
 Seongkyun Han's blog
Seongkyun Han's blog
Dilated Convolution과 Deformable Convolution
02 Jan 2019 | dilated deformable convolution deep learningDilated Convolution과 Deformable Convolution
Object detection에 관련된 딥러닝 논문을 읽다 보면 Feature extractor에서 사용되는 다양한 종류의 컨벌루션이 논해진다. 그 중 RFBNet 논문을 읽으며 알게 된 Dilated Convolution과 Deformable Convolution에 대해 간단하게 공부해봤다.
Dilated Convolution
- FCN 개발자들은 dilated convolution 대신 skip layer/upsampling을 사용
- 기본적인 convolution과 유사
- 아래의 그림에서 빨간 점만을 이용해 convolution을 수행.
- 이유? 해상도 손실 없이 receptive field 크기 확장 가능
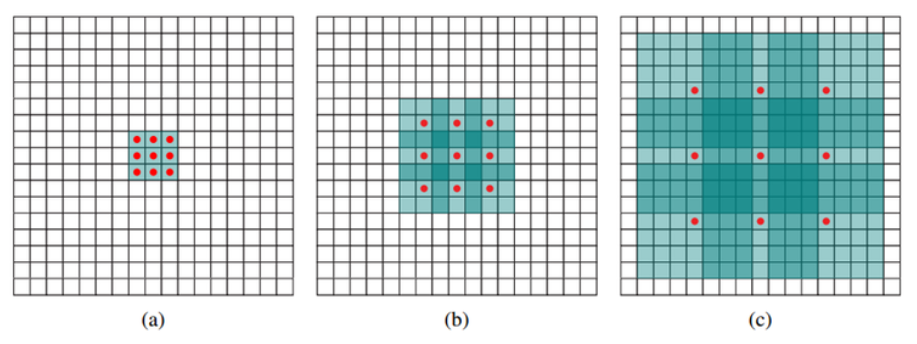
- (a): 1-dilated convolution으로 기존의 일반적인 convolution 연산과 동일
- (b): 2-dilated convolution. 각 빨간점만 convolution 연산에 사용.(나머지는 0으로 채워짐)
- Receptive field 크기가 7x7 영역으로 커지는 꼴
-
(c): 4-dilated convolution. Receptive field 크기가 15x15로 커지는 꼴
- Dilated convolution 사용 시 receptive field가 커지는 효과를 얻을 수 있음.
- 파라미터 개수(연산량)가 늘어나지 않으며 큰 receptive field를 취할 수 있는 장점이 존재(conv 표현력 대비 연산량 감소)
- ex. 7x7크기의 receptive field에 대해
- Normal: 49개의 parameters(7*7)
- Dilated: 9개의 parameters(3*3) -> 나머지는 모두 0으로 채워짐
- Dilated convolution의 이점?
- Receptive field의 크기가 커짐.
- Dilation 계수 조정 시 다양한 scale에 대한 대응이 가능 (다양한 scale에서의 정보를 끄집어내려면 넓은 receptive field가 필요하나, dilated conv가 그 문제를 해결)
- Pooling을 이용한 receptive field의 확장효과를 얻는 CNN보다 양질의 feature map을 얻을 수 있음(표현력이 더 좋음)
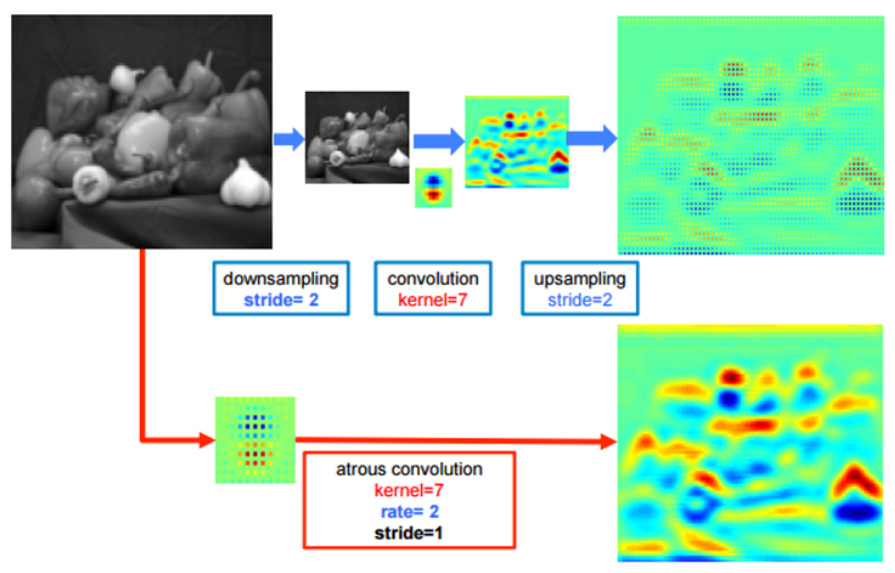
- DeepLab 논문의 그림을 참조하여 위쪽이 pooling과 normal convolution을 이용한 결과, 아래가 Dilated convolution을 이용한 결과
Deformalbe Convolution
- 기존의 CNN방식은 기하학적으로 제한적이고 일정한 패턴을 가정한 convolution을 사용하여 복잡한 transformation에서 유연한 대처가 어렵고, 이로 인하여 명확한 한계가 존재
- CNN Layer에서 사용하는 convolution은 receptive field 크기가 항상 같음
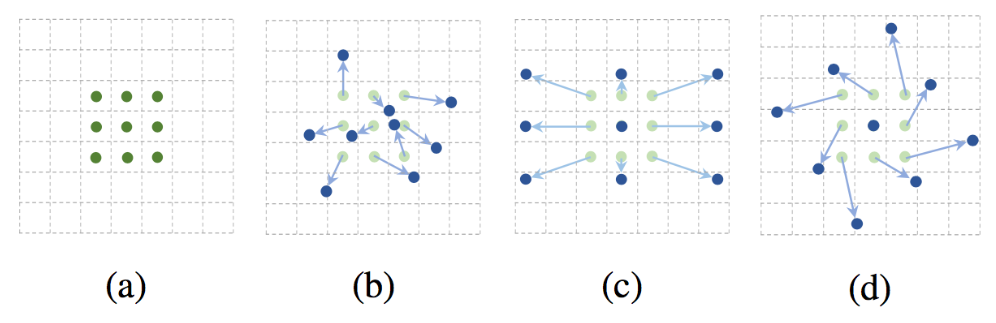
- Convolution에서 사용하는 sampling grid에 2D offset을 더한다는 idea에서 출발
- (a)에 offset을 더해(초록 화살표) (b), (c), (d)의 파란 점들처럼 다양한 패턴으로 convolution을 변형시켜 사용 가능=
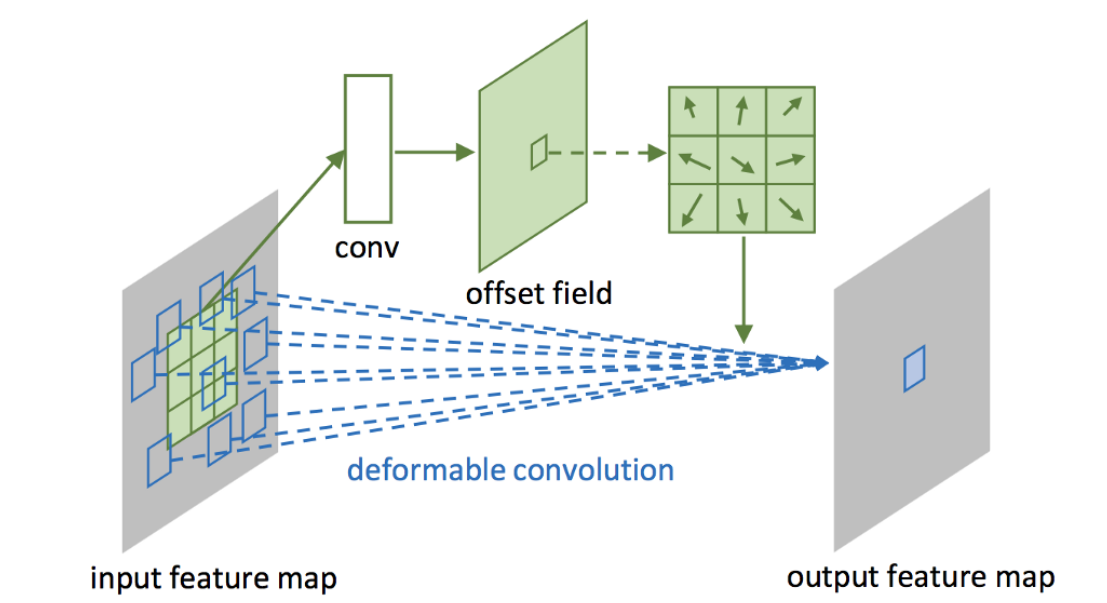
- Deformable conv에는 일반적인 conv layer말고 다른 conv layer가 존재
- 위의 그림에서 초록 선의 흰색
convlayer가 각 입력의 2D offset을 학습하기 위한 layer - 여기서 offset은 integer값이 아닌 fractional number이므로 0.5같은 소수 값이 가능
- 실제 계산은 linear interpolation(2D 이므로 bilinear)으로 이루어짐
- Training 과정에서, output feature를 만드는 convolution kernel과 offset을 정하는 convolution kernel을 동시에 학습 할 수 있음
- 여기서 ‘offset을 정하는 convolution kernel’은 얼마나 어떻게 멀어질지 정하는 convolutiond

- 붉은 점은 deformable convolution filter에서 학습한 offset을 반영한 sampling location
- 초록색은 filter의 output 위치
- 결과적으로, 일정하지 않은 sampling 패턴에 의해 큰 object에 대해서는 receptive field가 더 커진것을 확인 할 수 있음
Deformable ROI Pooling
- ROI Pooling: 크기가 변하는 사각형 입력 region을 고정된 크기의 feature로 변환하는 과정
- Deformable ROI pooling으로 일반적인 ROI Pooling layer와 offset을 학습하기 위한 layer로 구성
- Deformable conv와 다른점은 offset 학습에 convolution이 아니라 fc layer를 사용(이유는 논문에도 안나와있음…)
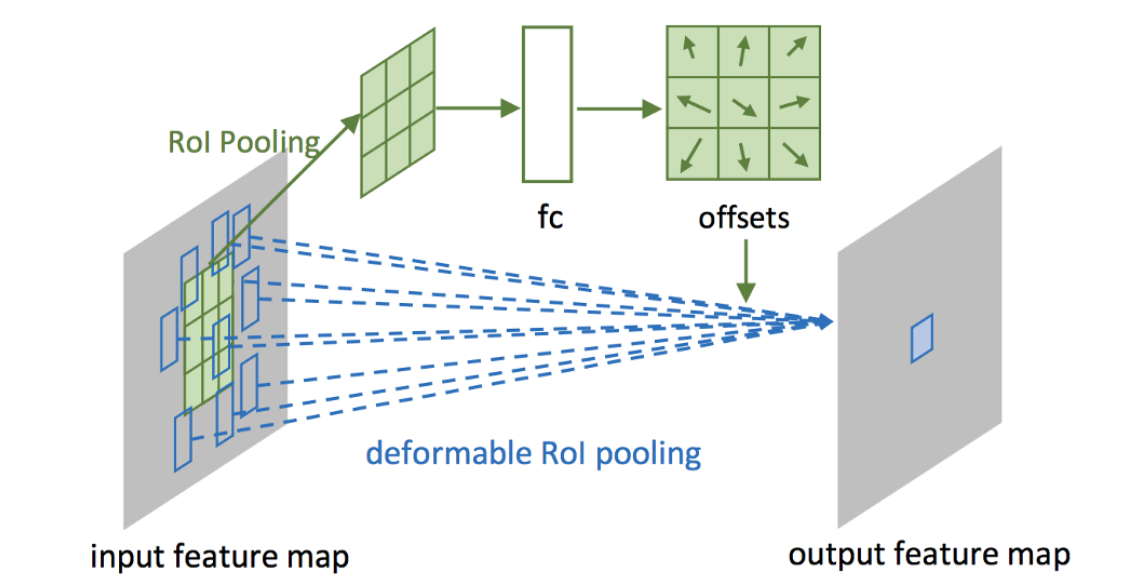
- Training 과정에서 offset을 결정하는 fc later도 back-propagation을 통해 학습됨(parameter update)

- 입력 ROI(노란색)에 대해 deformable ROI Pooling(붉은색)의 결과.
-
ROI에 해당하는 붉은 사각형의 모양이 object의 형대에 따라 다양한 형태로 변형됨
- 지금까지 deep learning 분야의 많은 연구들은 predictor의 weight 값(parameter, w)을 구하는데 초점을 맞춤
-
위 논문들은 어떤 데이터 x를 뽑을 것인가에 대해 초점을 맞춤
- [참고 글]
https://blog.naver.com/PostView.nhn?blogId=laonple&logNo=220991967450&proxyReferer=https%3A%2F%2Fwww.google.com%2F
https://jamiekang.github.io/2017/04/16/deformable-convolutional-networks/