
 Seongkyun Han's blog
Seongkyun Han's blog
EfficientDet:Scalable and Efficient Object Detection
25 Nov 2019 | Deep learningEfficientDet:Scalable and Efficient Object Detection
Original paper: https://arxiv.org/pdf/1911.09070v1.pdf
Authors: Mingxing Tan, Ruoming Pang, Quoc V. Le (Google)
- 참고 글
- https://hoya012.github.io/blog/EfficientDet-Review/
Introduction
- EfficientNet 이 classification task를 타겟으로 작성된 논문이라면, 본 논문은 object detection task를 타겟으로 작성된 논문
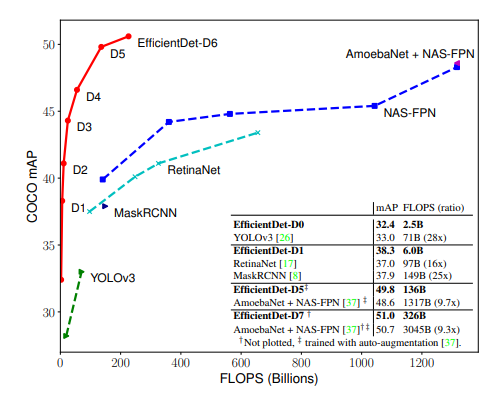
- 위의 MS COCO 결과를 볼 때, Feature Pytamid Network(FPN) 구조와 AutoML로 찾은 무거운 backbone인 AmoebaNet을 섞어서 사용한 모델이 COCO에서 가장 좋은 성능을 보임
- 제안하는 방법은 이러한 AutoML 기반의 모델들의 성능을 크게 상회함
- 특히 연산량, 연산 속도 관점에서는 굉장히 효율적인 모델을 제안함
Main Challenge and Solution
- Speed와 accuracy는 서로 trade-off 관계를 갖기 때문에(참고) 높은 정확도와 효율을 동시에 가져가기는 어려움
- 본 논문에서는 object detection에서 속도와 정확도를 모두 높게 가져가는 모델을 설계할 때 고려해야 할 점 중 크게 2가지를 challenge로 삼음
Challenge 1. Efficient Multi-scale Feature Fusion
- FPN은 2017년 공개된 이후 대부분의 object detection 연구에서 사용되고 있음
- 1-stage detector의 대표 모델인 RetinaNet, M2Det, AutoML의 NAS를 FPN구조에 적용한 NAS-FPN등 FPN을 적용하고 성능을 개선하고자 하는 연구들이 많이 진행되어옴
-
하지만 본 논문에선 이러한 선행 연구들이 모두 서로 다른 input feature들을 합칠 때 feature의 구분없이 단순히 더하는 방식을 사용하고 있음을 지적함
- 논문에선 서로 다른 input feature들은 해상도(resolution)가 서로 다르기에 output feature에 기여하는 정도를 다르게 가져가야 함을 주장함
- 단순히 더하게 되면 같은 weight로 기여하게 됨
- 이를 위해 간단하지만 효과적인 weighted bi-directional FPN(BiFPN) 구조를 제안함
- BiFPN 구조를 사용하면 서로 다른 input feature들의 중요성을 학습을 통해 배울 수 있으며, 이를 통해 성능을 많이 향상시킬 수 있음
- 자세한 구조는 후술
Challenge 2. Model Scaling
- EfficientNet에서 제안한 Compound Scaling 기법은 모델의 크기와 연산량을 결정하는 요소들(input resolution, depth, width)을 동시에 고려하여 증가시키는 방법을 의미함
- 이 compound scaling 기법을 통해 높은 성능을 달성 할 수 있었음
- 위의 아이디어를 object detection에도 적용 가능하며, backbone, feature network, box/class prediction network 등 모든 곳에 적용함
Main Contribution
- 본 논문에서 제안하는 핵심 내용은 크게 2개
- BiFPN
- Model scaling
- 위의 두 방법을 적용시켜 MS COCO에서 가장 높은 mAP 점수를 달성하고, 기존 방법들 대비 매우 적은 연산량(FLOPS)으로 비슷한 정확도를 달성함
- Main contributions
- Weighted bidirectional feature network (BiFPN)를 제안
- Object detection에도 compound scaling을 적용하는 방법을 제안
- BiFPN과 compound scaling을 접목해 좋은 성능을 보이는 EfficientDet 구조를 제안
BiFPN
Cross-Scale Connections
- Feature Pyramid Network를 이용한 방법들을 모아둔 그림은 아래와 같음
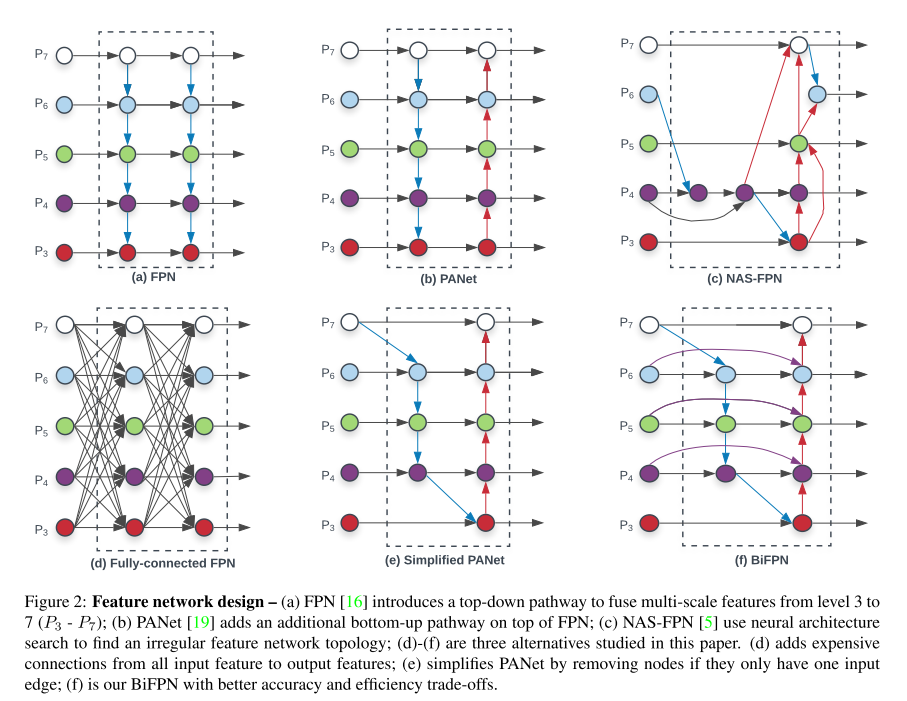
- (a): 전통적인 Feature Pyramid Network(FPN)의 구조
- (b): PANet. FPN에 추가로 bottom-up pathway를 FPN에 추가함
- (c): AutoML의 NAS를 FPN구조에 적용시킨 NAS-FPN
- 불규칙적인 FPN 구조를 보임
- (a)와 (b)의 구조는 같은 scale에서만 connection이 존재하지만, (c)부터는 scale이 다른 경우에도 connection을 형성한 Cross-Scale Connection 을 적용시킴
- (d)와 (e)는 본 논문에서 추가로 제안하고 실험한 방식
-
(f): 본 논문에서 제안하는 BiFPN 구조
- (e)의 simplified PANet 방식은 PANet에서 input edge가 1개인 node들은 기여도가 적을 것이라 판단하고 제거해 얻은 network 구조
- (f) BiFPN은 (e)에 보라색 전처럼 같은 scale에서 edge를 추가해 더 많은 feature들이 fusion되도록 구성을 한 방식
- PANet은 top-down과 bottom-up path를 하나만 사용했지만, 본 논문에서는 이러한 구조를 여러번 반복하여 사용함
- 이를 통해 더 high-level한 feature fusion이 가능하다고 주장함

- 논문에선 BiFPN의 성능 향상을 살펴보기 위해 2개의 ablation study를 수행함
- Table 3에선 같은 backbone(EfficientNet-B3)에서 FPN을 BiFPN으로 바꿨을 때의 성능을 측정함
- 이 때의 mAP는 약 4.1 증가했으며, parameter 수와 FLOPS도 적게 사용하고 있음을 보여줌
- Table 4에선 여러 Feature network 방식들에 따라 성능이 어떻게 바뀌는지를 분석한 결과
- BiFPN을 사용했을 때 성능이 가장 좋은 것을 확인 가능
Weighted Feature Fusion
- FPN에서 서로 다른 resolution의 input feature들을 합칠 때, 일반적으로는 같은 해상도가 되도록 resize 수행 후 합침
- 하지만 이러한 경우엔 모든 input feature를 동등하게 처리하게 된다는 문제점이 존재
- 본 논문에서는 위의 문제를 개선하기 위해 각 input feature에 weight를 주고, 학습을 통해 weight를 배울 수 있는 방식을 제안함
- 총 3가지 방식을 제안하고 있으며, 각 방식을 하나의 그림으로 정리하면 다음과 같음
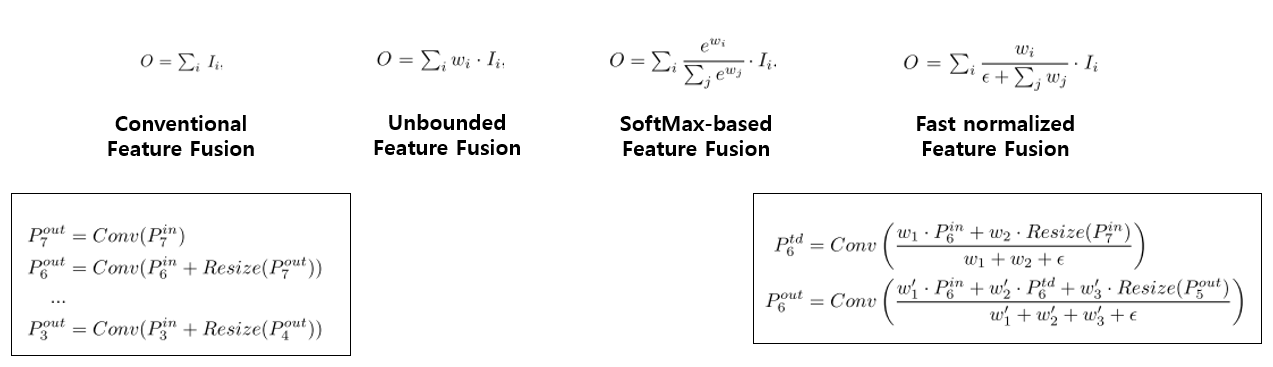
- Weight는 3가지 종류로 적용 가능함
- Scalar(per-feature)
- Vector(per-channel)
- Multi-dimensional tensor(per-pixel)
- 본 논문에선 scalar를 사용하는 것이 정확도와 연산량 측면에서 가장 효율적임을 실험을 통해 확인함
- 모든 실험에선 Scalar weight를 사용함
- Unbounded fusion은 말 그대로 unbounded이기에 학습에 불안정성을 유발 할 수 있음
- Weight normalization을 적용시켜 학습 불안정성 문제 해결
-
SoftMax-based fusion은 많이 사용하는 SoftMax를 사용한 것이지만 GPU 하드웨어에서 속도저하를 유발시킴을 실험을 통해 확인함
- 따라서 본 논문은 Fast normalized feature fusion 방법을 제안함
- 우선 weight들은 ReLU를 거치기에 non-zero임이 보장되며, 분모가 0이 되는것을 막기 위해 $\epsilon$인 0.0001 크기의 값을 넣어줌
- Weight 값이 0~1 사이로 normalize 되는 것은 SoftMax와 유사하며, ablation study를 통해 SoftMax-based fusion 방식보다 좋은 성능임을 확인시켜줌
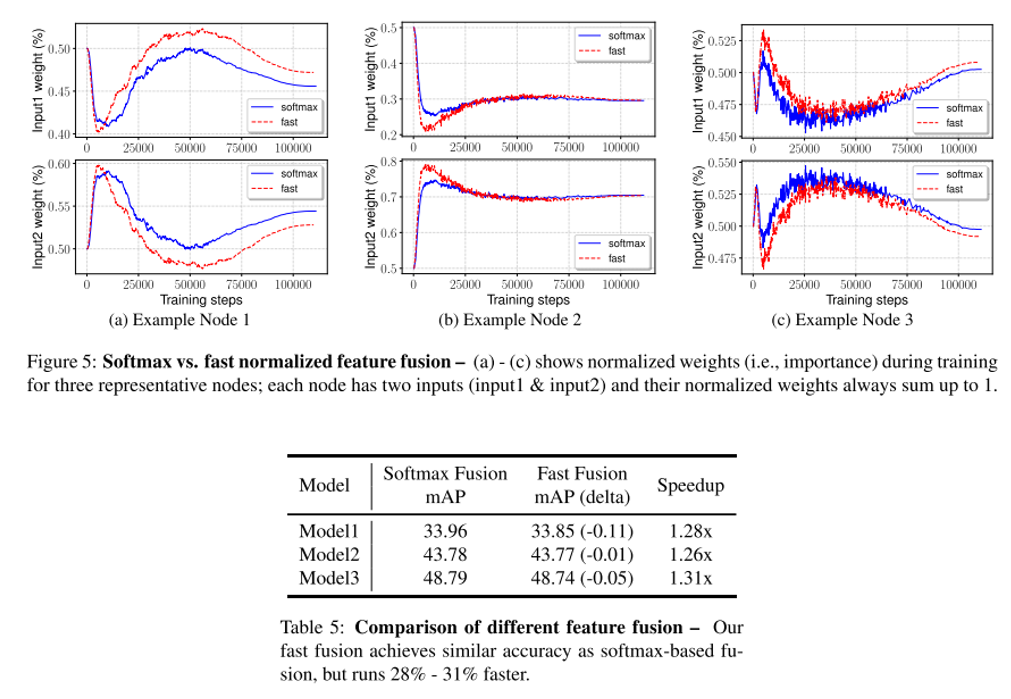
- 위의 Table 5는 SoftMax fusion과 Fast fusion을 비교한 결과
- Fast fusion을 사용하면 mAP의 하락이 약간 있지만 30%의 속도향상을 달성 할 수 있음
- 그림 5에선 input 1과 input 2의 weight를 training step에 따라 plot 한 결과를 확인 할 수 있음
- 학습이 계속될수록 weight가 빠르게 변하는 것을 확인 할 수 있음
- 이는 feture들이 동등하지 않게 output feature에 기여하고 있음을 의미함
- Fast fusion을 적용시켜도 SoftMax fusion과 양상이 비슷한것을 확인 할 수 있음
EfficientDet
- 위에서 설명한 BiFPN을 기반으로 EfficientDet이라는 1-stage detection method를 제안함
EfficientDet Architecture
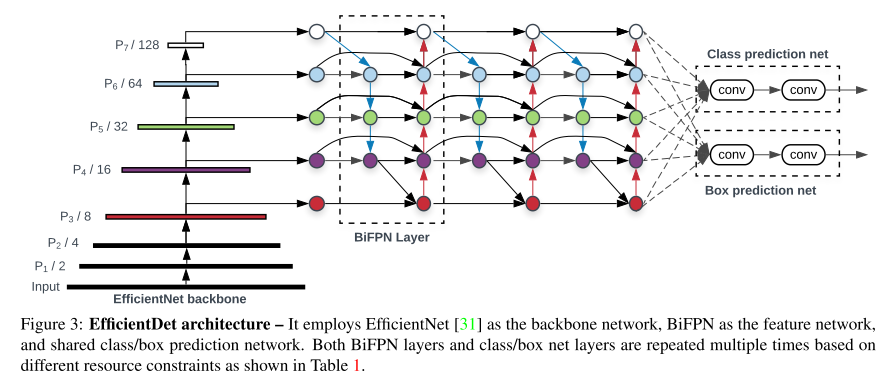
- EfficientDet의 구조는 위의 그림과 같음
- 별다른 특이점 없이 그냥 그림 그대로 deconv 된 feature를 concat/connect 하여 사용함
Compund Scaling
- Backbone network에는 EfficientNet-B0~B6를 사용했으며, ImageNet pre-trained network를 사용함
- 실험에 사용한 Compound Scaling configuration은 아래와 같음
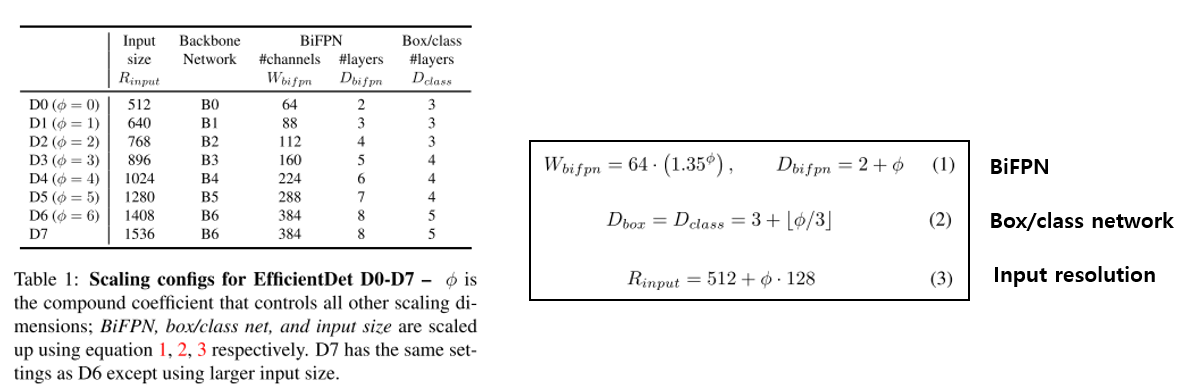
- EfficientNet의 Compound Scaling처럼 input의 resolution과 backbone network의 크기를 늘려줌
- 또한 논문에서 제안한 BiFPN과 Box/class network도 동시에 키워줌
- 각 네트워크별로 어떻게 키웠는지는 위 그림 우측의 (1), (2), (3)에서 확인 가능함
실험 결과
- 제안하는 모델은 MS COCO에서 가장 높은 mAP를 달성함
- 2019년 11월 기준 SOTA 성능을 보임
- 기존 방식들 대비 연산 효율이 압도적으로 좋음
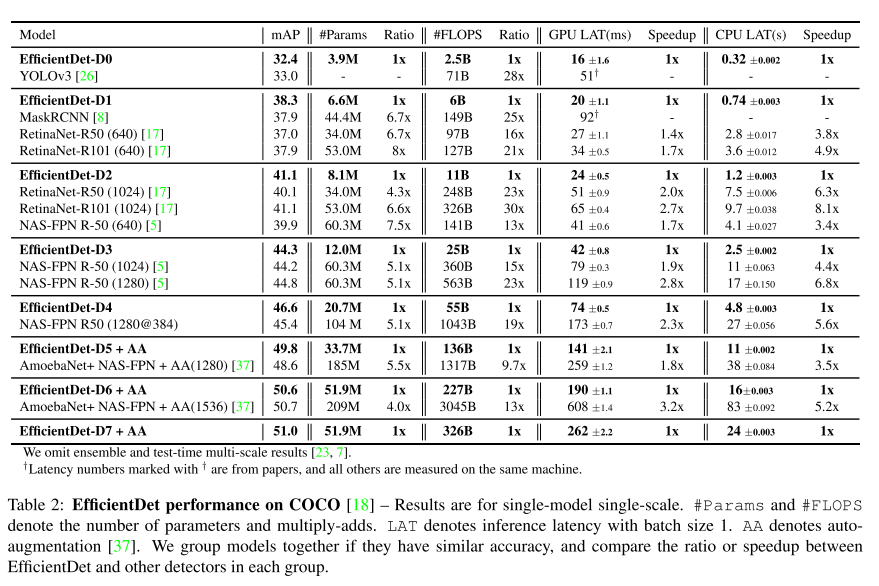
- 모델의 크기(parameter 수), inference latency를 GPU와 CPU에서 측정한 실험 결과
- 단순히 FLOPS가 적다고 해서 항상 inference latency가 적다는 보장이 없으므로 실제 inference time을 보여줌
- 정말 유용한 비교 방법인듯
- 위의 그림을 보면, 제안하는 방법이 정확도도 높고 모델 크기도 작고 inference time도 작아서 빠르게 동작하고 있음을 보여주고 있음
- 모델 학습에 관한 자세한 training strategy는 논문에서 확인 가능함
결론
- 본 논문에선 2018년을 기점으로 다양한 detection method들의 성능을 단숨에 서열정리함
- 성능보다도 inference time의 관점에서 매우 효율적
- MS COCO와 같은 연구용 데이터셋 뿐만 아니라 실제 데이터셋과 같은 실제(practical) application에서도 충분히 적용가능한 방법
- Object detection에서도 EfficientNet의 방법이 적용되었으니, 조만간 Semantic/Instance segmentation에도 적용된 논문들이 나올 수 있음