
 Seongkyun Han's blog
Seongkyun Han's blog
Batch normalization
19 May 2019 | Batch normalizationBatch normalization
- 참고 글: https://sacko.tistory.com/44
1. 배치 정규화 도입
- Batch normalization: 네트워크 학습 과정에서 gradient vanishing/exploding을 해결하기 위한 접근방법
Batch normalizatioln(배치 정규화)
- 학습의 효율을 높히기 위해 도입됨.(regularization)
- 학습 속도의 개선이 가능
- 가중치 초깃값 선택에 대한 의존성이 적어짐
- 학습 시마다 출력값을 정규화하기 때문
- 과적합(overfitting) 위험을 줄임
- Drop out 대체 가능
- Vanishing gradient 해결
- 배치 정규화는 활성화함수의 활성화값 또는 출력값을 정규화(정규분포로 만들어줌)하는 작업임
- 배치 정규화를 활성화함수 이전에 하는지 이후에 하는지는 아직 정답이 정해져있지는 않음
- 신경망의 각 layer에서 데이터(batch)의 분포를 정규화 하는 작업으로, 일종의 noise를 추가하는 방법으로(bias와 유사) 이는 배치마다 정규화를 함으로써 전체 데이터에 대한 평균의 분산과 값이 달라질 수 있음
-
학습할 때마다 활성화값/출력값을 정규화하기 때문에 초기화(가중치 초깃값)문제에서 비교적 자유로워짐
- 각 hidden layer에서 정규화를 하면서 입력분포가 일정하게 되고 이에따라 learning rate를 크게 설정해도 학습이 잘 진행되게 됨
- 학습속도가 빨라지게 됨
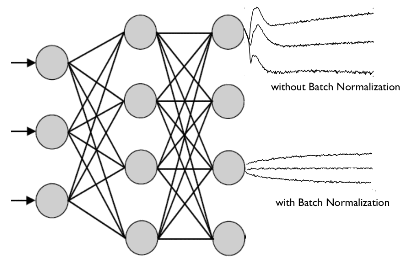
입력 분포의 균일화
- 학습할 때 hidden layer의 중간에서 입력분포가 학습할 때마다 변화하면서 가중치가 엉뚱한 방향으로 갱신될 가능성이 있으며, 이 때 학습이 제대로 이루어지지 않게 됨
- 신경망의 깊이가 깊어질수록 학습 시에 가정했던 입력분포가 변화하여 엉뚱한 학습이 될 수 있음
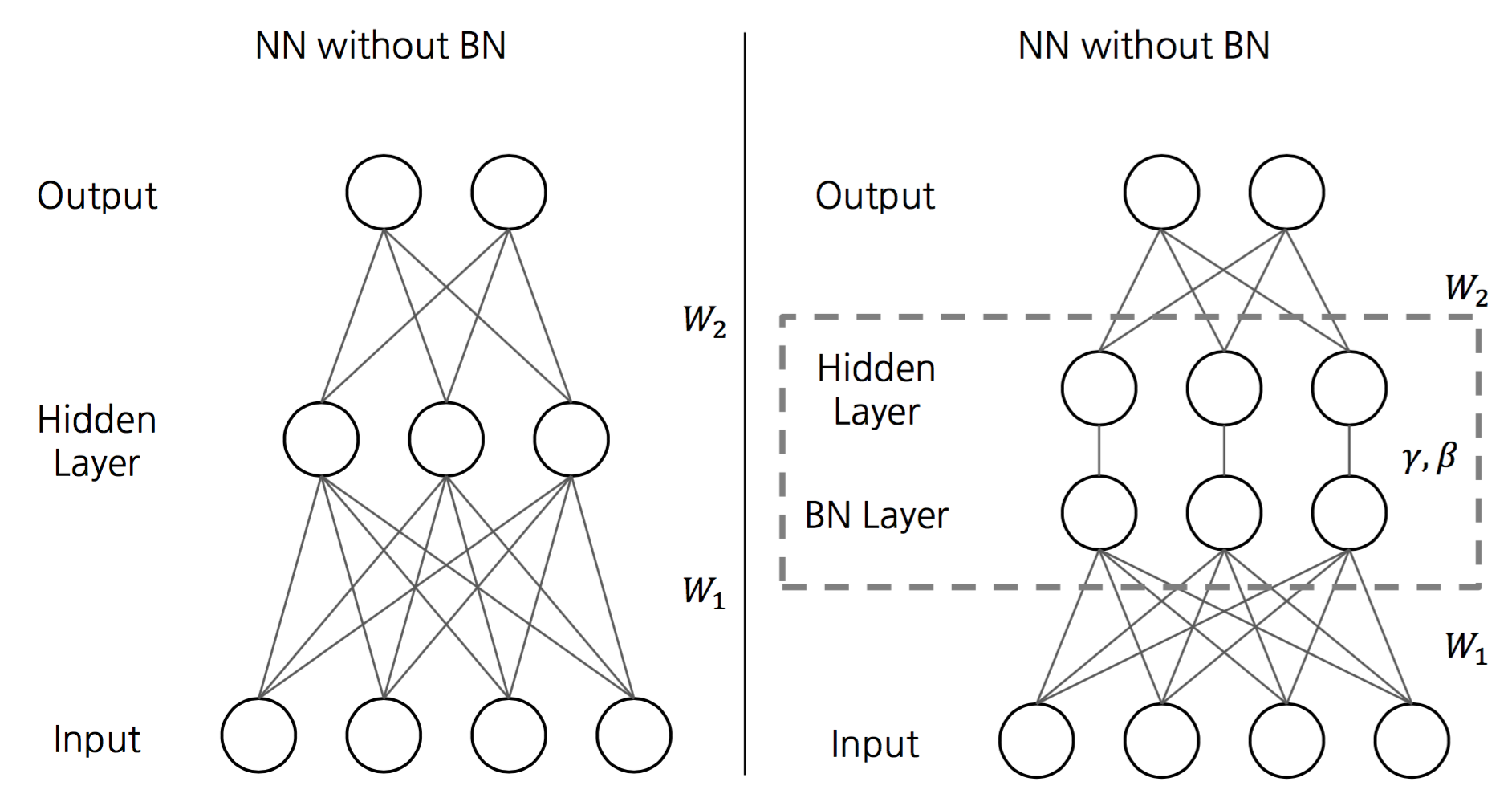
2. 배치 정규화 알고리즘
- 간단하게 배치 정규화는 학습 시의 mini-batch를 한 단위로 정규화를 하는 것으로, 분포의 평균이 0, 분산이 1이 되도록 정규화 하는것을 의미함

- 먼저 input으로 사용된 미니배치의 평균과 분산을 계산
- 그 다음 hidden layer의 활성화값/출력값에 대해 평균이 0, 분산이 1이 되도록 정규화(normalization) 수행
- 이로인해 데이터의 분포가 덜 치우치게(biased) 됨
- 배치 정규화 단계마다 확대 scale과 이동 shoft 변환(transform)을 수행
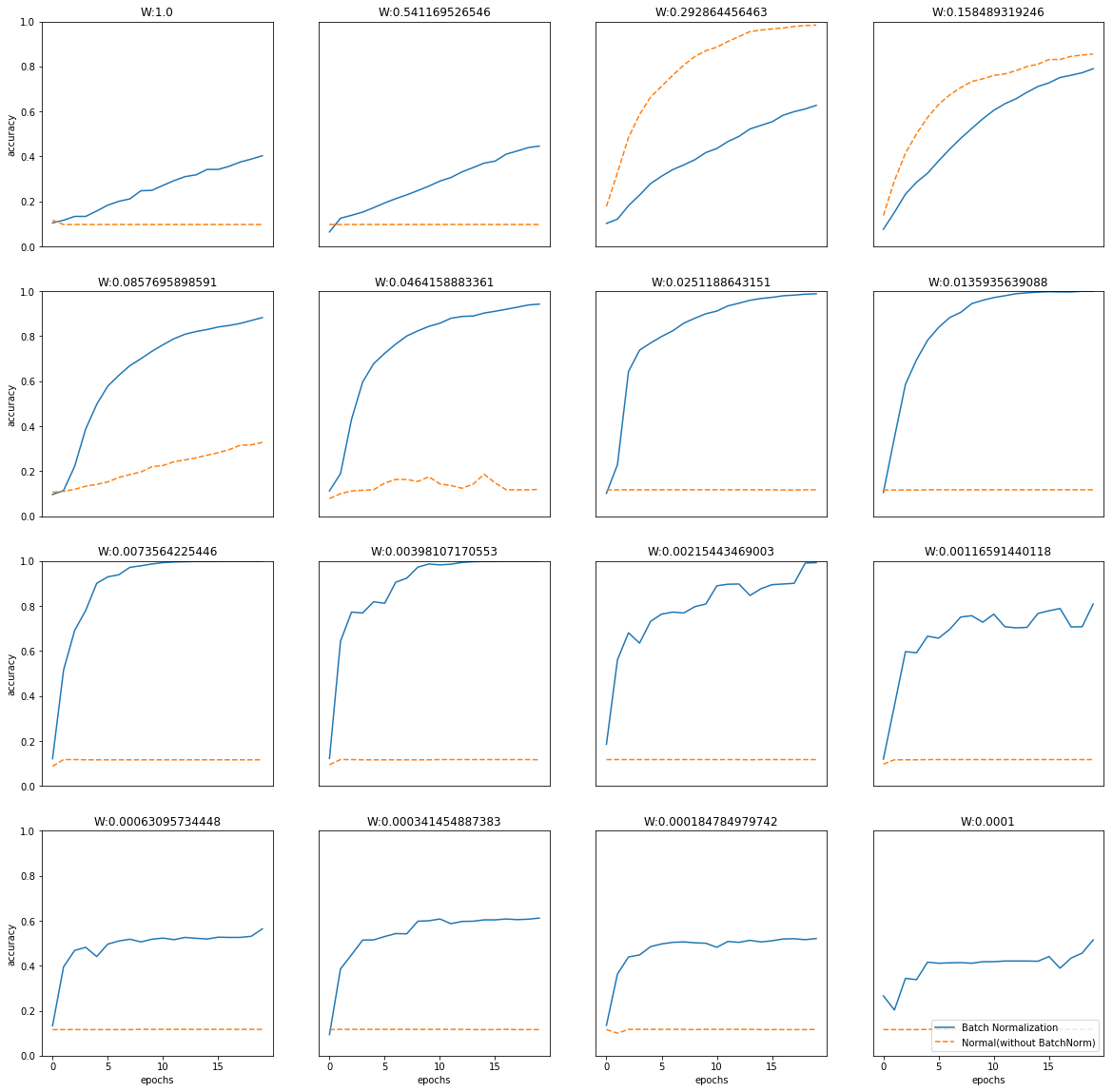
- 그림에서 파란색 선이 배치 정규화를 했을 때의 결과임
- 훨씬 학습 속도가 빠르며, 가중치 초깃값 세팅에 영향을 받지 않는것도 확인 가능
3. 기타 참고
- 배치 정규화는 가중치의 scale을 정규화하여 gradient exploding을 방지

- ReLU와같은 활성화함수의 사용이나 낮은 learning rate값 사용, 초기화 작업등은 간접적인 vanishing gradient/exploding 방지를 위한 방법
- 학습 과정 자체에서 학습을 안정화시키고 학습속도를 개선하는 직접적인 vanishing gradient/exploding 방지를 위한 방법으로 제안된것이 배치 정규화
정리
- 네트워크 학습 시엔 mini-batch의 평균과 분산으로 normalize하고, test 할 때는 계산해높은 이동 평균으로 normalize를 한다.
- Normalize한 후엔 scale factor와 shift factor를 이용해 새로운 값을 만들고, 이 값을 내놓는다.
- 이 scale factor와 shift factor는 다른 레이어에서 weight를 학습하듯이 back-prop에서 학습되어진다.