 만들어내는것이 최종 목적
- 이를 위해 ImageNet pretraineyd network를 사용해 $I_{content}$, $I_{style}$에 대해 각각의 feature map을 추출
- $I_{output}$의 feature map과는 content가 비슷해지도록, $I_{style}$과는 style이 비슷해지도록 $I_{output}$의 픽셀들을 최적화(optimize)
- 모든 과정에서 네트워크 자체의 weight parameter들은 변하지 않음(feed forward만 수행)
사용된 네트워크
- 논문에서는 특징 추출용 feature extractor로 ImageNet pretrained VGG19를 사용
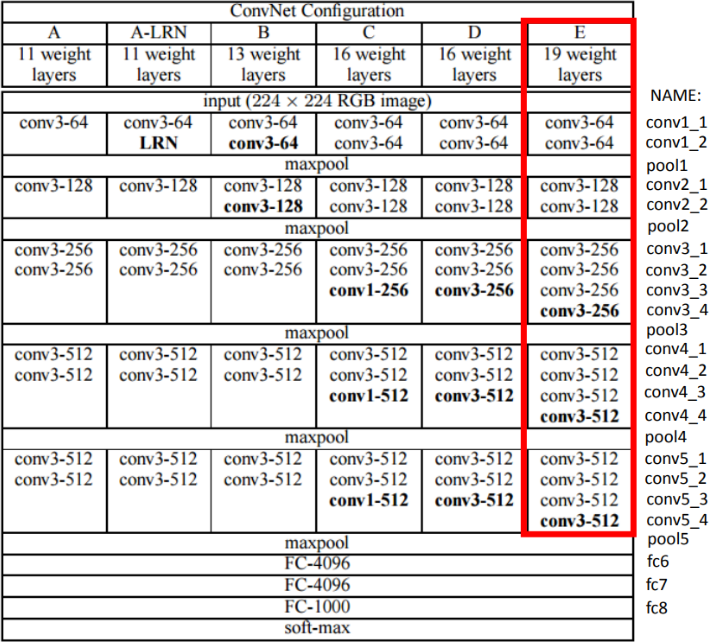
- Pretrained network에 아래의 처리를 수행
- 네트워크 정규화(네트워크 가중치 정규화)
- Average pooling 적용(원래의 max pooling 대신 적용)
네트워크의 어느 부분에서 만들어진 feature map을 사용할 것인가

- 실제로 CNN의 깊은 부분(뒷단)에서 추출된 feature map과 얕은 부분(앞단)에서 추출된 feature map은 서로 다른 특성을 가짐
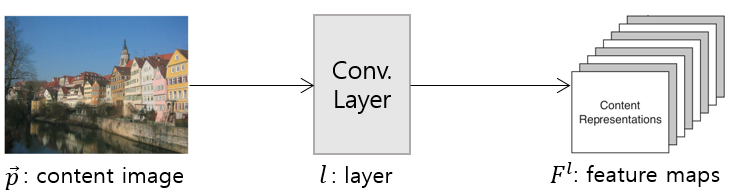
Content feature
- 입력 이미지 p와 convolution layer l에 대해 아래와 같이 feature map, F를 만들어 낼 수 있음
- 위 그림에서 conv1_2(a), conv2_2(b), conv3_2(c), conv4_2(d), conv5_2(e) 레이어에서 입력 이미지를 재구성한 영상을 보여줌
- 레이어가 깊어질수록(d, e) 픽셀 수준의 정보는 사라지지만 입력 이미지가 가진 semantic 정보는 그대로 유지됨(추상화가 많이 이루어짐)
- 반면 얕은 레이어일수록(a, b, c) 입력 이미지와 거의 동일함
- 따라서 얕은 레이어에서 생성된 feature map을 이용해 content feature를 추출
Style feature
- Style feature는 “Texture Synthesis Using Convolutional Neural Networks, Leon A. Gatys”의 Gram matrix를 기반으로 생성
- Style과 texture는 공간정보와 무관해야 함
- 따라서 각 레이어의 feature map 사이의 상관관계(correlation)를 나타내는 Gram matrix를 사용
- 레이어 l에서의 Gram matrix는 아래와 같이 정의됨
- Style image: $\vec{a}$
- Layer: $l$
- $F^l$: l번째 layer의 feature map
- $G_{ij}^{l}$: $\sum_k F_{ik}^{l}F_{jk}^{l}$
- Gram matrix at layer $l$, $G^l$: $[G_{ij}^{l}]$
- Style feature의 경우 단일 레이어가 아니라 여러 레이어에서 나온 feature map들의 상관관계를 동시에 고려함
- 이를 통해 이미지가 전역적으로 가진 레이아웃 정보가 아닌, 정적인(stationary) 정보를 다수의 스케일을 고려한 정보를 얻을 수 있음
- 위의 레이어별 feature 그림에서는 ‘conv1_1(a)’, ‘conv1_1, conv2_1(b)’, ‘conv1_1, conv2_1, conv3_1(c)’, ‘conv1_1, conv2_1, conv3_1, conv4_1(d)’, ‘conv1_1, conv2_1, conv3_1, conv4_1, conv5_1(e)’ 레이어에서 입력된 이미지를 재구성한 결과를 보여줌
- 깊은 레이어에 대한 정보가 많이 포함될수록 이미지가 가진 전역적인 레이아웃 정보가 아닌, 마지 이미지가 줌인 되는듯한 스타일을 얻어내는 것을 확인 할 수 있음
Loss function의 정의
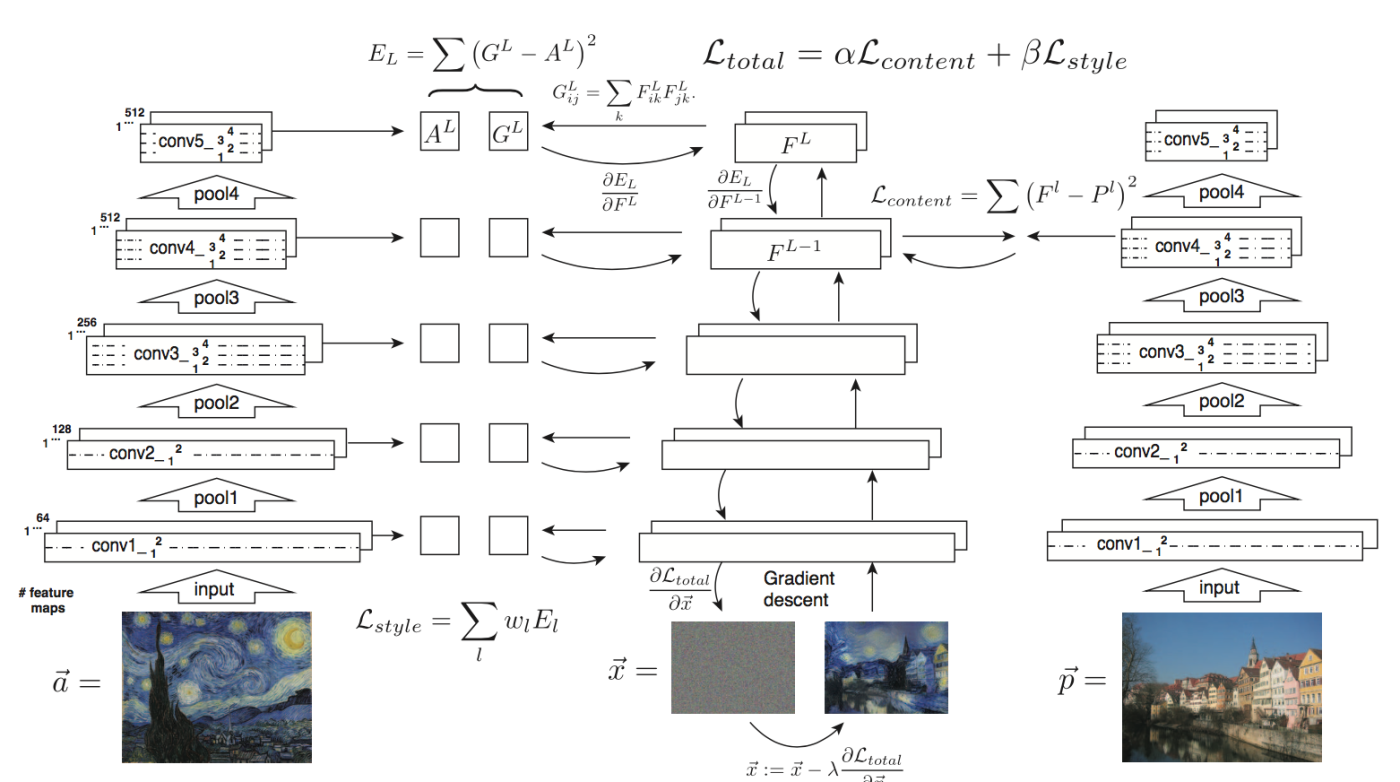
- 실제 style transfer 알고리즘은 아래와 같음
- Content image p, style image a에 대해 합성할 이미지인 x를 noise image로 초기화
- 각 이미지 p, a, x를 ImageNet pretrained VGG19에 foward pass 수행
- 이미지 p와 x에 대해서 content feature 기반의 content loss 계산
- 이미지 a와 x에 대해서 style feature 기반의 style loss 계산
- Content loss와 style loss를 합해 total loss 계산
- Total loss를 back propagation해서 noise image x를 업데이트
- 여기서 네트워크 자체의 weight parameter는 업데이트 되지 않으며, 생성하려는 입력 이미지 x의 픽셀 값들만 아래와 같이 업데이트됨
- $\vec{x}=\vec{x}-\lambda\frac{\partial L_{total}}{\partial \vec{x}}$
Content loss
- Content image p와 합성할 이미지 x 사이의 content loss는 아래와 같이 계산
- 먼저 content image p에 대해
- Content image p를 네트워크에 feed forward
- Content image p를 입력으로 feature map들이 계산된 네트워크에서 레이어 l의 feature map을 P라고 할 때, P는 아래와 같이 정의됨
- $P^l$, where $P_{ij}^{l}$ is the activation value of $i^{th}$ filter at position $j$ in layer $l$
- 마찬가지로 합성할 영상 x에 대해서도 동일하게 정의
- 합성할 영상 x를 네트워크에 feed forward
- 합성할 영상 x를 입력으로 feature map들이 계산된 네트워크에서 레이어 l의 feature map을 F라고 할 때, F는 아래와 같이 정의됨
- $F^l$, where $F_{ij}^{l}$ is the activation value of $i^{th}$ filter at position $j$ in layer $l$
- 레이어 l에서의 content loss는 아래와 같이 정의됨
- $L_{content}(\vec{p}, \vec{x}, l)=\frac{1}{2}\sum_{i, j}(F_{ij}^l-P_{ij}^l)^2$
Style loss
- Style image a와 합성할 이미지 x 사이의 style loss는 아래와 같이 계산됨
- Style image a에 대해
- Style image a를 네트워크에 feed forward
- Style image a에 대한 레이어 l에서의 Gram matrix A는 아래와 같이 정의됨
- $A^l$, where $A_{ij}^l$ is the inner product between $F_i^l$ and $F_j^l$ in layer $l$
- 동일하게 합성될 영상 x에 대해
- 합성될 영상 x를 네트워크에 feed forward
- 합성될 영상 x에 대한 레이어 l에서의 Gram matrix G는 아래와 같이 정의됨
- $G^l$, where $G_{ij}^l$ is the inner product between $F_i^l$ and $F_j^l$ in layer $l$
- 레이어 l에서의 style loss는 아래와 같이 정의됨
- $E_l=\frac{1}{4N_{l}^{2}M_{l}^{2}}\sum_{i,j}(G_{ij}^{l}-A_{ij}^{l})^2$, where $N_l$ is number of feature maps at layer $l$, $M_l$ is height $\times$ width of feature maps at layer $l$
- Style feature의 경우 여러 레이어를 동시에 사용하므로 total style loss는 아래와 같음
- $L_{style}(\vec{a}, \vec{x})=\sum_{l=0}^{L}w_l E_l$, where $w_l$ is weighting factors of the layer to the total loss
Total loss
- Content loss와 style loss를 결합한 total loss는 아래와 같음
- $L_{total}(\vec{p}, \vec{a}, \vec{x})=\alpha L_{content}(\vec{p}, \vec{x})+\beta L_{style}(\vec{a}, \vec{x})$
- 여기서 content loss와 style loss에 대해 각각 가중치를 적용시킴
- 가중치를 어떻게 하느냐에 따라 조금 더 content를 살릴지, style를 살릴지 결정 할 수 있음

- Style loss에 가중치를 크게 주면(좌측 상단) 스타일 중심적인 이미지 x가 생성됨
- Content loss에 가중치를 크게 주면(우측 하단) 컨텐츠 중심적인 이미지 x가 생성됨
구현
- https://www.popit.kr/neural-style-transfer-%EB%94%B0%EB%9D%BC%ED%95%98%EA%B8%B0/