
 Seongkyun Han's blog
Seongkyun Han's blog
MixConv:Mixed Depthwise Convolutional Kernels
15 Nov 2019 | Deep learningMixConv:Mixed Depthwise Convolutional Kernels
Original paper: https://arxiv.org/pdf/1907.09595.pdf
Authors: Mingxing Tan, Quoc V. Le (Google brain)
- 참고 글
- https://www.youtube.com/watch?v=252YxqpHzsg&feature=youtu.be
- https://www.slideshare.net/JinwonLee9/pr183-mixnet-mixed-depthwise-convolutional-kernels
- https://medium.com/@tantara/mixnet-on-tensorflow-lite-94520a89b791
Introduction
- 최근 convolution network design의 트렌드는 네트워크의 정확도와 효율을 모두 높히는 방향으로 연구가 활발히 진행되고 있음
- 이로 인해 다양한 종류의 depthwise convolution들이 연구되어 최근의 CNN모델들에 적용되고 있는 추세
- MobileNets, ShuffleNets, NASNets, AmoebaNet, MnasNet, EfficientNet 등등
- 대부분의 모델들에서 depthwise convolution들을 사용함
- 예전의 CNN들은 주로 3x3 conv layer들을 많이 사용했지만, 최근엔 5x5나 7x7같이 큰 커널 사이즈를 갖는 conv layer들을 많이 사용함
- 큰 커널을 사용하는것이 모델의 정확도나 효율 관점에서 더 좋다는 연구결과들이 있음
- 본 논문에선 “큰 커널을 사용할수록 정확도가 향상되나?” 라는 fundamental한 질문을 던졌음
- Conv layer에서 큰 크기의 커널을 사용할경우 파라미터나 연산량이 증가하더라도 더 디테일한 high-resolution pattern들을 학습할 수 있게 됨
- 반면 작은 크기의 커널을 사용할 경우 low-resolution 패턴을 학습하게 됨
- 이로 인해 큰 크기의 커널을 사용할수록 네트워크가 더 정확하게 동작 할 수 있게 됨
- 저자들은 커널 크기가 계속 커질수록 정확도도 계속 높아질것인가에 대한 질문을 한 것임
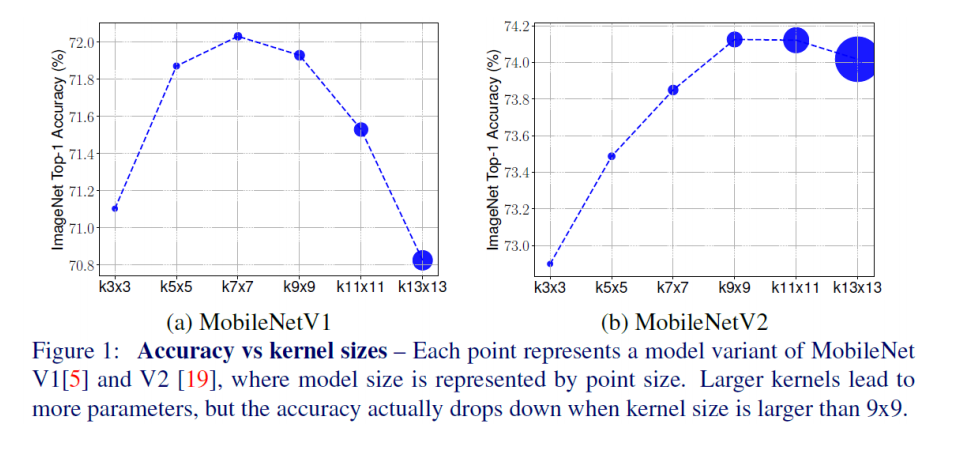
- 위 그림에서 왼쪽은 MobileNet v1의 ImageNet Top-1 정확도 결과를, 오른쪽은 MobileNet v2의 정확도 결과를 보여줌
- x축은 커널 크기, y축은 정확도를 의미
- 그림에서 보이는것처럼 커널 크기가 커지더라도 일정 수준 이상으로 커지게 되면 오히려 정확도가 감소하게 되는 것을 확인 할 수 있음
- MobileNet v1의 경우 7x7 커널 크기를 썼을 때 가장 성능이 좋았으며, v2의 경우 9x9가 가장 이상적인 커널 크기
- 커널의 크기가 input resolution까지 커지는 극단적인 경우를 생각해보면 이는 마치 fully-connected network처럼 동작하는것과 같게 됨
- 입력 영상의 각 픽셀(값)과 커널 파라미터가 1:1 매칭되기때문에 fc layer와 동일함
- 따라서 커널 크기가 extreme하게 계속 커지는것은 성능향상에 도움이 될 수 없음!
- 위 실험결과를 볼 때, 각 네트워크들은 해당 네트워크 구조가 갖는 optimal한 커널 크기 point가 존재함
- 따라서 정확도와 효율의 향상을 위해선 high-resolution 패턴을 학습할 수 있게 해주는 큰 크기의 커널과 low-resolution 패턴을 학습 할 수 있게 해주는 작은 크기의 커널 모두 필요
Related Work
Efficient ConvNets
- 최근들어서 CNN의 효율을 높히기 위한 다양한 연구들이 수행됨
- 특히 mobile-size CNN들에서 depthwise convolution의 인기가 매우 높음
- 일반적인 regular convolution과 다르게, depthwise convolution(=channel-wise convolution)은 각각 채널별로 다른 커널을 이용해 conv 연산을 수행하므로 파라미터 사이즈와 연산량을 줄일 수 있음
- Regular conv는 $k\times k\times c\times n$개의 파라미터를 이용해 $w\times h\times n$ 크기의 feature map을 생성
- k: kernel size, c: channel, n: output channel
- 자세한 내용은 후술
- Depthwise conv는 $k\times k\times 1\times c$개의 파라미터를 이용해 $w\times h\times c$ 크기의 feature map을 생성
- 크기를 regular conv와 동일하게 할 경우, 위 연산 후 poin-wise conv로 채널수만 n으로 맞춰주면 됨
- 이게 MobileNets의 depth-wise separable conv로, 추가되는 파라미터는 $w\times h\times c\times n$개로, 출력 크기는 regular와 같아지지만 실제 연산량 및 파라미터 수는 크게 감소
- $k\times k\times 1\times c+w\times h\times c\times n$
- 자세한 내용은 후술
- Regular conv는 $k\times k\times c\times n$개의 파라미터를 이용해 $w\times h\times n$ 크기의 feature map을 생성
Multi-Scale Networks and Features
- 이미 multi-branch 구조를 갖는 Inception 계열, Inception-ResNet, ResNext, NASNet등의 CNN들이 다양하게 제안되어왔음
- 각 layer에서 multi-branch 구조를 사용함에 따라 단일 convolution layer에서 다양한 연산(다양한 크기의 커널)을 적용시키는게 가능해짐
- 유사하게 DenseNet이나 FPN(feature pyramid network)등에선 서로 다른 layer들에서 생성된 feature map들을 묶어 multi-scale feature map을 만들어 사용함
- 위 구조는 multi-branch 구조가 아니라 skip-connection과 같이 input을 네트워크의 다른부분에서 가져와서 concat해 multi-scale feature map을 생성시킴
- 대부분 기존의 연구들은 이처럼 네트워크의 주된 구조(macro-architecture)를 변경/변형하는 식으로 다양한 conv 연산들을 활용함
- 본 논문에선 네트워크 구조를 그대로 주고, 그 구조 안에서 약간의 변형을 적용시켜 기존의 network들을 좀 더 효율적이게 만드는 방법에 대해 연구함
Neural Architecture Search
- AutoML, NAS
- 최근엔 사람이 만든(hand-crafted) 모델들보다 NAS를 이용해 만든 네트워크들의 성능이 훨씬 좋음
- 네트워크 디자인을 자동화하고 알아서 (사람이 지정해준 기준에 따라)더 나은 디자인을 선택하도록 하기 때문
- 새로운 연산이 추가될 경우, NAS의 search space에 추가해주면 NAS가 알아서 최적의 구조를 찾아줌
- 논문의 저자들도 제안하는 conv 방식(MDConv)을 search space에 추가하고, 효율성과 정확도를 높히는 방향으로 NAS가 최적의 네트워크 구조를 찾도록 했으며, 이를 MixNets(S, M, L)로 정의함
Regular(Normal) Convolution
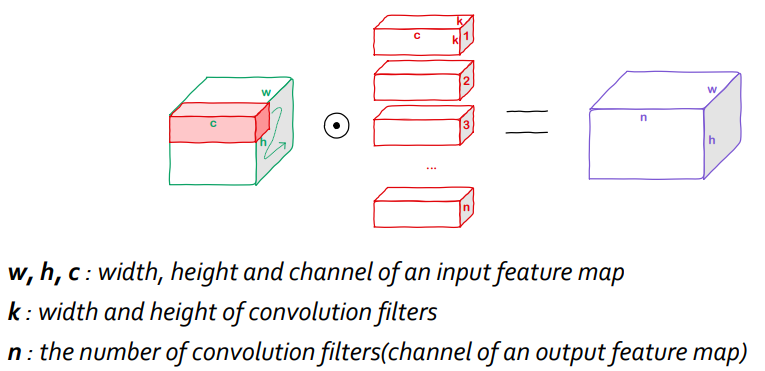
- 일반적인 경우로, output channel인 n개만큼의 커널들을 이용해 sliding window로 구해진 feature map을 만들어내는 과정
- 위 그림에서 순서대로 input, kernels(weight parameters), output feature map
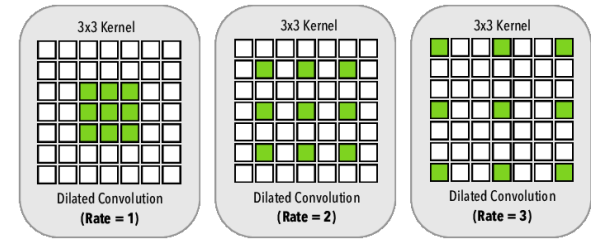
Dilated(Atrous) Convolution
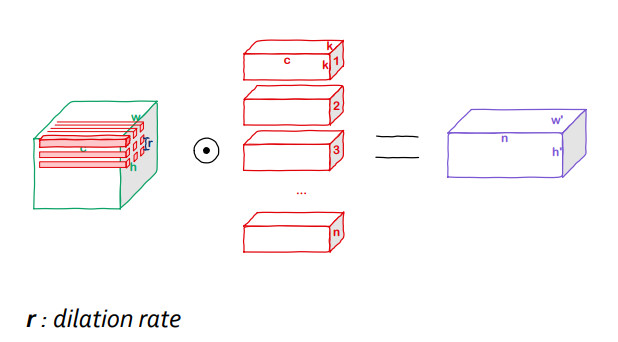
- 일반적인 convolution과 동일하지만 dilation rate를 조절해 파라미터 증가 없이/혹은 최소화하여 conv의 receptive field(RF)를 늘릴 수 있음
- 주로 image segmenataion에서 많이 사용함
Group(ed) Convolution
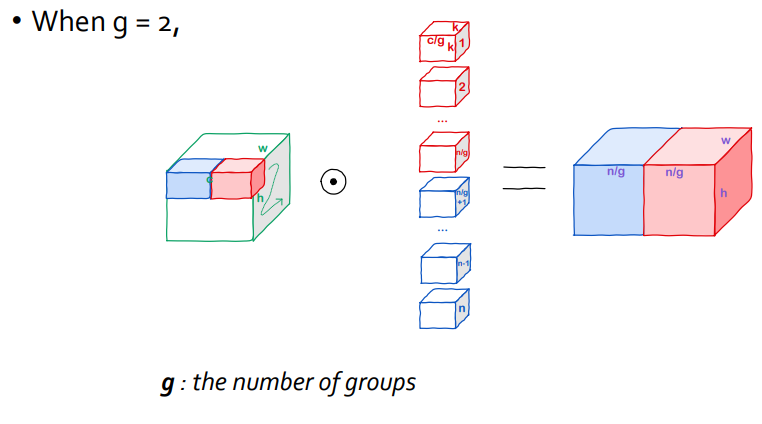
- Input의 channel을 몇 개의 토막으로 나눠서 연산해 feature map을 만드는 경우
- 위 그림은 group=2인 경우이며, 각 group에 대해 최종 결과는 생성된 feature map들을 concat해 완성됨
- AlexNet이 GPU 메모리때문에 채널을 나눠서 연산을 했는데, 나중에 보니 이로인한 정확도 향상이 유의미했기때문에 ResNeXt나 ShuffleNet 등에서도 사용된 방법
Depthwise(Channel-wise) Convolution
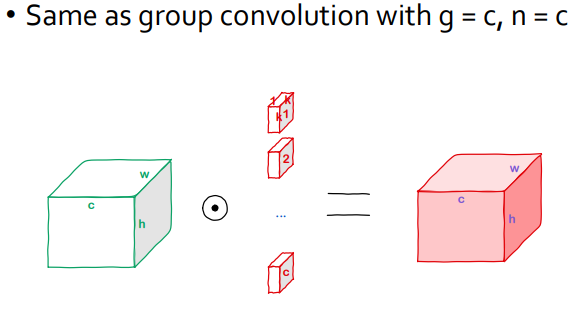
- Group convolution에서 group 수= input 채널 수, filter 수 = input 채널 수 인 경우와 동일함
- 각 커널들은 depth 방향으로 1의 크기만을 갖고, 각 채널별로 연산되 만들어진 feature map들이 depth(channel) 방향으로 concat되어 최종 결과 feature map이 완성됨
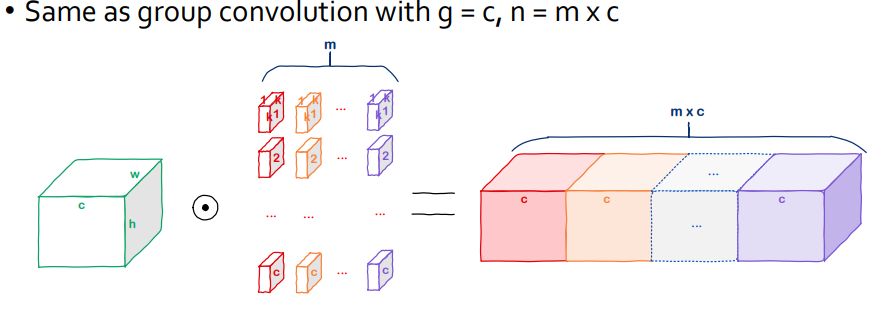
- 위 그림처럼 filter 개수를 조절해서 출력 채널 수를 늘릴 수 있음
- Regular conv와 동일한 크기의 feature map을 만들게 하려면 depthwise conv에서 kernel들을 depth(channel)방향으로 원하는만큼만 쌓으면 됨
- 연산량과 파라미터수 측면에서 동일 크기의 feature map을 만들 때 훨씬 이점이 큰 방식
Mixed Depthwise Convolution (MDConv)
- 본 논문에서 제안하는 방식으로, depthwise conv에서 다양한 크기의 커널을 써서 depthwise conv를 수행함
- 자세한 내용은 후술
Vanilla Depthwise Convolution
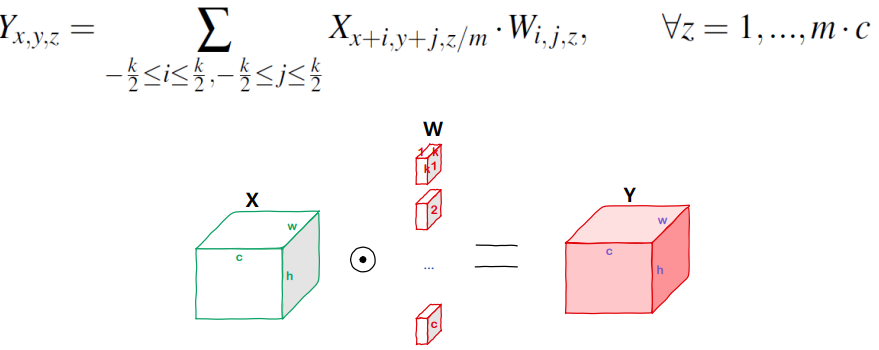
- 위 수식은 총 m개의 채널이 있는 경우를 의미함
MDConv
- 본 논문의 핵심 아이디어로, 앞의 group conv에 depthwise conv를 섞음
- MDConv는 group으로 나뉜 입력 channel에 대해 각 group별 다른 kernel size를 적용시켜 depthwise conv를 수행
- Input tensor $X$가 $g$개의 그룹으로 나뉠 때, 나뉘어진 tensor를 $\hat{X}$라고 하면 아래와 같음
- $<\hat{X}^{(h, w, c_{1})}, …, \hat{X}^{(h,w,c_{g})}>$
- 채널이 $c_1$부터 $c_g$로 총 g개로 나뉘어진 꼴
- $c_1+c_2+…+c_g=c$
- $<\hat{X}^{(h, w, c_{1})}, …, \hat{X}^{(h,w,c_{g})}>$
- 이 때의 출력은 아래와 같이 정의됨
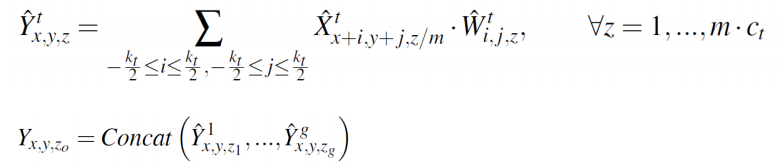
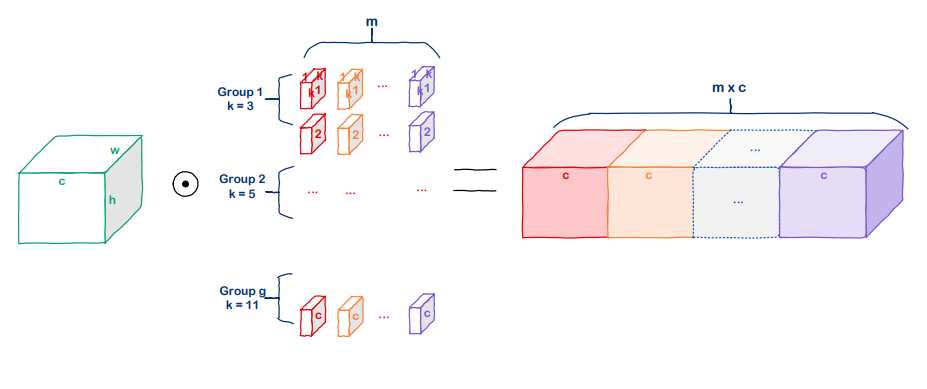
- 각 그룹별로 k는 커널의 크기를 의미함
- 순서대로 3x3, 5x5, …, 11x11의 커널 크기를 사용해 group conv를 수행
- 각 group은 서로 다른 커널 크기를 사용함
- 서로 다른 group에서 만들어진 feature map을 최종적으로 concat해 출력 feature map을 완성
- 커널 크기가 달라질 경우 spatial 방향으로 feature map의 크기가 달라지는데??
- Padding을 조절해서 같은 크기의 feature map이 만들어지도록 함
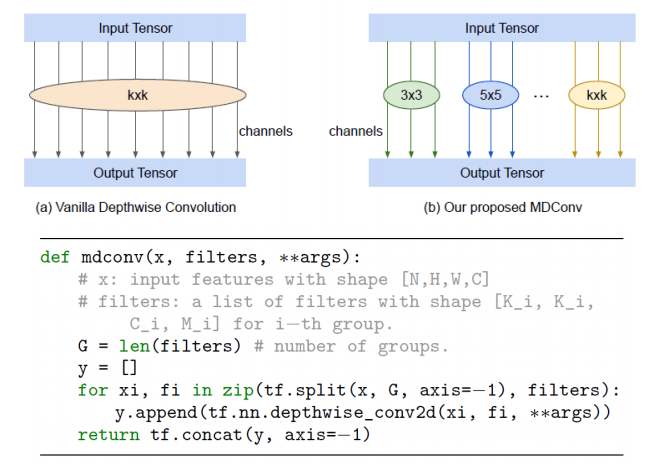
- 좌측 상단의 일반적인 depthwise convolution과 다르게, 제안하는 MDConv는 그룹별로 모두 다른 커널 크기를 적용시켜 생성된 feature map을 concat
- 아래는 Tensorflow를 이용한 MDConv 구현 코드
Design Choices
- Group Size 가 g일때, $g=1$인 경우는 일반적인 depthwise convolution과 동일함
- MobileNets 구조인 경우 $g=4$로 설정하는것이 일반적으로 가장 합리적인 선택이며, NAS를 이용해 생성된 모델들의 경우엔 1~5 사이의 다양한 값들을 이용할 때 더 좋은 정확도를 보임
Kernel Size Per Group
- 이론적으로 각 그룹은 임의대로 결정된 커널 크기를 가짐
- 논문의 저자들은 커널 크기를 3부터 2씩 증가시키며 3, 5, 7, 9, … 로 각 그룹이 사용하도록 설정함
- 즉, 커널 크기는 2i+1로 결정됨
- $g=4$인 경우 MDConv가 사용하는 커널 크기는 3x3, 5x5, 7x7, 9x9가 됨
- 즉, 커널 크기는 2i+1로 결정됨
Channel Size Per Group
- 두 개의 채널 분리(channel partition) 방법이 있음
- Equal partition(주로 사용됨)
- 각 그룹의 채널을 동일하게 할당함.
- $g=4$이고 input channel이 32일 때, {8, 8, 8, 8}로 채널이 분리됨
- Exponential partition
- 각 그룹의 채널이 2의 n승수대로 줄어들며 분할됨 (커널이 커질수록 채널이 점점 감소)
- $g=4$이고 input channel이 32일 때, {16, 8, 4, 4}로 채널이 분리됨
- Equal partition(주로 사용됨)
Dilated Convolution
- 큰 커널을 사용하기 위해 파라미터수를 유지하는 dilated convolution을 적용시켜봄
- 하지만 정확도 결과는 별로였다고 함
실험 결과
MDConv Performance on MobileNets
- ImageNet classification 결과
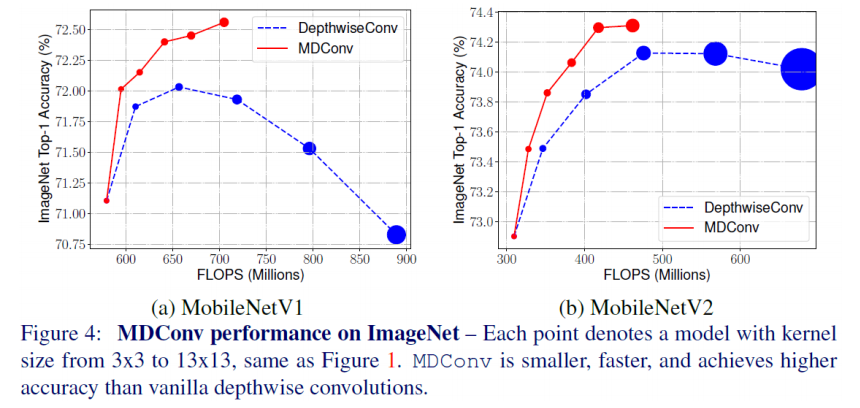
- 위의 각 그래프에서 점들은 커널 사이즈를 의미하며, 왼쪽에서 오른쪽으로 3, 5, 7, 9, 11의 커널 크기를 사용했을때의 연산량과 정확도임
- MobileNet v1과 v2 모두 일반적인 depthwise conv말고 MDConv 적용시켰을 때(커널 크기를 섞어 썼을 때) 성능이 제일 좋았음
Object detection
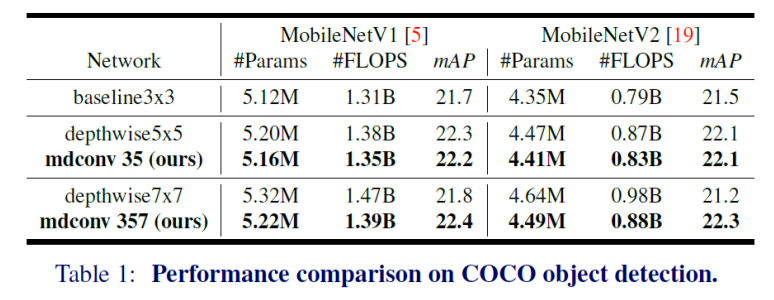
- 대부분의 경우 제안하는 모델을 backbone으로 썼을 때 정확도가 높았음
- 또한 파라미터수는 오히려 줄음
Ablation Study
- MDConv for Single Layer
- MobileNet v2에 대해 각 레이어를 MDConv로 대체했을 때의 정확도 변동률을 보여줌
- MobileNet v2는 원래 3x3 conv만 사용하지만 실험 처음에 9x9에서 가장 효율이 좋았으므로 해당 레이어를 9x9 depthwise conv로 바꿨을 때의 정확도 변동을 실험함
- 동일하게 9x9 depthwise conv말고 MDconv3579(커널 크기 3, 5, 7, 9)로 바꿨을 때의 정확도 변동을 실험
- MobileNet v2에 대해 각 레이어를 MDConv로 대체했을 때의 정확도 변동률을 보여줌
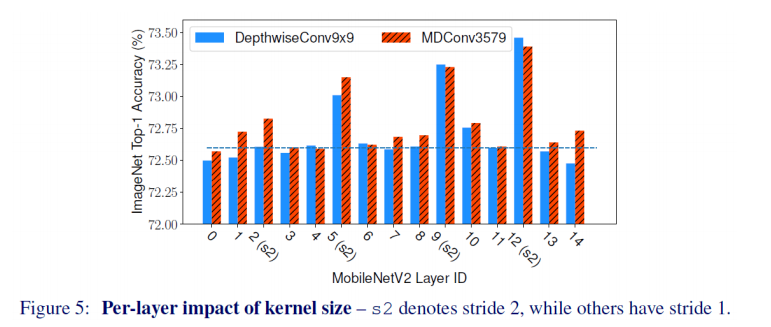
- 실험 결과를 볼 때, stride=2일 때 kernel size를 키우거나 MDConv를 적용시켰을 때의 정확도 향상이 가장 좋았음
- 전반적으로 MDConv를 적용시켰을 때의 정확도 향상이 가장 좋았음
Channel Partition Methods & Dilated Convolution
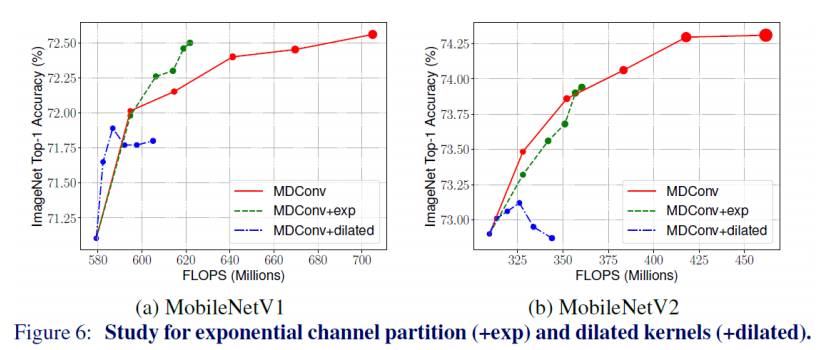
- 위 그림에서 초록 선은 exponential partition, 빨간 선은 equal partition, 파란 선은 dilated conv 적용시켰을 경우를 의미
- 각 point들은 오른쪽으로 갈수록 partition 갯수가 많아지거나, dilated rate가 커져 RF가 증가하게 됨을 의미
- Channel partition의 경우 base model의 경우에 따라 exp가 나을수도, equal이 나을수도 있음
- Dilated convolution은 성능향상에 도움 되지 않음
MixNets
- 앞에서 MDConv에 의한 효과가 검증 되었으니, NAS(AutoML)를 이용해 MixNet을 찾아냄
- MDConv-based model을 찾도록 함
- 최근의 연구들과 동일하게 논문에선 ImageNet train set을 이용해 직접적으로 3개의 모델을 NAS가 뽑도록 함
- ImageNet validation set과 transfer learning dataset 결과를 이용해서 선택
- 정확하고 연산량이 적을수록 score를 크게 부여하여 고르게 함
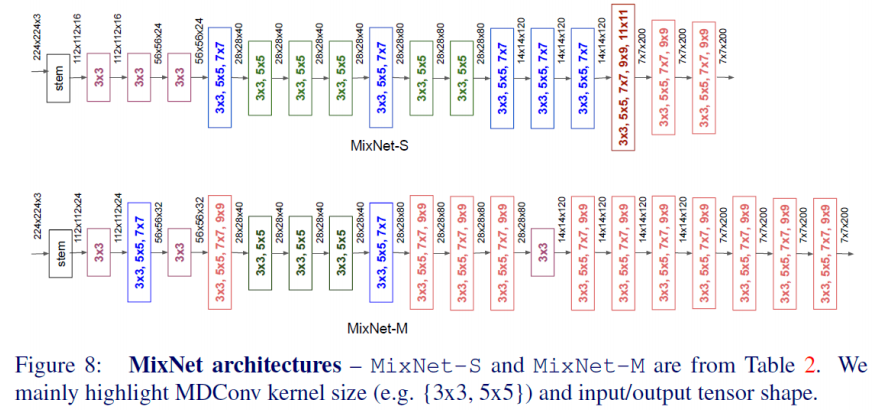
Architecture
- 네트워크의 초기엔 연산량 보존을 위해 작은 크기의 커널들을 사용하게 했으며, 뒤쪽으로 갈수록 정확도 향상을 위해 큰 크기의 커널 사이즈를 사용함
- MixNet-M이 더 큰 커널을 사용하며, 이로 인해 정확도는 좋지만 연산량(FLOPs)이 더 큼
MixNets Performance on ImageNet
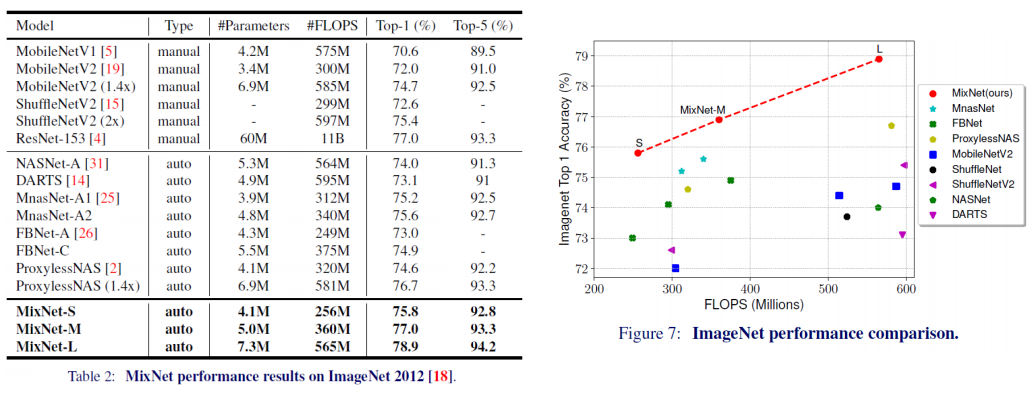
- 위에서 확인 가능하듯이 제안하는 MixNets가 파라미터를 적게 사용하면서도 높은 정확도를 보임
- 논외로, 우측 그림에선 전반적으로 hand-crafted model들보다 AutoML을 사용해 만들어진 모델들의 성능이 좋은것을 확인 할 수 있음
Transfer Learning Performance
- 요즘 논문들 추세로, 제안하는 방법의 성능을 classification + object detection + transfer learning으로 3단계로 검증함
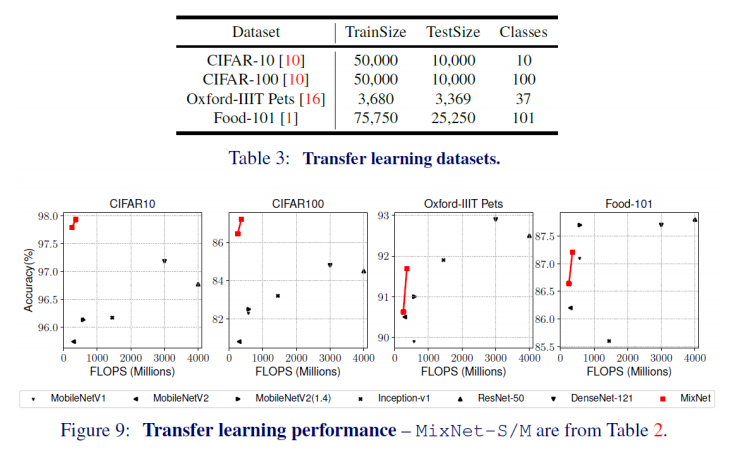
- 실험에선 MixNet S와 M만 사용(왼쪽 점이 S, 오른쪽 점이M)
- 위 그림에서 CIFAR-10과 CIFAR-100의 실험 결과가 가장 유의미함
- 다른 모델과 확연하게 차이날정도로 결과가 좋은것을 알 수 있음
Conclusion
- 논문에선 depthwise convolution의 kernel size에 대한 영향력을 실험했고, 그 결과 단일 kernel size 사용의 한계점을 확인했음
- 논문에선 단일 conv operation에서 다양한 kernel size를 사용할 수 있는 MDConv를 제안함
- MDConv는 일반적인 depthwise convolution을 간단하게 교체해 기존의 모델들에 손쉽게 적용 가능하며, 정확도가 향상되고 모델의 효율이 좋아짐(정확도는 커지고 모델 파라미터수와 연산량은 줄어듦)
- 마지막으로, NAS를 이용해 MixNets(S, M, L)를 제안했으며, MixNets은 최근의 mobile CNN들과의 성능 비교했을 때 정확도와 효율 측면에서 매우 뛰어난 성능을 보였음