
 Seongkyun Han's blog
Seongkyun Han's blog
Feature Pyramid Networks for Object Detection
06 Dec 2019 | Deep learningFeature Pyramid Networks for Object Detection
Original paper: https://arxiv.org/abs/1612.03144
Authors: Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie (Facebook, Cornell Univ.)
- 참고 글
- https://eehoeskrap.tistory.com/300
- https://medium.com/@lsrock125/feature-pyramid-networks-for-object-detection-%EB%85%BC%EB%AC%B8%EC%9D%BD%EA%B8%B0-e4e577c4b423
- https://hwkim94.github.io/deeplearning/cnn/image-detection/fpn/paperreview/2018/10/01/FPN1.html
Introduction
- Object detection 분야에서 Scale-Invariant는 아주 중요한 문제
- Scale과 location에 상관없이 객체를 하나의 class로 탐지해야 하기 때문
- 예전에는 다양한 크기의 물체를 탐지하기 위해 이미지 자체의 크기를 resize하면서 물체를 찾았음
- Pooling이나 stride convolution으로 feature map의 size를 조절하여 detection layer로 객체를 탐지
- SSD, RFB 등의 기존의 1-stage method들
- 이러한 작업은 메모리 및 시간 측면에서 비효율적
- Pooling이나 stride convolution으로 feature map의 size를 조절하여 detection layer로 객체를 탐지
- 이를 개선하기 위해 Feature Pyramid Network(FPN) 이라는 방법이 등장
Related Work
Featurized Image Pyramid
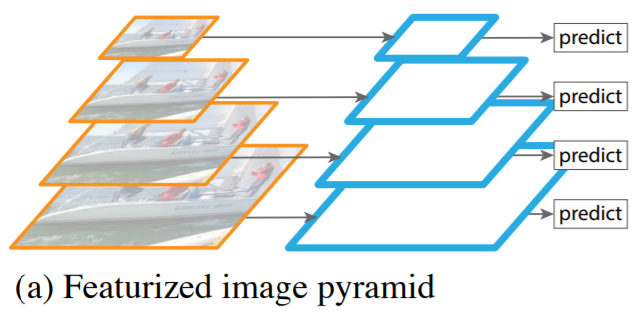
- 각 feature map level에서 독립적으로 특징을 추출해 객체를 탐지하는 방법
- 연산량과 시간 관점에서 비효율적이며 practical하게 적용하기 어려움
Single Feature Map
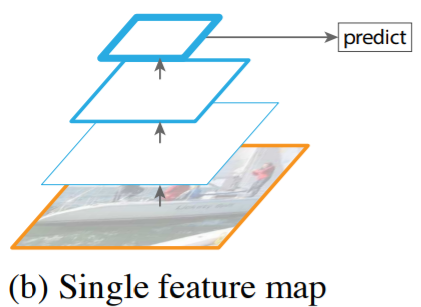
- 이 방법은 convolution layer가 scale variant에 robust한 점을 이용하는 방법
- 이로 인해 Conv layer를 통해 feature를 압축하는 방식
- 하지만 multi scale을 사용하지 않고 한 번에 feature를 압축하여 마지막에 압축된 feature만을 사용
- 성능이 떨어짐
- YOLO V1에서 사용하는 방법
Pyramidal Feature Hierarchy
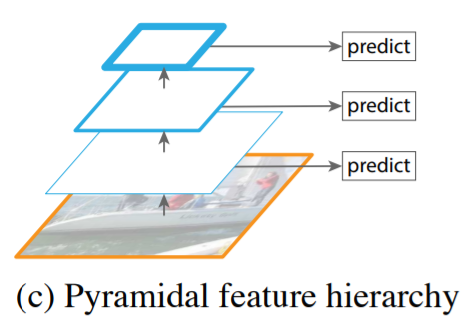
- 서로 다른 scale의 feature map을 이용해 multi scale feature를 추출하는 방식
- 각 level에서 독립적으로 feature를 추출해 객체를 탐지함
- 이 과정에서 이미 생성된 상위 level의 feature map을 재사용하지 않음
- 대표적으로 SSD에서 사용하는 방식
Feature Pyramid Network (FPN)
- Top-down 방식으로 feature를 추출함
- 각 추출된 결과물인 feature map의 low-resolution 및 high-resolution feature들을 묶는 방식
- 각 level에서 독립적으로 feature를 추출해 객체를 탐지함
- 이 과정에서 상위 level에서 이미 생성된 feautre map을 재사용하므로 multi-scale feature들을 효율적으로 재사용 가능함
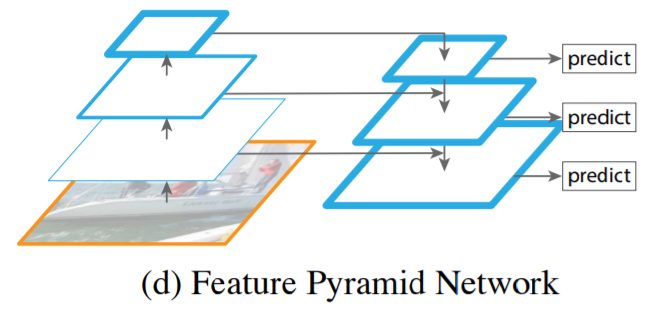
- CNN 자체가 layer를 거치면서 pyramid 구조를 만들고, forward pass를 거치면서 feature map은 더 많은 semantic 정보를 갖는 feature를 얻게 됨
- 각 level마다 prediction 과정을 넣어서 scale 변화에 더 강인한 모델이 됨
- FPN은 skip connection, top-down, CNN forward pass 과정에서 생성되는 pyramid의 구조를가짐
- Forward pass에서 생성된 feature map들을 top-down 과정에서 upsampling하여 spatial resolution을 올리고
- Forward pass에서 손실된 localization feature들을 skip-connection을 이용해 보충
- 위의 과정을 통해 scale variant에 강인한 feature map을 생성 할 수 있게 됨
- FPN은 ConvNet의 피라미드 계층 구조를 활용함
- 피라미드 특징 계층 구조는 낮은 수준에서 높은 수준까지의 semantic feature들을 모두 갖고 있음
- 이로 인해 전반적으로 높은 수준의 semantic information을 포함하는 feature pyramid를 생성하게 됨
-
이 FPN은 Fast R-CNN과 Faster R-CNN의 Region Proposal Network (RPN)을 기반으로 함
- FPN은 입력으로 임의 크기의 단일 scale 영상을 입력받음
- 전체적으로는 conv layer를 통해 비례된 크기의 feature map을 multi-level로 출력하게 됨
- 이러한 feature concat process는 backbone network와 독립적으로 진행됨
- 논문에선 ResNet을 backbone으로 사용함
- 위의 과정을 크게 Bottom-up과 Top-down 프로세스로 설명
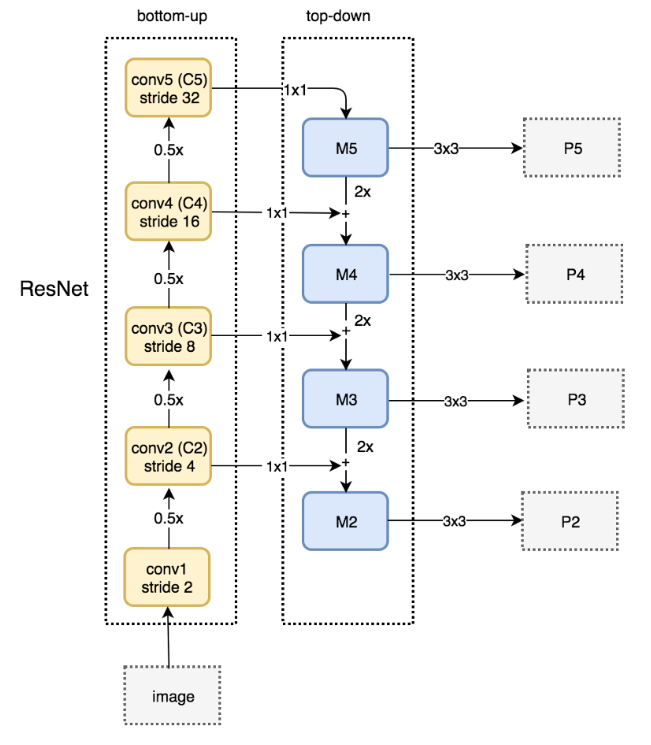
Bottom-up pathway
- 위로 올라가는 bottom-up pathway의 forward 단계에서는 매 레이어마다 semantic을 응축하는 역할을 함
- Backbone의 feed forward 계산과정
- 각 level은 convolution block 혹은 residual block으로 이루어짐
- 각 level의 마지막 layer를 각각 C2, C3, C4, C5로 정의
- 깊은 모델의 경우 가로, 세로 크기가 같은 레이어들이 여러 개 있을 수 있음
- 여기서 같은 크기를 갖는 레이어들을 하나의 단계로 취급해서 각 단계의 맨 마지막 레이어를 skip-connection으로 연결
- 각 단계 마지막 레이어의 출력을 feature map의 reference set으로 선택함
- 피라미드의 feature가 풍부하기 위해서는 각 단계의 가장 깊은 레이어에는 가장 의미 있는 feature가 있어야 함
- 따라서 feature가 풍부한 각 단계의 마지막 feature map을 이용해 skip-connection 형성
Top-down pathway and lateral connections(skip-connection)
- 하향식 과정에선 많은 semantic 정보들을 갖고 있는 feature map을 2배로 upsampling해 더 높은 해상도의 이미지를 만듦
-
여기서 skip-connection을 통해 같은 사이즈의 bottom-up layer와 합쳐서 손실된 local한 정보를 보충해줌
- Top-down 과정에서 매 레이어마다 classifier와 regressor가 적용됨
- 같은 하나의 classifier와 regressor를 사용하기에 모두 같은 256 채널의 feature map을 입력받아야 함
- 따라서 skip-connection을 할 때 1x1 conv로 채널을 맞춰주게 됨
- 즉, upsampled feature map은 element-wise addition에 의해 bottom-up에서 생성된 feature map과 병합되는 과정을 거침
- 이 과정에서 채널 수를 맞추기 위한 pointwise conv 수행
- 이 프로세스는 마지막 resolution의 feature map이 생성될까지 동일하게 수행됨
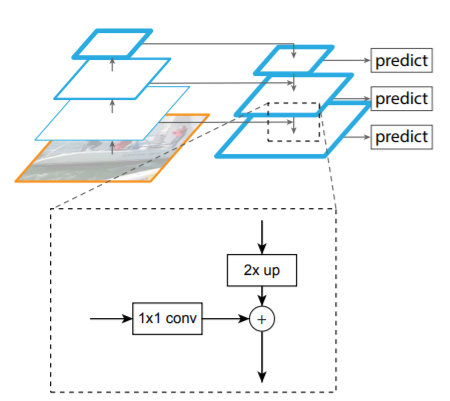
- 마지막으로, 합겨친 각 feature map에 3x3 conv를 수행해 upsampling의 aliasing 효과를 줄인 후 최종 feature map을 생성함
- 이렇게 생성된 feature map은 각각 P2, P3, P4, P5이며, 동일한 spatial size인 C2, C3, C4, C5에 대응되어 lateral connection을 형성
Lateral connection이 없다면?
- Top-down layer도 높은 semantic을 갖고 있지만, 지역적인 정보가 부족하게 되어 정확도가 떨어지게되는 단점이 생김
Pyramid 구조가 아니라면?
- 크기가 다른 각 layer에서 예측하는 것이 아니라 top-down의 맨 마지막 레이어에서만 prediction 하면 baseline보다는 높지만 원 구조보다는 성능이 떨어짐
- Scale variant에 덜 robust해지기 때문
- 피라미드 구조의 맨 마지막의 해상도가 높기 때문에 많은 anchor들이 적용되었는데도 그다지 성능이 좋지 않음
- 이는 anchor가 많은것이 성능을 높히기 충분하지 않다는 것을 반증함
Application
FPN for RPN
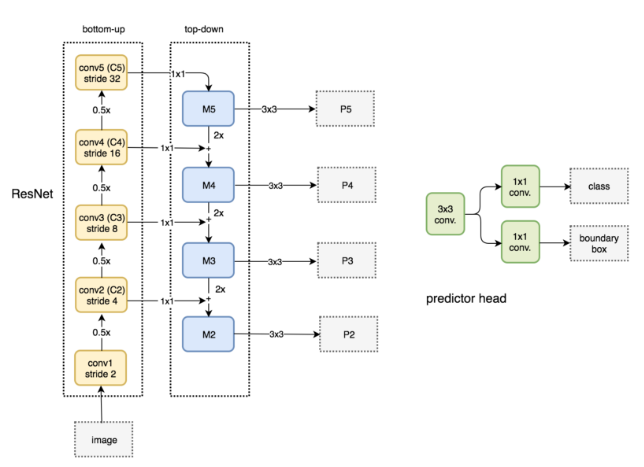
- RPN을 위해 3x3 conv와 sibling 1x1 conv을 각 level에 추가 구성
- 즉, 각 level의 feature마다 bounding box regression과 label classification 수행
- 각각의 Pk에 single scale anchor box를 사용
- 작은 feature map에는 작은 anchor box, 큰 feature map에는 큰 anchor box를 적용
- Multi-scale detection을 위함
- 작은 feature map에는 작은 anchor box, 큰 feature map에는 큰 anchor box를 적용
- IoU threshold
- 0.7 이상은 positive, 0.3 이하는 negative
- Sharing parameter
- Sibling 1x1 conv의 parameter를 모든 FPN이 공유
FPN for Fast R-CNN
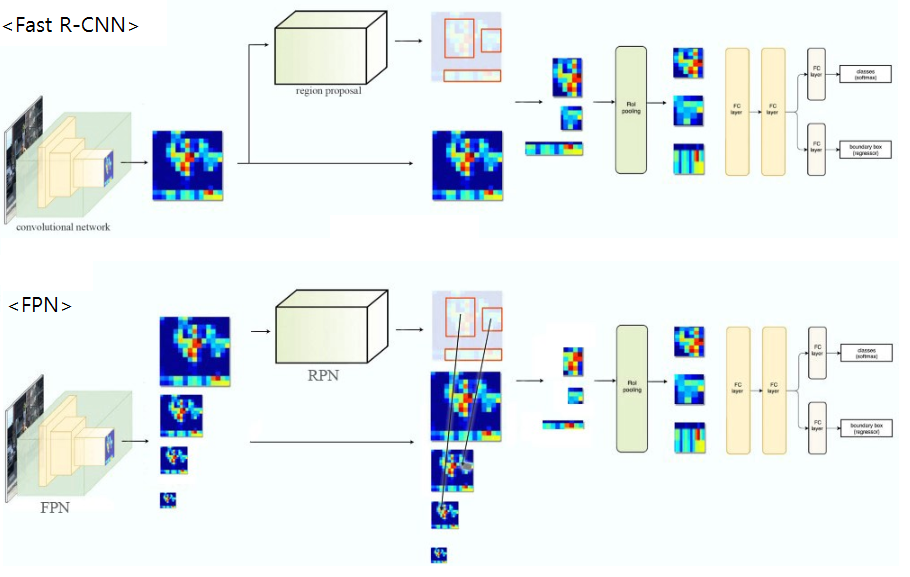
- FPN을 통해 다양한 scale의 feature map을 생성
- 가장 해상도가 높은 feature map을 RPN에 적용
- 각 region proposal을 적당한 크기의 feature map Pk에 적용
- $k=\left \lfloor k_0 + log_2 (\sqrt{wh}/224) \right \rfloor$
- $(w, h)$: Width and height of RoI
- 224: Size of input image
- RoI pooling
- bounding box regression and label classification
Experiments on Object Detection
- MS COCO
- Backbone: Pretrained ResNet
Region Proposal with RPN
- Synchronized SGD
- Mini-batch = 2
Ablation Experiments
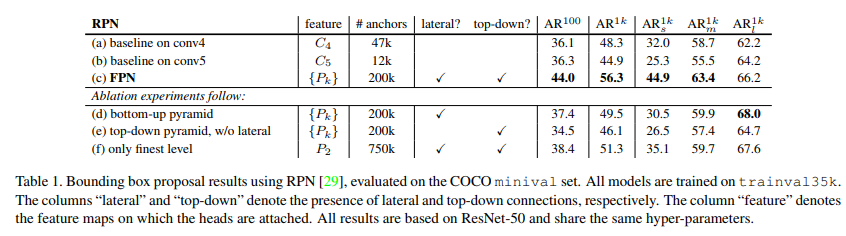
- Comparisons with baselines
- RPN에 single layer를 하나 더 사용하는것은 큰 효과 없음
- Coarser resolutions과 stronger semantics의 trade-off 때문
- 다양한 scale의 feature map을 만드는 FPN이 더 효율적
- RPN에 single layer를 하나 더 사용하는것은 큰 효과 없음
- How important is top-down enrichment?
- Top-down pathway 제거 후 bottom-up pathway에서 낮은 level의 feature map을 재사용
- Level마다 semantic gap이 존재하기에 큰 영향을 미치지 못함
- Top-down pathway 제거 후 bottom-up pathway에서 낮은 level의 feature map을 재사용
- How important are lateral connections?
- Skip-connection(lateral connection) 삭제
- Down sampling과 up sampling을 여러번 했기에 location 정보가 부정확
- Lateral connection이 있어야 bottom-up pathway의 location 정보가 잘 전달됨
- Skip-connection(lateral connection) 삭제
- How important are pyramid representations?
- Top-down pathway의 마지막 feature map으로만 최종 결과 예측
- Baseline보다는 좋은 성능을 보여주지만, FPN보다는 안좋은 성능
- 이는 scale 변화에 덜 robust하기 때문
- Anchor box의 개수를 늘림
- Anchor box의 종류와 크기를 다양하게 사용해도 성능의 큰 향상은 없음
- 즉, 단순히 anchor box 갯수를 늘리는 것으로는 성능을 끌어올리는 것은 힘듦
- Top-down pathway의 마지막 feature map으로만 최종 결과 예측
Object Detection with Fast/Faster R-CNN
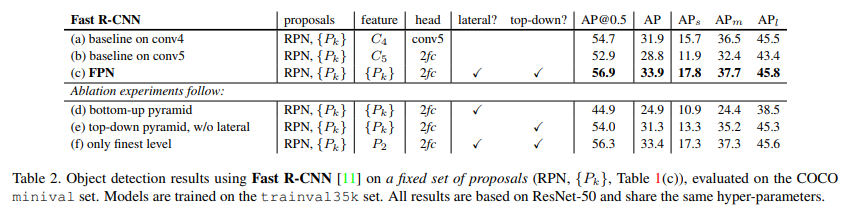
Fast R-CNN (on fixed proposals)
Faster R-CNN (on consistent proposals)

- Sharing features
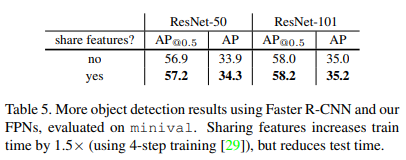
- Running time
- 기존의 모델보다 느리지만 큰 차이는 없음
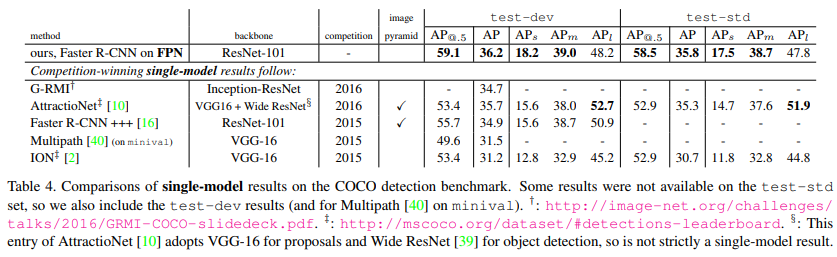
Comparing with COCO competition Winners
Extensions: Segmentation Proposals
- Segmentation prosal을 만들기 위해 FPN을 사용
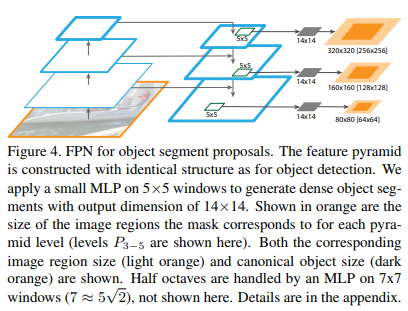
Segmentation Proposal Results
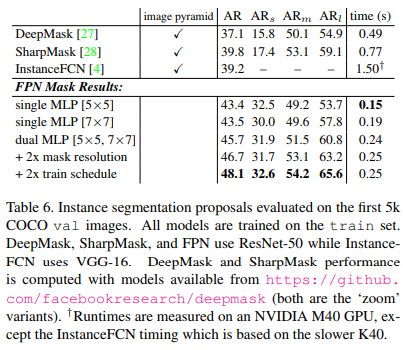
Conclusion
- Multi-scale representation을 사용하는 것이 성능향상에 도움이 됨