N개의 단어에 존재하는 모든 문자에 대해서, 각 문자가 연속해서 나타나는 경우만을 찾는 프로그램을 제작
예시
ccazzzzbb는 c, a, z, b가 모두 연속해서 나타나므로 그룹 단어
kin kin도 k, i, n이 연속해서 나타나므로 그룹 단어
aabbbccb는 b가 떨어져서 나타나기 때문에 그룹 단어가 아님
string.find(chr)는 chr문자를 string의 왼쪽에서부터 찾은 후, index를 반환한다.
string.rfind(chr)는 chr문자를 string의 오른쪽에서부터 찾은 후, index를 반환한.
정답
deffind_group(l):temp=[]s=''result=[]forjinrange(len(l)):# 입력 된 list를 string형태로 변환
s+=l[j]forjinrange(len(s)):# 변환 된 string에 왼쪽부터 loop를 돌며
l=s.find(s[j])# l: 해당 문자(string의 j번째 문자)가 가장 왼쪽에서 나오는 순번
r=s.rfind(s[j])# r: 해당 문자(string의 j번째 문자)가 가장 오른쪽에서 나오는 순번
temp=[]# temp 변수 초기화
foriinrange(l,r+1):# string에서 l부터 r 사이에
temp.append(s[i])# 존재하는 문자들을 temp에 이어 붙인 후
iftemp.count(s[l])==len(temp):# 만약 l과 r 사이에 s[l](최 좌측 문자)과 동일한 문자만 들어있다면
result.append(True)# 그룹 문자이므로 True
else:# 그렇지 않다면
result.append(False)# 그룹 문자가 아니므로 False
# for loop을 돌면서 문자별로 전체 단어에 대해서 수행
ifFalseinresult:# 만약 하나의 False만 존재하더라도 그룹 문자가 아니므로 counting되면 안됨
return0else:# False가 하나도 없다면 그룹 문자이므로 counting 되도록 1 return
return1n=int(input())cnt=0forjinrange(n):a=list(str(input()))iflen(set(a))==len(a):# 입력된 단어가 모두 다른 문자로 구성된 경우
cnt+=1# 그룹 단어
else:# 그렇지 못한 경우
cnt+=find_group(a)# 그룹 단어인지 판별 후 그룹 단어로 카운팅
print(cnt)
[2908] 상수
문제
두 수를 입력받고, 입력 받은 두 수를 각각 거꾸로 읽은 후 대소를 비교하여 큰 수를 출력
예시
734과 893을 입력 받았을 때, 수를 437과 398로 거꾸로 인식한 후 대소를 비교하여 두 수중 큰 수인 437을 출력한다.
a=input()# string 형식으로 입력을 받고
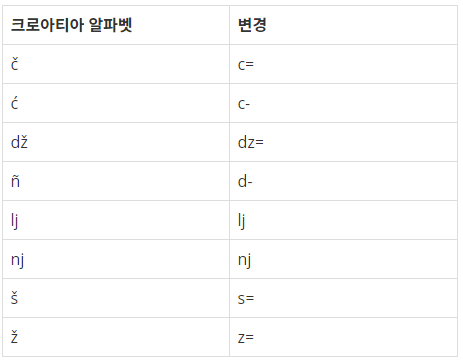
dics=["c=","c-","dz=","d-","lj","nj","s=","z="]# 크로아티아 문자가 저장된 dictionary 안에서
forkeyindics:# 각 key 값에 대해(c= 부터 차례대로 z=까지)
a=a.replace(key,"_")# key값과 동일한 문자를 _로 대체
print(len(a))# 결과 출
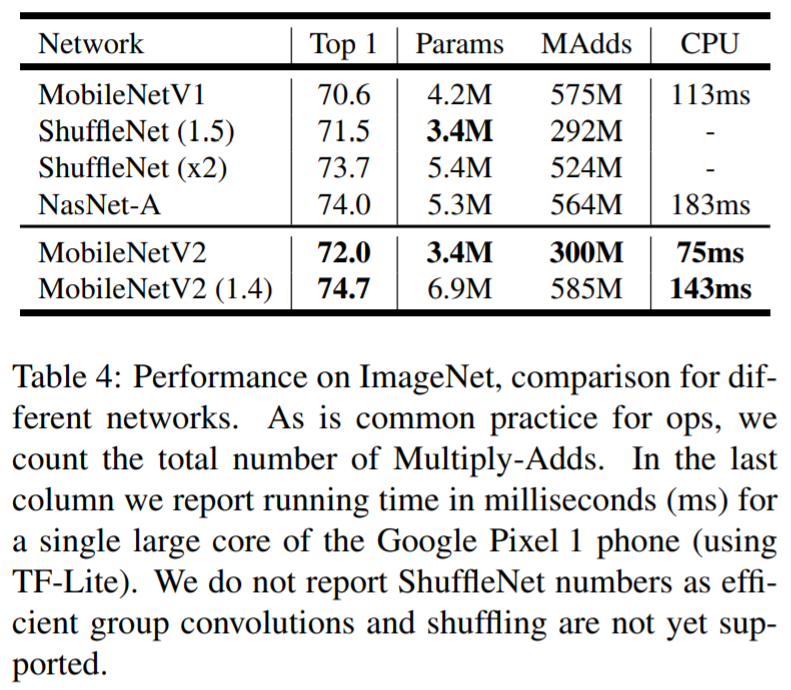
MobileNet V2와 ShuffleNet간의 연산량을 비교할 때, MobileNet V2의 연산량이 더 적음을 알 수 있음
정리
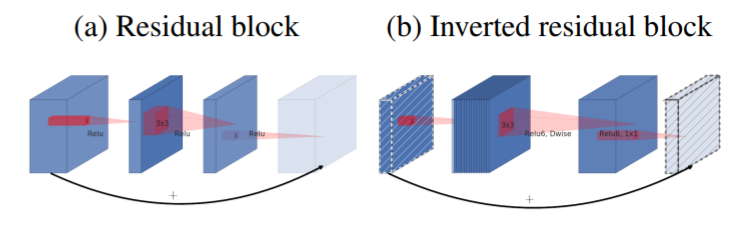
Real Image를 input으로 받았을 때 네트워크의 어떤 레이어들을 Manifold of interest라고 한다면, input manifold를 충분히 담지 못하는 space에서 ReLU를 수행하면 정보의 손실이 발생한다.
하지만 차원수가 충분히 큰 space에서 ReLU를 사용하면 정보가 손실될 가능성이 크게 줄어든다.
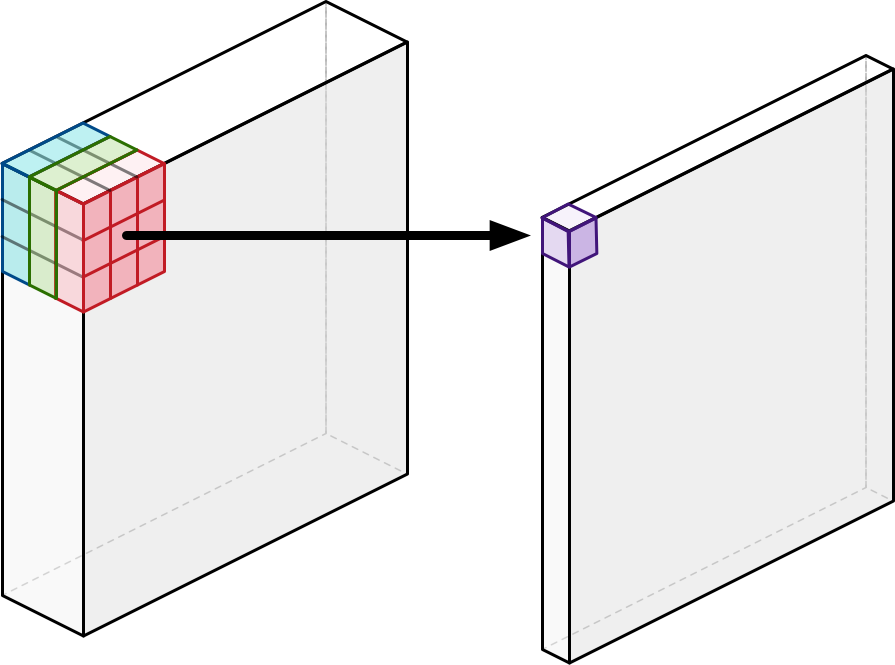
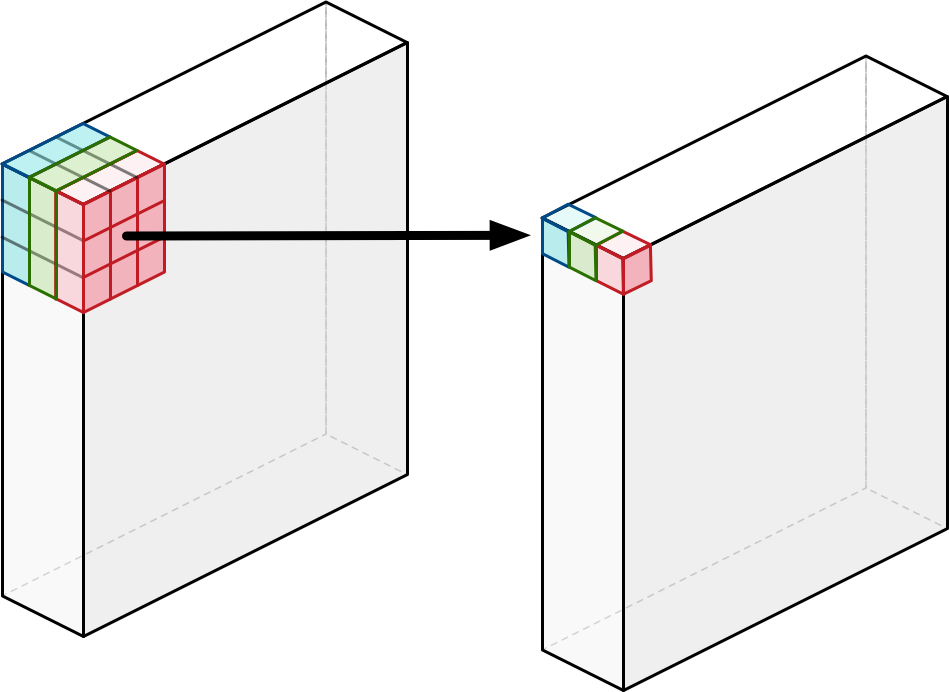
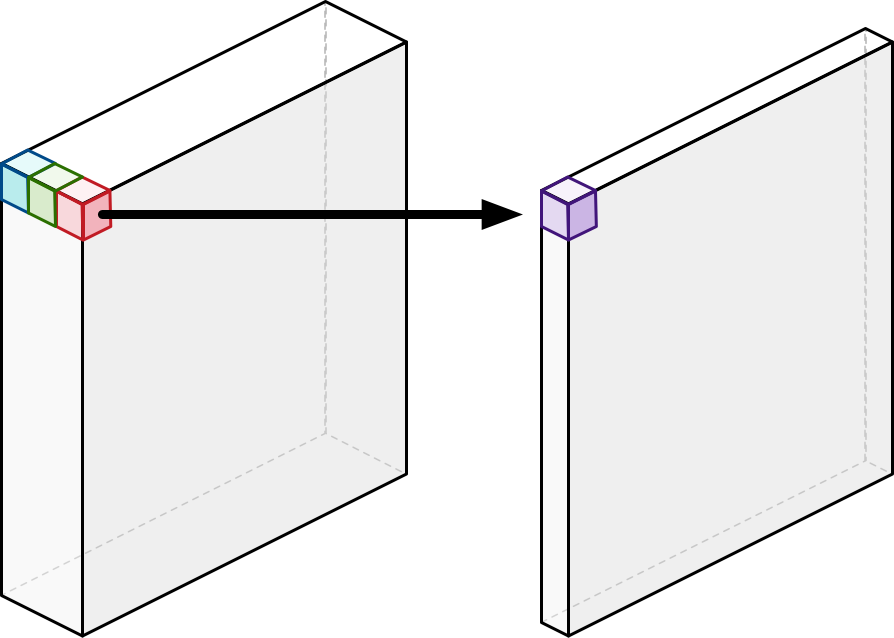
저차원 데이터에 conv 층을 적용하면 많은 정보를 추출 할 수 없다.
따라서 더 많은 데이터를 추출하기 위해 저차원의 압축된 데이터를 압축을 먼저 풀거(차원 확장) conv 층을 적용시킨 다음 projection층을 통해 데이터를 다시 압축시키는 과정을 거친다.
위의 일련이 과정이 바로 Inverted Residual Block이 하는 일이다.
마지막 ReLU 함수를 지나기 전에 Channel expansion을 해서 input manifold를 충분히 큰 space에 담아 놓고, ReLU를 적용시킴으로써 정보 손실을 최소화한다. 여기서 더 나아가서 Linear Bottleneck을 마지막에 두지 말고 앞으로 가져와 Expansion -> Projection 구조 + Shortcut connection을 사용한다.
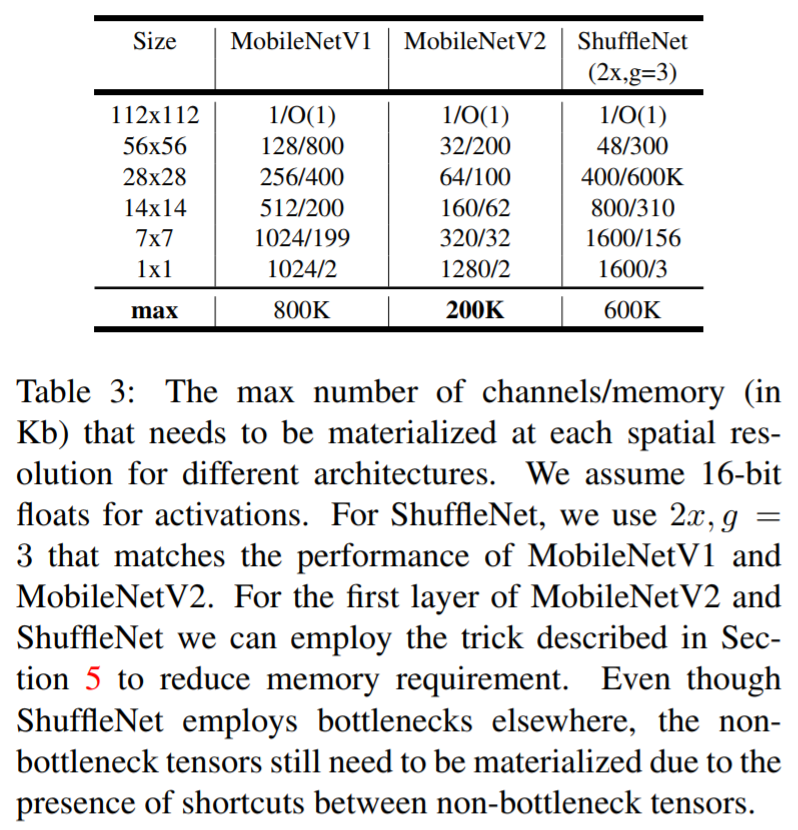
Memory efficiency inference
Inverted Residual block의 bottleneck layer은 memory를 효율적으로 사용 할 수 있게 해줌
Memory의 효율적 사용 문제는 Mobile application에서 매우 중요함
Experiment
Parameter의 수, 연산량이 증가하나 정확도가 크게 개선되는 것을 확인 할 수 있음
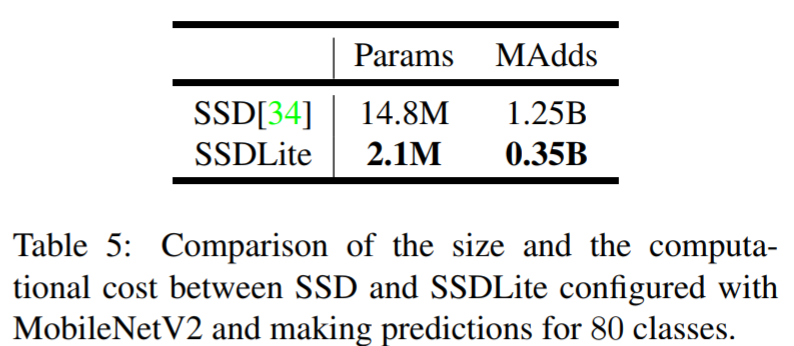
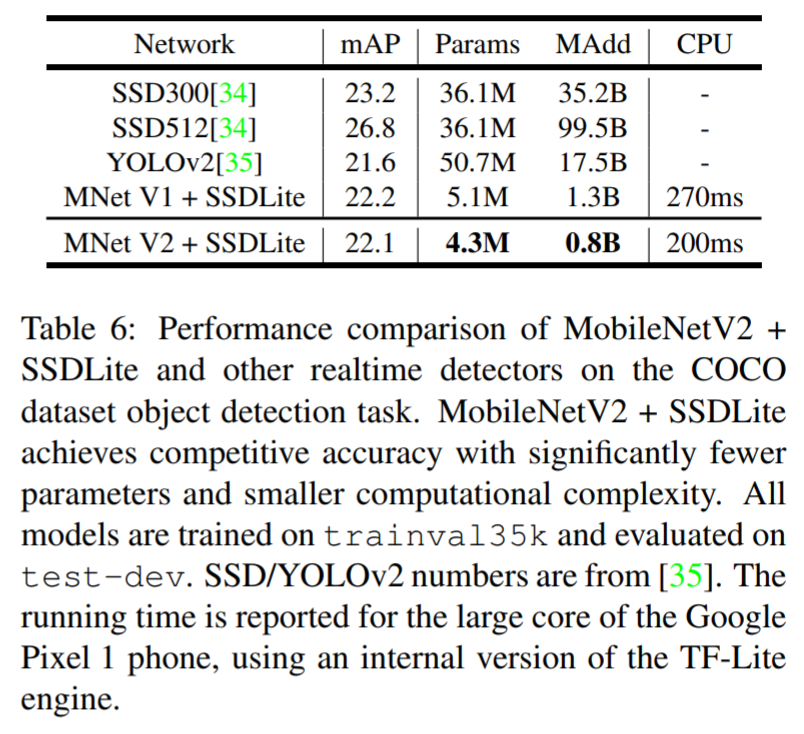
SSD Lite는 SSD의 prediction layer를 depthwise separable convolution으로 바꿔 파라미터의 수/연산량을 획기적으로 줄인 구조
Model size가 작아짐
정확도 측면에서 기존 방법에 비해 competitive한 결과를 보이나, 파라미터의 수/연산량 비교시 훨씬 효율적인 모델임을 알 수 있음
Conclusion
Linear bottleneck, Inverted residual block을 이용해 MobileNet V1을 개선함.
SSD Lite의 경우, YOLO V2보다 연산량, 파라미터의 수를 획기적으로 줄임.
매우 효율적인 구조
논문에서 제안한 convolution block을 exploring 하는것이 향후 연구의 중요한 방향이 될 것임.
[참고 글]
Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018.

 Seongkyun Han's blog
Seongkyun Han's blog