
 Seongkyun Han's blog
Seongkyun Han's blog
Pruning deep neural networks to make them fast and small
13 Apr 2019 | PruningPruning deep neural networks to make them fast and small
-
참고글: https://jacobgil.github.io/deeplearning/pruning-deep-learning
- Pytorch implementation code: https://github.com/jacobgil/pytorch-pruning
- paper: https://arxiv.org/pdf/1611.06440.pdf
Network pruning
- Neural network의 pruning은 1990년대에 제안된 아이디어다. 기본 아이디어는 네트워크의 많은 파라미터중 어떤것들은 중요도나 필요성이 떨어지는(redundant) 것들이 있으며, 따라서 output의 출력에 큰 영향력을 끼치지 못하는 파라미터들이 존재한다는 것이다.
- 만약 네트워크의 뉴런들을 어떤 뉴런이 더 중요한지에 따라 순서를 매겨서 나열 할 수 있다면, 낮은 순위에 존재하는 뉴런들은 상대적으로 output의 출력에 대한 기여도가 떨어지기 때문에 네트워크에서 그 뉴런들을 제거 할 수 있게 되며, 이로 인해 네트워크가 더 빠르게 동작 할 수 있게 된다.
- 이러한 빠르고 작은 네트워크는 mobile device에서 빠른 동작을 위한 필수요소다.
- 중요도를 정하는것(ranking)은 뉴런 weight의 L1/L2 평균, mean activations, 뉴런의 출력이 어떠한 validation set의 입력이 들어왔을 때 0이 아닌 횟수 등 몇몇의 다양한 방법들에 의해 정렬 될 수 있다. 이러한 pruning 다음엔 정확도가 떨어지게 되지만(하지만 ranking이 제대로 되었다면 조금밖에 떨어지지 않음) 보통은 네트워크를 더 학습시켜 이를 복구시킬 수 있게된다. 만약 한번에 너무 많이 pruning이 될 경우엔 네트워크가 손상되어 정확도의 복구가 불가능하게 된다. 따라서 실제로는 pruning이 interactive process가 되어야 한다.
- 이를 “Interactive Pruning” 이라 하며, Prune-Train-Repeat으로 수행된다.
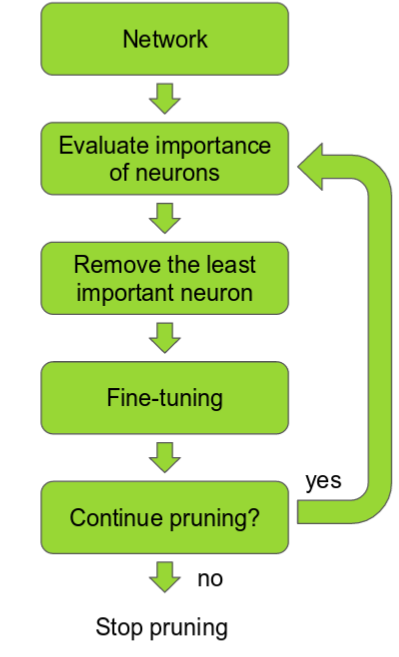
Pruning이 popular하지 않은 이유는?
- 실제로 pruning에 대한 수많은 논문들이 존재하지만 real life상에서 접할 수 있는 딥러닝 프로젝트에 적용된경우는 드물다. 그 이유는 다음과같이 추측이 가능하다.
- Ranking하는 방법이 아직까진 그렇게 좋지 못하므로 정확도의 향상이 크다.
- 실제 적용에 매우 힘들다.
- Pruning을 실제 사용한 경우라도 official하게 내놓지 않는다(secret sauce advantage).
- 이러한 이유들로 인해 implementation을 한다음 그 결과를 확인해본다.
- 본 글에선 몇몇의 pruning 방법들에대해 살펴보고 최근논문에서 제안하는 방법을 implementation한다.
- Kaggle Dogs vs Cats dataset에서 개와 고양이 분류를 위한 VGG network를 fine-tuning한다.(tranfer learning)
- 네트워크 pruning 뒤엔 속도가 3배, 크기가 4배가량 감소되었다.
Pruning for speed vs Pruning for a small model
- VGG16 weight의 90%가량은 fully connected(fc) layer이지만 전체 floating point operation의 1%만을 차지한다.
- 몇몇 연구들은 fc layer 수를 줄이는데 중점을 두었으며, fc layer들을 pruning하여 모델 사이즈를 크게 줄일 수 있었다.
- 하지만 본 글에선 convolutional layer에서 전체 filter를 pruning하는데 중점을 둔다.
- 또한 pruning을 통해 네트워크 사이즈를 줄임으로써 사용될 메모리가줄어들게 된다. [1611.06440 Pruning Convolutional Neural Networks for Resource Efficient Inference] 논문에서 레이어가 깊어질수록 pruning에 의한 이점은 더 커지게 된다.
- 이는 마지막 convolutional layer가 많이 pruning 될수록 그 뒤에 연결되어있는 fc layer도 같이 정리가 되게 되므로 많은 메모리 절약의 효과를 가져오게 되기 때문이다.
- Convolutional filter를 pruning할 때의 다른 option으로 각 필터의 weight를 줄이거나 단일 kernel에서의 특정한 dimension을 제거하는 방법이 있다. 하지만 몇몇의 filter에 대해서만 듬성듬성하게 pruning을 적용하여 계산 속도를 높히는것은 불가능하므로 최근의 연구들은 전체 filter들이 pruning하는 대신에 “Structured sparsity”를 선호한다.
- 이러한 논문들에서 다뤄지는 것들중 제일 중요한 것으로 큰 네트워크를 학습시킨 다음에 pruning함에 있어서, 특히 transfer learning의 경우, 작은 네트워크를 처음부터 학습시키는것보다 훨씬 더 나은 결과를 얻을 수 있다는 점이다.
- 아래에서 몇 가지 방법들에 대해 다뤄본다.
Pruning filters for efficient convnets
-
paper: https://arxiv.org/pdf/1608.08710.pdf
-
이 논문에선 전체 convolutional filter들에 대해서 pruning을 했다. 만약 Index가 k 인 filter를 pruning하게 될 경우 해당 필터가 존재하는 레이어와 다음 레이어에까지 영향을 주게 된다. 따라서 다음 레이어에서 Index k모든input channel들이 필요가 없어지므로 동시에 제거된다.
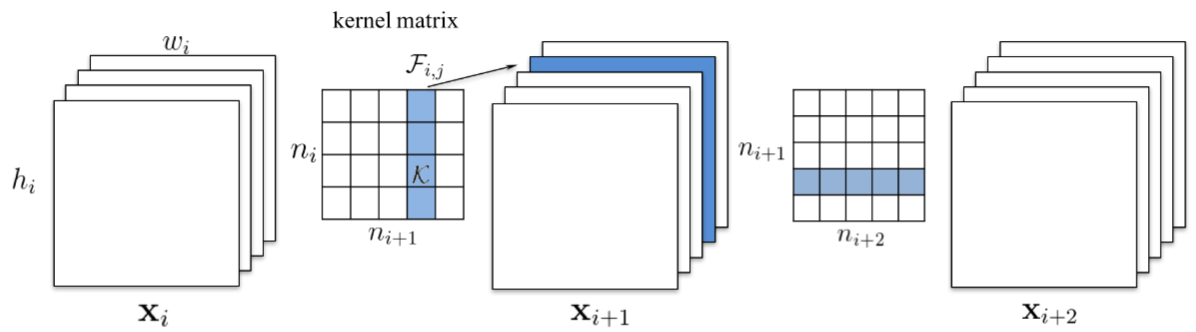
- 다음 레이어가 fc layer이고 해당 채널의 feature map의 크기가 MxN 일 경우, MxN개의 뉴런들이 fc layer에서 제거된다.
- 이 pruning 방법에서 ranking은 매우 간단하다. Ranking의 기준은 각 필터 weight의 L1 norm이다.
- 각 pruning iteration에서 모든 filter에 대해 순위를 매기고, m 개의 가장 낮은 rank 필터를 모든 layer에 대해 globally하게 pruning 한 다음 retrain하고 이를 다시 반복한다.
Structured Pruning of Deep Convolutional Neural Networks
-
paper: https://arxiv.org/ftp/arxiv/papers/1512/1512.08571.pdf
- 이 논문의 방법은 앞의 방법과 매우 비슷하지만 ranking의 방법은 훨씬 더 복잡하다. N particle filter는 유지하도록 설정하는데, 이는 N convolutional filter가 pruning 될 것임을 뜻한다.
- Particle에 의해 filter가 mask out 되지 않는 경우 각 particle은 validation set으로 측정되는 네트워크의 정확도를 기반으로 점수가 할당되어진다. 그런 다음 새로운 점수에 기반해서 새로운 pruning mask가 sampled된다.
- 이러한 연산과정은 heavy하므로 particle score의 측정에 작은 validation set을 사용했다.
Pruning Convolutional Neural Networks for Resource Efficient Inference
-
paper: https://arxiv.org/pdf/1611.06440.pdf
- Nvidia에서 쓴 coool한 논문.
- 먼저 pruning problem을 combinatorial optimization problem으로 명시하고, weight B의 일부를 선택하여 pruning하면 네트워크 cost의 변경이 최소화 될 것이다.
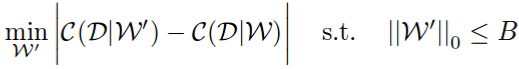
- 논문에서 어떻게 그냥 difference가 아니라 absolute difference를 썻는지 살펴볼 필요가 있다. Absolute difference를 사용하여 pruned network의 성능이 너무 많이 떨어지지 않게 하면서도 증가하지 않도록 할 수 있게 된다. 논문에선 이를 통해 더 안정적인 이유로 인해 더 나은 결과를 보였다고 한다.
- 이제 모든 ranking 방법들은 아래의 cost function으로 결정된다.
Oracle pruning
- VGG16에는 4224개의 conv filter들이 존재한다. 이상적인 ranking 방법은 각 필터를 random하게 처리한다음에 training set에서 cost function이 어떻게 변하는가를 관찰하면 된다. Nvidia 논문은 GPU resource가 충분해서 그렇게 했다. 이를 oracle ranking이라 하며, 이는 네트워크 cost의 변화를 최소화 할 수 있는 neuron의 rank를 높게 부여하는 방법이다. 이제 다른 ranking 방법에 대해 효용성을 측정하기 위해 oracle과 spearman과의 correlation을 계산한다. 놀랍게도 논문에서 제안한 ranking method(밑에 설명)은 oracle과 관련이 크다.
- 네트워크 cost function의 first order(계산이 빠름) taylor expansion에 기반한 새로운 뉴런 ranking방법을 제안한다.
- 필터 h를 pruning하는것은 곳 이것을 0으로 만드는것과 동일하다.
- C(W, D)는 네트워크 weight가 W로 설정된 경우 데이터 집합 D에 대한 평균 network cost function을 의미한다. 이제 C(W, D, h=0) 주변으로 expansion함으로써 C(W, D)를 평가할 수 있게된다. 단일 filter를 제거하더라도 cost에 미치는 영향이 작아야 하므로 C(W, D)와 C(W, D, h=0)이 매우 가까워야한다.
- 필터 h의 ranking은 abs(C(W, D, h = 0) - C(W, D))다.
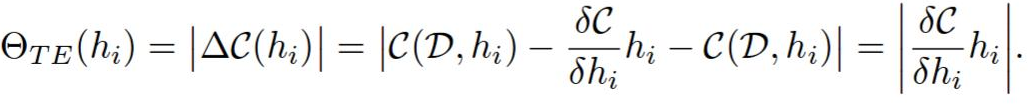
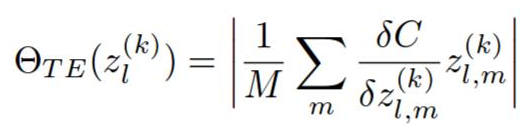
- 각 layer의 ranking들은 해당 layer의 rank들끼리 L2 norm으로 normalize된다. 아마도 이건 실험적으로 이렇게 했을 때 결과가 좋았기 때문에 이렇게 하는거같고.. 이 과정이 원글 저자는 구지 필요한지는 모르겠다고 한다. 하지만 pruning의 quality에는 지대한 영향을 끼치는것은 확실하다.
- 이 rank는 매우 직관적이다. 각 activation과 gradient 모두를 ranking 방법으로 사용할 수 있다. 이 중 하나라도 높게되면 이는 곧 output과 밀접한 연관이 있는 filter임을 의미한다. 이것들을 모두 곱함으로써 각 gradient나 activation이 매우 높거나 낮을 때 해당 filter를 유지하거나 버릴지를 결정하도록 하는데에 대한 기준을 삼을 수 있게된다.
- 이 논문에선 pruning problem을 네트워크 cost의 변화를 최소화 하는 문제로 바꾸고, taylor expansion 방법을 제안한다음, costs oracle의 차이를 통해 어떻게 네트워크를 pruning하는지를 제안했다. 이 논문에선 제안하는 방법이 다른 방법들의 성능보다 좋은 결과를 냈기때문에 oracle이 좋은 indeicator라고 생각 할 수 있다. 어쨌든 이게 particle filter 방법보다 더 적용이 간편하고 이해가 쉬우므로 이것을 implementation시켜본다.