
 Seongkyun Han's blog
Seongkyun Han's blog
Cross entropy loss in machine learning
20 Jan 2019 | cross entropy loss deep learning machine learningCross entropy loss in machine learning
맨날 그냥 사용하기만 하는 cross entropy loss에 대해 공부해보려 한다.
- 손실함수는 신경망 학습의 목적
- Cross-entropy는 squared loss와 더불어 양대 손실함수
- Cross-entropy는 신경망 출력을 확률로 간주할 수 있는 경우에 사용되는 매우 중요한 손실함수
Cost/Loss function
Squared loss
Mean squared loss
Information
- 어떤 사건을 수치로 나타낸 것
- 확률을 이용한다
- $x$: 동전의 앞면이 나올 때(event)
- $X$: 확률변수, random process
- (모두 같은 표현)
사건을 수치화 하기
- 사건이 드물게 발생할수록 정보가 커야 함.
- 의 확률을 수치화 해 보면?
- log는 곱셈을 덧셈 연산으로 바꿔줌
- $\frac{1}{p(x)}\times \frac{1}{p(y)}$의 양 변에 log를 취한게 최종 정보량으로 정의 됨
Entropy
- 정보량의 기댓값
- 확률변수 $X$의 기댓값에 대한 공식
- $E[X]=\sum_{x}xp(x)\quad$
- $p(x)$: 확률변수 $X$의 분포함수(확률질량함수, 확률밀도함수)
- $E[aX+b]=\sum_{x}(ax+b)p(x)$ 이므로
- 가 성립함
- 따라서, $-log(p(x))$에 대해서 다음이 성립
Cross entropy
- 다른 사건의 확률을 곱해서 entropy를 계산한 것
- 예를 들어 0 또는 1만 가지는 확률변수 $X$가 있을 때(Bernoulli),
신경망의 손실함수로 활용
- $E(w)\equiv \frac{1}{2}\frac{1}{\left\vert D \right\vert}\sum_{d\in D}(y_{d}-\hat{y}_d)^{2}$ 일 때,
-
- 우 항 sum 안쪽의 식은 베르누이 확률변수를 n회 시행해서 얻은 샘플로부터 베르누이 확률변수의 평균과 분산을 추정하는 어떤 방법으로부터 유도 가능
- Maximum likelihood estimation
Cross-entropy 그래프
- 아래로 볼록 모양으로 최소값을 구할 수 있음
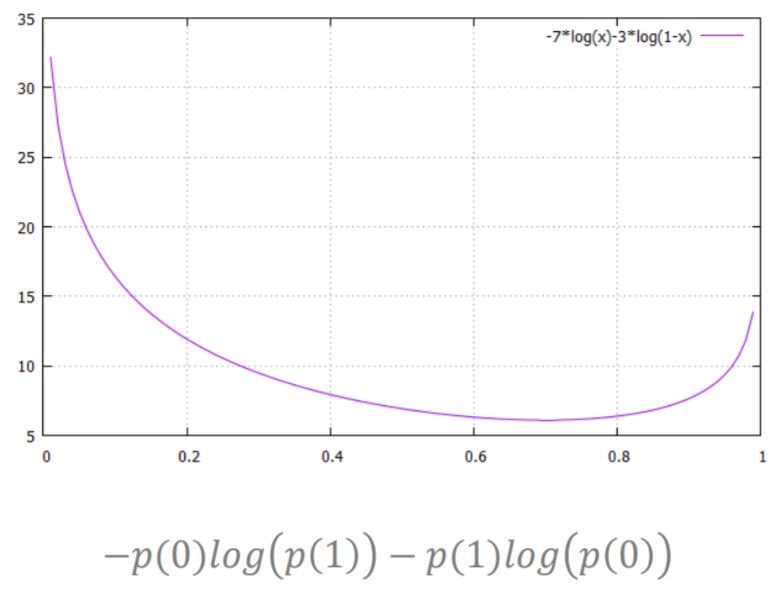
- 부호를 바꾸면 최댓값을 구할 수 있음.
- $+ylog(\hat{y})+(1-y)log(1-\hat{y})$
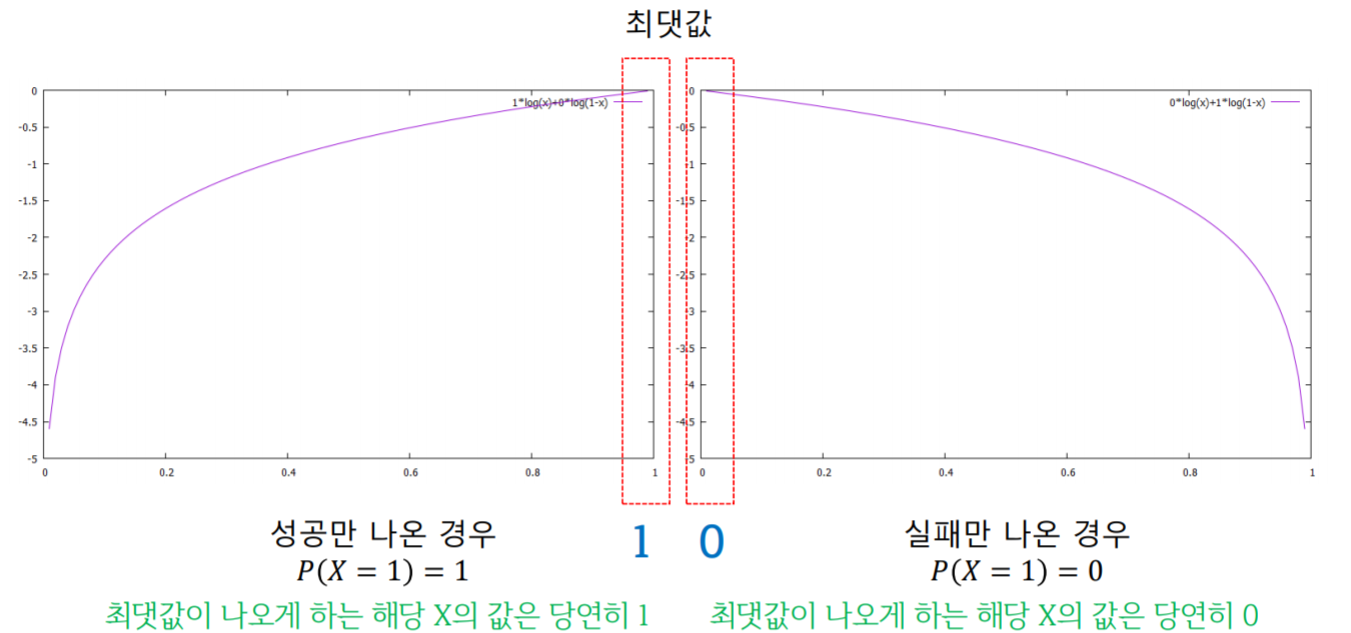
- 성공(1) 또는 실패(0)만 나오는 경우, 이렇게 나오게 되는 확률이 가장 크게 되는 x의 값을 얼마로 추정?
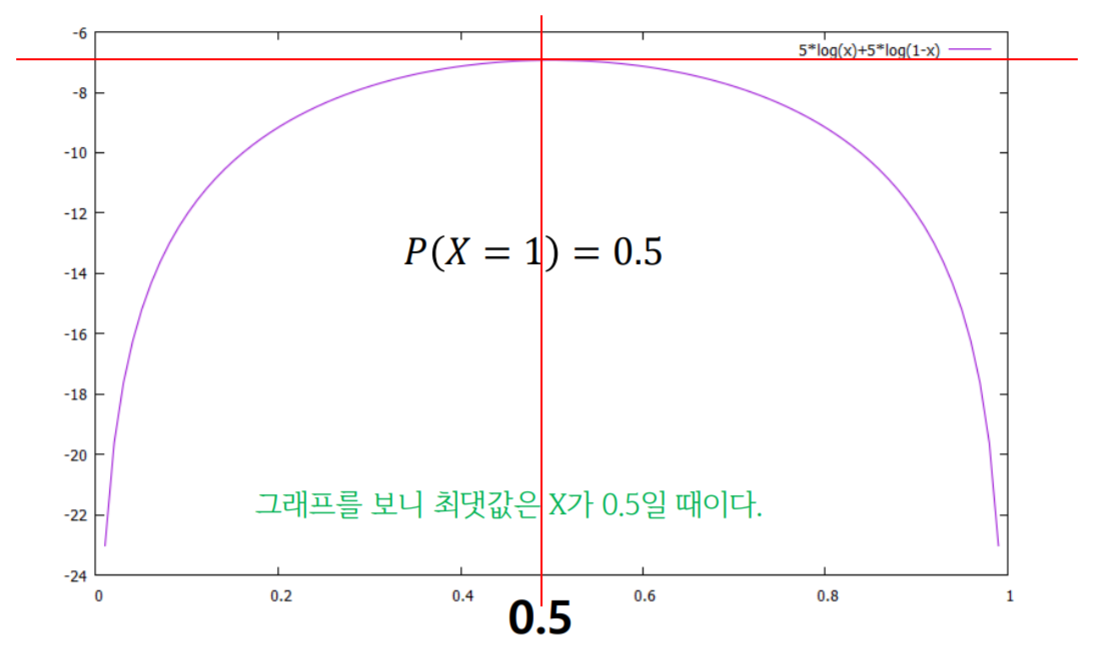
- 성공과 실패가 반반 나온 경우
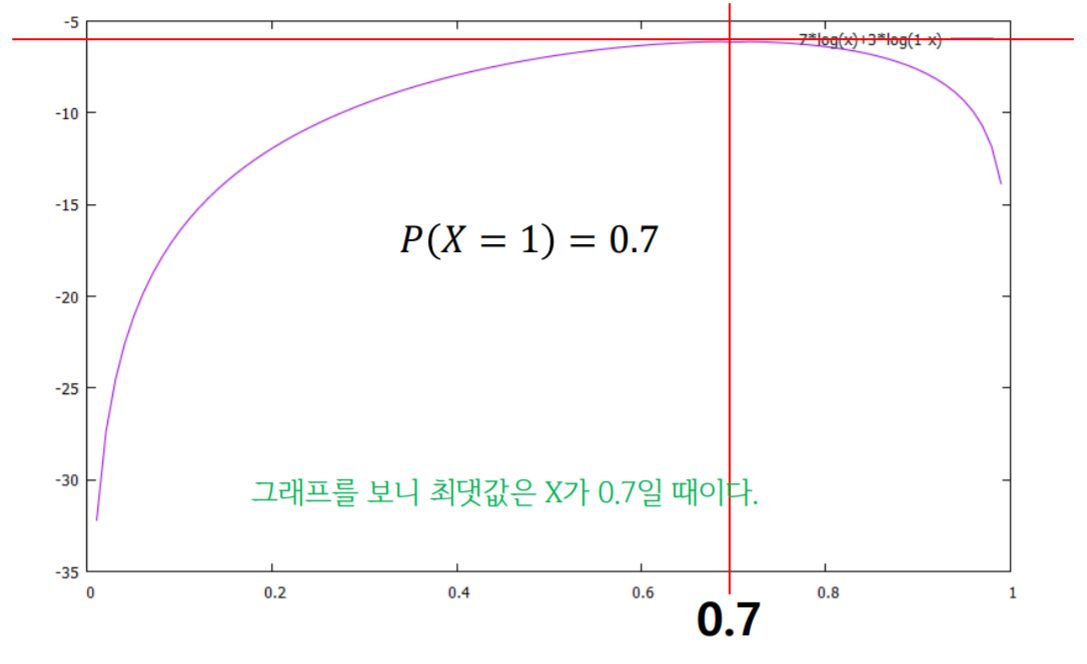
- 성공 70%과 실패 30% 나온 경우
결론
- 신경망 출력이 0~1 사이의 확률로 나오는 경우 loss 함수로 사용 할 수 있음
- [참고글]
https://www.slideshare.net/jaepilko10/ss-91071277