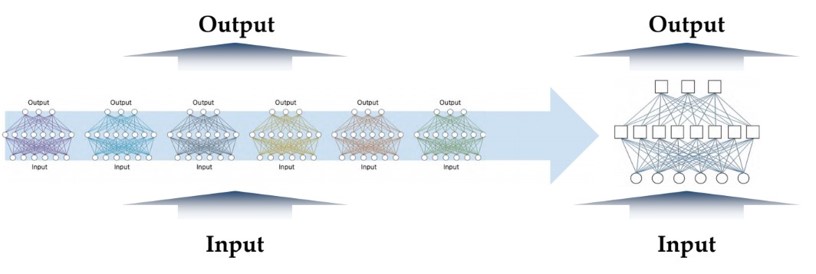
모델의 효율을 좋게 하도록 redundancy를 줄이거나 efficiency를 높이는 방식
Pruning / Distillation
Pruning: 모델에서 중요도가 낮은 뉴런을 제거하여 직접적인 모델 크기의 감소
모델의 redundancy를 줄이는 방법
장점: 모델 최적화에 따른 연산량 감소 및 모델사이즈 축소율이 상당함
단점: 모델 학습 및 pruning 과정이 복잡하고 매우 오래 걸리며, task별로 다른 적용방법을 필요로함
Distillation: 작은 모델에 큰 모델의 정보(knowledge)를 전달하여 작은 모델의 정확도를 향상시킴
모델의 efficiency를 높이는 방식
장점: Pre-trained model을 이용해 빠르게 학습시킬 수 있으며 범용적으로 적용 가능
단점: 모델 최적화 개념보다는 존재하는 모델의 표현력(capacity)을 최대한 사용하게 되어 정확도가 향상되어 큰 모델을 대체할 수 있게 되는 간접적인 모델 사이즈 축소방법
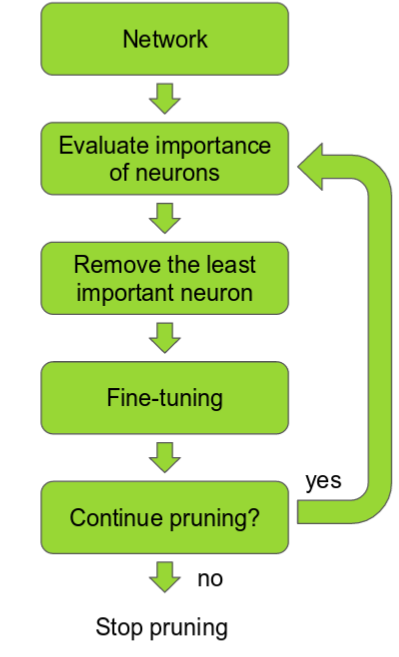
Network Pruning
네트워크의 수많은 파라미터중 중요하지 않은 파라미터들을 제거하는 방법
어떠한 기준을 정하여 rank를 만들도록 뉴런을 정렬(ranking)
Ranking에 따라 일정 threshold를 넘지 못하는 뉴런을 제거
이 과정에서 뒤에 연결된 뉴런에까지 모두 영향을 미치므로 파라미터가 많이 제거됨(pruning)
Pruned 네트워크의 정확도는 전에비해 조금 감소됨
너무 많이 pruning이 되면 네트워크가 손상되어 정확도 회복이 불가능
Pruning 후 네트워크를 재학습시켜 정확도를 회복
Interactive Pruning
Interactive pruning
Pruning Convolutional Neural Networks for Resource Efficient Inference
ICLR 2017 논문(Nvidia)
Pre-trained VGG16의 filter를 random하게 골라 pruning하고 validation set에서 cost function의 변화를 제일 적게 하는 뉴런의 rank가 높도록 하여 나열
실험결과 VGG16 네트워크 모델사이즈 10배정도 줄일 수 있었음
Caltech Birds-200 dataset 이용
Network Pruning on SSD
Multi-layer Pruning Framework for Compressing Single Shot MultiBox Detector
Singh, Pravendra, et al. 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019.
Single Shot Multi-Box Detector(SSD)를 pruning
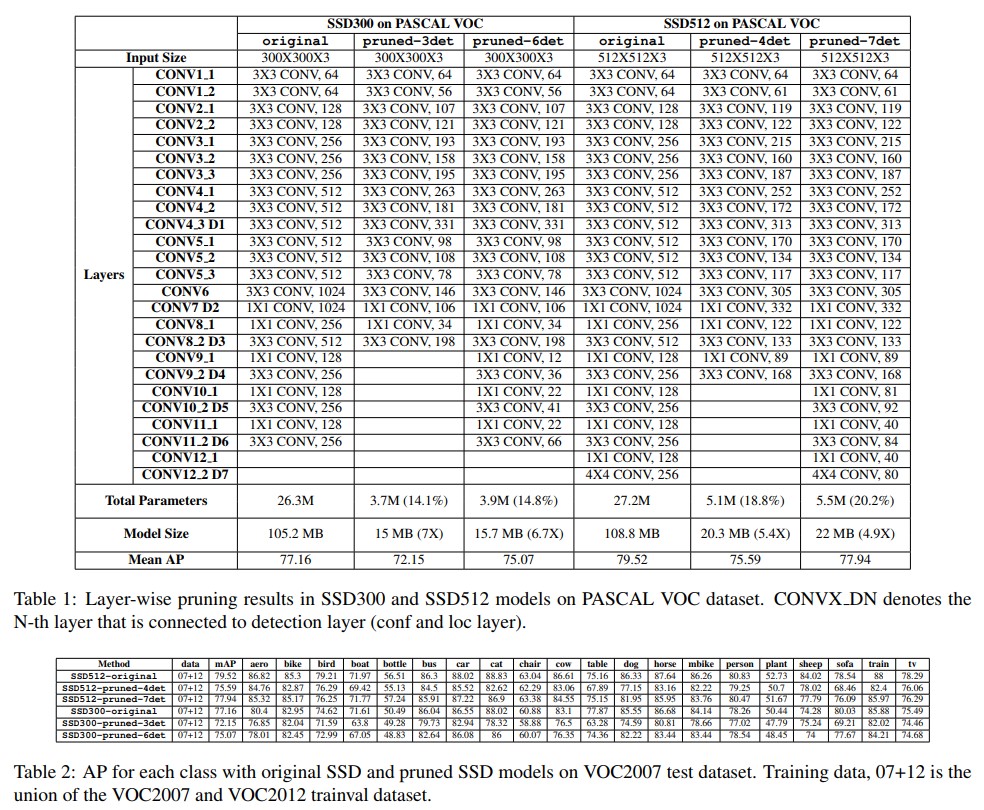
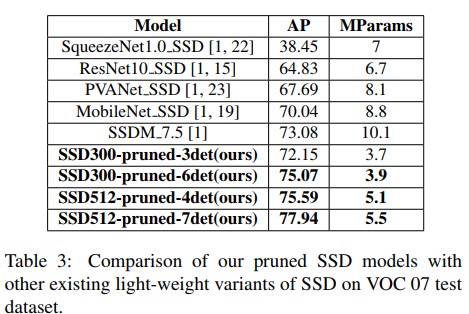
Object detection: PASCAL VOC dataset에 대해 정확도는 유지하며 6.7~4.9배의 모델 압축(VGG16 based)
Classification: CIFAR dataset에 대해 정확도는 유지하며 125배의 모델 압축(VGG16)
Sparsity induction: Pre-trained SSD 를 L1-norm이 적용된 loss function으로 threshold 이하의 weight를 0으로 만들어 pruning 될 layer 집합 𝐿을 만듦
L1-norm에는 test set과 val set을 이용함
기준이 될 threshold는 validation set을 이용하여 해당 레이어의 값 평균을 기준으로 정함
Filter selection: 이렇게 선택된 layer 집합 𝐿의 레이어 𝑙의 중요도를 평가
레이어 𝑙과 다음 레이어 𝑙+1간의 filter sparsity statics를 이용하여 중요도 평가
이 과정에서 레이어 l에서 중요하지 않다고 판단되는 filter의 list를 얻음
Layer 집합 𝐿에 대해 모두 반복수행
Pruning: 앞에서 중요하지 않다 판단된 레이어 𝑙과 해당 output과 연결된 layer 𝑙+1을 제거
Layer 집합 𝐿에 대해 모두 반복수행
Retraining: 앞에서 pruning된 네트워크를 original loss(SSD)를 이용해 떨어진 정확도를 복원(재학습)
실험 결과
실험 결과 정확도는 비교적 보존하면서 네트워크의 크기는 매우 크게 줄어들게 됨
또한 여타 모델에 비해 훨씬 높은 mAP로 추론하면서도 훨씬 작은 파라미터수를 가짐
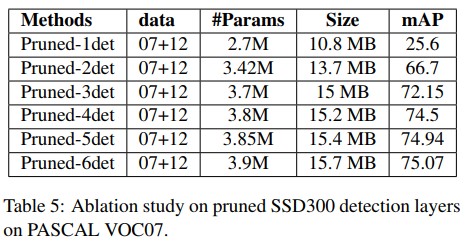
SSD300의 경우 detection layer를 뒷단에서 pruning 하는것이 앞단에서 하는것보다 더 정확한 실험 결과를 보이는 것을 확인 할 수 있었는데, 이는 구조상 4, 5, 6번째 detection layer의 parameter 수가 매우 적지만 큰 객체를 찾는데 주요하게 작용하기 때문임
Network Distillation
개발에 사용되는 딥러닝 네트워크와 실제 적용되는 모델은 다름
개발에는 리소스 사용이 자유롭지만, application단에서는 그렇지 않음
이를 위해 크고 무거운 모델의 정보(knowledge)를 작고 가벼운 모델로 전달하여 작고 가벼운 모델이 더 정확한 추론을 하도록 학습시킴(Knowledge Distillation, KD)
Overfitting등에 강인한 앙상블(ensemble) 모델 및 ResNet등 무거운 모델(teacher network)에서 distilled knowledge를 작고 가벼운 모델(student network)로 전이(transfer)
이 과정에서 작고 가벼운(shallow/small) student model은 무거운 teacher model의 정보를 전달받을 수 있음
Network Distillation methods
Model compression
Buciluǎ, C., Caruana, R., & Niculescu-Mizil, A. (2006, August). In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 535-541). ACM.
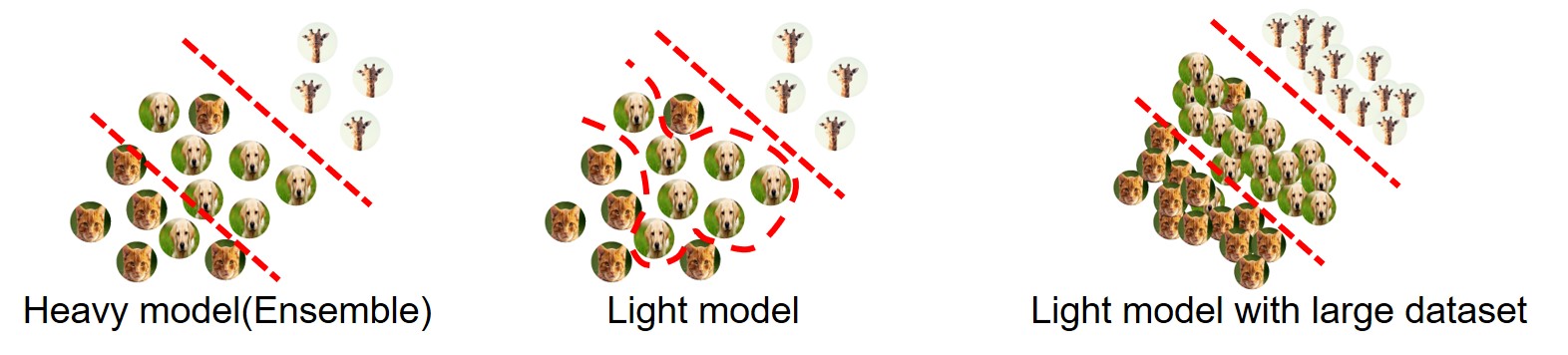
관측치(training dataset)가 많다면 구지 앙상블 모델을 쓰지 않고도 일반화 성능이 좋아진다는 점에서 착안
Heavy model(ensemble)은 학습 데이터셋이 많지 않아도 일반화 성능이 좋아 실제 test단에서 성능이 좋음
일반적으로 shallow model은 training set에만 적합하도록 overfitting되는 경향이 있음
Training set이 많다면 overfitting이 발생하더라도 전반적으로 generalization 성능이 좋아짐
Training set을 noise성분을 추가해 oversampling 하여 unlabeled oversampled data 생성
Pre-trained heavy model로 oversampled data를 labeling하여 oversampled dataset 생성
Oversampled dataset과 기존의 training dataset을 합쳐 large dataset을 만들어 light model 학습
Large dataset에는 heavy model(ensemble)의 정보가 담겨있음(distilled knowledge)
Light model의 large dataset을 이용한 학습을 통해 robust한 모델이 생성됨
More well-generalized / Robust against overfitting
실험 결과
Result
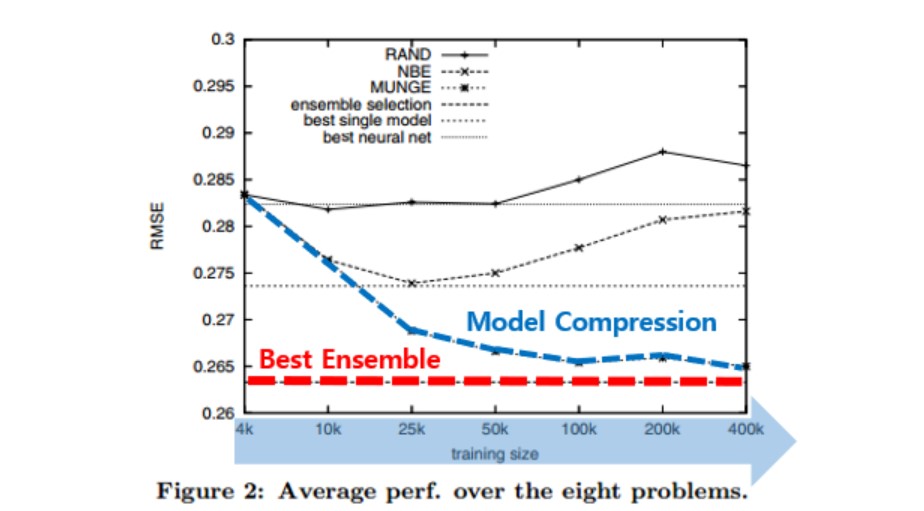
RMSE를 이용하여 모델 평가
Training dataset의 크기가 커질수록 compressed model의 정확도가 향상됨
Ensemble 모델과 정확도가 유사해짐
Do deep nets really need to be deep?
Ba, J., & Caruana, R. (2014). In Advances in neural information processing systems (pp. 2654-2662).
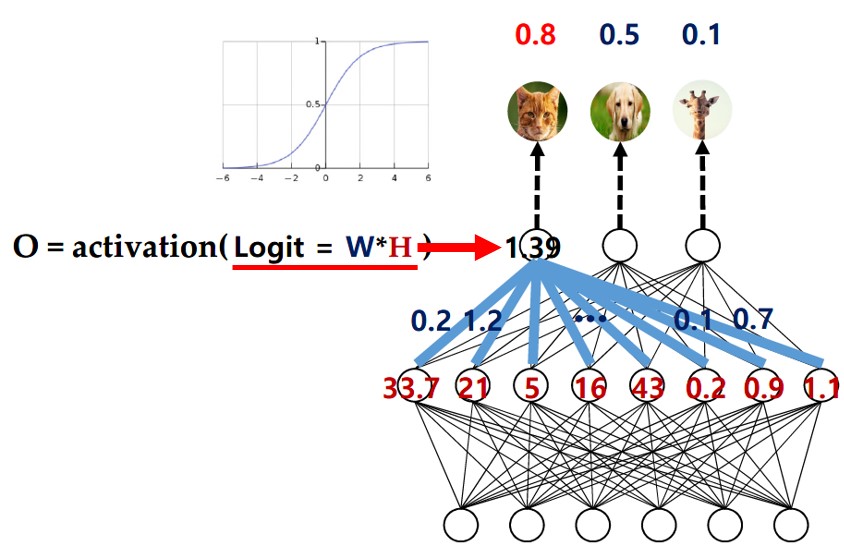
Distillation 과정에서 단순히 네트워크 출력으로 heavy model(ensemble)이 만든 class 정보를 주었던 앞의 방식에 logit 값을 적용하여 class information 뿐만 아니라 heavy model이 만들어내는 data 분포정보까지 전이
Logit은 클래스의 점수로, 이 점수를 학습시에 같이 고려하여 class의 확률분포를 알게 됨
Logit
Logit이란?
최종 추론 후 activation 통과 전의 값
학습과정
Pre-trained heavy model(ensemble)의 logit값을 light model로 전이해서 그 값을 토대로 학습
이 과정을 통해 추론class의 점수(heavy model의 출력분포)를 light model이 학습하게 되며 logit이 곧 distilled knowledge로 더 많은 정보를 이용하여 네트워크가 학습하게 됨
Deep Model Compression: Distilling Knowledge from Noisy Teachers
Sau, B. B., & Balasubramanian, V. N. (2016). arXiv preprint arXiv:1610.09650.
Distillation method 2와 큰 틀에서 동일
Heavy model의 logit을 light model이 닮도록 학습되어짐
하지만 heavy model(ensemble)의 logit값에 약간의 noise 성분을 추가
Logit에 noise성분 𝜖를 추가
추가된 noise 𝜖이 regularizer 역할을 하여 light model의 정확도가 향상됨
일반 training dataset으로 heavy model(ensemble)을 학습시킨 후, 해당 dataset에 대한 prediction의 분포값을 얻음(probability density function, pdf)
이 과정에서 일반적인 neural network가 사용하는 softmax가 아닌 temperature parameter 𝑇를 적용시킨 customized softmax를 사용
일반 softmax는 가장 큰 값을 1에 매우 가깝게, 나머지를 0에 매우 가깝도록 mapping(one-hot hard target)
Customized softmax는 temperature parameter 𝑇에 따라 1과 0 사이의 soft targets를 출력
𝑇가 0에 가까울수록 일반 hard target 생성(𝑇=1 일 때 일반 softmax)
𝑇가 10에 가까울수록 모든 확률은 1/# of class 로 수렴해 제대로된 추론 불가
𝑇가 중간에 적절하도록 설정하여 soft targets를 생성하도록 하여야 함(실험적으로 찾아야함)
Pre-trained heavy network가 customized softmax를 이용하여 생성한 pdf를 생성하도록 light model이 학습
논문에선 𝑇로 2~5 사이의 값 중 적절한 값을 찾아 사용(dataset별로)
실제 loss function은 일반적인 softmax로 추론된 label 정보와 soft targets 정보 모두 학습을 위한 변형된 cross entropy loss가 사용됨
Cross entropy loss가 label 정보와 soft target 정보 활용을 위한 2개 term으로 나뉘어 있으며, 비율이 𝛼로 조절됨(𝛼=0.5)
실험 결과
실험 결과, 일반적인 경우에 비해 soft target이 적용된 모델이 더 정확함
실험 결과
Network Distillation on SSD
Object detection at 200 Frames Per Second
Mehta, Rakesh, and Cemalettin Ozturk. Proceedings of the European Conference on Computer Vision (ECCV). 2018
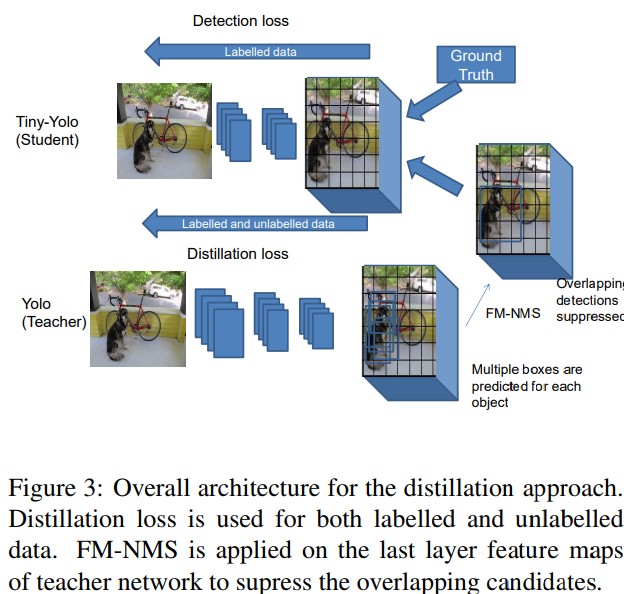
정확도가 높은 teacher network의 정보를 distillation loss, unlabeled data를 이용하여 light-weight student network에 전달
Keypoint
Tiny-Yolo(Yolo-v2)를 변형하여 효율적인 구조 제안
Deep/narrow 구조를 이용하여 정확도는 보존하면서 연산량 줄임
Distillation loss
Training data
Main contributions
R-CNN 계열에 대한 distillation 적용이 아닌 sing shot 방식의 detector에 대한 적용
Single shot detector가 네트워크의 추론 후 외부의 non-maximal suppression(NMS)를 사용하여 최종 출력을 낸다는 것을 참고하여 FM-NMS를 제안하고, 이로부터 teacher의 distilled knowledge를 student로 전이
Objectness scaled distillation loss를 제안하고, 이를 이용하여 distillation을 수행
Dense feature map stacking
Feature map을 pooling을 사용하여 concat하는 방식이 아닌 yolo-v2의 feature map stacking 사용
일반적인 max pooling은 정보의 손실이 발생하므로 큰 feature map을 resize하여 feature map의 activation이 다른 feature map으로 분산되도록 함.
Bottleneck을 적용해 depth를 추가하여 네트워크 용량(capacity)은 늘리면서 연산량과 파라미터 수를 보존
Deep but narrow
Feature extractor의 출력 개수를 줄이고 feature stacking을 이용
Narrow하고 deep하도록 1x1 conv layer를 이용하여 연산량을 보존
Distillation loss for Training
네트워크의 최종 출력은 너무 많은 정보를 담고있음
NMS를 거치기 전의 feature map에서 객체 클래스 정보와 위치 정보가 혼잡하게 존재
이를 그대로 distillation할 경우 student는 overfitting으로 인해 정확도가 오히려 하락함
이를 해결하기 위해 student의 bounding box coordinate와 class probability가 teacher prediction의 objetness value가 높을때만 distilled 정보를 학습하도록 함
학습 과정에서 loss function에 의해 teacher가 background로 분류되는 객체에게 매우 작은 objectness value를 할당하도록 학습됨
Feature Map-NMS(FM-NMS)
동일 객체가 존재할것이라 네트워크가 추론하는 KxK cell 지역에 multiple candidate가 존재한다면 하나의 객체일 확률이 큼
이 중 가장 높은 objectness value를 갖는 결과를 선택하여 객체로 함.
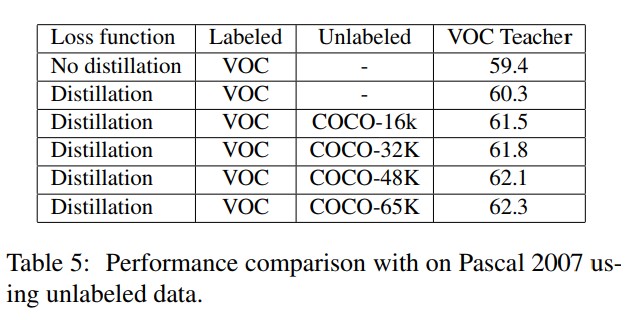
Effectiveness of data
Labeled data가 많아질 때 네트워크의 정확도가 얼마나 개선되나 확인
PASCAL VOC와 해당 클래스의 MS COCO 이용
Unlabeled data에 대해선 teacher의 output(soft label)만을 이용하여 student를 학습
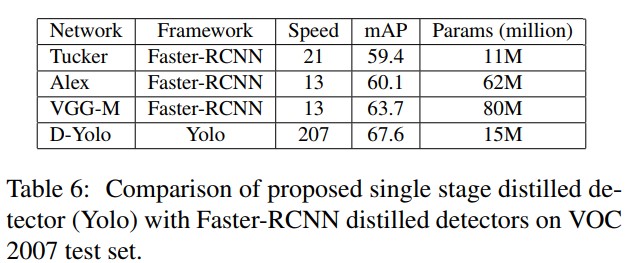
실험 결과(table 1, 3)
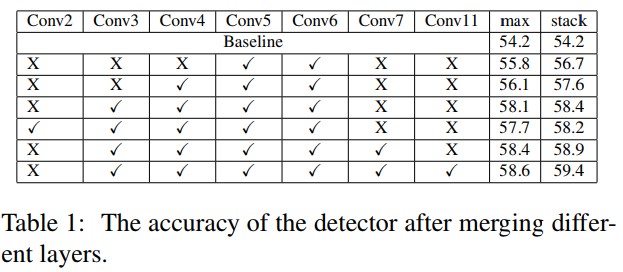
Merging different layers
다양한 layer에서 feature map이 stacking 될 때 정확도가 더 향상됨
초기 레이어보단 뒤쪽 레이어를 stacking하는게 정확도 향상에 도움됨
Max pooling보다 stacking이 더 정확도가 향상됨
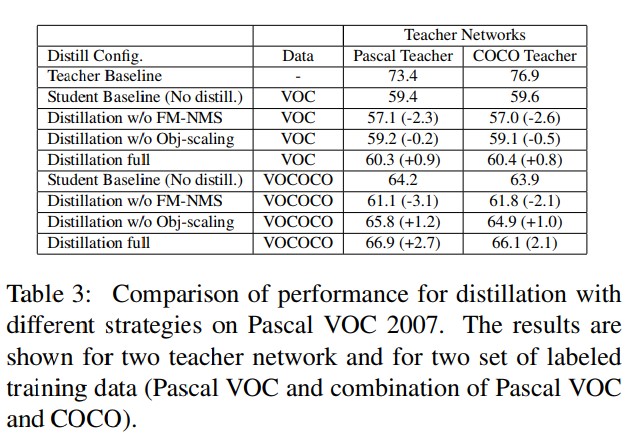
Distillation with labeled data
PASCAL VOC 2007, 2012와 COCO에서의 65K 추가 이미지
실험 결과, distillation을 적용하기 위해선 distillation loss function의 objetness value scaling이 필수로 필요함(Obj-scaling)
학습 데이터셋이 많을수록 더 많은 soft label이 이용 가능해지므로 student의 정확도 향상이 컸음
하지만 teacher의 성능은 student의 성능향상에 크게 영향을 끼치지 못함(COCO teacher의 정확도에 상관 없이 student는 모두 정확도가 비슷하게 향상)

 Seongkyun Han's blog
Seongkyun Han's blog