
 Seongkyun Han's blog
Seongkyun Han's blog
YOLOv3:An Incremental Improvement
20 Nov 2019 | Deep learningYOLOv3:An Incremental Improvement
Original paper: https://arxiv.org/abs/1804.02767
Authors: Joseph Redmon, Ali Farhadi
- 참고 글
- https://www.youtube.com/watch?v=HMgcvgRrDcA
- https://www.slideshare.net/JinwonLee9/pr207-yolov3-an-incremental-improvement
Background
IoU & mAP
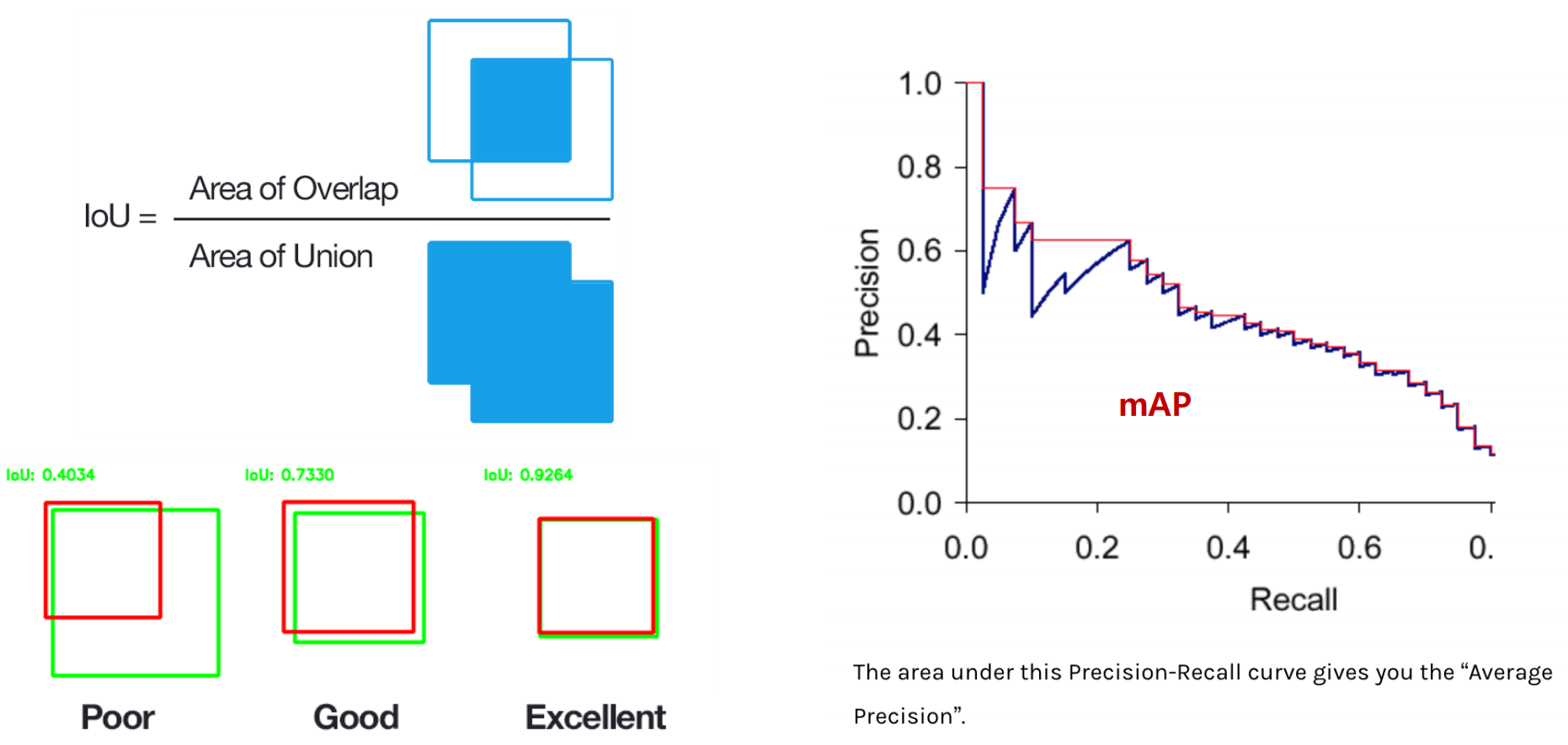
- mAP란?
- Precision-Recall 그래프에서 빨간 선 기준으로 아래 면적이 Average Precision(AP)
- Precision이 특정 값으로 fix 되었을 때의 recall값을 plot
- Recall: 해당 precision을 기준으로 찾아진 정답의 rate
- Precision이 특정 값으로 fix 되었을 때의 recall값을 plot
- 각 클래스간 평균이 mean Average Precision, mAP가 됨
- Precision-Recall 그래프에서 빨간 선 기준으로 아래 면적이 Average Precision(AP)
Indroduction
- 본 논문은 일종의 tech report 개념
- YOLO의 성능을 개선시켰지만 super interesting한 결과는 아님
- 작은 changes들을 모아서 성능을 개선시킨 정도
- 빠르진 않지만, 더 낫고 강력한 성능을 가짐
- 저자는 자기 트위터 끊었다고 더이상 태깅하지 마라…고 함
Bounding Box Prediction
- YOLOv2와 동일
- 미리 Anchor box 정의 후, regression을 통해 얼마나 움직일지에 대한 부분을 예측
- YOLOv3는 anchor box역할을 하는 dimension cluster들을 이용해 bounding box들을 예측함
- 네트워크는 4개의 box값을 예측하며, 각각 $t_x, t_y, t_w, t_h$로 x, y 위치와 width, height를 의미함
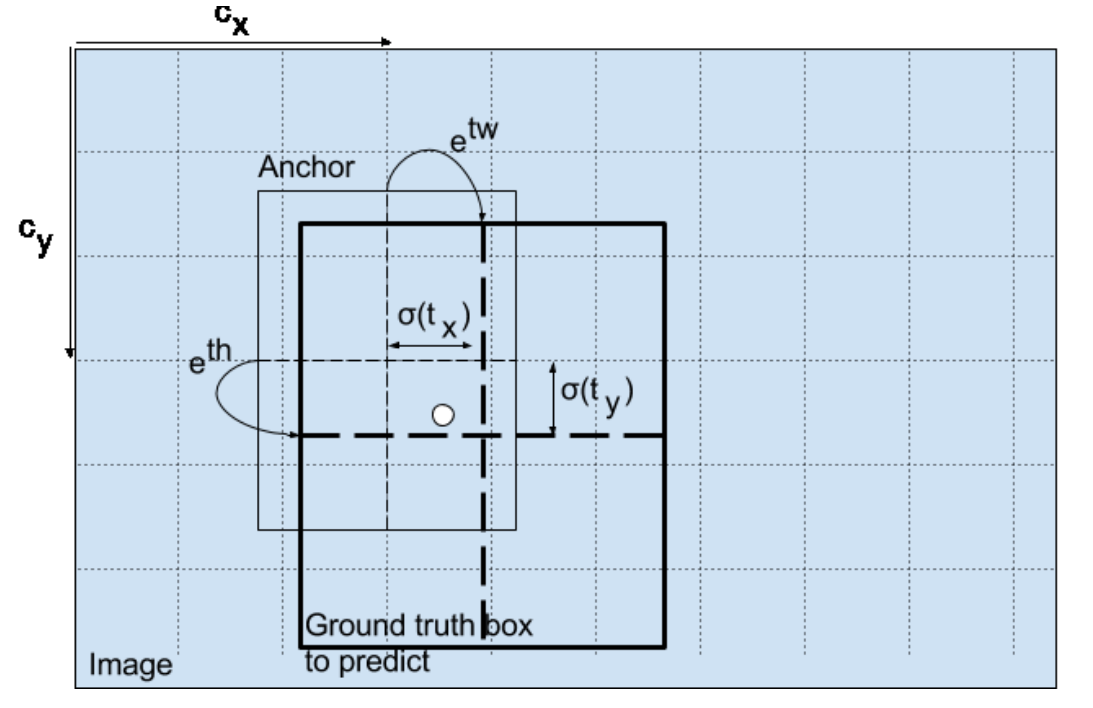
- Box prediction은 추론된 rough한 박스 좌표를 정확한 GT값으로 맞춰주는 일종의 regression이므로 squared error loss를 사용함
- $b_x=\rho(t_x)+c_x$
- $b_y=\rho(t_y)+c_y$
- $\rho$: Sigmoid function
- 실제 움직여야 하는 값을 나타니는 $t_x, t_y$는 sigmoid에 의해 0~1사이의 값으로 매핑됨
- 즉, bounding box의 중심은 다을 칸(다른 grid cell)로 벗어날 수 없음
- $b_w=p_w e^{t_w}$
- $b_h=p_h e^{t_h}$
- Width와 height에 대한 term
- $t_w, t_h$는 각각 width와 height로 얼만큼 움직여야하나를 의미
- 원래 결과인 $p_w$와 $p_h$에 exponential term으로 곱해짐
- YOLOv3는 각 bounding box가 갖고있는 일종의 confidence인 objectness score를 이용해 객체의 위치를 탐지
- Logistic regression을 통해 objectness score는 0~1사이 값을 갖게 됨
- GT와 가장 많이 겹치는 box prior의 objectness score는 1이 되도록 설정됨
- 일반적인 SSD등의 방법에서 background class와 hard negative mining을 사용하는것과 다름
- YOLOv3는 각 GT에 대해 bounding box가 1개씩 할당됨
- 이로인해 background class와 hard negative mining이 필요없음
- 해당 알고리즘은 오탐되는경우에 대해 background class의 정보량이 너무 많아저 imbalance를 줄이고자 학습과정에서 적용되는 방법임
- 다른 방법들은 GT와 IoU가 가장 큰 것 + IoU가 0.7(일반적으로)이상 되는 것 전부 다 box를 치게 됨
- 정답이 아닌 경우 모두 background로 할당되로, 이로인해 background class의 정보량이 증가해 별도 처리(hard negative mining)를 하지 않으면 학습이 불가능하게 됨
- 이로인해 background class와 hard negative mining이 필요없음
Class Prediction
- 다음으로 YOLOv3는 영상 내 찾아진 객체들의 위치에 대해 multilabel classification을 수행
- 일반적으로 COCO 기준 80개 class를 할당해 softmax를 수행해 하나의 class를 찾음
- 이 논문은 80개의 class별로 각각 확률을 sigmoid를 취해 binary classification을 수행함
- 이로인해 multiclass classification이 되도록 함
- 왜 구지 multiclass classification?
- Google openimage dataset과 같은 데이터셋을 위한 처리
- 600개 클래스로 중복되는 상위-하위 클래스가 포함됨
- Person의 경우 women처럼 hierarchical한 클래스들이 존재하는 경우, 여러 클래스를 동시에 고려해야하므로 binary classification이 적용됨
- Google openimage dataset과 같은 데이터셋을 위한 처리
Predictions Across Scales
- 3가지 scale에 대해 3개의 bounding box(aspect ratio)를 사용함
- 3x3으로 총 9개의 bounding box들을 추론
- Scale에 따라 resolution이 바뀌므로 정확하게 9개라고 보기에는 조금 애매함
- 이 때 찾아진 tensor size는 $N\times N\times(3\times(4+1+80))$
- $N\times N$: NxN개의 grid cell들
- 3: 3개의 scale에서 bounding box 찾기
- 4: x, y, w, h
- 1: objectness score
- 80: MS COCO classes score
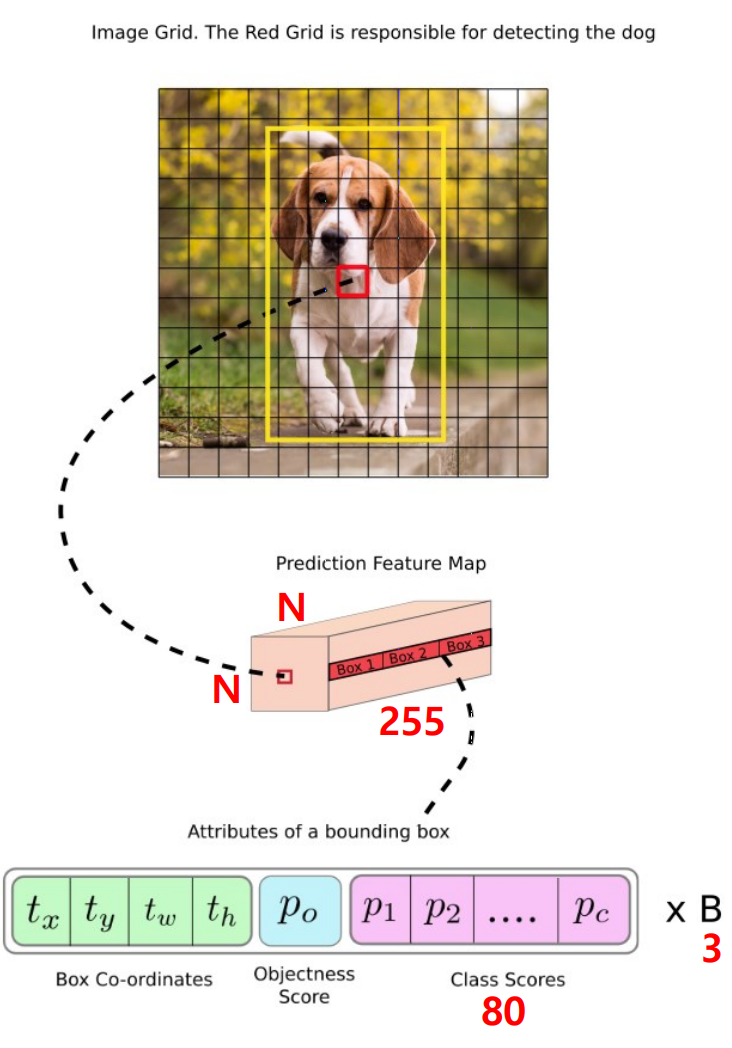
- 위 그림에서 grid cell이 총 NxN개가 존재한다고 하면(개 사진)
- 빨간색으로 칠해진 해당 grid cell에서 해당 scale에서의 aspect ratio로 정의된 크기의 anchor box 3개를 뽑게 됨
- Depth 방향으로 (4+1+80)x3 으로 총 255의 depth가 쌓임
Anchor Boxes
- 기존의 방법(SSD나 RCNN)들은 정해진 aspect ratio 사용
- k-means clustering으로 얻어진 aspect ratio를 이용해 해당 비율을 갖는 객체만 찾게 됨
- YOLO는 갖고있는 training set을 분석해서 anchor box의 aspect ratio를 정함
- MS COCO기준 scale별로 총 9개의 cluster를 정함
- Small: 10x13, 16x30, 33x23
- Medium: 30x61, 62x45, 59x119
- Large: 116x90, 156x198, 373x326
Number of Bounding boxes
- YOLOv1: 98 boxes (7x7 cells, 2 boxes per cell @448x448)
- YOLOv2: 845 boxes (13x13 cells, 5 anchor boxes @416x416)
-
YOLOv3: 10,647 boxes (@416x416)
- YOLOv3는 10배정도 많은 box들을 사용함
- 1-stage 성능 높히기 위해선 피할 수 없는 선택!
Feature extraction
- Darknet-53 사용
- 아래 표에서 BFLOP/s 는 1초당 가능한 연산량을 의미
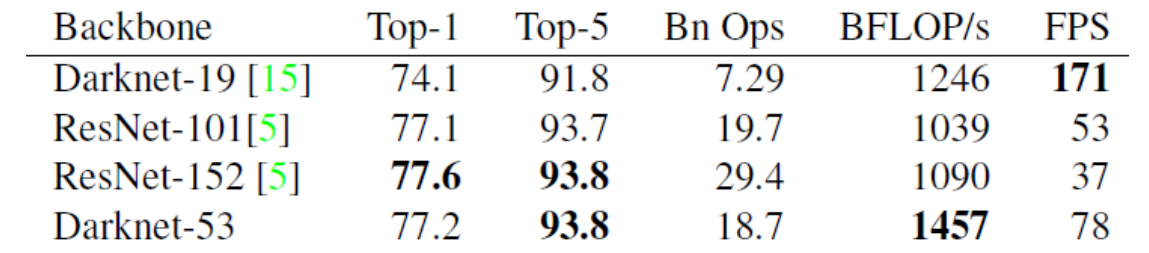
- Darknet-53이 속도와 연산량 측면에서 ResNet-152보다 1.5배정도 나은 성능을 보이며, 정확도도 비슷하고 속도는 2배정도 빠름
- Darknet-53은 1초당 가능한 연산량이 가장 큼(floating poing operations per second)
- 이는 제안한 구조가 GPU를 가장 잘 활용하는것을 의미함
- 이로인해 더 빠르고 효율적으로 동작
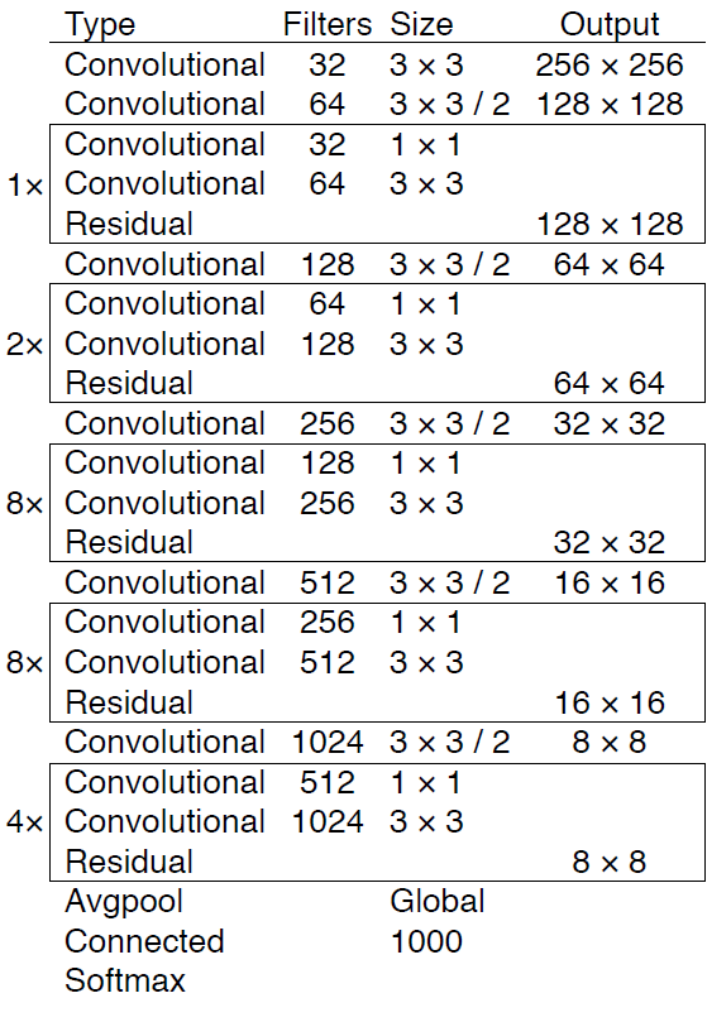
YOLOv3 Architecture
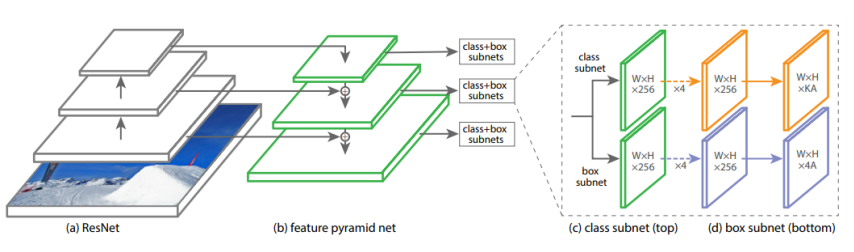
- YOLOv3는 위와 같은 일반적인 FPN과 구조가 비슷함
- 위 그림의 왼쪽은 일반적인 SSD와 같은 구조로, feature extractwor의 앞쪽에서 나온 feature map은 표현력이 부족함
- 이를 보완하기 위해 우측처럼 다시 deconvolution으로 feature map의 크기를 확장시켜 high-level feature를 뽑도록 함
- 왼쪽과 오른쪽의 feature map을 concat해서(왼쪽에서 위치정보 등을 갖고오는 식으로) 표현력을 향상시켜 사용함
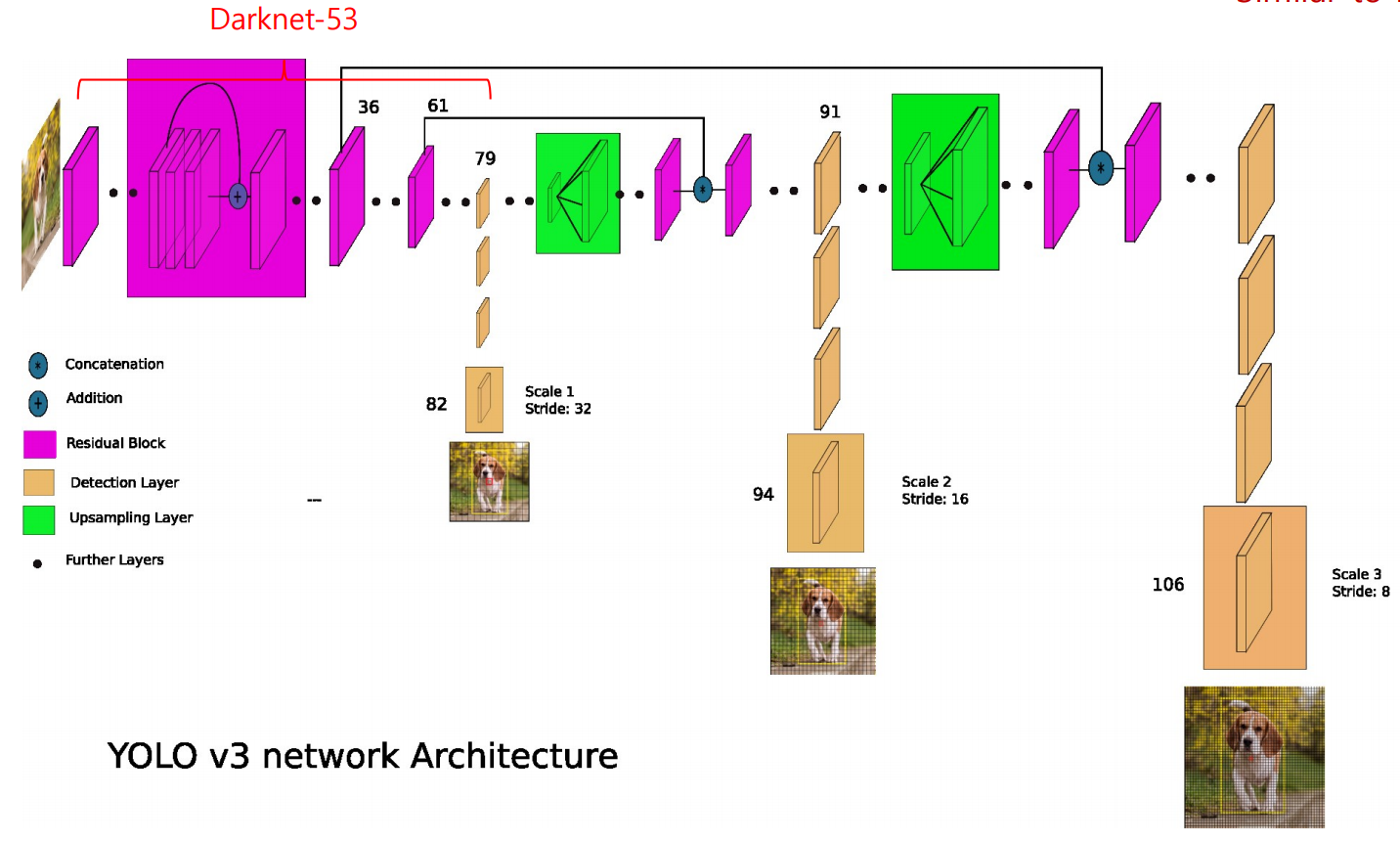
- 위 그림은 YOLOv3의 구조로, FPN과 거의 유사한 구조
- 왼쪽부터 오른쪽으로 순서대로 가장 큰 객체, 중간 크기 객체, 가장 작은 객체를 찾도록 할당됨
- 각각 feature extractor에서 생성된 feature map을(가로 방향) detection layer를 거쳐(세로 방향) 객체를 찾게 됨
Training
- 일반적인 네트워크들과 다르게 hard negative mining의 적용 없이 전체 이미지를 학습시킴
- Hard negative mining은 detection시 뽑힌 bounding box중 실제 제대로 탐지된 객체의 갯수가 매우 적어 background class에만 데이터량이 매우 많아 네트워크가 학습되지 않는 현상을 방지하기 위해 적용됨
- YOLO 계열은 대신 objectness score로 1개의 GT를 탐지하는 bounding box를 이용해 네트워크가 학습되므로 background class와 hard negative mining이 필요 없음
- Objectness score를 갖고 thresolding을 통해 GT와 가장 많이 겹치는것을 1로 설정해 남기고 나머지를 날리게 됨
- 이로 인해 hard negative mining이 필요 없음
- Objectness score를 갖고 thresolding을 통해 GT와 가장 많이 겹치는것을 1로 설정해 남기고 나머지를 날리게 됨
- Multi-scale training, data augmentation 방법들, batch normalization등과 같은 일반적인 normalization, regularization 방법들을 적용시켜 네트워크를 학습시킴
- Multi-scale training은 이미지를 다양한 resolution으로 scaling하여 물체의 크기에 대한 정보를 증대시킴(학습 정보량 증가)
Result
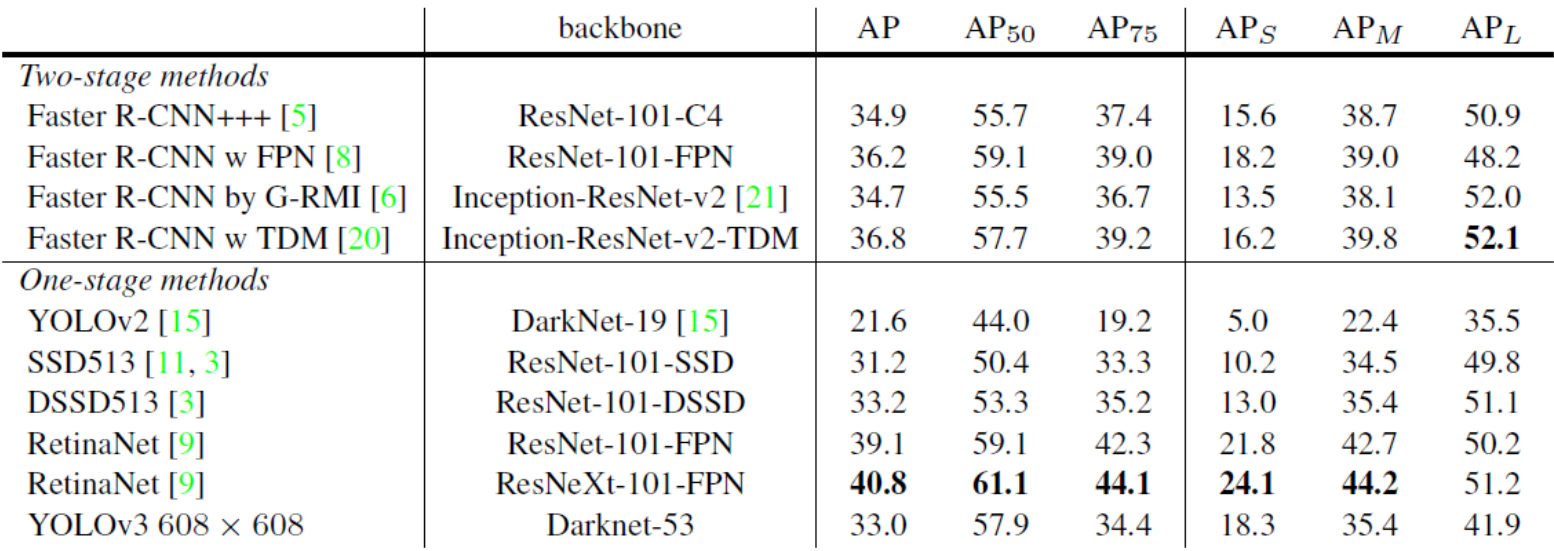
- RetinaNet보다는 성능이 좋진 않지만, 이건 비합리적인 MS COCO Metric의 문제라고 줄기차게 말함
- IoU threshold를 0.5부터 0.95까지 0.05단위로 쪼개서 테스트하고 평균을 때리는 방식 자체가 불합리하다고 함
- 고정된 IoU threshold를 사용하는게 오히려 합당하다고 함
- 그리고 그 때 YOLOv3의 성능이 제일 합리적이다(속도대비)
- IoU=0.5(AP50)처럼 고정된 IoU thresold를 사용할 경우, YOLOv3의 성능은 매우 좋음
- Multi-scale prediction에 대해서도 YOLOv3의 AP는 상대적으로 높음
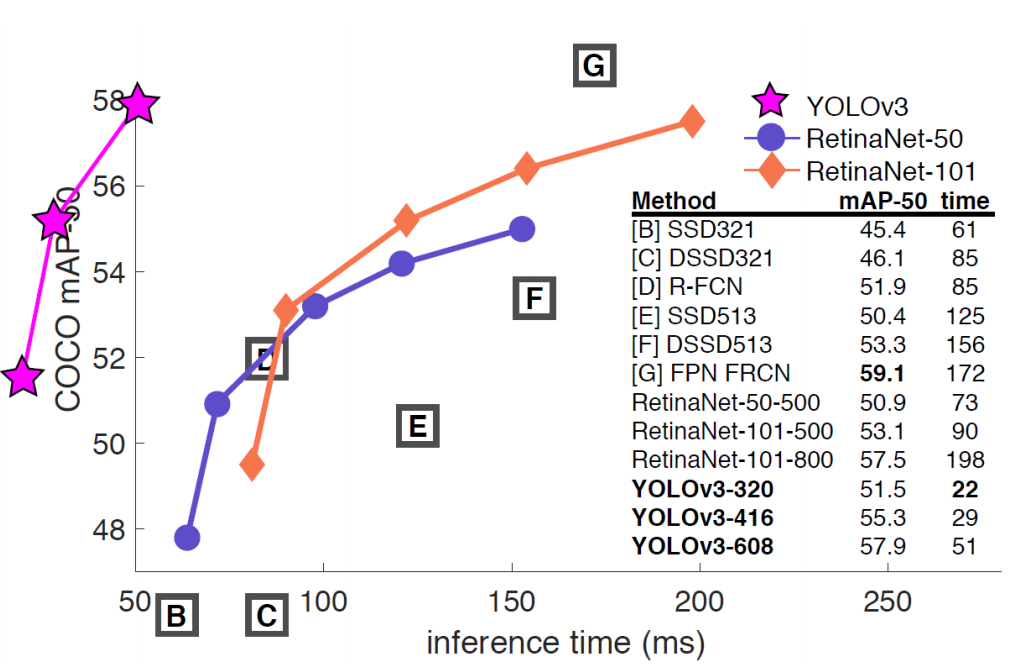
- 저자는 일부러 속도대비 성능이 좋다는걸 강조하기위해 RetinaNet의 그래프를 그대로 가져다가 표현함
- 위 그래프는 IoU threshold 0.5 기준 결과임
Things We Tried That Didn’t Work
- 실험했지만 도움되지 않았던 방법들
- Anchor box x, y offsets predictions
- $d_x, d_y$를 width, height의 비율로 계산하게 했더니 오히려 성능이 나빠짐
- $\hat{G}_x=P_w d_x(P)+P_x$
- $\hat{G}_y=P_h d_y(P)+P_y$
- $\hat{G}_w=P_w exp(d_w(P))$
- $\hat{G}_h=P_h exp(d_h(P))$
- $d_x, d_y$를 width, height의 비율로 계산하게 했더니 오히려 성능이 나빠짐
- Linear x, y, predictions instead of logistic regression
- Linear regression으로 x와 y좌표를 직접 뽑게 했더니 성능이 오히려 나빠짐
- Focal Loss
- RetinaNet에서 나온 loss function으로, class별 imbalance한 정보량을 해결하기위한 방법
- YOLOv3에 적용시킨 결과 오히려 mAP가 2점정도 떨어짐
- Dual IoU threshold and truth assignment
- Faster R-CNN에서 나온 방법
- Thresold가 0.3미만은 negative, 0.7이상은 positive, 나머지는 버림으로 처리함
- 적용시킨 결과 성능이 하락함
What This All Means
- YOLOv3은 진짜 좋은 detector라고 함
- 빠르고 정확하니까
- MS COCO Metric의 IoU threshold 기준인 0.5:0.95:0.05 는 정말 비합리적이고 최악
- 하지만 오래된 방식인 PASCAL VOC(IoU=0.5)의 성능은 굉장히 좋았음
- Russakovsky et al. 논문에서는 사람한테도 IoU threshold가 0.3일때와 0.5일때를 학습시키고 구분짓게 했더니 사람도 잘 못했다고 함
- 즉, COCO가 thresold를 0.5:0.95:0.05로 하는건 비합리적이고 좋지 못한, 구지 그렇게 해야하나 싶은 방법이라고 주장함
Rebuttal
- RetinaNet의 논문들은 non-zero point에서 그래프가 시작함
- 0부터 그래프가 시작되도록 plot하면 아래와 같음
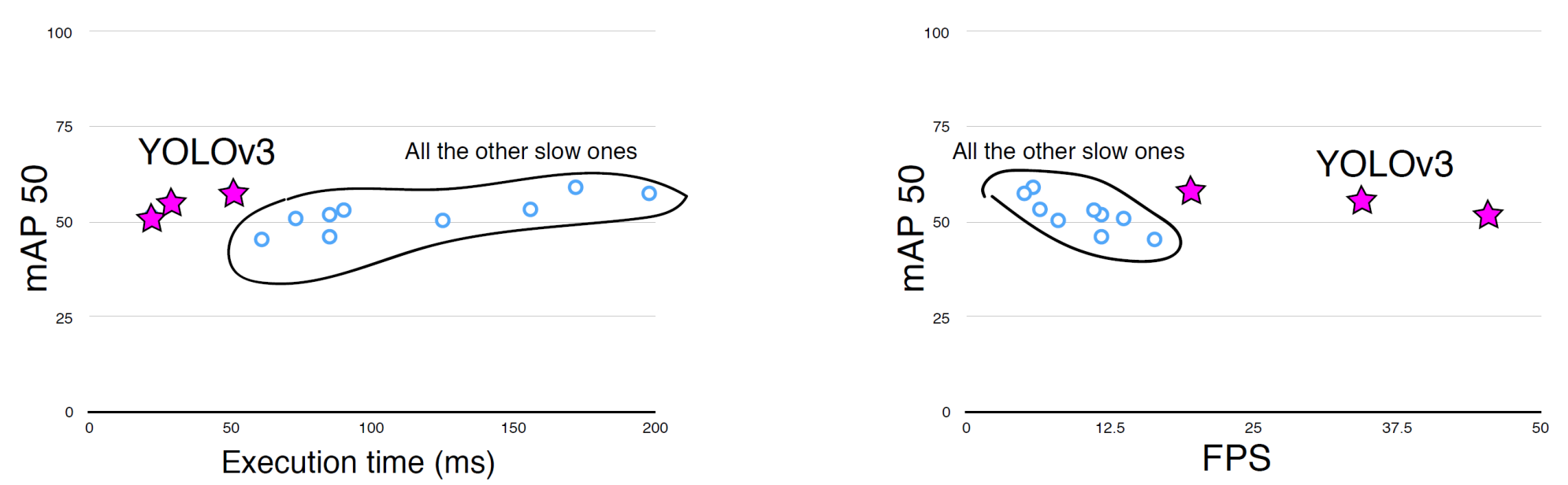
-
연산시간도 훨씬 빠르고, FPS도 훨씬 좋은 결과를 확인 할 수 있음
- PASCAL VOC가 0.5를 threshold로 쓴 건 Ground-Truth(GT) bounding box가 inaccuracy가 포함되어있기에 고의적으로 낮은 IoU thresold를 사용한 것임
- COCO는 segmentation mask가 포함되어 있어 PASCAL VOC보다는 레이블링이 잘 되어있긴 하나, 아직도 mAP 평가방식이 합리적이라는 이유는 설명될 수 없음
- IoU thresold가 0.5보다 높아야 한다는, 더 bounding box를 잘, 정확하게 그려야한다는 정당성을 부여할 이유는 되지 못함
- 만약 detection model이 분류를 정확히 했는데 bounding box를 조금 잘못 친 경우, threshold가 높은 경우 틀렸다고 판단하게 된다면 그게 옳은 판단이라고 볼 순 없음
- 이는 classification이 box regression보다 덜 중요하다 하는것인데 말이 안됨
- 사람이 보기에도 classification을 잘못한것은 명확하지만, bounding box를 잘못 친것은 덜 분명하게 파악함
- 따라서 bounding box를 그렇게 tight하게 판단하는것은 옳지 못함
mAP’s Problems
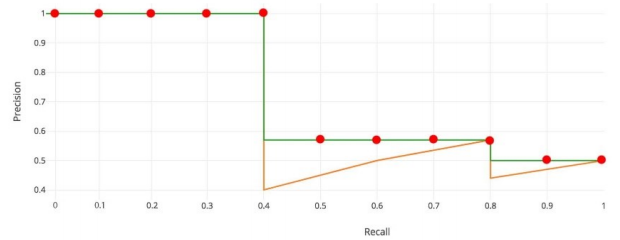
- 위 그래프는 실제 mAP를 측정하는 Precision-Recall graph
- Precision을 높히면 recall은 줄어들게 되는 구조
- 실제 그래프는 금색 선이지만, 계산시엔 구간 최댓값을 나타내는 초록색 선 아래의 면적으로 계산하게 됨
- 구간 최댓값
- 만약 Precision이 1일 때 Recall이 1이 된다면, 위 그래프의 mAP는 1이 됨
- 오탐 결과들(초록색 선 밑의 금선)을 반영하지 못하는 metric 방법
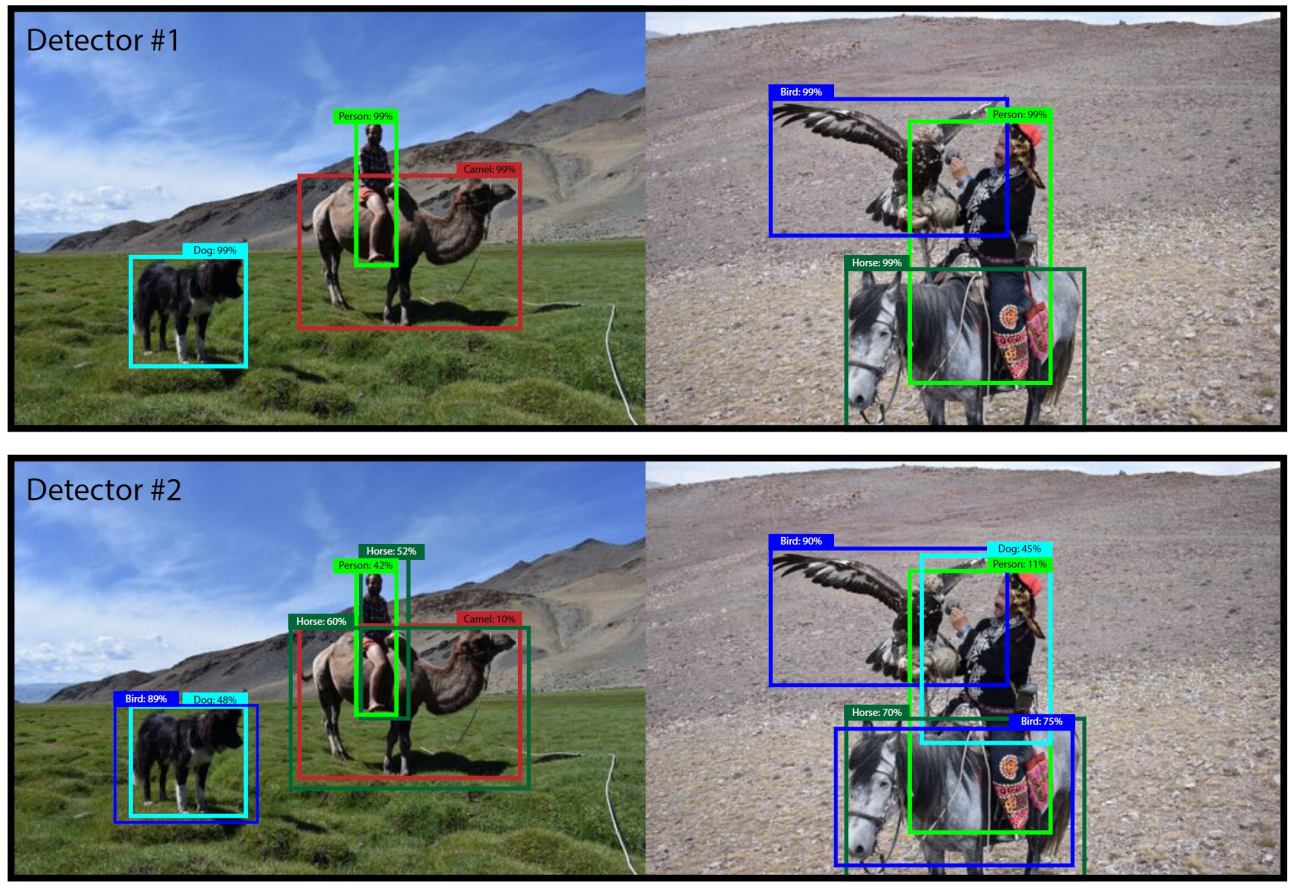
- 실제 위 그림에서, Detector 1과 2의 mAP는 모두 1로 동일함
- 모두 각 객체의 위치에 낮은 확률(precision)로라도 box를 그렸기 때문
- 하지만 2번 detector는 명백하게 오탐한 결과들이 존재하지만, mAP metric에선 이를 반영하지 못함
A New Proposal
- mAP는 class별 AP를 평균 낸 결과이므로 엉망임
- 이렇게 class별로 따로 하지 말고, 전체 클래스를 다 한번에 계산하는 global average precision을 사용한다면 더 합리적일 것
- 또는 mean을 하긴 하되, class가 아니라 image별로(per-image) 평균을 내는것이 더 합리적일 것
- 이미 AP 자체가 Average Precision으로, 여기에 class별로 평균을 또 때려 이를 mean을 붙이는것 자체가 바보같은 일이라고 함
- 결론적으로, bounding box를 그리는건 멍청한 일이고, mask가 굉장히 합리적인 방법이라고 생각
- YOLO는 masking을 하도록 학습시킬 수 없지만 저자는 mask의 true believer(신봉자)라고 함..
- 전반적으로 특이한 논문