이 후 1.5epoch동안 unaugmented labeled images에 대해 큰 resolution으로 fine-tuning 시킴
위 방법을 제안한 논문과 유사하게 fine-tuning동안 shallow layer를 freeze시켜서 실험함
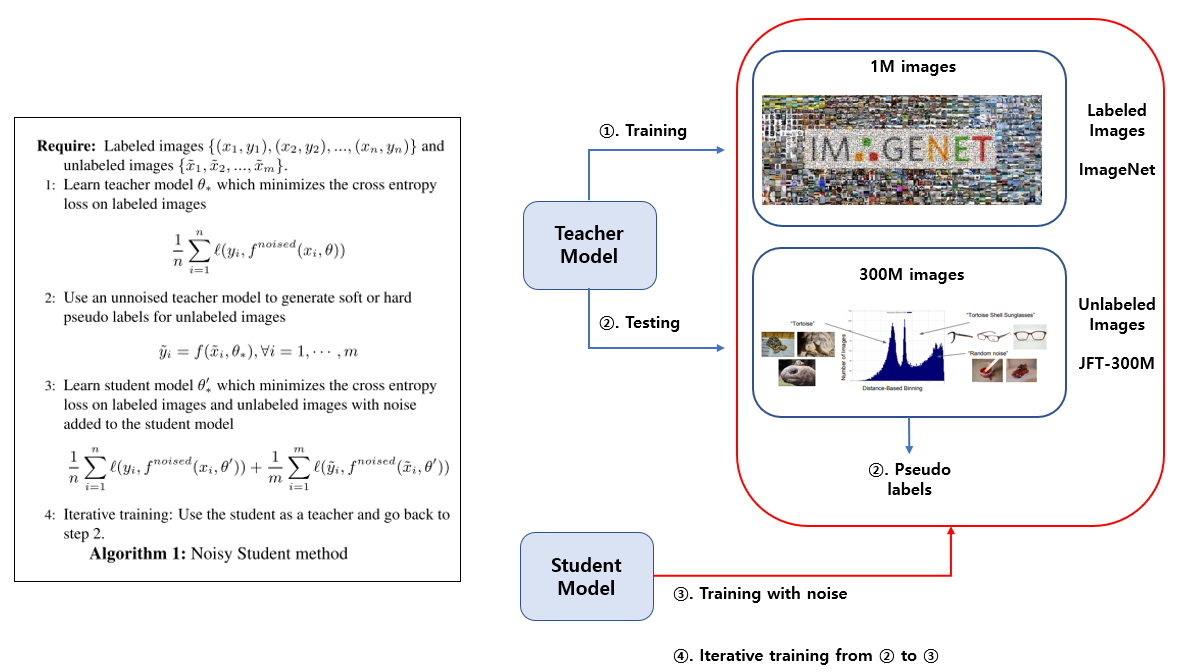
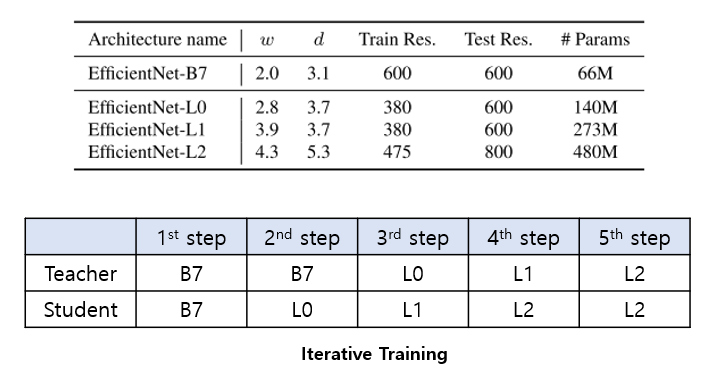
Iterative Training
반복적으로 새로운 pseudo label을 만들고, 이를 이용해 student model을 학습시키는 방법
이 과정에서 약간의 트릭이 들어감
트릭에 사용된 3가지 EfficientNet의 모델은 각각 B7, L0, L1, L2이며 뒤로 갈수록 모델의 size가 커지는것을 의미함
각 모델에 대한 세부 구조는 아래에서 확인 가능
처음엔 teacher와 student 모두 EfficientNet-B7로 학습시킴
그 뒤, teacher는 EfficientNet-B7, student는 EfficientNet-L0로 학습
다음에 teacher는 EfficientNet-L0, student는 EfficientNet-L1로 학습
다음에 teacher는 EfficientNet-L1, student는 EfficientNet-L2로 학습
마지막으로 teacher는 EfficientNet-L2, student는 EfficientNet-L2로 학습
실험결과
Appendix의 추가 결과 외에 본문에 있는 결과 위주로 설명됨
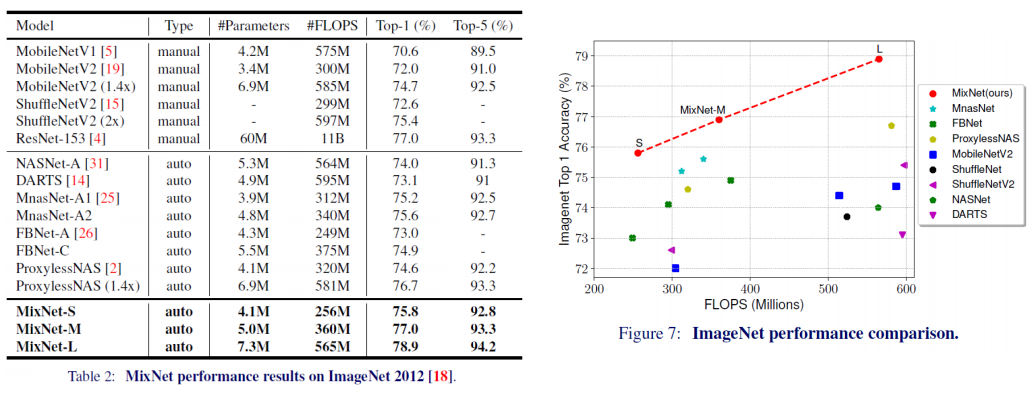
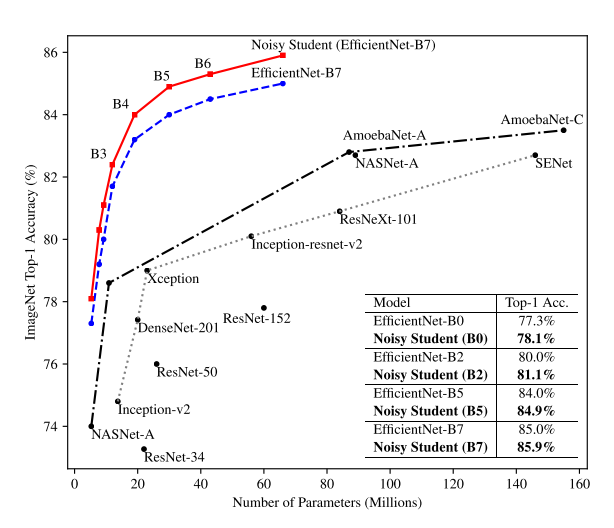
ImageNet result
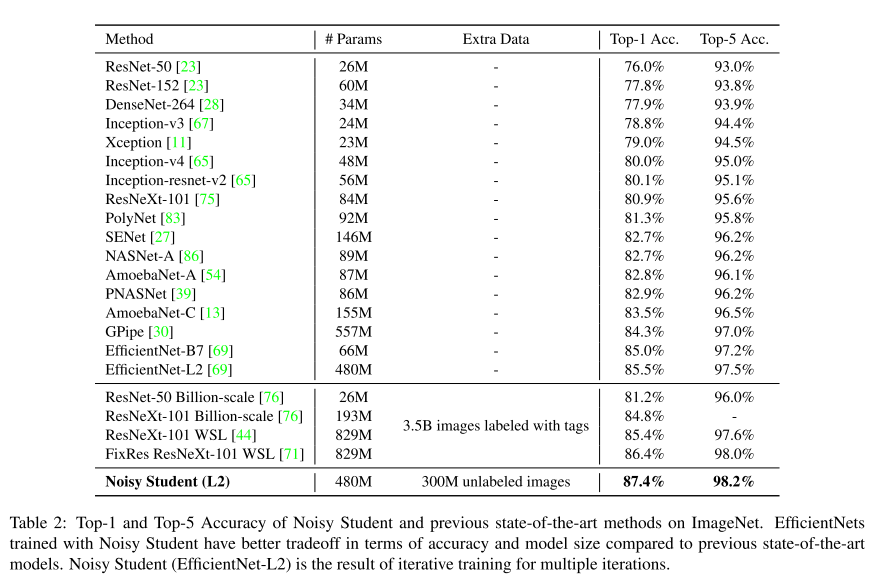
ImageNet 데이터셋에 대해 다른 선행 연구들을 모두 제치고 가장 높은 Top-1, Top-5 Accuracy를 달성
가장 좋은 성능을 보였던 Noisy Student(L2)는 기존 SOTA 성능을 달성했던 모델들보다 더 적은 파라미터수를 가지며, 학습에 사용된 Extra Data의 크기도 더 적고, Label도 사용하지 않고 달성한 결과라 더 유의미함
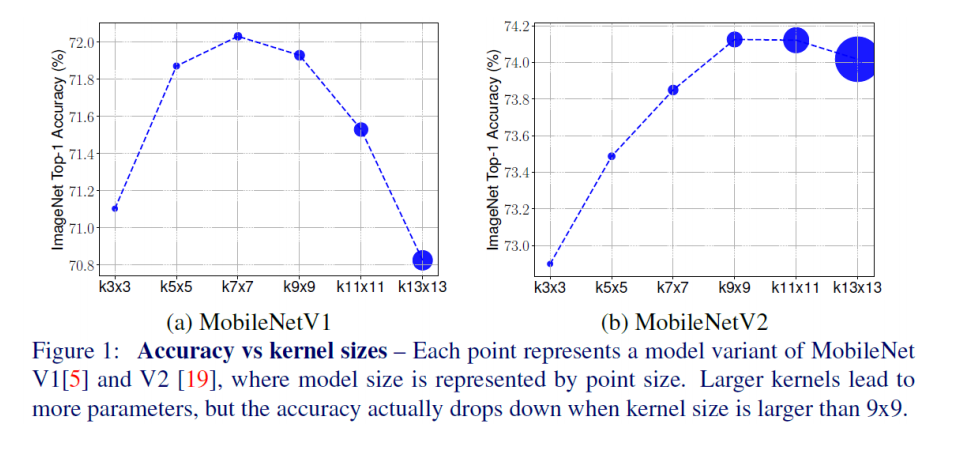
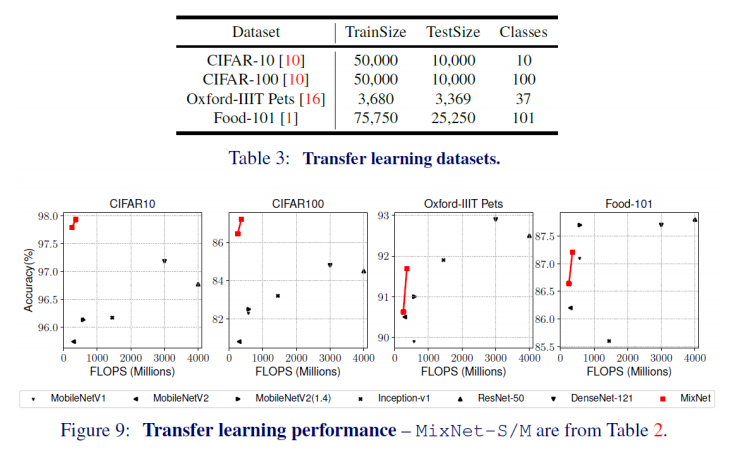
위 그림은 Iterative Training을 적용시키지 않은 결과
EfficientNet-B0부터 EfficientNet-B7까지 Noisy Student 알고리즘으로 학습 시켰을 때의 결과를 보여줌
제안하는 알고리즘들이 모든 경우에서 효과적임을 보여줌
Robustness 실험결과
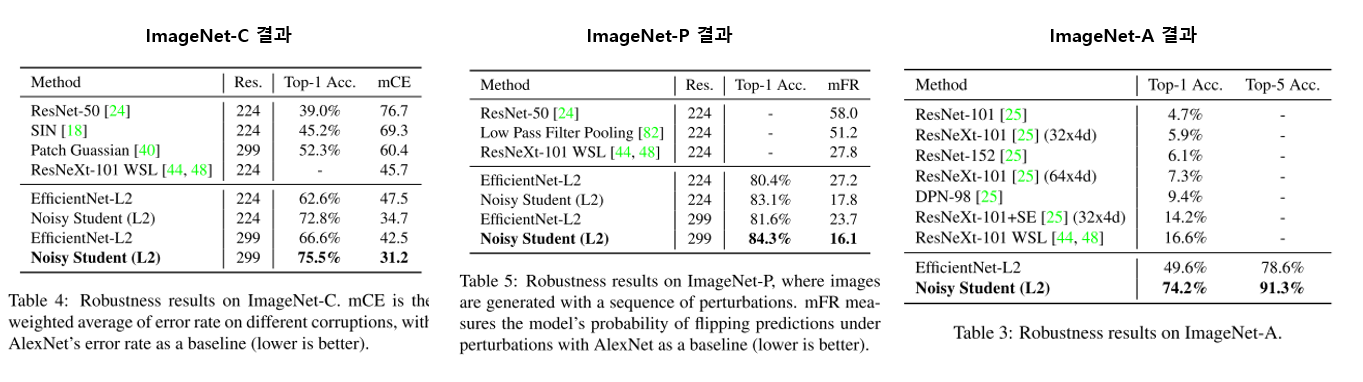
모델의 신빙성, robustness측정을 위한 test set인 ImageNet-C, ImageNet-P, ImageNet-A를 이용한 실험결과
ImageNet-C, ImageNet-P 데이터셋은 (Benchmarking Neural Network Robustness to Common Corruptions and Perturbations)[https://arxiv.org/pdf/1903.12261.pdf] 에서 제안되었으며, 영상에 blurring, fogging, rotation, scaling등 흔히 발생 가능한 왜곡등의 변화요소를 반영시켜 만든 데이터셋
ImageNet-A 데이터셋은 (Natural Adversarial Examples)[https://arxiv.org/pdf/1907.07174.pdf]에서 제안됐으며 기존 classification network들이 공통으로 분류를 어려워하는 실제 natural image들을 모아 만든 데이터셋
각 데이터셋에 대한 자세한 실험결과는 위 사진에서 확인 가능함
ImageNet-C의 평가에 사용된 mCE 지표와 ImageNet-P의 평가에 사용된 mFR 지표는 낮을수록 좋은 결과를 의미함
본 논문에서 제안하고 있는 방식이 기존 모델들 대비 좋은 성능을 보여주고 있음(mCE와 mFR 모두 가장 낮음)
ImageNet-A에 대해선 가장 높은 정확도를 보여줌
Noisy Student 방식처럼 외부의 데이터셋을 사용하는 ResNeXt-101 WSL모델은 ImageNet-A의 Top-1 accuracy가 매우 낮음(Top-1 acc 16.6%)
논문에서 제안하는 Noisy Student(L2)의 경우 굉장히 높은 정확도(Top-1 acc 74.2%)를 보임
EfficientNet-L2 역시 괜찮은 정확도(Top-1 acc 49.6%)를 보임
이는 EfficientNet 자체가 natural adversarial example에 꽤 견고한 모델임을 보여주며, 견고한 baseline architecture에 Noisy Student를 적용시킨다면 결과가 훨씬 더 좋아질 수 있음을 의미함
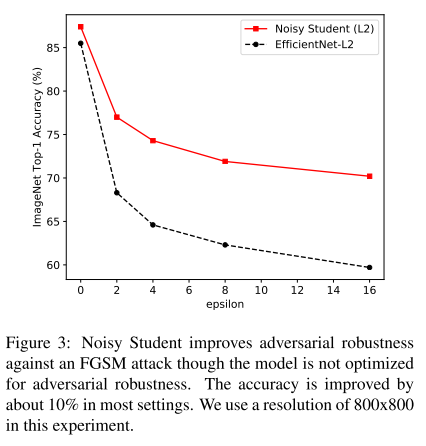
Adversarial Attack 실험결과
Adversarial attack에 얼마나 robust하게 버티는지 평가한 실험
Adversarial attack은 네트워크가 오작동하게 만드는 noise 성분으로 생각하면 됨
사람이 보기엔 adversarial attack을 당한 영상도 전과 동일하게 판단되지만, 딥러닝 네트워크는 adversarial attack받은 영상은 전혀 다른것으로 판단
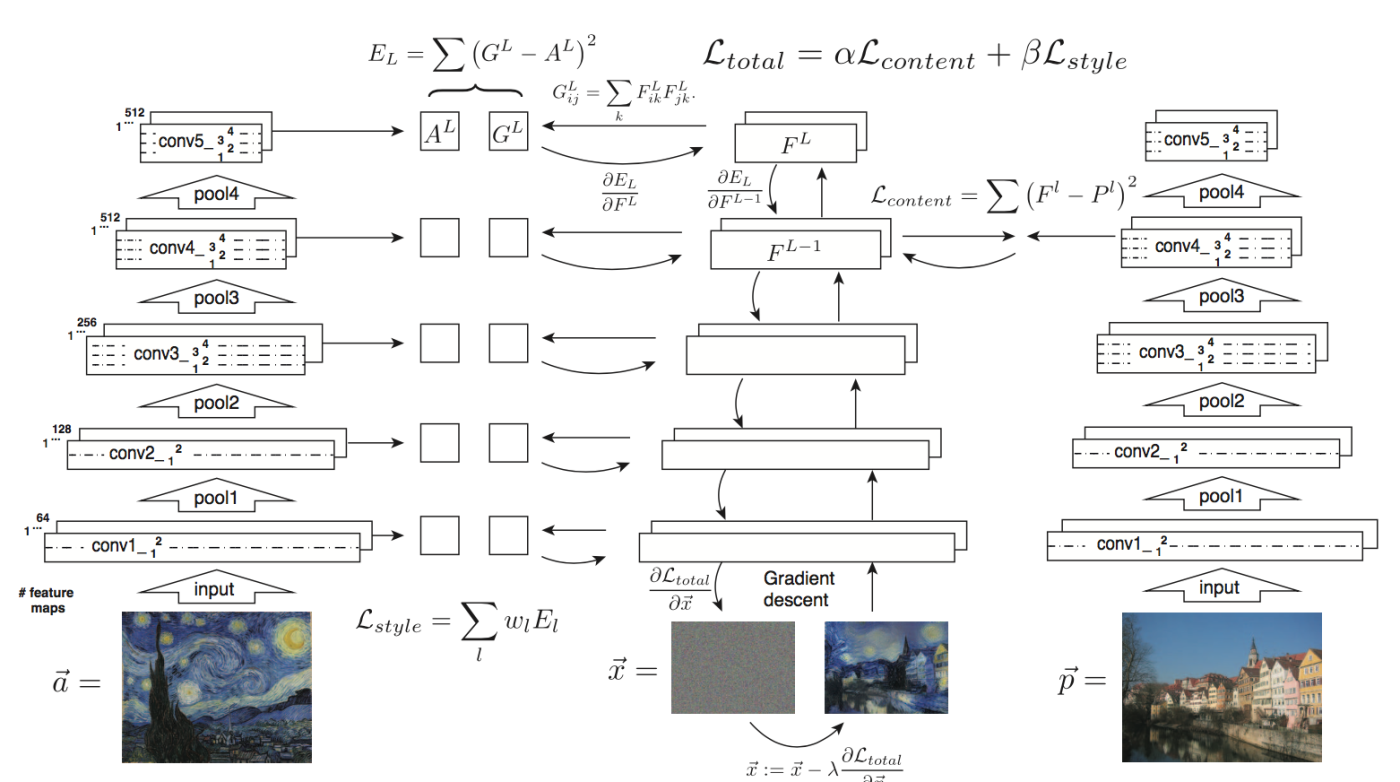
Style image a와 합성할 이미지 x 사이의 style loss는 아래와 같이 계산됨
Style image a에 대해
Style image a를 네트워크에 feed forward
Style image a에 대한 레이어 l에서의 Gram matrix A는 아래와 같이 정의됨
$A^l$, where $A_{ij}^l$ is the inner product between $F_i^l$ and $F_j^l$ in layer $l$
동일하게 합성될 영상 x에 대해
합성될 영상 x를 네트워크에 feed forward
합성될 영상 x에 대한 레이어 l에서의 Gram matrix G는 아래와 같이 정의됨
$G^l$, where $G_{ij}^l$ is the inner product between $F_i^l$ and $F_j^l$ in layer $l$
레이어 l에서의 style loss는 아래와 같이 정의됨
$E_l=\frac{1}{4N_{l}^{2}M_{l}^{2}}\sum_{i,j}(G_{ij}^{l}-A_{ij}^{l})^2$, where $N_l$ is number of feature maps at layer $l$, $M_l$ is height $\times$ width of feature maps at layer $l$
Style feature의 경우 여러 레이어를 동시에 사용하므로 total style loss는 아래와 같음
$L_{style}(\vec{a}, \vec{x})=\sum_{l=0}^{L}w_l E_l$, where $w_l$ is weighting factors of the layer to the total loss
ICCV2019에 발표된 논문으로, Yolo v3 기반의 기존 object detection모델이 갖는 문제를 개선하기 위한 연구를 수행한 논문
자율주행 환경에서 사용하기 위해선 object detection 모델이 실시간으로 동작해야 하면서도 높은 정확도를 가져야 함
이러한 관점에서 어떻게 연구를 수행했는지 설명
Indroduction
ICCV2019에 40편 이상 되는 object detetion 논문들이 accept 됨
최근 핫한 연구분야
여러 논문들이 나오면서 정확도 지표는 과거 R-CNN, OverFeat들에 비해 굉장히 높아졌음
하지만 object detection을 실생활에 적용하는 대표적인 case인 자율주행에 대해서는 실시간 동작이 필수요소
일반적으로 실시간 동작을 위해선 30FPS의 동작이 필수
논문에서는 실시간 동작이 가능한 1-stage detection model인 YOLOv3를 기반으로 연구를 수행
또한 자율주행에서는 mislocalization(False Positive, 오탐지)가 굉장히 위험한 결과를 초래할 수 있음
False Positive로 인해 차량이 갑자기 급정거를 하며 사고로 이어질 수 있기 때문
하지만 대부분의 논문들은 오로지 mAP 수치만 높히려고 하지, False Positive 자체를 줄이는 것을 목표로 하지 않음
이 논문에서는 정확도(mAP)를 높이면서 동시에 자율주행에 맞게 False Positive를 줄이는 방법을 제안
이 논문에서 주목할 점
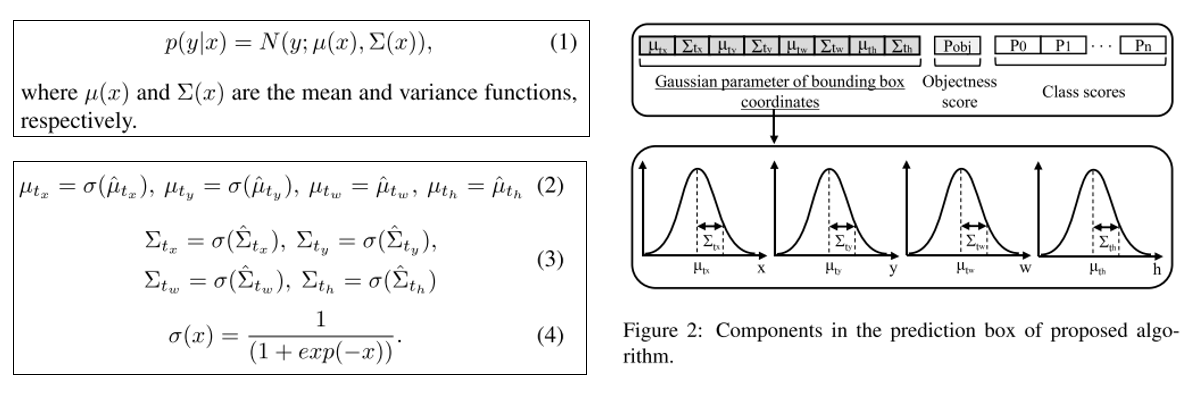
Object detection 알고리즘들의 output은 bounding box coordinate, class probability 인데, class에 대한 정보는 확률 값으로 출력되지만 bounding box coordinate들은 deterministic한 값을 출력하기 때문에 bounding box의 예측 결과에 대한 불확실성을 알 수 없음
저자는 이러한 점에 주목해서 bounding box coordinate에 Gaussian modeling을 적용하고 loss function을 재설계해 모델의 정확도를 높히고 localization uncertainty를 예측하는 방법 을 제안
Gaussian YOLOv3
Gaussian Modeling
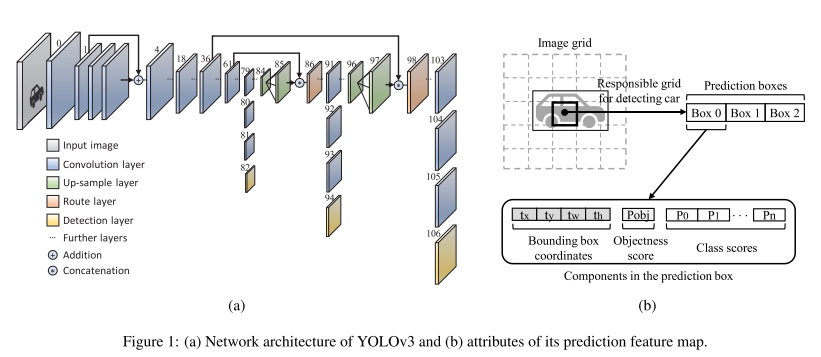
Gaussian YOLOv3의 설명에 앞서 기존의 YOLOv3에 대해 정리한 그림은 아래와 같음
Network 구조는 YOLOv3 논문등을 확인
YOLOv3의 예측 결과는 각 image grid마다 4개의 bounding box coordinate, objectness score, class score가 한 묶음이 되어 하나의 예측 box를 그리게 됨
Objectness score는 이 bounding box 안에 object가 존재하는지를 나타내는 확률값
Class score는 존재하는 object가 모든 class별로 해당 class일 확률을 나타내는 값
Bounding box coordinate를 구성하는 t parameter들은 예측된 box의 중심 좌표, size를 나타내는 값이며 하나의 정해진 값을 나타냄
Objectness score, class score는 확률 값 이며 thresholding등을 통해 낮은 확률을 갖는 값들을 걸러낼 수 있음
Bounding box coordinate 는 확률 값이 아니기때문에 예측된 box의 좌표들이 얼마나 정확한지, 아닌지를 알 수 없음
이를 해결하기 위해 bounding box coordinate를 구성하는 4개의 t parameter들에 Gaussian Modeling을 적용한 모델이 Gaussian YOLOv3
Gaussian Modeling for YOLOv3
주어진 test input x에 대한 output y의 Single Gaussian Model은 위 그림의 (1)과 같이 나타 낼 수 있음
YOLOv3의 구조에 맞게 이를 적용한 방식은 (2)~(4)
각 coordinate의 mean값은 예측된 bounding box 좌표를 의미
Variance 값은 uncertainty를 의미
즉, variance가 작으면 확실한 bounding box라고 예측한 경우고, variance가 크다면 예측된 bounding box가 불확실한 것을 의미
Gaussian Modeling은 기존 YOLOv3의 detection layer만 수정하면 되고, 연산량 자체도 미미하게 증가하기 때문에 처리 속도가 거의 유지되면서도 정확도만 더 향상시킬 수 있음
512x512 input 기준 YOLOv3: $99\times10^9$ FLOPS, Gaussian YOLOv3: $99.04\times10^9 FLOPS$
Reconstruction of loss function
기존 YOLOv3은 bounding box regression에 sum of the squared error loss function을 사용
Gaussian YOLOv3은 bounding box coordinate에 Gaussian Modeling을 적용해 Gaussian parameter로 변환했기 때문에 이에 맞게 loss function을 재설계 해야 함
Loss function of Gaussian YOLOv3
논문에서는 negative log likelihood(NLL) loss를 이용했으며, 이는 위 그림의 (5)에서 확인 가능
GT의 bounding box는 위 그림의 (6)~(9)를 통해 계산되며 각 식의 notation은 논문 참조
기존 YOLOv3의 sum of the squared error loss는 학습 과정에서 noisy한 bounding box에 대한 패널티를 줄 수 없음
새로 구성한 loss function의 경우 noisy bounding box에 대한 uncertainty를 반영하게 되면서 패널티 부여 가능해짐
즉, 데이터셋이 noisy하더라도 uncertainty를 이용하기 때문에 믿을 수 있는 데이터에 집중하는 효과를 얻을 수 있음
또한 전반적인 정확도 향상도 얻을 수 있음
Utilization of localization uncertainty
Detection criterion에 localization uncertainty를 적용
예측한 bounding box안에 어떤 물체가 있는지 계산할 때 objectness score와 class score를 곱해서 사용하는데, 여기에 $(1-Uncertainty_{avg})$를 곱해줌
이를 통해 False Positive를 줄이고, 전반적인 정확도를 향상 시킬 수 있음
Uncertainty는 각 coordinate의 uncertainty를 평균내서 사용
실험결과
실험 데이터셋과 실험환경
논문에서는 자율주행 환경에 적합한 KITTI 데이터셋과 BDD 데이터셋을 이용
KITTI 데이터셋(좌측), BDD 데이터셋(우측) 예시
KITTI 데이터셋은 car, cyclist, pedestrian 3가지 class로만 구성되어있고, 7,481 장의 학습 셋과 7,518장의 테스트 셋으로 구성됨
테스트 셋은 GT가 존재하지 않기때문에 학습 셋의 절만을 검증용 셋으로 사용함
BDD 데이터셋은 bike, bus, car, motorcycle, person, rider, traffic light, traffic sing, train, truck의 총 10가지 class로 구성
학습, 검증, 테스트 셋이 각각 7:1:2로 나뉘어있음
각 데이터셋마다 주로 사용되는 IoU thresholdㄱ밧은 선행 연구들과 동일한 값을 사용했으며, 학습에 사용한 hyper parameter, 실험환경 등은 논문 참조
실험결과
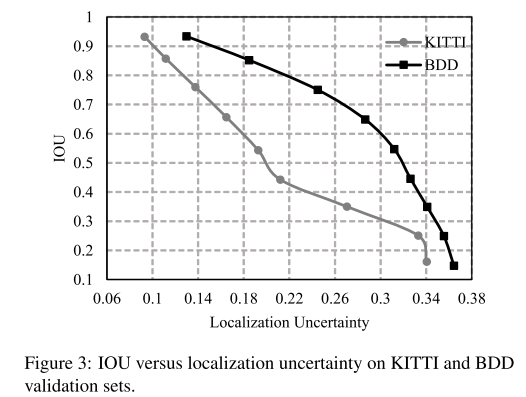
IoU vs Localization uncertainty on KITJTI and BDD validation sets
위는 KITTI, BDD validation dataset중 car class에 대해 예측된 bounding box들의 IoU에 따른 localization uncertainty를 그래프로 나타낸 결과
IoU가 높을수록 localization uncertainty는 낮으며, 두 값이 반비례하는 경향을 보임
이를 통해 제안하는 localization uncertainty가 실제로 예측된 bounding box의 confidence를 잘 나타내고 있음을 확인 가능
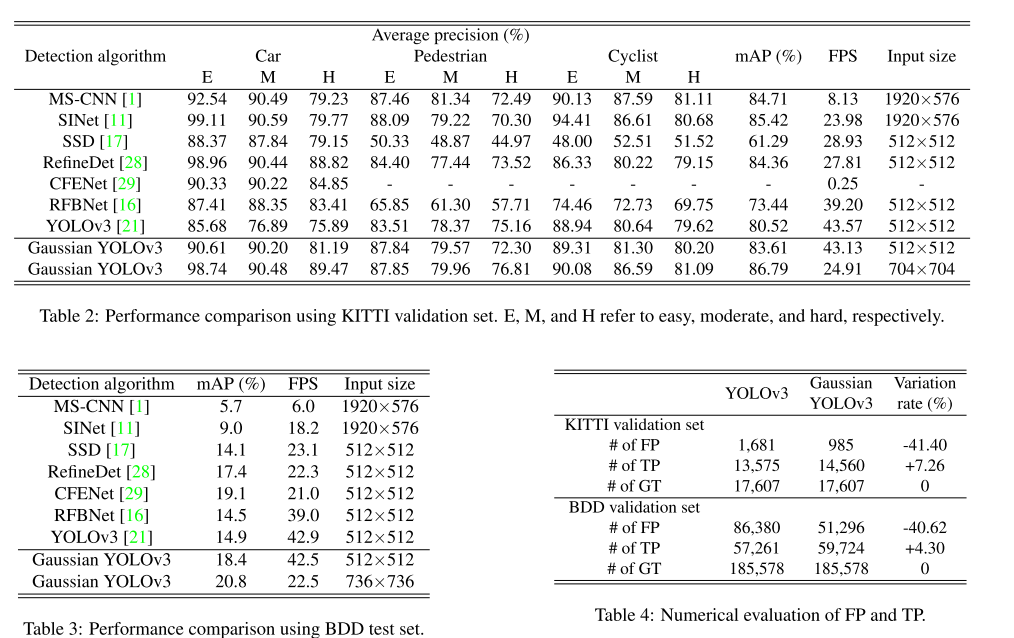
Gaussian YOLOv3 성능 비교
기존 방법들과 성능을 비교할 때 더 좋은 mAP 점수를 보이며, 특히 baseline인 YOLOv3에 비해 1FPS가량의 미묘한 속도감소만으로 정확도를 크게 높일 수 있었음
Table4를 보면 YOLOv3 대비 True Positive도 늘었고 False Positive가 약 40%이상 감소된 것을 확인 가능
즉, Bounding box coordinate에 uncertainty를 부여함으로써 False Positive를 줄이겠다는 논문의 목적이 잘 달성된 것을 확인 가능
다만, bounding box coordinate에 uncertainty를 부여하면서 얻을 수 있는 효과중 하나인 noisy data에 robust해진다는 점을 실험적으로도 그런 경향을 확인할 수 없음
이를 입증해기 위해선 noisy label을 담고 있는 object detection용 public dataset이 필요하기 때문에 본 논문에서는 실험 불가능하지만, 추후 이러한 데이터셋이 나온다면 적용해서 실험 결과를 살펴 볼 수 있음
결론
자율주행을 타겟으로 실시간 동작하면서 동시에 자율주행에 치명적인 False Positive를 효과적으로 줄이는 방법을 제안

 Seongkyun Han's blog
Seongkyun Han's blog