Object detection에서는 모델의 성능(정확도)을 주로 Mean average precision(mAP)를 통해 확인한다. mAP가 높을수록 정확하고, 작을수록 부정확하다.
그런데 보통 모델의 mAP의 측정 해당 데이터셋별(PASCAL VOC, MS COCO 등등..)로 잘 짜여진 코드가 많이 있어서 알고리즘적으로 어떻게 계산되는지 자세히는 알지 못했다.
이번 글에서는 mAP에 대해 보다 자세히 알아보기 위한 공부를 한 내용을 정리했다.
기본적으로 mAP는 다른 recall 값에서의 평균 최대 precision으로 정의
Precision, recall and IoU
Precision
Precision은 모델의 출력이 얼마나 정확한지를 측정하는 것.
즉, 모델이 예측한 결과의 Positive 결과가 얼마나 정확한지를 나타내는 값.
Recall
Recall은 모델의 출력이 얼마나 Positive 값들을 잘 찾는지를 측정하는 것.
Precision과 Recall의 수학적 정의
예를 들어, 암 진단의 경우에 대해 Precision과 Recall은 다음과 같이 정의 됨.
$TP$: 실제 암 세포들의 개수
$total \; positive \; results$: 암세포라고 판단 된 결과
$total \; cancer \; cases$: 전체 암 세포들의 개수
Object detection의 관점에서 보자면, recall과 precision의 관계는 아래와 같이 정의 가능
IoU (Intersection over union)
2개 영역 사이의 중첩되는 정도를 측정.
이는 Object detector가 실제 Ground truth와 예측 결과(Prediction)가 얼마나 정확히 겹치는지를 계산하여 예측이 얼마나 잘 되는지를 측정.
IoU의 정의
Average precision (AP)
AP를 계산하는 간단한 예제를 살펴보자.
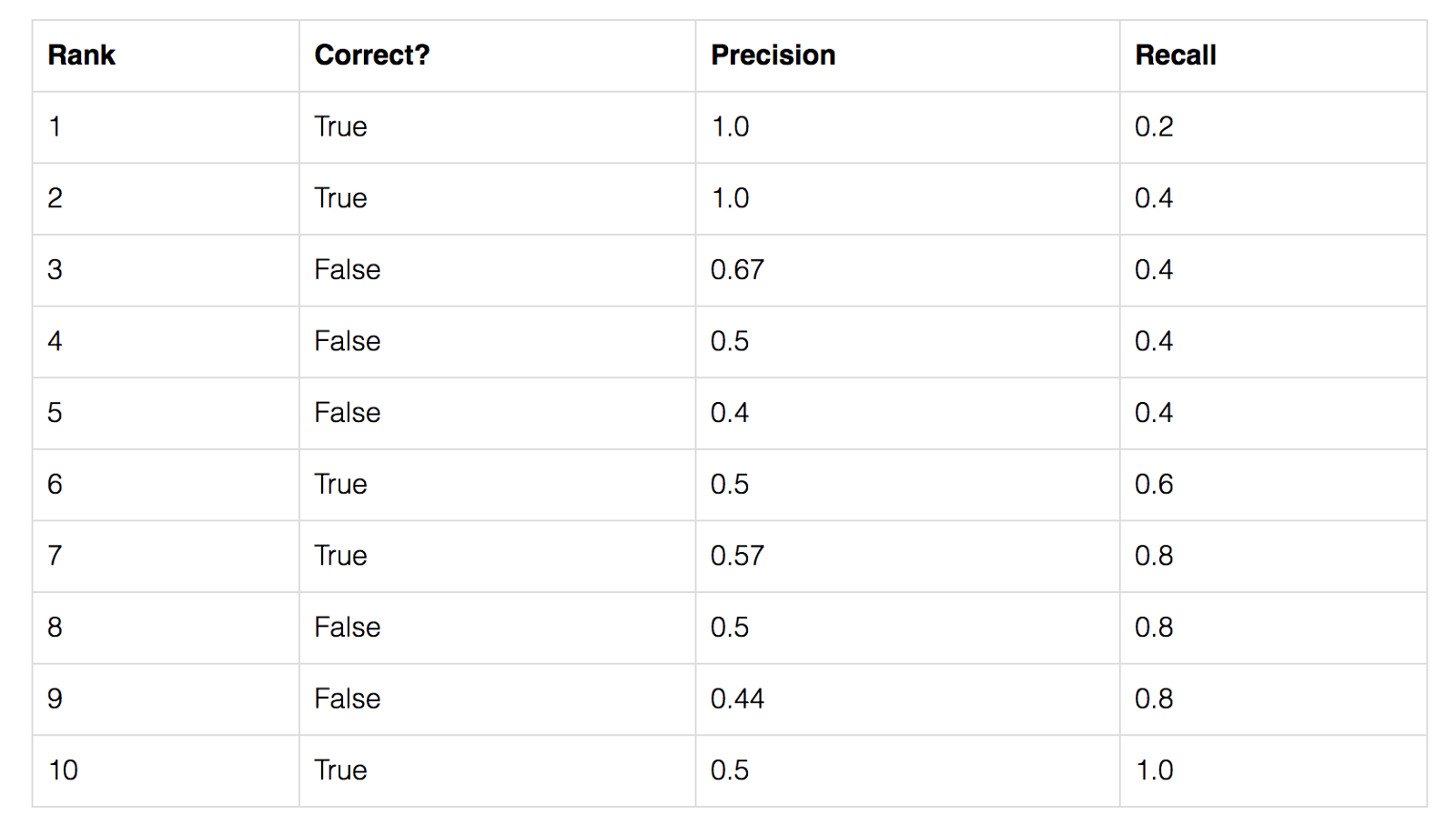
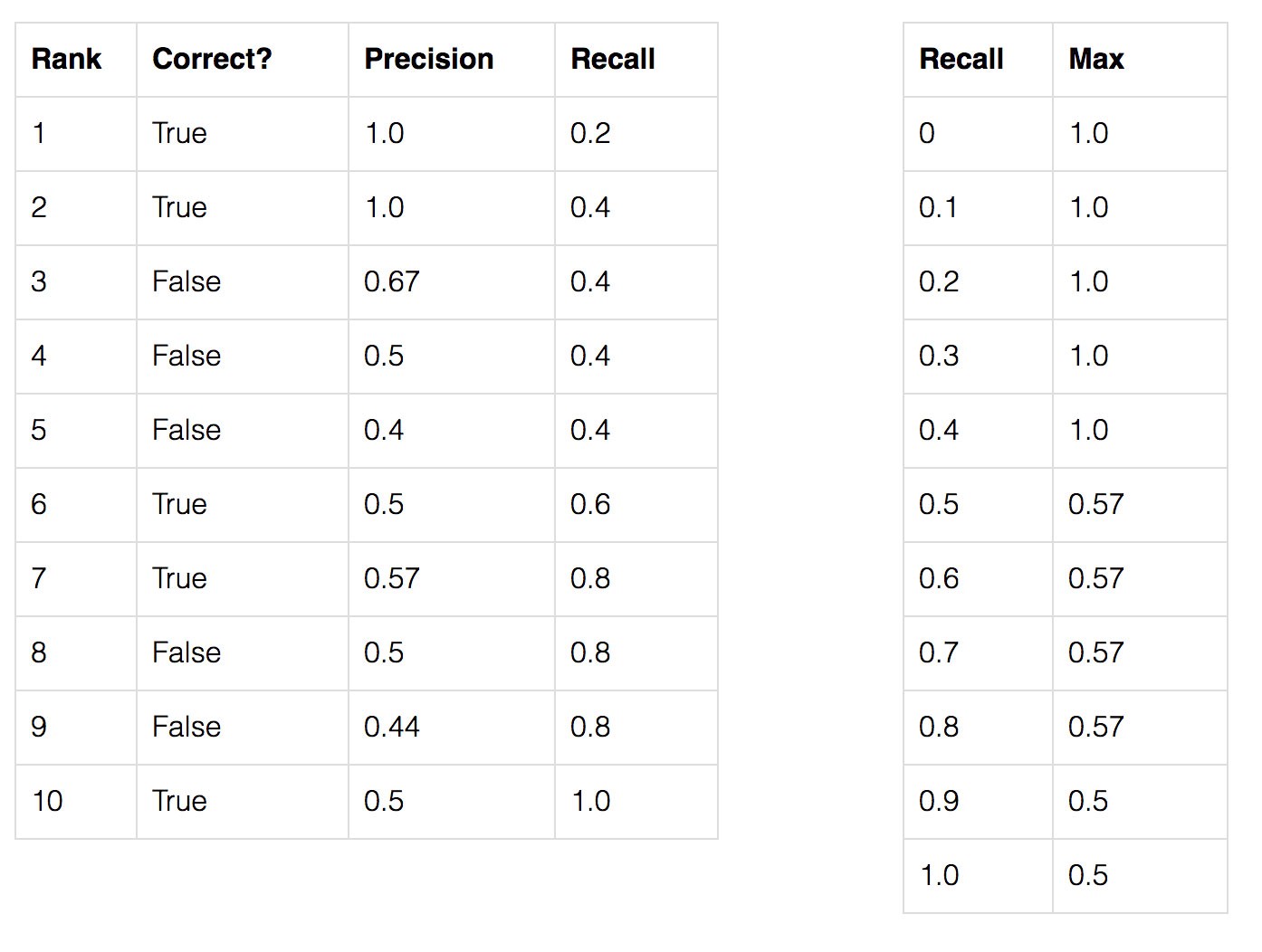
데이터셋에는 총 5개의 사과가 있음
모델이 사과에 대해 예측한 모든 결과를 수집하고 예측 신뢰 수준(predicted confidence level)에 따라 순위를 지정하여 나열
두 번째 열은 예측 결과가 올바른지 여부를 나타냄
예측이 정확하다고 판단(Correct=True)하는 기준은 Ground Truth(GT)와의 IoU가 50%가 넘는 경우($IoU\geq 0.5$)
위의 표에서 3번 Rank의 결과에 대한 Precision 및 Recall 값을 계산 해 보자.
Precision은 TP의 proportion으로 $\frac{2}{3}=0.67$ 이 된다.
Recall은 possible positives 외의 TP의 비율이므로 $\frac{2}{5}=0.4$가 된다.
Recall 값은 더 많은 모델의 예측값들(predictions)을 포함시킬수록 더 좋아지지만, precision은 이로 인해 증/감하게 됨.
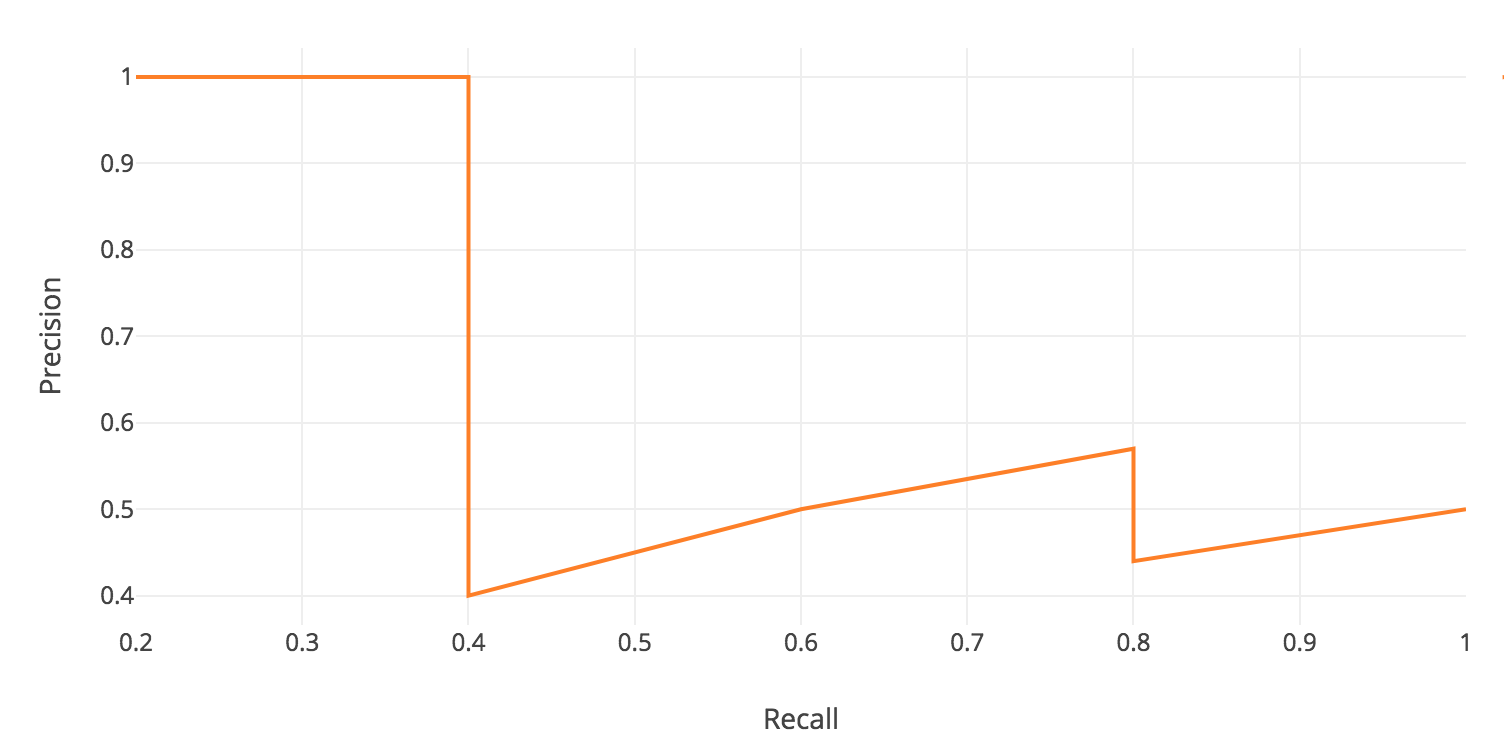
아래에서 recall 값에 따른 precision의 변화 관계를 볼 수 있음.
Precision-recall graph
AP의 idea는 precision-recall 그래프(오랜지색 선) 아래 영역을 찾는 것으로 개념적으로 볼 수 있음.
위의 그래프는 recall인 $\hat{r}$ 값이 0, 0.1, 0.2, …, 0.9, 1.0 일때의 값에 대한 plot이며, precision 값은 $recall \geq \hat{r}$ 일때의 최대 precision 값으로 대체 된 것.
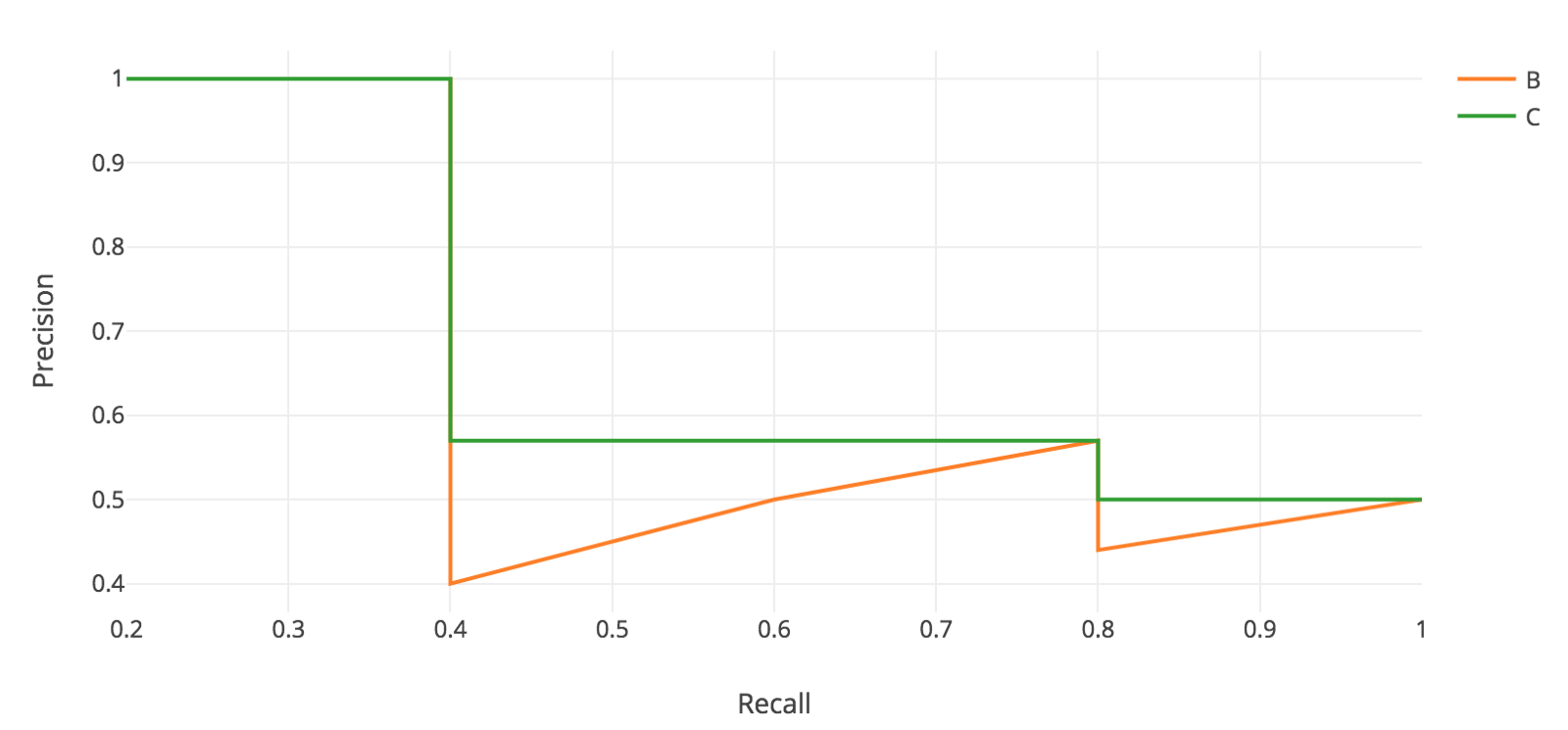
다음으로, Recall 값의 오른쪽에서 가장 큰 값들을 찾아 그 값끼리 이은 최대 precision 값을(초록색 선) 찾음.
Precision-recall graph
AP(average precision)는 아래의 11개의 recall 값들에 의해 최대 precision 값의 평균을 취함으로써 계산 할 수 있음.
Recall 값이 0에서 1까지 0.1 단위로 커지면서
위 수식의 계산은 precision-recall 그래프에서 녹색 곡선 아래의 총 면적을 구하는 것과 유사하며, 그 값을 11로 나눈 값.
보다 정확한 정의는 아래와 같음
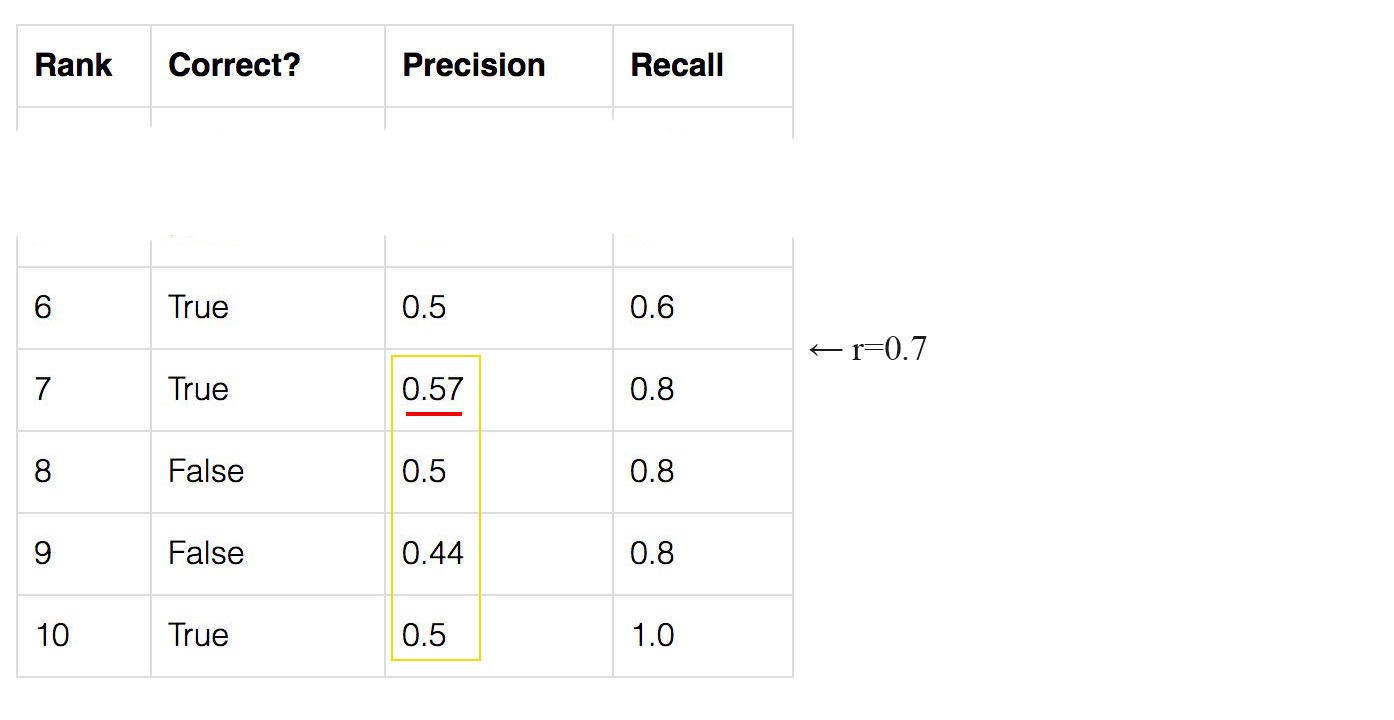
$p_{interp}(0.7)$ 은 아래의 노란색 상자에서 최대값을 갖게 됨.
recall 값이 0.7일때 갖을 수 있는 precision의 최대 값일 때의 recall 값은 0.8이 됨.
그래서 그래프에서 최대 precision일 때의 recall 값이 0.8임
본 예시에서, $AP=(5\times 1.0 + 4\times 0.57+2\times 0.5)/11$ 로 계산 됨.
Recall이 0 ~ 0.4 일 때 최대 precision은 1.0
Recall이 0.5 ~ 0.8 일 때 최대 precision은 0.57
Recall이 0.9, 1.0 일 때 최대 precision은 0.5
mAP(mean average precision)는 모든 클래스에 대해 각각 위의 연산을 반복하고, 그 값들의 평균을 의미.
다양한 데이터셋에 대해 종종 AP라고 불림.
PASCAL VOC Challenge에서의 AP(Average Precision)
PASCAL VOC는 object detection에서 널리 사용되는 데이터 셋
PACAL VOC Challenge의 경우, 모델의 예측과 ground truth의 IoU가 0.5보다 크면($IoU>0.5$) 모델의 예측이 올바르게 되었다고 판단
그러나 모델이 동일한 객체에 대한 중복 탐지결과를 출력 할 경우 첫 번째 출력을 positive로, 나머지를 negative로 계산.
PASCAL VOC의 mAP는 위의 AP 계산 방법과 동일
MS COCO mAP
SOTA(State of art) object detector 모델들은 주로 MS COCO에 대한 mAP 결과만을 제공하는 경향이 있음
MS COCO는 PASCAL VOC의 단일 IoU값 계산과는 다르게($IoU>0.5$) 다중 IoU에 대한 평균값을 계산
Minimum IoU는 positive match를 위해 고려됨
AP@[.5:.95]는 0.05의 단계 크기로 0.5부터 0.95까지의 IoU에 대한 평균 AP에 해당함
MS COCO competition의 경우 AP는 80개의 카테고리에서 10개 이상의 IoU에 대한 평균값으로 경쟁.
AP@[.50:.05:.95]: 0.5에서 0.95까지 단계 크기 0.05씩 커지며 계산
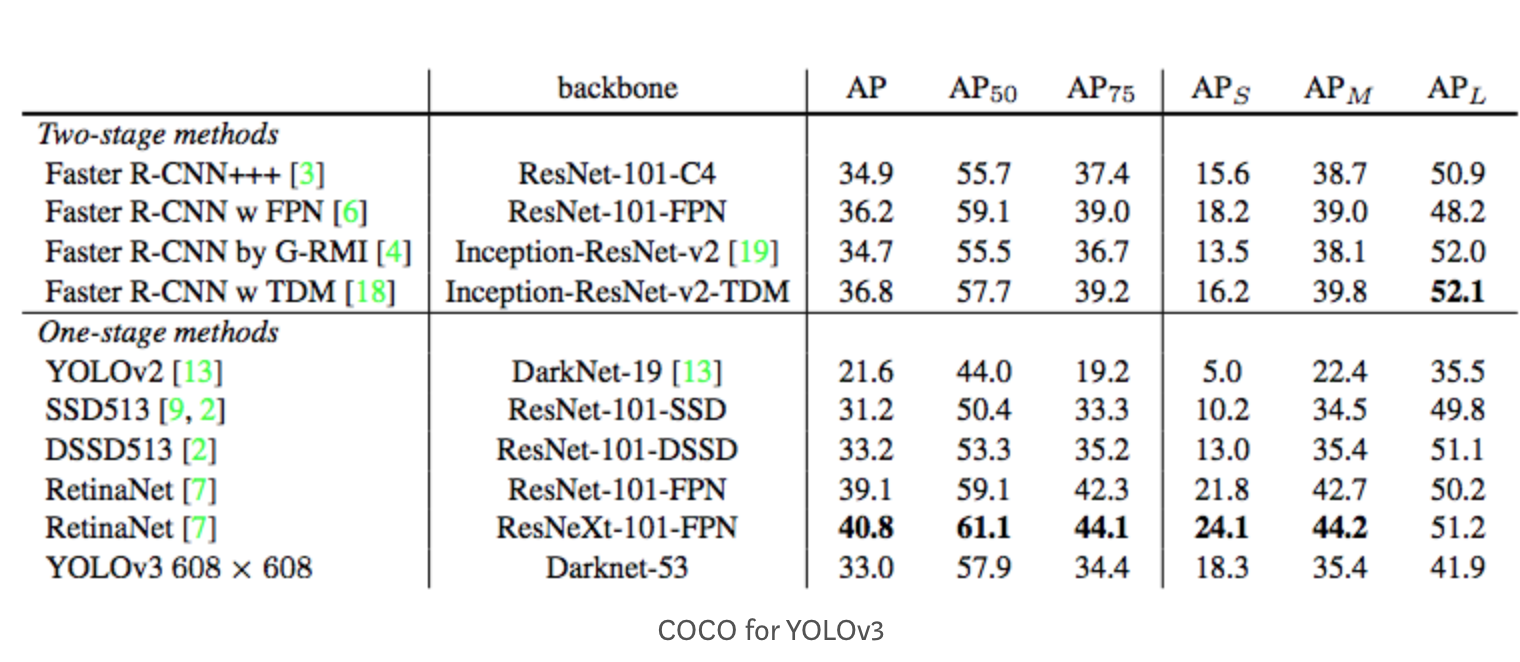
다음은 YOLO V3 object detector의 MS COCO 에 대한 mAP 실험 결과임
위의 실험 결과에서 mAP@.75는 IoU=0.75 기준일 때 계산 된 mAP 값을 의미함.
deffind_group(n):# 입력된 숫자가 몇 번째 그룹에 속해있는지를 찾는다.
cnt=0ifn==1:return1else:forjinrange(1,n+1):cnt+=1n-=jifn==-cnt:returncnt-1elifn<0:returncntnum=int(input())group=find_group(num)odd=group%2# 홀/짝별로 숫자배열이 달라지므로 다른 연산이 필요하다.
nums=[]# 해당 그룹의 숫자들을 저장한다.
ifodd==1:temp=groupforjinrange(1,group+1):string=str(temp)+'/'+str(j)nums.append(string)temp-=1else:temp=groupforjinrange(1,group+1):string=str(j)+'/'+str(temp)nums.append(string)temp-=1init_num=int((group-1)*group/2+1)# 앞에서 정의된 일반항으로 해당 그룹의 첫 번째 순번이 몇 번으로 시작하는지를 찾는다.
plus=num-init_num# 완성 된 분수 그룹에 몇 번째 숫자인지를 정의한다.
print(nums[plus])

 Seongkyun Han's blog
Seongkyun Han's blog