
 Seongkyun Han's blog
Seongkyun Han's blog
Unsupervised Visual Representation Learning Overview (Self-Supervision)
29 Nov 2019 | CNN Deep learning Unsupervised learningUnsupervised Visual Representation Learning Overview (Self-Supervision)
- 참고
- https://www.youtube.com/watch?v=eDDHsbMgOJQ
- https://www.slideshare.net/HoseongLee6/unsupervised-visual-representation-learning-overview-toward-selfsupervision-194443768
What is “Self-Supervision”?
- 지도학습(Supervised learning)은 강력하지만 많은 량의 labeled data가 필요함
- 주로 다양한 문제들을 해결함에 있어서 labeled data를 사용하는 지도학습 모델을 많이 사용함
- 많은량의 양질의 데이터만 있다면 좋은 성능을 낼 수 있음
- 하지만 이는 labeled data가 없으면 사용 불가능하다는 문제가 있음
- 이러한 labeled data를 만드는데도 매우 큰 human factor가 필요함
- 이처럼 labeled data 문제를 해결하고자 다양한 방법의 un/self supervised learning 방법들이 연구됨
- 주로 다양한 문제들을 해결함에 있어서 labeled data를 사용하는 지도학습 모델을 많이 사용함
- Self-supervised visual representation learning
- 본 글에선 비지도 학습(Unsupervised learning)의 한 분야인 self-supervised learning을 이미지 인식분야에 적용한 연구들에 대해 다룸
- Unlabeled data를 이용해서 모델을 학습시키며, 모델이 이미지의 higher level의 semantic한 정보들을 이해 할 수 있도록 학습됨
- 이를 위해 필요한게 pretext task
- Pretext task란, 딥러닝 네트워크가 어떤 문제를 해결하는 과정에서 영상 내의 semantic한 정보들을 이해 할 수 있도록 배울 수 있도록 학습되게 하는 임의의 task
- Pretext task는 딥러닝 네트워크가 semantic 정보를 학습하도록 사용자가 임의대로 정의하게 됨
- 이렇게 pretext task를 학습하며 얻어진 feature extractor들을 다른 task로 transfer시켜 주로 사용함
- Self-supervised visual representation learning에서 사용하는 pretext task들
- Exempler, 2014 NIPS
- Exampler가 처음에 나오고, 이와 관련된 연구들이 계속해서 진행됨
- Relative Patch Location, 2015 ICCV
- Jigsaw Puzzles, 2016 ECCV
- Autoencoder Base Approaches - Denoising Autoencoder(2008), Context Autoencoder(2016), Colorization(2016), Split-brain Autoencoders(2017)
- Count, 2017 ICCV
- Multi-task, 2017 ICCV
- Rotation, 2018 ICLR
- Exempler, 2014 NIPS
Exemplar
- Discriminative unsupervised feature learning with exemplar convolutional neural networks, 2014 NIPS
- STL-10 데이터셋을 사용해 실험
- STL-10의 96x96크기의 영상 내에서 considerable한 gradient가 있는(객체가 존재할 만한 영역) 부분을 32x32 크기로 crop
- 이렇게 crop된 32x32 크기의 패치를 seed patch로 하고, 이 seed patch가 하나의 class를 의미하도록 함
- Seed patch를 data augmentation에 사용하는 transformation들을 적용시켜 추가영상을 만들어냄


- 위처럼, seed image를 data augmentation을 적용시켜 여러개로 부풀리고, 부풀려진 data를 seed image로 판독하도록 네트워크를 학습시킴
- 예를들어
- Deer seed 1번 영상으로 총 23장의 영상을 생성한 후, 해당 seed를 1번 클래스로 지정
- Deer seed 2번으로(1번과 다름) 총 23장의 영상을 생성한 후, 해당 seed를 2번 클래스로 지정
- 이런식으로 총 N개의 영상에 대해 N개의 클래스가 존재하게 됨
- Classifier는 하나의 seed image랑 augmented 영상들을 같은 class로 분류하도록 학습됨
- 하지만 이런 경우, ImageNet과 같이 백만장의 영상으로 구성된 데이터셋은 총 백만 개의 class가 존재하게 되는 꼴
- 학습 난이도가 올라가며 파라미터수도 매우 많아지게 됨
- 따라서 이런 Exemplar 방식은 큰 데이터셋에는 적합하지 않음
Relative Patch Location
- Unsupervised Visual Representation Learning by Context Prediction, 2015 ICCV
- 위의 Exemplar 방식의 단점을 해결한 논문
- 한 장의 영상에서 3x3개의 패치들을 뜯어오고, 가운데 패치를 기준으로 1번부터 8번까지 할당
- 가운데 패치 기준으로 임의로 선택된 패치가 1번부터 8번 패치 중 몇 번 패치인지 예측하도록 모델이 학습됨
- 3x3 패치 기준 총 8개의 클래스만 존재하는 꼴
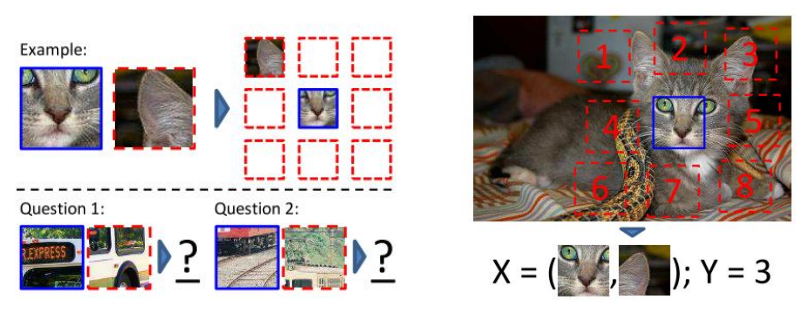
- 위 사진 좌측처럼 사람이 예측하기도 어려운 문제를 학습시키면 이미지 전반의 representation을 배울 수 있을 것이라는 가정에서 나온 연구
- AlexNet 기반의 네트워크를 사용함
- 위 사진 우측처럼 patch는 일정하게 만들어지지 않고 약간 위치가 바뀌게끔 설정됨
- 일정하게 patch를 만들게 되면 모델이 trivial solution만을 추론하는 경우가 발생 할 수 있으므로, 이를 위해 약간의 위치 조정을 적용함
- Gap, Randomly jitter 등이 적용
- 하지만 이 방법도 완벽하게 trivial solution을 피하지는 못함
- 이를 완벽히 피하는 solution이 jigsaw puzzle 방법
- 일정하게 patch를 만들게 되면 모델이 trivial solution만을 추론하는 경우가 발생 할 수 있으므로, 이를 위해 약간의 위치 조정을 적용함
- 위의 방식대로 feature extractor를 학습시킨 후 다른 task에 해당 모델을 transfer 시켰을 때 성능이 좋았음

Jigsaw Puzzles
- Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles, 2016 ECCV
- 직소퍼즐 풀게하는 pretext task
- 앞과 비슷하게 3x3 패치를 뜯고, 임의의 permutation을 적용해 직소퍼즐처럼 셔플링을 수행함
- 여기서 네트워크는 어떤 permutation이 적용되어 해당 patch가 만들어졌는지를 예측하게 됨
- 셔플링 된 위치가 본래 어디 위치인지를 추론해야 함
- 직관적 이해는 밑에서..
- 셔플링 된 위치가 본래 어디 위치인지를 추론해야 함
- 하지만 9!=362,880 으로 classifier에겐 약 36만개의 class를 배워야 하게 됨
- 불가능!
- 따라서 유사한 permutation을 제거해 100개의 pre-defined permutation을 사용함
- 최종적 으로 네트워크의 출력은 permutation index를 예측한 100-d의 벡터가 됨

- Network는 AlexNet 기반의 모델을 사용했음
- 논문 방법의 직관적 이해는 아래와 같음
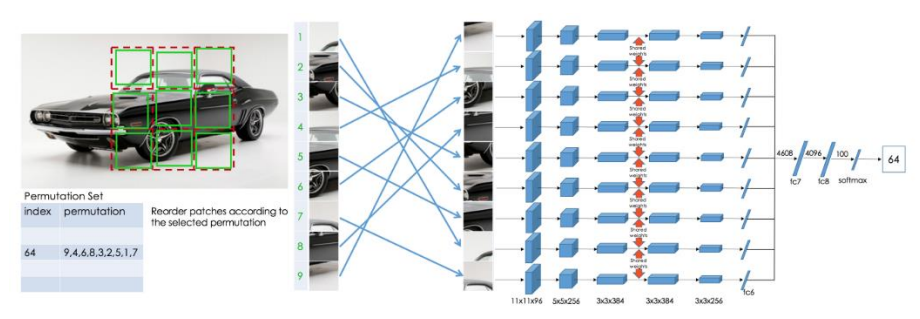
- 위 사진처럼 총 9조각 기준으로 각자 자기 원래 위치에 해당하는 위치 값을 추론하게 됨
- 사진의 예시 기준 총 9개의 AlexNet 기반의 네트워크를 사용함
- 모델의 weight는 서로 sharing
- 사진의 예시 기준 총 9개의 AlexNet 기반의 네트워크를 사용함
Autoencoder-Base Approaches
- Denoising Autoencoder, Context Autoencoder, Colorization, Split-brain Autoencoders
- Learn image features from reconstructing images without any annotation
- 아래와 같은 일련의 이미지 복원 과정을 통해 네트워크가 영상 전반의 representation을 학습 할 수 있게 된다는 가정
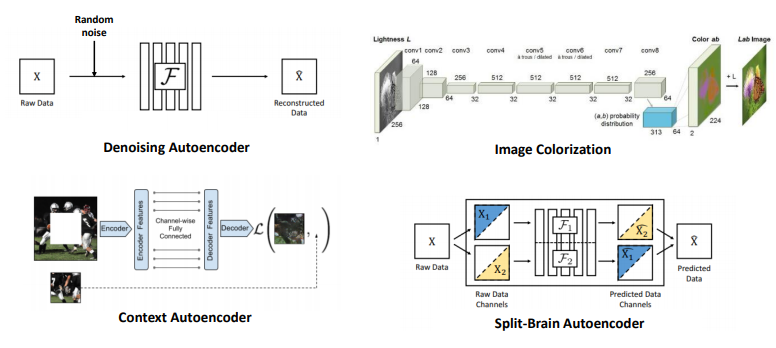
- Denoising Autoencoder: 랜덤 노이즈가 섞인 원본 raw data에서 네트워크를 거쳐 원본 raw data를 복원하는 방법
- Image Colorization: 흑백 영상을 색을 입혀 컬러 영상으로 바꿔주는 방법
- Context Autoencoder: 영상 내 중간에 뚫린 부분을 추측/복원하는 방법
- Split-Brain Autoencoder: 이미지의 절반을 잘랐을 때, 네트워크가 나머지 잘린 이미지 절반을 맞추도록 하는 방법
Count
- Representation Learning by Learning to Count, 2017 ICCV
- 한 patch의 object의 특징들을 가상의 vector로 표현함
- ex. 각 패치 안에 코 2개, 눈 4개, 머리 1개 등등..
- 이런 특징들은 각 패치나 전체 영상이 up/down sampling 되어도 유지가 되어야 함
- 각 패치의 특징 벡터들의 합은 원래 이미지의 특징 벡터의 합과 같다는 가설에서 제안된 논문
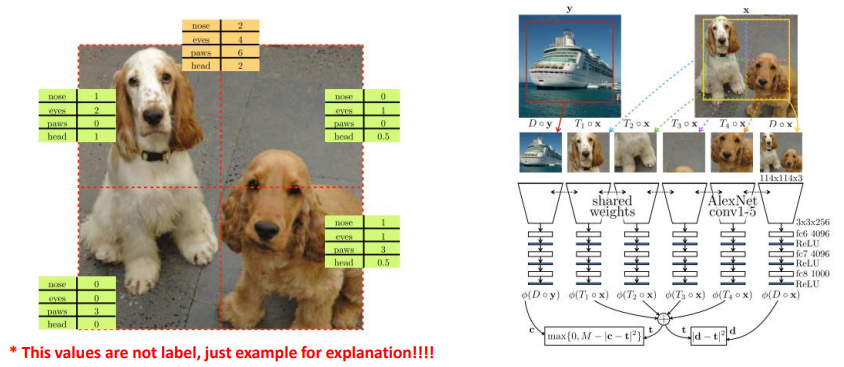
- 메인 아이디어는
- 이미지를 네트워크에 넣고, feature extractor를 통해서 최종 출력으로 위와 같은 패치별 특징 벡터를 구하도록 모델을 구현 후 학습시키게 됨
- 위 사진 우측처럼 네트워크는 학습되게 됨
- 원본 이미지를 그냥 down sampling 했을 때 추론되는 특징 vector와
- 각 patch별로 네트워크에 들어갔을 때 얻어지는 특징 벡터들의 합이 같도록 학습됨
- 하지만 한 장의 영상만으로 학습 될 경우, 모든 feature를 0으로 추론하는 등의 trivial solution을 만들어내게 될 수 있음
- 이를 위해 패치로 잘리는 영상 x와 완전히 다른 영상 y를 넣었을 때 다른 feature vector가 나오도록 하는 contrastive loss를 추가
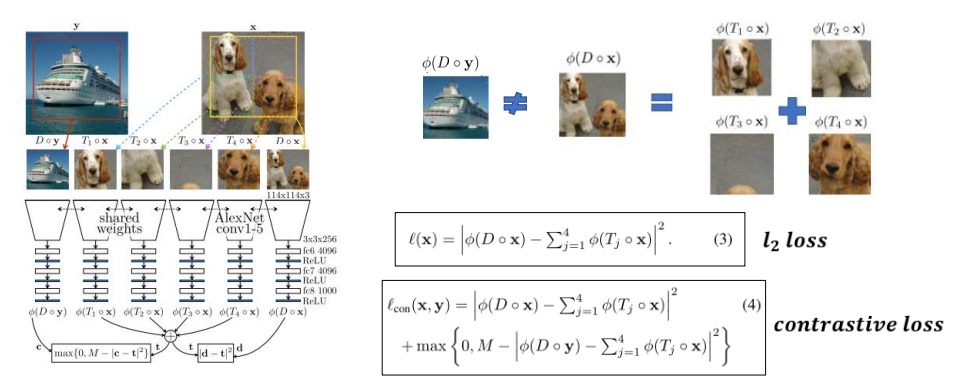
- Feature vector는 calculating loss(l2 loss)에서 사용됨
- Trivial solution을 피하기 위한 contrastive loss
Multi-task
- Multi-task Self-Supervised Visual Learning, 2017 ICCV
- 2017년 당시 주로 쓰였던 위의 4가지 self supervised learning들을 동시에 multi task로 학습시키는 방법
- 다른 4개의 self supervised learning 방법들을 한 개의 네트워크에 학습
- 앞의 context prediction task인 Relative Patch Location + Colorization + Exemplar + Motion Segmentation이 적용됨
- 성능을 ImageNet classification, PASCAL VOC 2007 detection, NYU V2 depth prediction으로 측정함
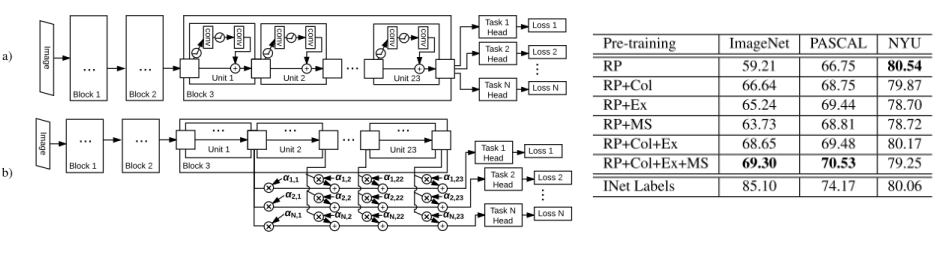
- 실험 결과를 봣을 때 4개를 모두 적용했을때의 결과가 가장 좋았음
Rotations
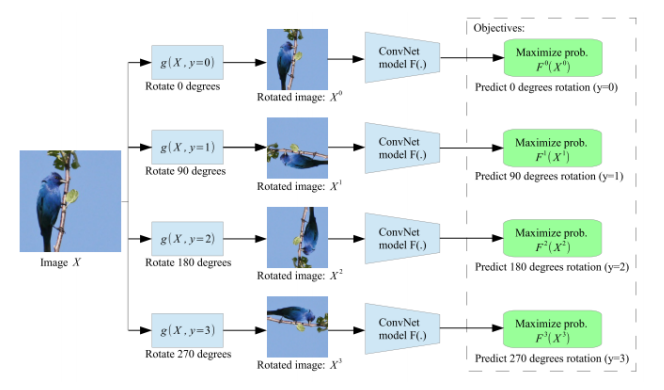
- Unsupervised representation learning by predicting image rotations, 2018 ICLR
- 이미지의 rotation을 추론하도록 학습하는 pretext task
- 각각 영상을 랜덤하게 회전시킴
- 회전영상으로 원본에서 몇 도 회전했는지를 예측함
- 0, 90, 180, 270의 4개 클래스가 존재
- 논문의 가설은
- 회전을 잘 예측하기 위해선 원래 영상의 canonical orientation을 잘 이해해야 하고, 이를 잘 이해하려면 영상 전반의 특징을 잘 이해 할 것이다라는 전제로 모델을 구현함
- 그리고 적용시켰을때도 성능이 실제 좋아졌음
성능 측정의 방법
- 앞의 방법들의 성능을 어떻게 측정할 것인가?
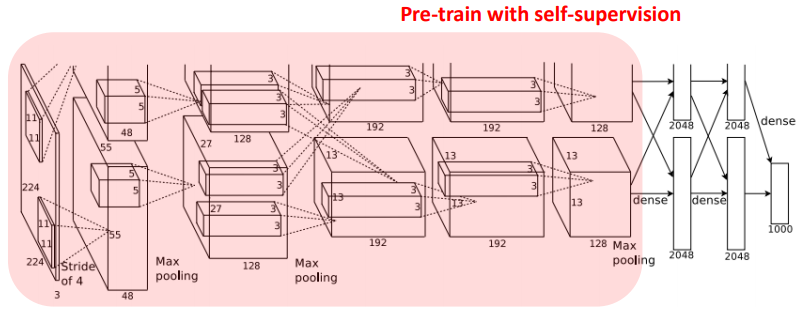
- 모델의 일반화 성능을 보기 위해 ImageNet 분류 task에 각 feature extractor들을 transfer learning시킴
- 모든 self supervised learning들을 ImageNet pretraining 시킴
- 이 때, label 정보는 사용하지 않고 해당 방법들의 pretext task를 따라 학습
- 다음으로, 모든 feature extractor들을 freeze하고, 뒤에 linear classifier를 붙여서 classification 결과를 확인
- Logistic regression으로 classifier를 구성했으며, 여기선 ImageNet 데이터 셋의 레이블 정보를 활용하여 supervised learning시킴
- 일종의 feature extractor as a fixed feature extractor transfer learning
- Logistic regression으로 classifier를 구성했으며, 여기선 ImageNet 데이터 셋의 레이블 정보를 활용하여 supervised learning시킴
- 실험엔 Batch size 192, SGD momentum (coefficient 0.9), weight decay 5e-4, learning rate 0.01 적용
- Learning rate decay는 총 30 epoch동안 10, 20 epoch에서 10배씩 줄어들게 적용됨
- 총 epoch가 매우 적기때문에 크게 의미있는 실험결과로 보긴 어려움
- 특히 from scratch로 학습하는 경우 epoch를 매우 크게 가져가지만, 실험에선 그러지 않음
- 총 epoch가 매우 적기때문에 크게 의미있는 실험결과로 보긴 어려움
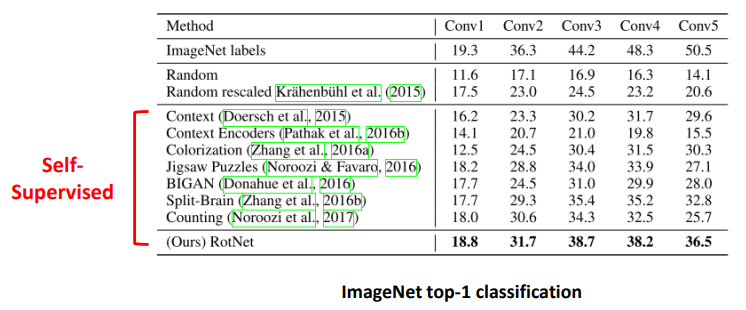
- 위 표에서 Conv1, Conv2, .. 는 AlexNet의 해당 layer까지 parameter를 freeze시키고 뒷부분을 학습시켰다는 의미
- ex. Conv2 는 Conv1과 Conv2가 freeze
- ImageNet labels: 일반적인 supervised learning으로 모델을 학습시킴
- Random/Random rescaled: 각 방법대로 conv layer weight parameter를 초기화하고 해당 레이어까지 freeze하고 학습시킴
-
Self-supervised: Feature extractor를 ImageNet 데이터셋을 이용해 레이블 정보를 활용하지 않고 각 논문의 pretext task에 따라 학습시키고 해당 레이어별로 freeze시키고, linear classifier를 붙였을 때의 결과들을 의미함
-
실험 결과를 보면, 모델 성능이 좋기 위해선 feature extractor가 이미지의 전반적인 semantic한 정보들을 잘 이해하고, representation을 잘 학습해야만 단순한 linear classifier 하나만으로도 성능이 잘 나올 수 있는것을 확인 할 수 있음
- 다음으로, PASCAL VOC 2007을 이용해 classification, detection, segmentation의 3가지 task에 대해서도 transfer 시켜봄
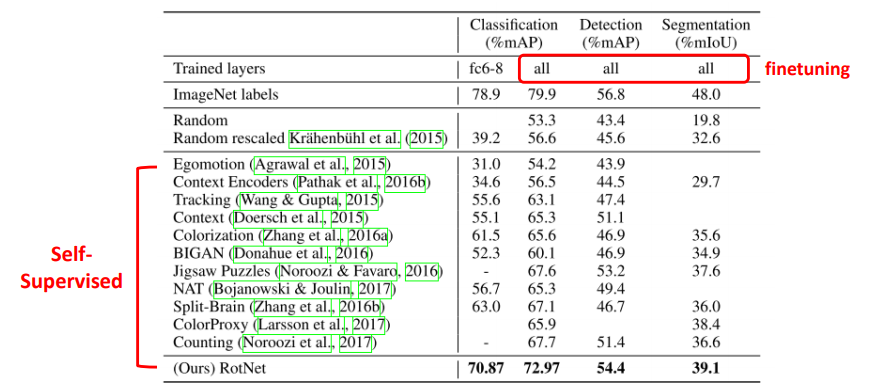
- 앞과 동일하게 이미지넷으로 각 방법별 pretraining 시키고 새 task로 transfer learning 시킴
- 하지만 conv layer별로 freeze가 아니라 모두 다 weight parameter가 update되도록 설정(un-frozen)
-
Random의 방법들을 볼 때, 적은 epoch로도 좋은 성능을 낸 것을 볼 수 있음
-
전반적으로 ImageNet pretrainined feature extractor를 썼을 때 보다도 성능이 좋은 것은 아니지만, detection같은 경우엔 mAP가 2밖에 차이가 나지 않을 정도로 나쁘지 않은 결과를 보임
- 위 실험들이 갖는 의미
- 레이블이 없는 경우에도 이렇게 self supervised learning의 pretext task로 feature extractor를 pre-training시켜 본래 task에 적용시키면(transfer) 비슷한 성능을 낼 수 있음을 의미함
- 본 글에서 다뤄지지 않은, 동일 내용을 다루는 논문들은 아래와 같음
- Deep Cluster (2018 ECCV)
- Revisiting Self-Supervised Visual Representation Learning (2019 CVPR)
- 앞의 논문들이 AlexNet만 갖고 실험했던것을 문제삼음
- 성능을 최대한으로 끌어올리기 위해 위처럼 다양한 pretext task를 적용시키는것도 중요하지만, 모델의 표현력이라는 기본기에도 충실한 실험을 해야한다는 관점에서 연구한 논문
- Selfie (2019 arXiv)
- Deeper Cluster (2019 ICCV)
- S4L (2019 ICCV)
- Semi supervised learning에 self supervised learning을 섞은 논문
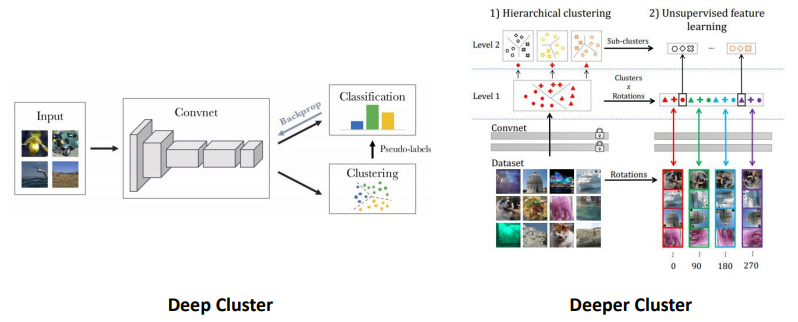
- Deep Cluster
- Unlabeled data들을 pretrained 네트워크에 넣어 feature map을 뽑고, feature map을 clustering 기반으로 sudo label을 만들어 학습시키는 방법
- Deeper Cluster
- Deep cluster의 개선 버전
- 위 두 방법 모두 상당히 좋은 성능을 보인다고 함
Summary
- 이런 self-supervised learning은 un-supervised learning에 속하는 문제
- Unlabeled data를 이용해 학습 시키는데 다양한 pretext task들을 창작해 영상의 전반적인 representation을 배울 수 있도록 문제를 만들고 학습시킴
- Pretext task로 pre-trained 된 feature extractor들을 다른 task에 transfer 시켰을 때의 결과를 분석함
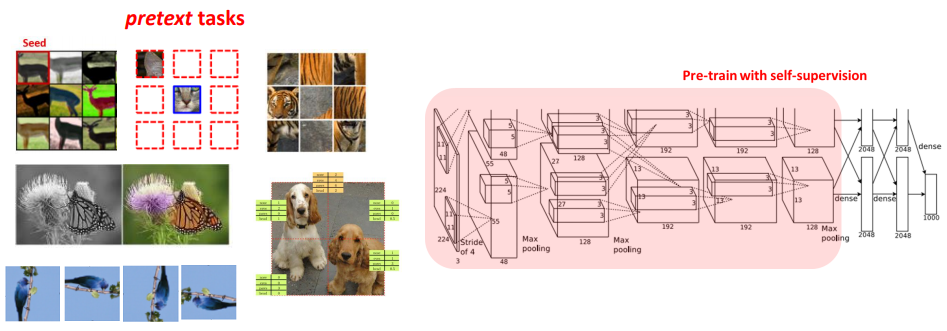
- 위의 방법들이 unsupervised learning이기에 supervised learning만큼 좋은 성능을 낼 순 없음
- 하지만 from scratch 학습보다는 좋은 성능을 보였음
- 또한 feature extractor들이 꽤 semantic한 정보들을 잘 배워서 단순한 linear classifier 하나만으로도 꽤 의미있는 성능을 보일 수 있었음