Seongkyun Han's blog
Seongkyun Han's blog
CH10. 정렬 (Sorting) 1 (단순한 정렬 알고리즘)
10 Aug 2019 | data structure 자료구조CH10. 정렬 (Sorting) 1 (단순한 정렬 알고리즘)
- 정렬?
- 알고리즘 내용이 맞지만 자료구조에서도 다룸
- 자료구조의 3대 연산인 삽입, 삭제, 탐색 중 탐색에서 다뤄지기 때문
- 탐색의 성능을 얼마나 끌어올릴수 있느냐가 중요하며, 이와 직결적으로 연관되는것이 정렬 알고리즘이기 때문임
- 탐색에 앞서 수행되어야 하는것이 정렬 알고리즘
CH10-1. 단순한 정렬 알고리즘
- 복잡한 알고리즘들은 어렵게 구현되나 그 성능(속도)이 매우 좋음
- 반면 단순한 정렬 알고리즘은 쉽게 구현되지만 성능이 좋지 못함
- 단순한 정렬 알고리즘의 방법이 다른 알고리즘에 적용되는 경우가 많음
버블 정렬: 이해
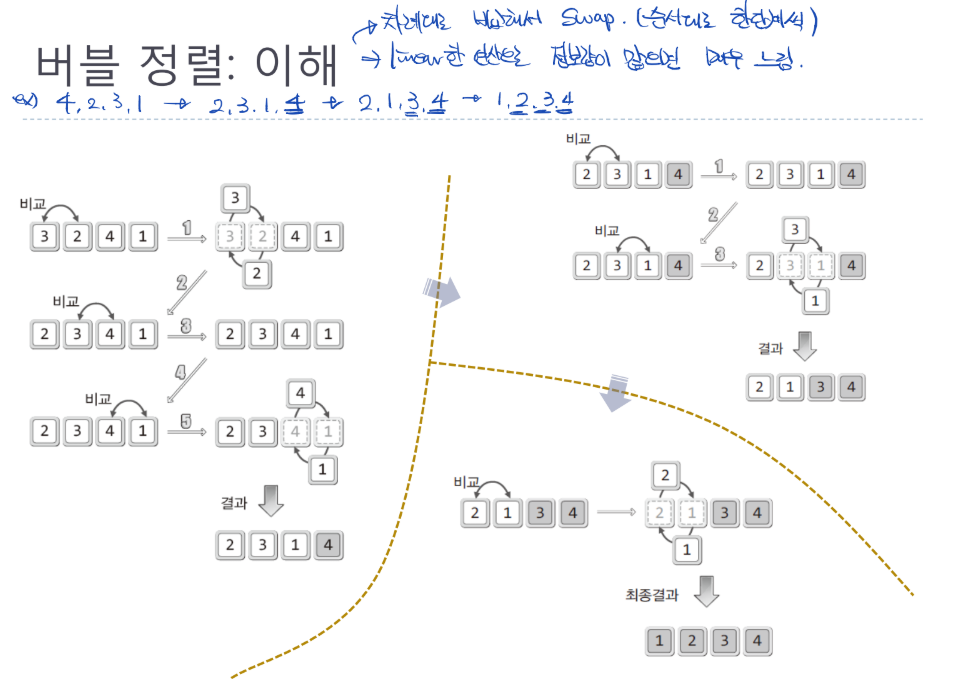
- 차례대로 비교해서 Swap하는 정렬 알고리즘
- 순서대로 한단계씩
- linear한 연산으로 정보량이 많아지면 매우 느려지는 단점이 존재
- 앞에서부터 뒤로 가며 중요도 순서대로 좌우로 순서를 바꿔가며 수행됨
버블 정렬: 구현

- 함수의 입력은 정렬할 데이터와 정렬한 데이터의 길이임
- 바깥쪽 for문은 전체 data를 돌기 위한 역할
- 마지막 데이터 2개는 돌 필요 없으므로
n-1까지만 돌게 됨
- 마지막 데이터 2개는 돌 필요 없으므로
- 안쪽 for문은 각 for 루틴마다 데이터를 비교하도록!
- 즉, 바깥쪽 for문은 0번 인덱스부터 n-1 번째 인덱스까지 돌면서
- 안쪽 for문은 그 다음 숫자와의 비교연산을 수행!
- 인덱스 0, 1, 2, 3 -> 0번째에서 0, 1, 2, 3과 비교 -> 1번째에서 1, 2, 3과 비교 -> 2번째에서 2, 3과 비교
버블 정렬: 성능평가
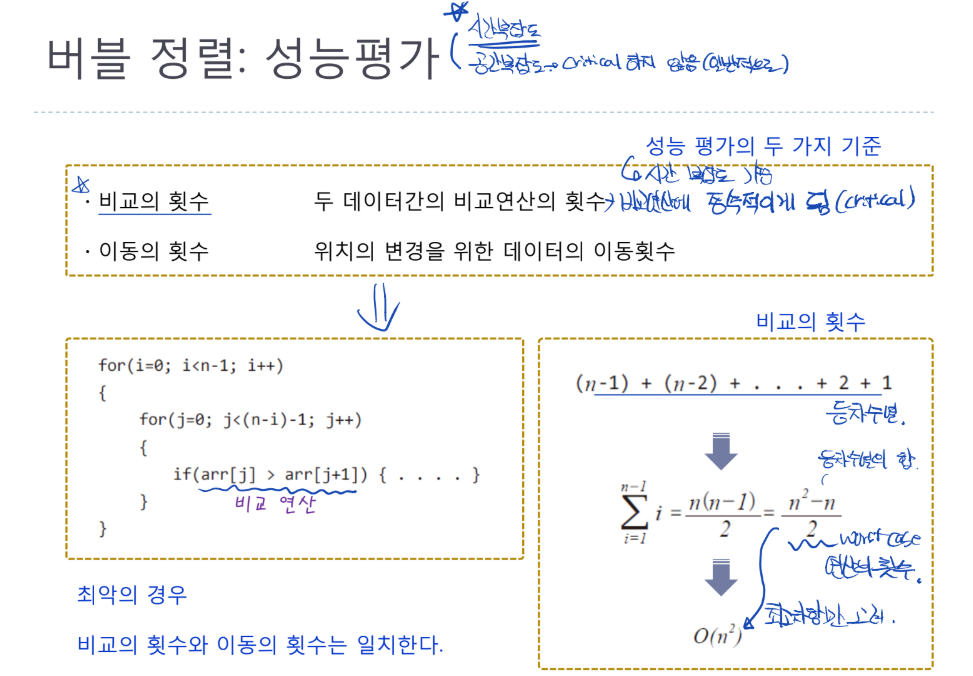
- 시간 복잡도와 공간 복잡도중 시간 복잡도가 critical하기에 시간 복잡도만을 고려함
- 시간 복잡도는 이동보다는 비교 횟수에 critical함 (비교연산에 종속적)
- 비교 연산이 안쪽 for문 안에서 수행됨
- Worst case의 비교 횟수를 계산하여 수식화 한 후 빅-오를 계산하면 $O(n^{2})$ 가 됨
- 등차수열의 합 식에서 최고차항만 고려하기때문
- Worst case의 비교 횟수를 계산하여 수식화 한 후 빅-오를 계산하면 $O(n^{2})$ 가 됨
선택 정렬: 이해
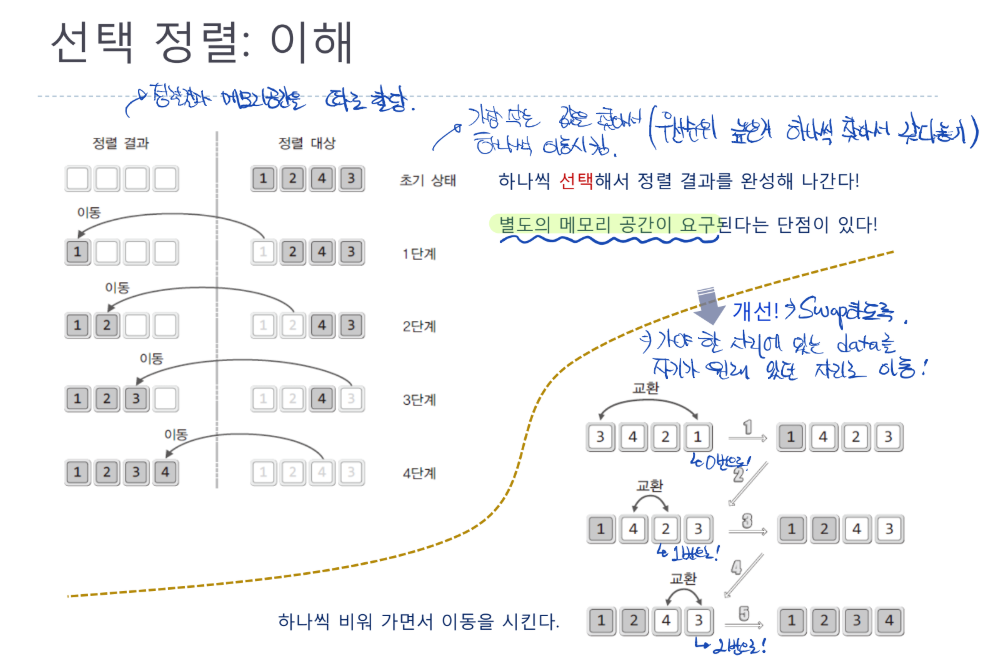
- 기본적으로 정렬결과 메모리공간을 별도로 할당해야함
- 메모리 효율 낮음
- 방법은, 가장 작은 값을 찾아서 하나씩 이동시키게 됨
- 우선순위 높은거 하나씩 찾아서 결과에 갖다놓기
- 메모리 효율을 높게 하기 위해 swap을 이용하여 메모리 낭비를 줄임
- 동일하게 수행하되, 해당 순서의 우선순위가 높은 data가 갈 자리에 존재하는 data와 자리를 바꿈(swap)
선택 정렬: 구현

- 버블 정렬과 동일하게 바깥 for문은 전체 숫자를 돌게하는 역할
- 안쪽 for문은 해당 숫자가 존재해야 할 자리를 찾도록 숫자들을 오른쪽으로 scan하며 알맞은 index를 정함
- 마지막으로 swap 연산 수행
선택 정렬: 성능평가
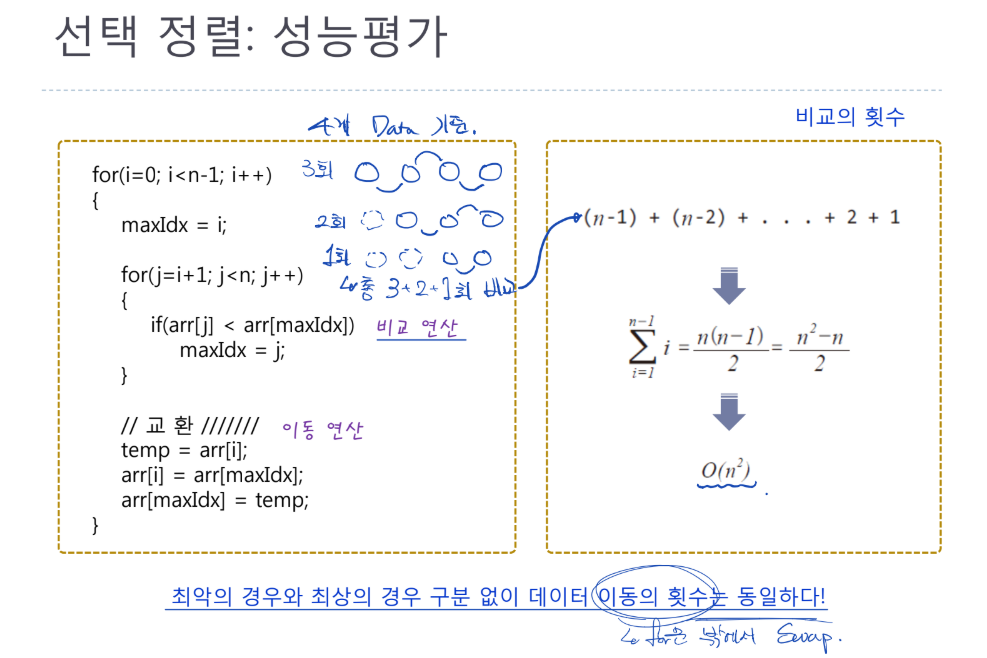
- 버블 정렬과 동일함
- Worst case와 Best case의 구분 없이 데이터 이동 횟수는 동일하다는 단점이 존재
삽입 정렬: 이해
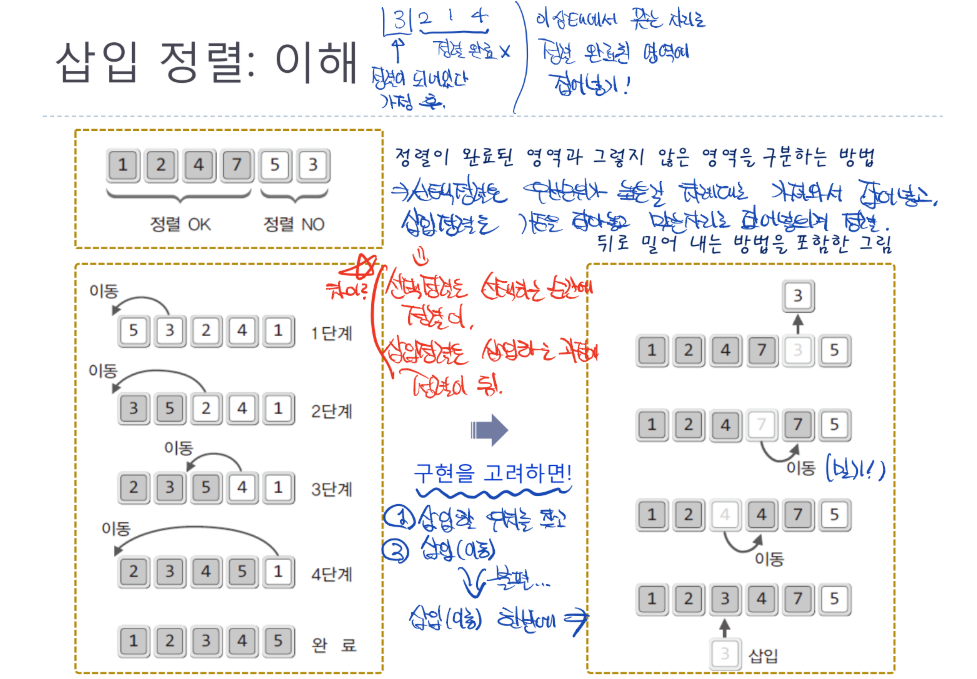
- 언뜻 보면 선택정렬과 동일하다고 생각할 수 있음
- 삽입정렬은 맨 왼쪽 첫번째 숫자를 정렬이 되어있다고 가정하고, 나머지 오른쪽 숫자들을 정렬되지 않은 상태로 하여 해당 숫자들이 올바른 자리로 찾아가도록 알맞은 자리에 삽입시킴
- 선택정렬
- 우선순위가 높은걸 차례대로 가져와서 집어넣음
- 선택하는 순간에 정렬 알고리즘이 적용됨
- 삽입정렬
- 기준을 잡아놓고 맞는 자리로 데이터를 집어넣으며 정렬
- 데이터를 삽입하는 과정에 정렬 알고리즘이 적용됨
- 기본 알고리즘은 동작이 삽입할 위치를 찾고 삽입(이동)되는 식으로 구분되어 있음
- 이를 한번에 수행되도록 구현을 고려하여 최적화
- 한칸씩 데이터를 밀어내며 알맞은 자리를 만들어놓은 후 최종적으로 해당 자리에 삽입
삽입 정렬: 구현

- 바깥쪽 for문은 첫 번째 data를 정렬되어있다고 fix 해 놓기 때문에
n=1부터 시작 - 안쪽 for문은 정렬된 데이터들에서 올바른 위치를 찾아가야 하므로 왼쪽으로 가며 탐색
- 이 과정에서 알맞은 자리를 밀어놓고 들어갈 자리를 만들어둠
삽입 정렬: 성능평가

- if문이 안쪽 for문에 존재
- 앞과 동일한 빅-오를 가짐 ( $O(n^{2})$ )